
項目完成小結 - Django3.x版本 - 開發(fā)部署小結 (2)
前言
好久沒更新博客了,最近依然是在做之前博客說的這個項目:項目完成 - 基于Django3.x版本 - 開發(fā)部署小結
這項目因為前期工作出了問題,需求沒確定好,導致了現(xiàn)在要做很多麻煩的工作,搞得大家都身心疲憊。唉,只能說技術團隊,有里一個靠譜有能力的領導是非常重要的。
進入正題
本文繼續(xù)記錄Django項目開發(fā)的一些經驗。
本次的項目依然基于我定制的「DjangoStarter」項目模板來開發(fā),該項目模板(腳手架)整合了一些常用的第三方庫以及配置,內置代碼生成器,只要專注業(yè)務邏輯實現(xiàn)即可。
數(shù)據(jù)批量導入
上篇文章說到我寫了腳本導入大量數(shù)據(jù)的時候很慢,然后有網友評論可以使用bulk_create,所以在第二期的新增需求中,我處理完數(shù)據(jù)就使用bulk_create來導入,速度確實有了可觀的提升,應該是能達到原生SQL的性能。
先把Model的實例全都添加到列表里面,然后再批量導入,就很快了。
寫了個偽代碼例子
result?=?data_proc()
data?=?[]
for?item?in?result:
????print(f"處理:{item['name']}")
????data.append(ModelObj(name=item['name']))
????
print('正在批量導入')
ModelObj.objects.bulk_create(data)
print('完成')
還有除了這個批量新增的API,DjangoORM還支持批量更新,bulk_update,用法同這個批量新增。
數(shù)據(jù)處理
上次需求很急的情況下,拿到了幾百M的Excel數(shù)據(jù)之后,我直接用Python的openpyxl庫來預處理成JSON格式,然后再一條條導入數(shù)據(jù)庫
而且這些數(shù)據(jù)還涉及到多個表,這就導致了數(shù)據(jù)處理和導入速度異常緩慢
當時是DB manager直接把Excel導入到數(shù)據(jù)庫臨時表處理的,但是后面發(fā)現(xiàn)SQL處理的數(shù)據(jù),清洗過后還是出了很多錯誤
所以后面來的新一批數(shù)據(jù),我選擇自己來搞,SQL還是不太適合做這些數(shù)據(jù)清洗~
直接用openpyxl來處理Excel也太外行了,Python做數(shù)據(jù)分析有很多工具,都可以利用起來,比如pandas。
這次新需求給的Excel很惡心,里面一堆合并的單元格,雖然是好看,但要導入數(shù)據(jù)庫很麻煩啊!
不過還好pandas的數(shù)據(jù)處理功能足夠強大,可以應付這種情況,然后為了整個數(shù)據(jù)處理的過程更直觀,我安排上了jupyter,pycharm現(xiàn)在已經集成了,體驗比網頁版的好一點,不過實際使用的時候發(fā)現(xiàn)有一些bug,有些影響體驗。
數(shù)據(jù)例子如下

第一列序號是沒用的,不管,然后看到這里面姓名的人和家庭成員直接應該是一對多的關系,為了好看合并了單元格,這樣處理的時候就很惡心了,合并后的單元格,pandas讀取進來只有第一行是有數(shù)據(jù)的。
不過我們可以用pandas的數(shù)據(jù)補全功能來處理。
簡單的處理單元格合并的代碼參考:
import?pandas?as?pd
xlsx1?=?pd.ExcelFile('文件名.xlsx')
#?參數(shù)0代表第一個工作表,header=0代表第一行作為表頭,uescols表示讀取的列范圍,我們不要第一列那個序號
df?=?pd.read_excel(xlsx1,?0,?header=0,?usecols='B:G')
df['姓名'].fillna(method='pad',?inplace=True)
df['性別'].fillna(method='pad',?inplace=True)
df['出生年月'].fillna(method='pad',?inplace=True)
df['聯(lián)系人'].fillna(method='pad',?inplace=True)
df['聯(lián)系電話'].fillna(method='pad',?inplace=True)
代碼里有注釋,用fillna填充缺失的字段即可
然后再把DateFrame轉換成比較容易處理的JSON格式(其實在Python里是dict)
json_str?=?df.to_json(orient='records')
parsed?=?json.loads(json_str)
這樣出來就是鍵值對的數(shù)據(jù)了
PS:好像可以直接遍歷df來獲取數(shù)據(jù),轉JSON好像繞了一圈,不過當時比較急沒有研究
參考資料
使用Pandas讀取結構不良 Excel 的2個方法:https://www.shouxicto.com/article/1642.html
PANDAS合并單元格的表格讀取后處理:http://zhangqijun.com/2733-2/
admin后臺優(yōu)化
定制化的項目其實Django Admin后臺用得也不多了,不過作為報表看看數(shù)據(jù)或者進行簡單的篩選操作還是足夠的。
本項目的admin界面基于simpleUI庫定制
從上一篇文章可以看到我對admin后臺的主頁進行了重寫替換,效果如下
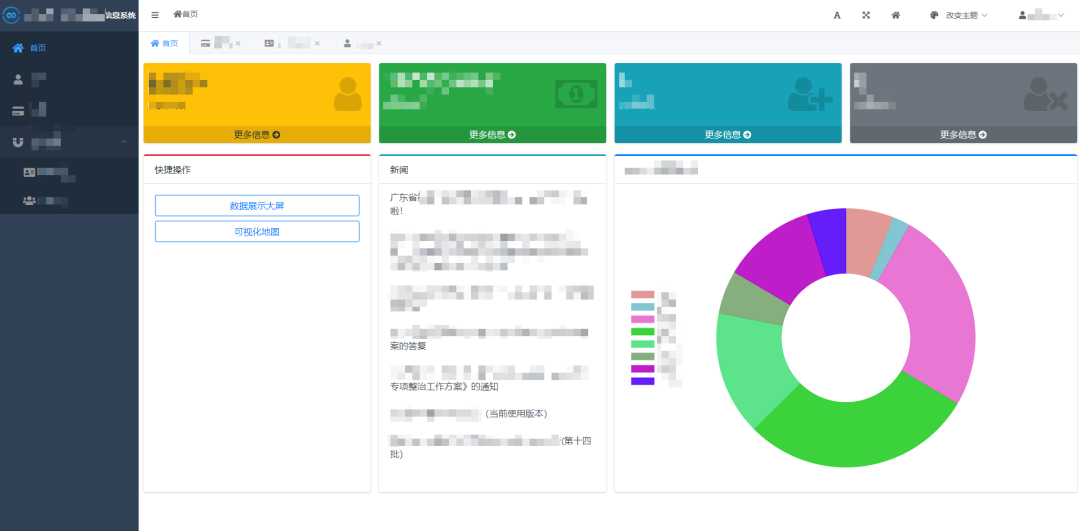
這個界面是用Bootstrap和AdminLTE實現(xiàn)的,AdminLTE這個組件庫確實不錯,在Bootstrap的基礎上增加了幾個很好看的組件,很有用~
然后圖標用的font-awesome,圖表用的是chart.js,都屬于是看看文檔就會用的組件,官網文檔地址我都整理在下面了,自取~
有一點要注意的是,在SimpleUI里,自定義的主頁是以iframe的形式實現(xiàn)的!而SimpleUI本身是Vue+ElementUI,所以想要在主頁里跳轉到admin本身的其他頁面是很難實現(xiàn)的!這點要了解,我暫時沒想到什么好的辦法,要不下次試試別的admin主題好了~
參考資料
AdminLTE:https://adminlte.io/docs/3.2/components/boxes.html FontAwesome:http://www.fontawesome.com.cn/faicons/ Chart.js:https://www.chartjs.org/docs/latest/ Django進階(1): admin后臺高級玩法(多圖) Django實戰(zhàn): 手把手教你配置Django SimpleUI打造美麗后臺(多圖):https://zhuanlan.zhihu.com/p/372185998
繼續(xù)說Django的聚合查詢
上一篇文章有提到聚合查詢,但是沒有細說,本文主要介紹這幾個:
aggregate annotate values values_list
根據(jù)我目前的理解,aggregate和annotate的第一個區(qū)別是,前者返回dict,后者返回queryset,可以繼續(xù)執(zhí)行其他查詢操作。
aggregate
然后就是使用場景的區(qū)別,aggregate一般用于整體數(shù)據(jù)的統(tǒng)計,比如說
統(tǒng)計用戶的男女數(shù)量
from?django.db.models?import?Count
result1?=?User.objects.filter(gender='男').aggregate(male_count=Count('pk',?distinct=True))
result2?=?User.objects.filter(gender='女').aggregate(female_count=Count('pk',?distinct=True))
PS:其實這里的
Count函數(shù)里,可以不加distinct參數(shù)的,畢竟主鍵(pk)應該是不會重復的
這樣返回的數(shù)據(jù)是
#?result1
{
????"male_count":?100
}
#?result2
{
????"female_count":?100
}
應該很容易理解
annotate
annotate的話,一般是搭配values這種分組操作使用,例子:
from?django.db.models?import?Count
result1?=?User.objects.values('gender').annotate(count=Count('pk'))
返回結果
[
????{
????????"gender":?"男",
????????"count":?100
????},
????{
????????"gender":?"女",
????????"count":?100
????}
]
簡而言之,就是在values分組之后,annotate對數(shù)據(jù)進行聚合運算之后把自定義的字段插入每一組內~ 有點拗口,反正看上面的代碼就好理解了。
values / values_list
最后是values和values_list,作用差不多,都是提取數(shù)據(jù)表里某一列的信息,*(這倆都跟分組有關)*
比如說我們的用戶表長這樣
| id | name | gender | country |
|---|---|---|---|
| 1 | 人1 | 男 | 中國 |
| 2 | 人2 | 女 | 越南 |
| 3 | 人3 | 男 | 新加坡 |
| 4 | 人4 | 女 | 馬來西亞 |
| 5 | 人5 | 男 | 中國 |
| 6 | 人6 | 男 | 中國 |
我們可以用這段代碼提取所有國家
User.objects.values("country")
#?或者
User.objects.values_list("country")
前者根據(jù)指定的字段分組后返回包含字典的Queryset
'country':?'中國'},?{'country':?'越南'},?{'country':?'新加坡'},?{'country':?'馬來西亞'},?{'country':?'中國'},?{'country':?'中國'}]>
后者返回的是包含元組的Queryset
'中國',),?('越南',),?('新加坡',),?('馬來西亞',),?('中國',),?('中國',)]>
然后values_list還能加一個flat=True參數(shù),直接返回包含數(shù)組的Queryset
'中國',?'越南',?'新加坡',?'馬來西亞',?'中國',?'中國']>
這就可以很直觀的看出來這倆函數(shù)的作用了。
然后結合上面的annotate再說一下,假如我們要計算每個國家有多少人,可以用這個代碼
User.objects.values("country").annotate(people_count=Count('pk'))
結果大概是這樣
[
????{
????????"country":??"中國",
????????"people_count":?3
????},
????{
????????"country":??"越南",
????????"people_count":?1
????},
????{
????????"country":??"新加坡",
????????"people_count":?3
????},
????{
????????"country":??"馬來西亞",
????????"people_count":?3
????}
]
搞定~
聚合查詢這方面還有很多場景例子,本文只說了個大概,后續(xù)有時間再寫篇新博客來細說一下~
參考資料
Python 教程之如何在 Django 中實現(xiàn)分組查詢:https://chinese.freecodecamp.org/news/introduction-to-django-group/ aggregate和annotate的區(qū)別:https://www.cnblogs.com/Young-shi/p/15174328.html values / values_list:https://www.jianshu.com/p/e92ab45075d5 django_filter的values / values_list:https://blog.csdn.net/weixin_40475396/article/details/79529256
使用docker部署MySQL數(shù)據(jù)庫
雖然之前看到有人說MySQL不適合用docker來部署,不過docker實在方便,優(yōu)點掩蓋了缺點,所以本項目還是繼續(xù)使用docker。
繼續(xù)用docker-compose來編排容器。
首先如果在本地啟動一個測試用的MySQL,可以找個空目錄,單獨創(chuàng)建一個docker-compose.yml文件,配置內容在下面,然后運行docker-compose up。
下面的配置里我做了volumes映射,MySQL數(shù)據(jù)庫的文件會保存在本地這個目錄下的mysql-data文件夾里
version:?"3"
services:
??mysql:
????image:?daocloud.io/mysql
????restart:?always
????volumes:
??????-?./mysql-data:/var/lib/mysql
????environment:
??????-?MYSQL_ROOT_PASSWORD=mysql-admin
??????-?MYSQL_USER=test
??????-?MYSQL_PASS=yourpassword
????ports:
??????-?"3306:3306"
使用ports開啟端口,方便我們使用Navicat等工具連接數(shù)據(jù)庫操作。
下面是整合在web項目中的配置(簡化的配置,詳細配置可以看我的DjangoStarter項目模板)
version:?"3"
services:
??mysql:
????image:?daocloud.io/mysql
????restart:?always
????volumes:
??????-?./mysql-data:/var/lib/mysql
????environment:
??????-?MYSQL_ROOT_PASSWORD=mysql-admin
????#?注意這里使用expose而不是ports里,這是暴露端口給其他容器使用,但docker外部就無法訪問了
????expose:
??????-?3306
??web:
????restart:?always?#?除正常工作外,容器會在任何時候重啟,比如遭遇 bug、進程崩潰、docker 重啟等情況。
????build:?.
????command:?uwsgi?uwsgi.ini
????volumes:
??????-?.:/code
????ports:
??????-?"80:8000"
????#?在依賴這里指定mysql容器,然后才能連接到數(shù)據(jù)庫
????depends_on:
??????-?mysql
關鍵的配置我寫了注釋,很好懂。
參考資料
Docker-compose封裝mysql并初始化數(shù)據(jù)以及redis:https://www.cnblogs.com/xiao987334176/p/12669080.html 你必須知道的Docker數(shù)據(jù)卷(Volume):https://www.cnblogs.com/edisonchou/p/docker_volumes_introduction.html
關于緩存問題
上一篇文章有提到緩存的用法,Redis搭配Django原生的緩存裝飾器cache_page是沒啥問題的,但用第三方的drf-extensions里的cache_response裝飾器的時候,就有個問題,不能針對不同的query params請求參數(shù)緩存響應
比如說下面這兩個地址,雖然是指向同一個接口,但參數(shù)不同,按理說應該返回不同的數(shù)據(jù)。
http://example.api/?type=1 http://example.api/?type=2
但加上cache_response裝飾器之后,無論傳什么參數(shù)都返回同一個結果,目前我還沒搞清楚是我哪里寫錯了還是這個庫的bug~
性能優(yōu)化
老生常談…
上篇文章也說了一點,不過沒有具體。都說DjangoORM性能差,其實瓶頸還是在數(shù)據(jù)庫IO這塊,在耗時最長的IO操作面前,那點性能劣勢其實也不算什么了(特別是我們這種toB的系統(tǒng),沒有高并發(fā)的需求)
經過profile性能分析,瓶頸基本都在哪些統(tǒng)計類的接口,這類接口的特征就是要關聯(lián)多個表查詢,經常一個接口內需要多次請求數(shù)據(jù)庫,所以優(yōu)化思路就很明確了,減少數(shù)據(jù)庫請求次數(shù)。
兩種思路
一種是一次性把數(shù)據(jù)全部取出到內存,然后用pandas這類數(shù)據(jù)分析庫來做聚合處理; 一種是做先做預計算,然后保存中間結果,下次請求接口的時候直接去讀取中間結果,把中間結果拿來做聚合
最終我選擇使用第二種方式,并且選擇把中間結果存在MongoDB數(shù)據(jù)庫里
小結
本項目到這里只是出了一個階段性的成果,還是未完結,從這個項目中也發(fā)現(xiàn)了很多問題,團隊的、自身的,都有。
(不好說太多,刪了)
實際上一個政企項目涉及到太多非技術因素了,其實這本不是咱技術人員需要關心的,但現(xiàn)實就是這樣,唉。