
帶你徹底擊潰跳表原理及其Golang實(shí)現(xiàn)!(內(nèi)含圖解)
導(dǎo)語?|?最近在看《Redis設(shè)計(jì)與實(shí)現(xiàn)》這本書,書中簡(jiǎn)單描述了跳表的性質(zhì)和數(shù)據(jù)結(jié)構(gòu),但對(duì)它的具體實(shí)現(xiàn)沒有詳細(xì)描述。本文是基于我個(gè)人對(duì)跳表原理的深入探究,并通過golang實(shí)現(xiàn)了一個(gè)基礎(chǔ)跳表的理解和實(shí)踐。
前言
書里對(duì)跳表結(jié)構(gòu)的描述是這樣的:
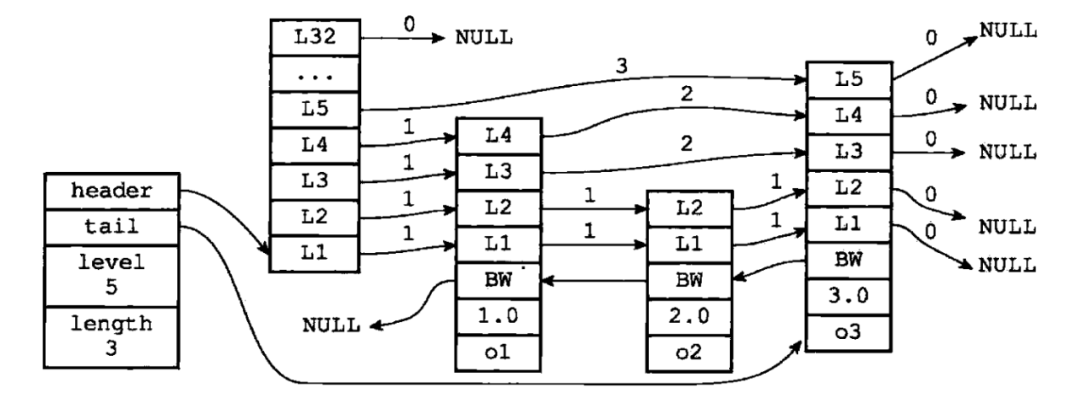
跳躍表節(jié)點(diǎn):
?typedef?struct?zskiplistNode{
?????//?后退指針
?????struct?zskiplistNode?*backward;
?????//?分值
?????double?score;
?????//?成員對(duì)象
?????robj?*obj;
?????//?層
?????struct?zskiplistLevel{
?????????//?前進(jìn)指針
?????????struct?zskiplistNode?*forward;
?????????//?跨度
?????????unsigned?int?span;
????}?level[];
?}?zskiplistNode;
跳躍表結(jié)構(gòu):
?typedf?struct?zskiplist{
?????//?表頭節(jié)點(diǎn)和表尾節(jié)點(diǎn)
?????struct?zskiplistNode?*header,?*tail;
?????//?表中節(jié)點(diǎn)數(shù)量
?????unsigned?long?length;
?????//?表中層數(shù)最大的節(jié)點(diǎn)的層數(shù)
?????int?level;
?}?zskiplist;
雖然大概懂了跳表是一種怎么樣的存在,它有媲美平衡樹的效率,但比平衡樹更加容易實(shí)現(xiàn),但這本書并沒有詳細(xì)描述跳表的實(shí)現(xiàn),其中一些關(guān)鍵點(diǎn)也沒有說明,比如:
為什么表頭節(jié)點(diǎn)是不被計(jì)算在length屬性里?新增節(jié)點(diǎn)時(shí)是如何決定level的指針指向哪個(gè)后繼節(jié)點(diǎn)?為什么zset分值可以相同而成員對(duì)象不能相同?
為了解答這些問題,我決定完全弄懂跳表的原理,自己實(shí)現(xiàn)一個(gè)基礎(chǔ)的跳表。
一、跳表的原理
(一)有序單鏈表和二分查找法
顧名思義,有序單鏈表就是節(jié)點(diǎn)的排列是有順序的鏈表。

如果我們想從中找到一個(gè)節(jié)點(diǎn),比如15,除了從頭節(jié)點(diǎn)開始遍歷,是否有其他方式?
經(jīng)典的查找算法中,有專門針對(duì)一個(gè)有序的數(shù)據(jù)集合的算法,即“二分算法”,以O(shè)(logN)的時(shí)間復(fù)雜度進(jìn)行查找。它通過對(duì)比目標(biāo)數(shù)據(jù)和中間數(shù)據(jù)的大小,在每輪查找中直接淘汰一半的數(shù)據(jù):
中間節(jié)點(diǎn)數(shù)字為10(10或8都可以作為中間節(jié)點(diǎn)),比目標(biāo)15小,所以排除10之前的4個(gè)數(shù)據(jù),在10-21中查找。
中間節(jié)點(diǎn)為18 ,比目標(biāo)15大,排除18及之后的2條數(shù)據(jù),在10-15中查找。
中間節(jié)點(diǎn)為15 ,與目標(biāo)一致,查找結(jié)束。
設(shè)想在鏈表中,我們參考二分算法的思想,為“中間節(jié)點(diǎn)”加索引,就能像二分算法一樣進(jìn)行鏈表數(shù)據(jù)的查找了。

OK,現(xiàn)在我們將每一個(gè)中間節(jié)點(diǎn)抽了出來,組成了另一條鏈表,即一級(jí)索引,一級(jí)索引的每個(gè)節(jié)點(diǎn)都指向原單鏈表對(duì)應(yīng)的節(jié)點(diǎn),這樣可以通過二分算法來快速查找有序單鏈表中的節(jié)點(diǎn)了。
如果原鏈表節(jié)點(diǎn)數(shù)量太多將會(huì)導(dǎo)致一級(jí)索引的節(jié)點(diǎn)數(shù)量也很多,這時(shí)需要繼續(xù)向上建立索引,選取一級(jí)索引的中間節(jié)點(diǎn)建立二級(jí)索引。
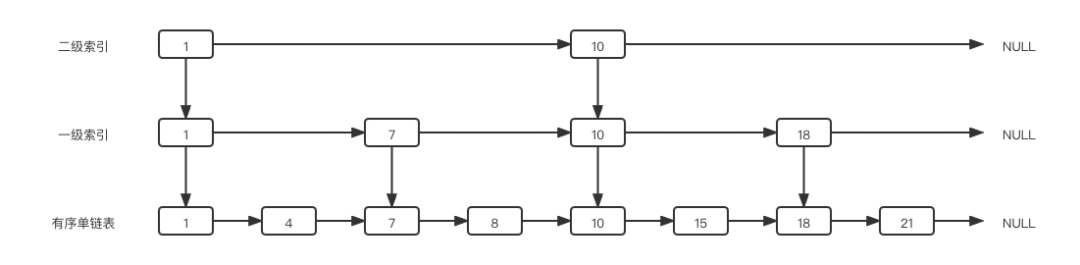
這就是跳表的本質(zhì):是對(duì)有序鏈表的改造,為單鏈表加多層索引,以空間換時(shí)間的策略,解決了單鏈表中查詢速度的問題,同時(shí)也能快速實(shí)現(xiàn)范圍查詢。
鏈表節(jié)點(diǎn)數(shù)少時(shí)提升的效果有限,但當(dāng)鏈表長(zhǎng)度達(dá)到1000甚至10000時(shí),從中查找一個(gè)數(shù)的效率會(huì)得到極大的提升。
(二)跳表索引的更新
二叉樹和跳表的退化
前言中提到,跳表具有媲美平衡樹的效率,平衡樹之所以稱之為平衡樹,是為了解決普通樹結(jié)構(gòu)在極端情況下容易退化成一個(gè)單鏈表的問題,每次插入或刪除節(jié)點(diǎn)時(shí),會(huì)維持樹的平衡性。
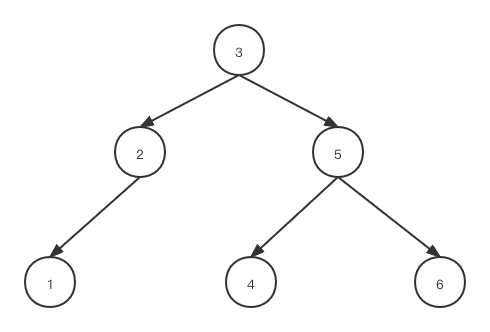
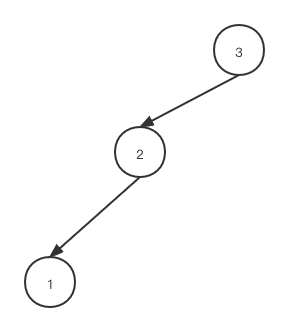
下面這種二叉樹具有O(log n) 的查找時(shí)間復(fù)雜度,但在極端情況下容易發(fā)生退化,比如刪除了4,5,6三個(gè)節(jié)點(diǎn)后,會(huì)退化為單鏈表,查詢時(shí)間復(fù)雜度退化為O(n).
退化后的二叉樹:
如果跳表在插入新節(jié)點(diǎn)后索引就不再更新,在極端情況下,它可能發(fā)生退化,比如下面這種情況:

10到100之間插入n多個(gè)節(jié)點(diǎn),查詢這其中的數(shù)據(jù)時(shí),查詢時(shí)間復(fù)雜度將退化到接近O(n)。既然跳表被稱之為媲美平衡樹的數(shù)據(jù)結(jié)構(gòu),也必然會(huì)維護(hù)索引以保證不退化。
跳表索引的維護(hù)
通過晉升機(jī)制。既然現(xiàn)在跳表每?jī)蓚€(gè)原始鏈表節(jié)點(diǎn)中有一個(gè)被建立了一級(jí)索引,而每?jī)蓚€(gè)一級(jí)索引中有一個(gè)被建立了二級(jí)索引,n個(gè)節(jié)點(diǎn)中有n/2個(gè)索引,可以理解為:在同一級(jí)中,每個(gè)節(jié)點(diǎn)晉升到上一級(jí)索引的概率為1/2。
如果不嚴(yán)格按照“每?jī)蓚€(gè)節(jié)點(diǎn)中有一個(gè)晉升”,而是“每個(gè)節(jié)點(diǎn)有1/2的概率晉升”,當(dāng)節(jié)點(diǎn)數(shù)量少時(shí),可能會(huì)有部分索引聚集,但當(dāng)節(jié)點(diǎn)數(shù)量足夠大時(shí),建立的索引也就足夠分散,就越接近“嚴(yán)格的每?jī)蓚€(gè)節(jié)點(diǎn)中有一個(gè)晉升”的效果。
當(dāng)然,晉升的概率可以根據(jù)需求進(jìn)行調(diào)整,1/3或1/4,晉升概率稍小時(shí),空間復(fù)雜度小,但查詢效率會(huì)降低。在下文中,我們將晉升率設(shè)置為p。
(三)時(shí)間復(fù)雜度與空間復(fù)雜度
時(shí)間復(fù)雜度
結(jié)論:跳表的時(shí)間復(fù)雜度為O(log n)
證明:
按二分法進(jìn)化出的跳表,無論是原鏈表還是N級(jí)索引,都是每?jī)蓚€(gè)節(jié)點(diǎn)中有一個(gè)被用作上一級(jí)索引。這個(gè)過程我們稱之為“晉升”,晉升的概率為p。
假設(shè)原鏈表節(jié)點(diǎn)數(shù)量為n,一級(jí)索引節(jié)點(diǎn)數(shù)為n*p^1,二級(jí)索引節(jié)點(diǎn)數(shù)為n*p^2,以此類推,h級(jí)索引的節(jié)點(diǎn)數(shù)應(yīng)為n*(p^h)。
最高層的期望節(jié)點(diǎn)數(shù)應(yīng)為1/p,我的理解是:小于等于這個(gè)期望數(shù),再高一層索引的期望節(jié)點(diǎn)數(shù)將為1,沒有意義了。
根據(jù)上述推算,易得一個(gè)跳表的期望索引高度h為:
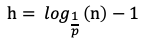
加上底層的原始鏈表,跳表的期望總高度H為:
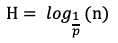
查找索引時(shí),我們運(yùn)用倒推的思維,從原始鏈表上的目標(biāo)節(jié)點(diǎn)推到頂層索引的起始節(jié)點(diǎn),示意圖如下:
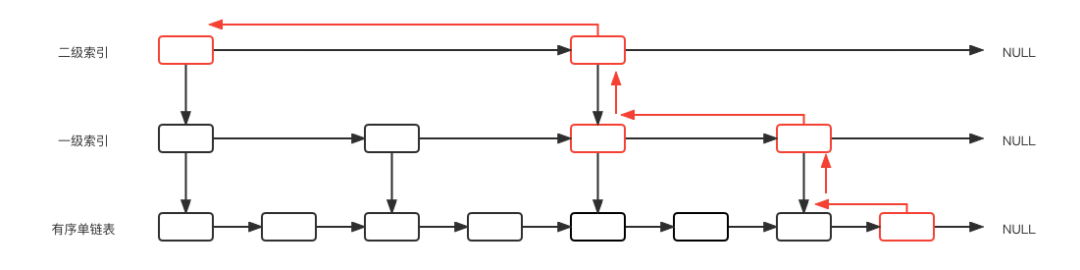
當(dāng)我們?cè)诘讓庸?jié)點(diǎn)時(shí),只有兩種路徑可走,向上或向左,向上的概率為p,向左的概率為1-p。
假設(shè)C(i)為一個(gè)無限長(zhǎng)度的跳表中向上爬i層的期望代價(jià)(即經(jīng)過的節(jié)點(diǎn)數(shù)量)
爬到第0層時(shí),無需經(jīng)過任何節(jié)點(diǎn),所以有:
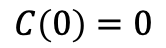
爬到第1層時(shí),可能有兩種情況:
從有p的概率是從第0層直接爬升1個(gè)節(jié)點(diǎn),這種情況經(jīng)過的節(jié)點(diǎn)數(shù)為:
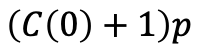
有1-p的概率是從第1層向左移動(dòng)一個(gè)節(jié)點(diǎn),則經(jīng)過的節(jié)點(diǎn)數(shù)為:
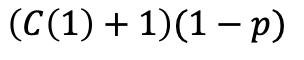
則有:
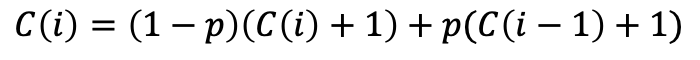
解得:C(i) = i/p
當(dāng)爬到期望中的最高層——第h層時(shí),則期望步數(shù)為h/p,在第h層,繼續(xù)向左走的期望步數(shù)不會(huì)超過當(dāng)前層節(jié)點(diǎn)的期望總和1/p,向上走的期望步數(shù)也不會(huì)超過當(dāng)前層節(jié)點(diǎn)的期望總和1/p,全部加起來,從最底層的目標(biāo)節(jié)點(diǎn)到最頂層的頭節(jié)點(diǎn),期望步數(shù)為h/p+2/p,將上面h的公式帶入,忽略常量,時(shí)間復(fù)雜度為O(log n)。
空間復(fù)雜度
空間復(fù)雜度基本上就是等比數(shù)列之和的計(jì)算,比值為p。
直接說結(jié)果為O(n)
二、跳表的實(shí)現(xiàn)
為了更好地理解跳表,自己參考著跳表的原理,嘗試手?jǐn)]一條跳表,當(dāng)然這是最基礎(chǔ)的,沒有redis跳表那樣豐富的能力,粗略實(shí)現(xiàn)了對(duì)數(shù)字的增刪改查,以插入的數(shù)字作為排序的基準(zhǔn),不支持重復(fù)數(shù)字的插入。
redis跳表在經(jīng)典跳表之上有額外的實(shí)現(xiàn):
經(jīng)典跳表不支持重復(fù)值,redis跳表支持重復(fù)的分值score。
redis跳表的排序是根據(jù)score和成員對(duì)象兩者共同決定的。
redis跳表的原鏈表是個(gè)雙向鏈表。
在這之前需要說明,索引的節(jié)點(diǎn)其實(shí)并不是像底層鏈表一樣的節(jié)點(diǎn)Node,而是一種Level層結(jié)構(gòu),每個(gè)層中都包含了Node的指針,指向下一個(gè)節(jié)點(diǎn)。
(一)基礎(chǔ)數(shù)據(jù)結(jié)構(gòu)
const?MaxLevel?=?32
const?p?=?0.5
type?Node?struct?{
??value??uint32
??levels?[]*Level?//?索引節(jié)點(diǎn),index=0是基礎(chǔ)鏈表
}
type?Level?struct?{
??next?*Node
}
type?SkipList?struct?{
??header?*Node??//?表頭節(jié)點(diǎn)
??length?uint32?//?原始鏈表的長(zhǎng)度,表頭節(jié)點(diǎn)不計(jì)入
??height?uint32?//?最高的節(jié)點(diǎn)的層數(shù)
}
func?NewSkipList()?*SkipList?{
??return?&SkipList{
????header:?NewNode(MaxLevel,?0),
????length:?0,
????height:?1,
??}
}
func?NewNode(level,?value?uint32)?*Node?{
??node?:=?new(Node)
??node.value?=?value
??node.levels?=?make([]*Level,?level)
??for?i?:=?0;?i?????node.levels[i]?=?new(Level)
??}
??return?node
}
這里的p就是上面提到的節(jié)點(diǎn)晉升概率,MaxLevel為跳表最高的層數(shù),這兩個(gè)數(shù)字可以根據(jù)需求設(shè)定,根據(jù)上面推出的跳表高度公式:
可以倒推出此跳表的容納元素?cái)?shù)量上限,n為2^32個(gè)。
(二)插入元素
重點(diǎn)在于如何確認(rèn)插入的這個(gè)新節(jié)點(diǎn)需要幾層索引?通過下面這個(gè)函數(shù)根據(jù)晉升概率隨機(jī)生成這個(gè)新節(jié)點(diǎn)的層數(shù)。
func?(sl?*SkipList)?randomLevel()?int?{
??level?:=?1
??r?:=?rand.New(rand.NewSource(time.Now().UnixNano()))
??for?r.Float64()?????level++
??}
??return?level
}
可以看出,默認(rèn)層數(shù)為1,即無索引,通過隨機(jī)一個(gè)0-1的數(shù),如果小于晉升概率p,且總層數(shù)不大于最大層數(shù)時(shí),將level+1。
這樣就有:
1/2的概率level為1
1/4的概率level為2
1/8的概率level為3
......
這里需要注意一下,上面我們說有1/2的概率有一層索引,即level為2的概率應(yīng)該是1/2,為什么這里是1/4呢?而位于第一層的原始鏈表存在的概率應(yīng)該是1,這里為什么level=1的概率為1/2呢?
原因在于,當(dāng)level為2時(shí),同時(shí)也表示存在第一層;當(dāng)level為3時(shí),同時(shí)也存在第一層和第二層;畢竟不能出現(xiàn)“空中閣樓”。所以:
新節(jié)點(diǎn)存在原鏈表節(jié)點(diǎn)的概率為1/2+1/4+1/8+...=1
新節(jié)點(diǎn)存在一層索引的概率為1/4+1/8+1/16+...=1/2
新節(jié)點(diǎn)存在二層索引的概率為1/8+1/16+1/32+...=1/4
插入元素的具體代碼如下:
func?(sl?*SkipList)?Add(value?uint32)?bool?{
??if?value?<=?0?{
????return?false
??}
??update?:=?make([]*Node,?MaxLevel)
??//?每一次循環(huán)都是一次尋找有序單鏈表的插入過程
??tmp?:=?sl.header
??for?i?:=?int(sl.height)?-?1;?i?>=?0;?i--?{
????????//?每次循環(huán)不重置?tmp,直接從上一層確認(rèn)的節(jié)點(diǎn)開始向下一層查找
????for?tmp.levels[i].next?!=?nil?&&?tmp.levels[i].next.value???????tmp?=?tmp.levels[i].next
????}
????????//?避免插入相同的元素
????if?tmp.levels[i].next?!=?nil?&&?tmp.levels[i].next.value?==?value?{
??????return?false
????}
????update[i]?=?tmp
??}
??level?:=?sl.randomLevel()
??node?:=?NewNode(uint32(level),?value)
??//?fmt.Printf("level:%v,value:%v\n",?level,?value)
??if?uint32(level)?>?sl.height?{
????sl.height?=?uint32(level)
??}
??for?i?:=?0;?i?
????????//?說明新節(jié)點(diǎn)層數(shù)超過了跳表當(dāng)前的最高層數(shù),此時(shí)將頭節(jié)點(diǎn)對(duì)應(yīng)層數(shù)的后繼節(jié)點(diǎn)設(shè)置為新節(jié)點(diǎn)
????if?update[i]?==?nil?{
??????sl.header.levels[i].next?=?node
??????continue
????}
????????//?普通的插入鏈表操作,修改新節(jié)點(diǎn)的后繼節(jié)點(diǎn)為前一個(gè)節(jié)點(diǎn)的后繼節(jié)點(diǎn),修改前一個(gè)節(jié)點(diǎn)的后繼節(jié)點(diǎn)為新節(jié)點(diǎn)
????node.levels[i].next?=?update[i].levels[i].next
????update[i].levels[i].next?=?node
??}
??sl.length++
??return?true
}
數(shù)組update保存了每一層對(duì)應(yīng)的插入位置。
從頭節(jié)點(diǎn)的最高層開始查詢,每次循環(huán)都可以理解為一次尋找有序單鏈表插入位置的過程。
找到在這層索引的插入位置,存入update數(shù)組中。
遍歷完一層后,直接使用這一層查到的節(jié)點(diǎn),即代碼中的tmp開始遍歷下一層索引。
重復(fù)1-3步直到結(jié)束。
獲取新節(jié)點(diǎn)的層數(shù),以確定從哪一層開始插入。如果層數(shù)大于跳表當(dāng)前的最高層數(shù),修改當(dāng)前最高層數(shù)。
遍歷update數(shù)組,但只遍歷到新節(jié)點(diǎn)的最大層數(shù)。
增加跳表長(zhǎng)度,返回true表示新增成功。
比如下面這張?zhí)恚乙略鲈?,最高高度為5,當(dāng)前最高高度為3:
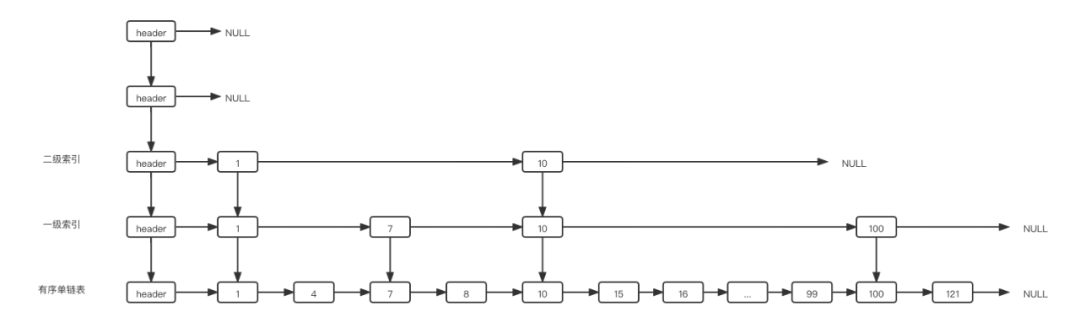
update長(zhǎng)度為5
那么會(huì)從3層開始向下遍歷,在二級(jí)索引這層找到9應(yīng)該插入的位置——1和10之間,update[2]記錄包含1的節(jié)點(diǎn)。
在一級(jí)索引這層找到9應(yīng)該插入的位置——7和10之間,update[1]記錄了包含7的節(jié)點(diǎn)。
在原鏈表這層找到9應(yīng)該插入的位置——8和10之間,update[0]記錄了包含8的節(jié)點(diǎn)。
假設(shè)新節(jié)點(diǎn)的level為4,則修改當(dāng)前最高高度為4,然后開始逐層插入這個(gè)新節(jié)點(diǎn),update[3]為空,因?yàn)槟壳罢麄€(gè)跳表的高度只有3,所以需要將三級(jí)索引上的節(jié)點(diǎn)9插入到頭節(jié)點(diǎn)后面,插入過程與普通的鏈表插入無異。示意圖如下:

(三)刪除元素
func?(sl?*SkipList)?Delete(value?uint32)?bool?{
??var?node?*Node
??last?:=?make([]*Node,?sl.height)
??tmp?:=?sl.header
??for?i?:=?int(sl.height)?-?1;?i?>=?0;?i--?{
????for?tmp.levels[i].next?!=?nil?&&?tmp.levels[i].next.value???????tmp?=?tmp.levels[i].next
????}
????last[i]?=?tmp
????//?拿到?value?對(duì)應(yīng)的?node
????if?tmp.levels[i].next!=nil&&tmp.levels[i].next.value?==?value?{
??????node?=?tmp.levels[i].next
????}
??}
????//?沒有找到?value?對(duì)應(yīng)的?node
??if?node?==?nil?{
????return?false
??}
??//?找到所有前置節(jié)點(diǎn)后需要?jiǎng)h除node
??for?i?:=?0;?i?????last[i].levels[i].next?=?node.levels[i].next
????node.levels[i].next?=?nil
??}
??//?重定向跳表高度
??for?i?:=?0;?i?????if?sl.header.levels[i].next?==?nil?{
??????sl.height?=?uint32(i)
??????break
????}
??}
??sl.length--
??return?true
}
與插入節(jié)點(diǎn)思路一致,從最上層開始向下遍歷尋找,找到需要?jiǎng)h除的節(jié)點(diǎn)的前置節(jié)點(diǎn)并記錄在 last 數(shù)組中,然后修改前置節(jié)點(diǎn)指針的指向。
(四)查找
解決了增刪,剩下的查詢就很簡(jiǎn)單了,可以查找對(duì)應(yīng)value的node,也可以查找一個(gè)范圍。
查找范圍即先找到范圍前邊界的節(jié)點(diǎn),再通過鏈表向后遍歷即可。
這里我只實(shí)現(xiàn)了查找單個(gè)node的函數(shù):
func?(sl?*SkipList)?Find(value?uint32)?*Node?{
??var?node?*Node
??tmp?:=?sl.header
??for?i?:=?int(sl.height)?-?1;?i?>=?0;?i--?{
????for?tmp.levels[i].next?!=?nil?&&?tmp.levels[i].next.value?<=?value?{
??????tmp?=?tmp.levels[i].next
????}
????if?tmp.value?==?value?{
??????node?=?tmp
??????break
????}
??}
??return?node
}
三、redis的跳表實(shí)現(xiàn)
上述是一個(gè)標(biāo)準(zhǔn)跳表的原理和實(shí)現(xiàn),redis中的跳表還有所不同,它提供了更多的特性和能力:
經(jīng)典跳表不支持重復(fù)值,redis跳表支持重復(fù)的分值score。
redis跳表的排序是根據(jù)score和成員對(duì)象兩者共同決定的。
redis跳表的原鏈表是個(gè)雙向鏈表。
redis中,跳表只在zset結(jié)構(gòu)有使用。zset結(jié)構(gòu)在成員較少時(shí)使用壓縮列表 ziplist作為存儲(chǔ)結(jié)構(gòu),成員達(dá)到一定數(shù)量后會(huì)改用map+skiplist作為存儲(chǔ)結(jié)構(gòu)。這里只討論使用skiplist的實(shí)現(xiàn)。
zset結(jié)構(gòu)要求,分值可以相同,但保存的成員對(duì)象不能相同。zset對(duì)跳表排序的依據(jù)是“分值和成員對(duì)象”兩個(gè)維度,分值可以相同,但成員對(duì)象不能一樣。分值相同時(shí),按成員對(duì)象首字母在字典的順序確定先后。
zset還維護(hù)了一個(gè)map,保存成員對(duì)象與分值的映射關(guān)系,被用來通過成員對(duì)象快速查找分值,定位對(duì)應(yīng)的節(jié)點(diǎn),在ZRANK、ZREVRANK、ZSCORE等命令中均有使用。
另外,這個(gè)map還用于插入節(jié)點(diǎn)時(shí),判斷是否存在重復(fù)的成員對(duì)象。見下面redis源碼中的dictFind函數(shù)。
int?zsetAdd(robj?*zobj,?double?score,?sds?ele,?int?in_flags,?int?*out_flags,?double?*newscore)?{
????//?...
????/*?Update?the?sorted?set?according?to?its?encoding.?*/
????if?(zobj->encoding?==?OBJ_ENCODING_ZIPLIST)?{
????????//?...
????}?else?if?(zobj->encoding?==?OBJ_ENCODING_SKIPLIST)?{
????????zset?*zs?=?zobj->ptr;
????????zskiplistNode?*znode;
????????dictEntry?*de;
????????de?=?dictFind(zs->dict,ele);
????????if?(de?!=?NULL)?{
????????????//?已經(jīng)存在
????????????//?...
????????}?else?if?(!xx)?{
????????????//?不存在,插入
????????????ele?=?sdsdup(ele);
????????????znode?=?zslInsert(zs->zsl,score,ele);
????????????serverAssert(dictAdd(zs->dict,ele,&znode->score)?==?DICT_OK);
????????????*out_flags?|=?ZADD_OUT_ADDED;
????????????if?(newscore)?*newscore?=?score;
????????????return?1;
????????}?else?{
????????????*out_flags?|=?ZADD_OUT_NOP;
????????????return?1;
????????}
????}
}
四、回顧問題
前面提到,在看《Redis設(shè)計(jì)與實(shí)現(xiàn)》這本書時(shí)我有幾點(diǎn)疑問,在詳細(xì)了解跳表之后現(xiàn)在就完全理解了。
(一)為什么表頭節(jié)點(diǎn)是不被計(jì)算在length屬性里?
因?yàn)楸眍^節(jié)點(diǎn)是初始化跳表時(shí)提供的空節(jié)點(diǎn),不保存任何節(jié)點(diǎn),只用于提供各級(jí)索引的入口。
(二)新增節(jié)點(diǎn)時(shí)是如何決定level的指針指向哪個(gè)后繼節(jié)點(diǎn)?
通過分值和成員對(duì)象共同決定,判斷新節(jié)點(diǎn)的插入位置和順序。分值相同時(shí),按成員對(duì)象首字母在字典的順序確定先后。
經(jīng)典跳表也同樣需要一個(gè)維度來確定插入的順序,我的跳表實(shí)現(xiàn)中直接使用了新節(jié)點(diǎn)的值作為排序的維度。
(三)為什么zset分值可以相同而成員對(duì)象不能相同?
根據(jù)第二個(gè)問題的答案,如果都相同,就無法確定插入的位置和順序。
?作者簡(jiǎn)介
馮啟源
騰訊后臺(tái)開發(fā)工程師
騰訊后臺(tái)開發(fā)工程師,畢業(yè)于中南大學(xué),目前負(fù)責(zé)騰訊教育業(yè)務(wù)的后端開發(fā)工作,希望能用技術(shù)改善人們的生活。
想要了解關(guān)于 Go 的更多資訊,還可以通過掃描的方式,進(jìn)群一起探討哦~
ps:群內(nèi)還有 剩余不多的個(gè)空位,拼手速的時(shí)候到了(bushi)!?還可以加?微信號(hào):gocnio?讓小編拉你進(jìn)群哦