
商品推薦系統(tǒng)淺析

2.1 推薦系統(tǒng)的定義
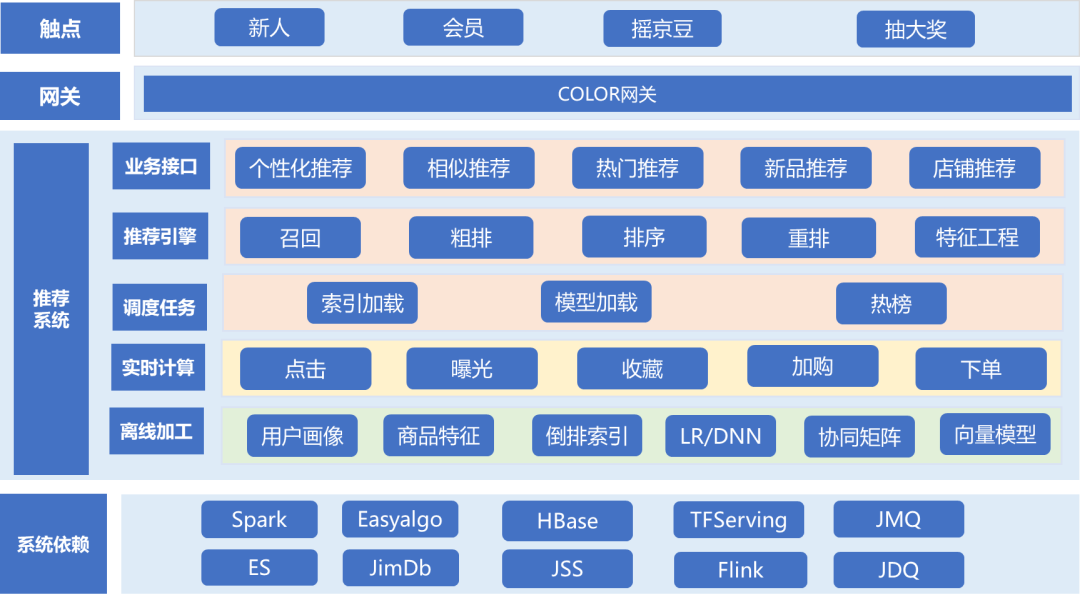
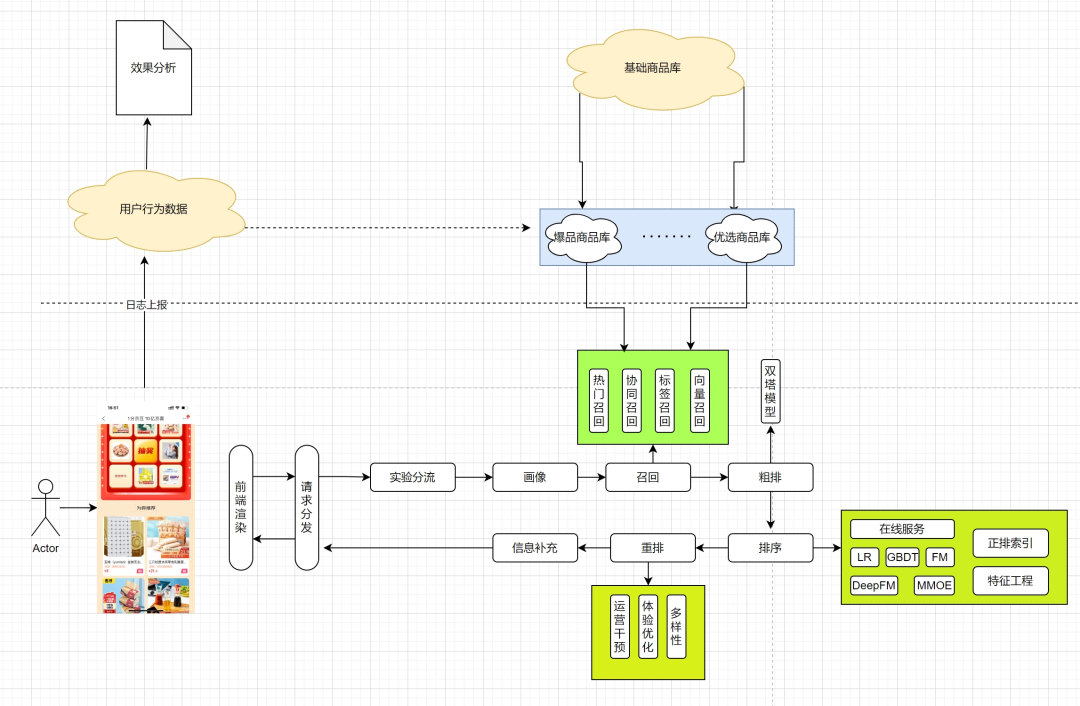
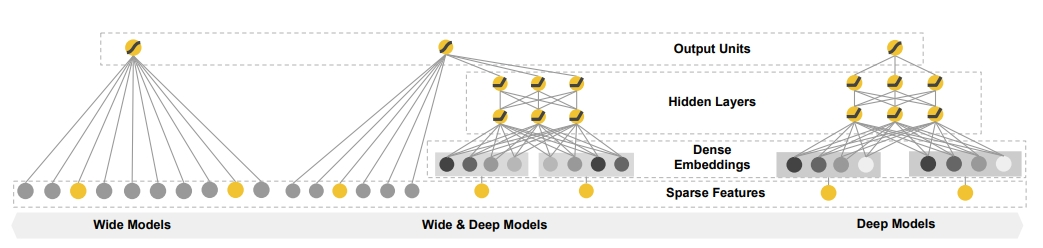
2.2 推薦架構(gòu)
 ?
?
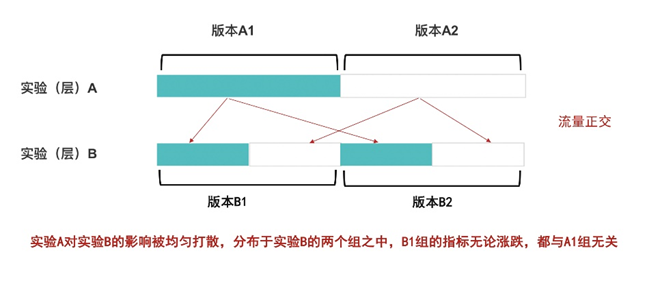
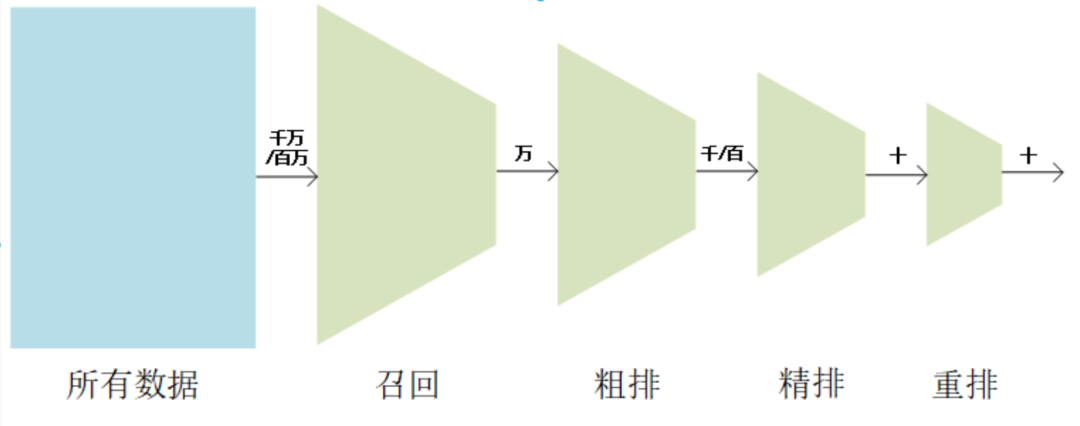
2.3.1 多路召回的優(yōu)劣
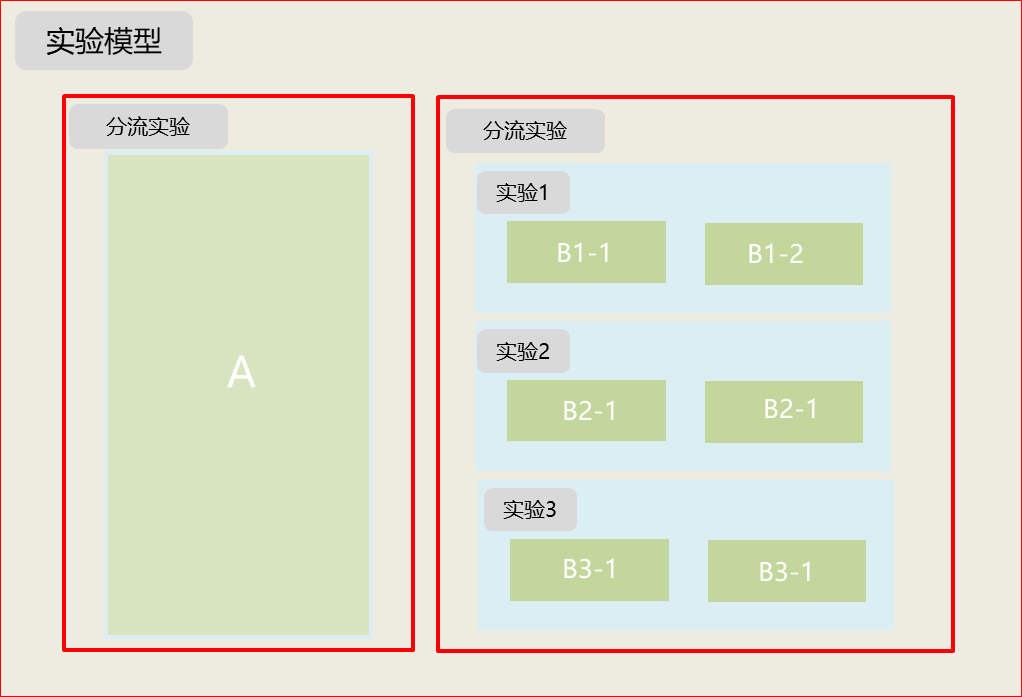
2.3.2 召回分類
-
標簽召回:用戶感興趣的品類、品牌、店鋪召回等 -
地域召回:根據(jù)用戶的地域召回地域內(nèi)的優(yōu)質(zhì)商品。
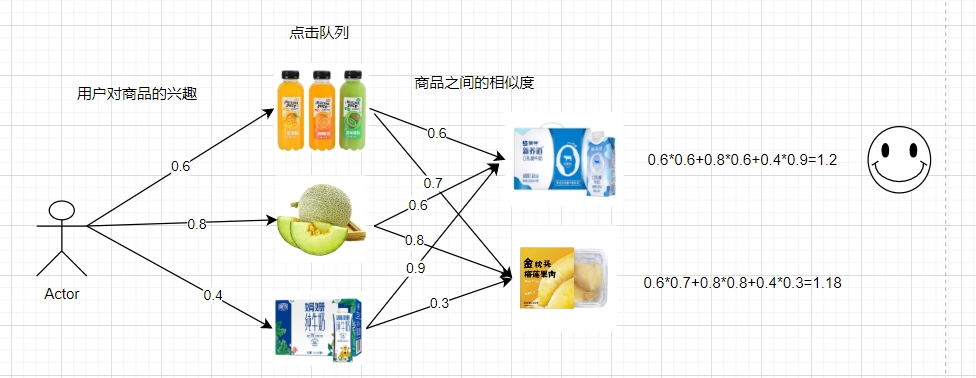
| 商品a |
商品b | 商品c | 商品d | |
| 用戶A |
1 |
0 |
0 | 1 |
| 用戶B | 0 |
1 | 1 |
0 |
| 用戶C | 1 |
0 | 1 |
1 |
| 用戶D | 1 |
1 | 0 |
0 |
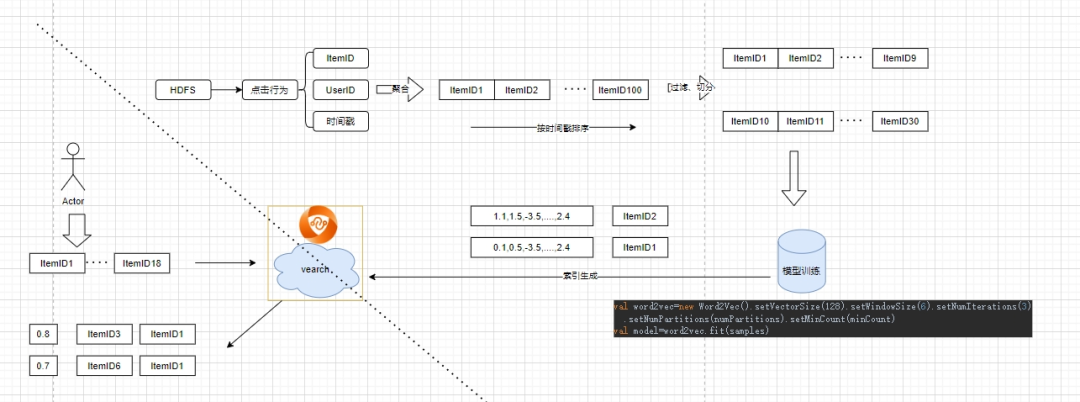
-
局部敏感性哈希(LSH) -
基于圖(HNSW) -
基于乘積量化
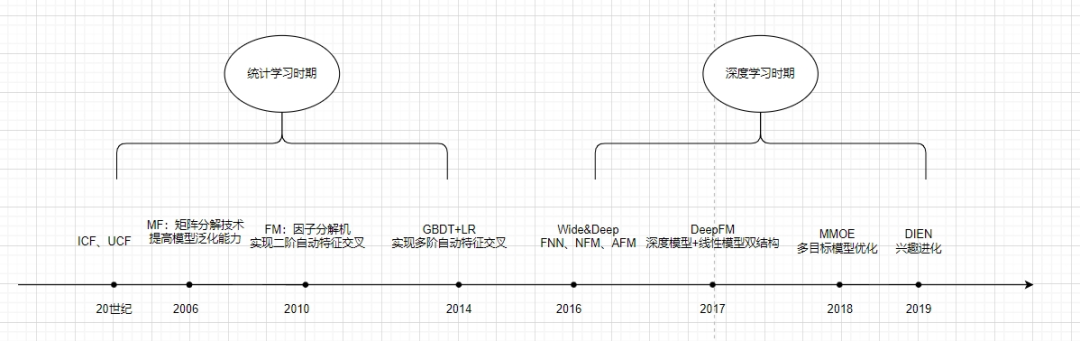
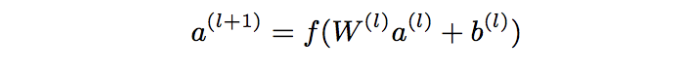
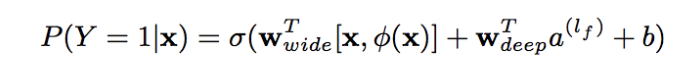
2.5 重排
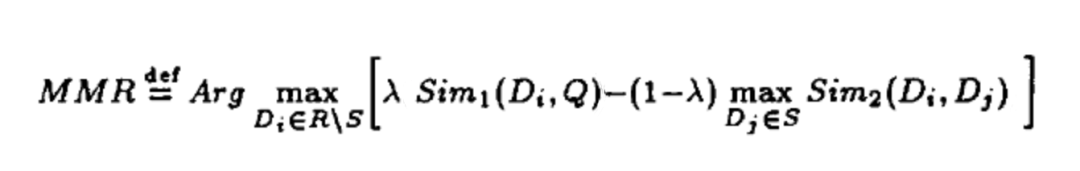
def MMR(itemScoreDict, similarityMatrix, lambdaConstant=0.5, topN=20):#s 排序后列表 r 候選項r = [], list(itemScoreDict.keys())while len(r) > 0:score = 0selectOne = None# 遍歷所有剩余項for i in r:firstPart = itemScoreDict[i]# 計算候選項與"已選項目"集合的最大相似度secondPart = 0for j in s:sim2 = similarityMatrix[i][j]if sim2 > second_part:secondPart = sim2equationScore = lambdaConstant * (firstPart - (1 - lambdaConstant) * secondPart)if equationScore > score:score = equationScoreselectOne = iif selectOne == None:selectOne = i# 添加新的候選項到結(jié)果集r,同時從s中刪除r.remove(selectOne)s.append(selectOne)return (s, s[:topN])[topN > len(s)]
評論
圖片
表情