
詳解 XGBoost 2.0重大更新!
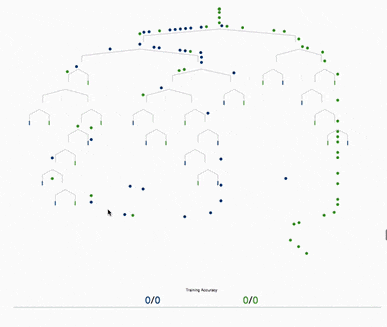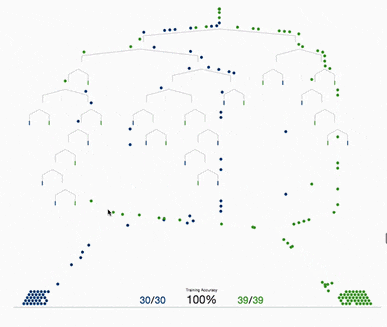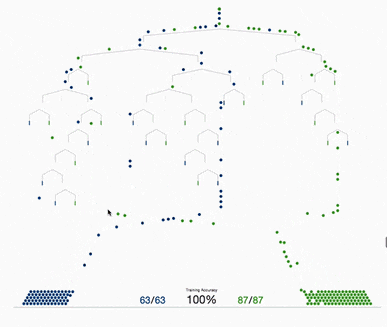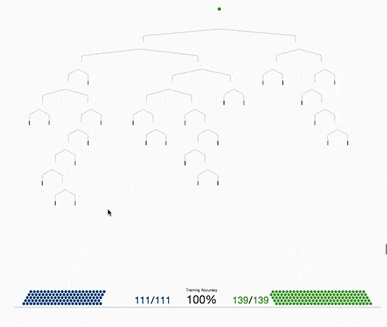
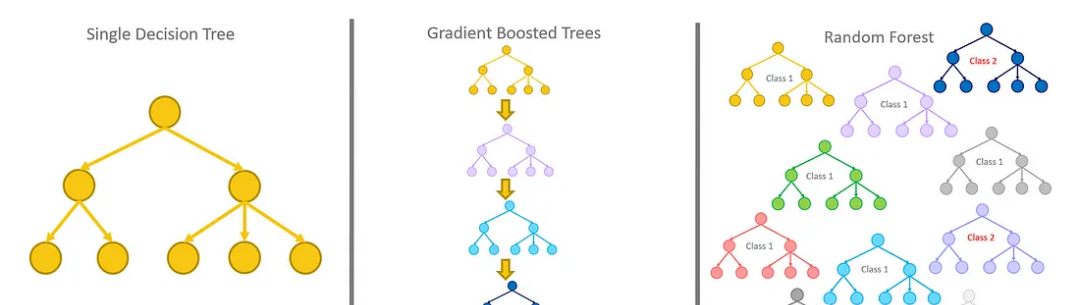
決策樹(shù)
損失函數(shù)
基尼系數(shù)
基尼指數(shù)還是信息增益?
過(guò)擬合和修剪
-
分割:隨著樹(shù)的增長(zhǎng),持續(xù)監(jiān)控它在驗(yàn)證數(shù)據(jù)集上的性能。如果性能開(kāi)始下降,這是停止生長(zhǎng)樹(shù)的信號(hào)。 -
后修剪:在樹(shù)完全生長(zhǎng)后,修剪不能提供太多預(yù)測(cè)能力的節(jié)點(diǎn)。這通常是通過(guò)刪除節(jié)點(diǎn)并檢查它是否會(huì)降低驗(yàn)證準(zhǔn)確性來(lái)完成的。如果不是則修剪節(jié)點(diǎn)。
隨機(jī)森林

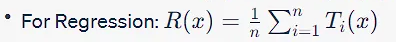
過(guò)擬合和Bagging
梯度增強(qiáng)決策樹(shù)
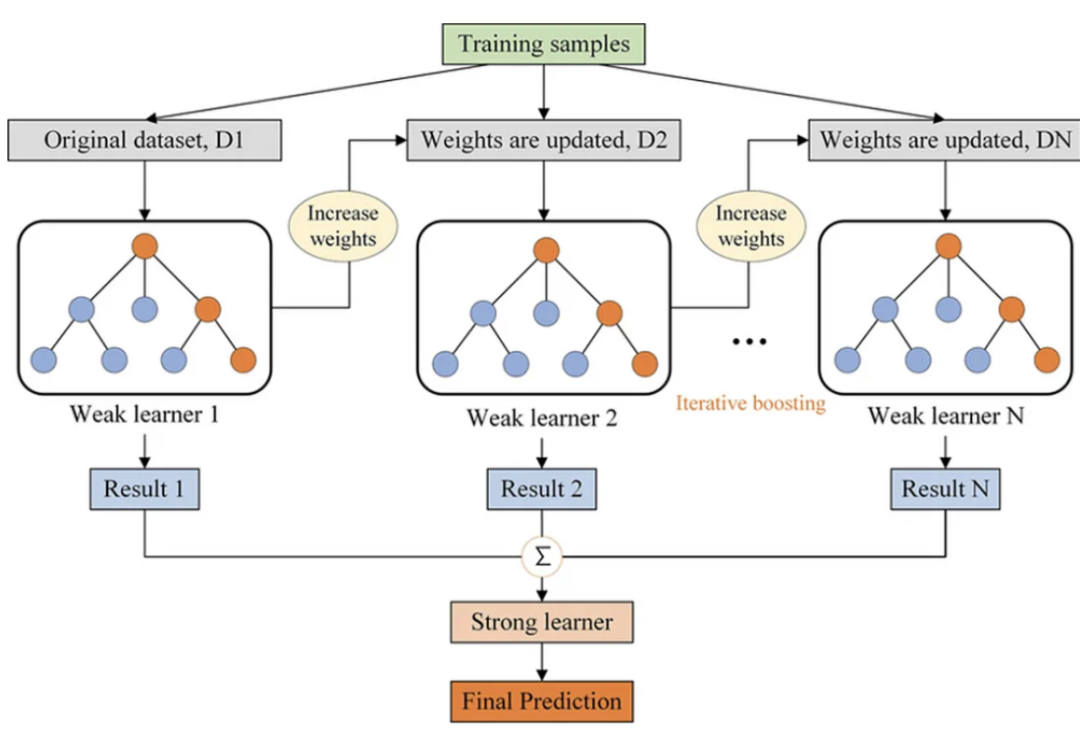
為什么它比決策樹(shù)和隨機(jī)森林更好?
-
減少過(guò)擬合:與隨機(jī)森林一樣,GBDT也避免過(guò)擬合,但它是通過(guò)構(gòu)建淺樹(shù)(弱學(xué)習(xí)器)和優(yōu)化損失函數(shù)來(lái)實(shí)現(xiàn)的,而不是通過(guò)平均或投票。 高效率:GBDT專(zhuān)注于難以分類(lèi)的實(shí)例,更多地適應(yīng)數(shù)據(jù)集的問(wèn)題區(qū)域。這可以使它在分類(lèi)性能方面比隨機(jī)森林更有效,因?yàn)殡S機(jī)森林對(duì)所有實(shí)例都一視同仁。
優(yōu)化損失函數(shù):與啟發(fā)式方法(如基尼指數(shù)或信息增益)不同,GBDT中的損失函數(shù)在訓(xùn)練期間進(jìn)行了優(yōu)化,允許更精確地?cái)M合數(shù)據(jù)。
更好的性能:當(dāng)選擇正確的超參數(shù)時(shí),GBDT通常優(yōu)于隨機(jī)森林,特別是在需要非常精確的模型并且計(jì)算成本不是主要關(guān)注點(diǎn)的情況下。
靈活性:GBDT既可以用于分類(lèi)任務(wù),也可以用于回歸任務(wù),而且它更容易優(yōu)化,因?yàn)槟梢灾苯幼钚』瘬p失函數(shù)。
梯度增強(qiáng)決策樹(shù)解決的問(wèn)題
XGBoost

計(jì)算效率
缺失數(shù)據(jù)的處理
正則化
稀疏性
硬件的優(yōu)化
特征重要性和模型可解釋性
早停策略
處理分類(lèi)變量
XGBoost 2.0有什么新功能?
具有矢量葉輸出的多目標(biāo)樹(shù)
設(shè)備參數(shù)
Hist作為默認(rèn)樹(shù)方法
基于gpu的近似樹(shù)方法
內(nèi)存和緩存優(yōu)化
Learning-to-Rank增強(qiáng)
新的分位數(shù)回歸支持
總結(jié)
評(píng)論
圖片
表情