
AnimateDiff 文本生成視頻
AnimateDiff 是一個(gè)能夠?qū)€(gè)性化的文本轉(zhuǎn)換為動(dòng)態(tài)圖像或視頻(text to video)的擴(kuò)展模型,它可以將生成的靜態(tài)圖像與動(dòng)態(tài)運(yùn)動(dòng)結(jié)合起來,從而創(chuàng)建個(gè)性化的動(dòng)畫圖像。
AnimateDiff 的主要特點(diǎn)是可以適用于大多數(shù)現(xiàn)有的個(gè)性化文本到圖像模型,而無需進(jìn)行特定的調(diào)整和訓(xùn)練。具體來說,AnimateDiff 通過向已經(jīng)固定的基于文本到圖像模型添加一個(gè)新的初始化運(yùn)動(dòng)建模模塊,并在之后對視頻片段進(jìn)行訓(xùn)練,以蒸餾出一個(gè)合理的運(yùn)動(dòng)先驗(yàn)。一旦訓(xùn)練完成,通過簡單地注入這個(gè)運(yùn)動(dòng)建模模塊,所有派生于相同基礎(chǔ)模型的個(gè)性化版本都可以變成文本驅(qū)動(dòng)模型,可以生成多樣且個(gè)性化的文本到視頻動(dòng)畫圖像。 使用 AnimateDiff(tex2vid),您可以將自己的想象力轉(zhuǎn)化為高質(zhì)量的圖像動(dòng)畫,而無需進(jìn)行繁瑣的模型特定調(diào)整。
詳情可查看 AnimateDiff。
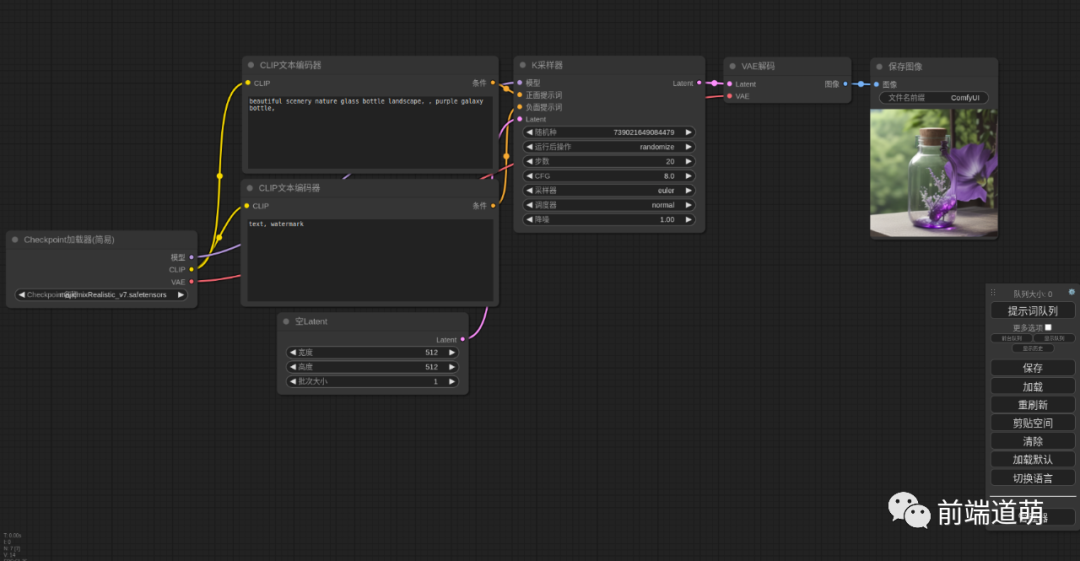
使用 ComfyUI
ComfyUI 是基于節(jié)點(diǎn)流程式的 WebUI, 通過將stable diffusion的流程拆分成節(jié)點(diǎn),實(shí)現(xiàn)了更加精準(zhǔn)的工作流定制和完善的可復(fù)現(xiàn)性。與 a111 相比,ComfyUI有著更快的出圖速度和更小的資源占用,生成大圖片的時(shí)候不會爆顯存。
使用 A111
文本生成視頻:
(masterpiece, best quality),
0:1girl,solo,cherry_blossoms,flower viewing,pink flowers,white flowers,spring,wisteria,petals,flower,plum_blossom,outdoor,falling petals,dark eyes,upper_body,white clothes,purple hair,
16:1girl,solo,lavender,blue sky and white clouds,summer,outdoor,falling rose petals,dark eyes,upper_body,white clothes,purple hair,
32:1girl,solo,orange leaves,yellow leaves,autumn,outdoor,fallen leaves,dark eyes,upper_body,white clothes,purple hair,
48:1girl,solo,plum_blossom,red leaves,winter,outdoor,falling snow,dark eyes,upper_body,white clothes,purple hair,
64:1girl,solo,cherry_blossoms,flower viewing,pink flowers,white flowers,spring,wisteria,petals,flower,plum_blossom,outdoor,falling petals,dark eyes,upper_body,white clothes,purple hair,
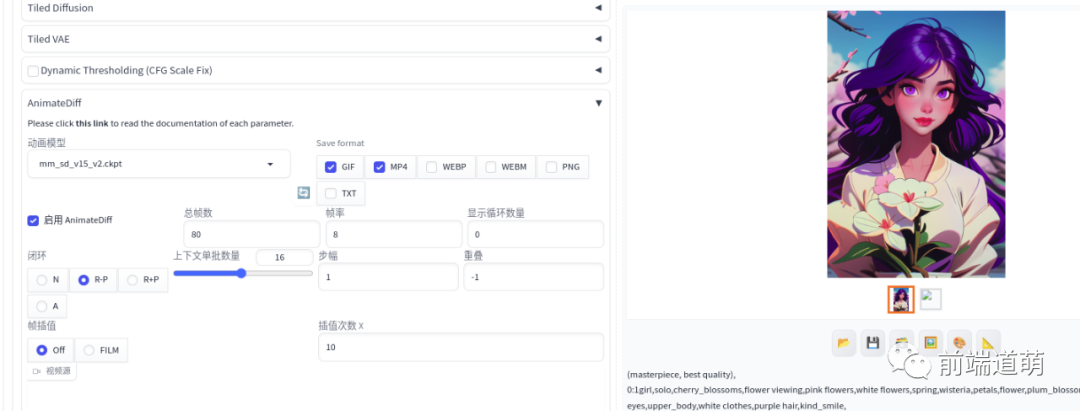
將總幀數(shù)設(shè)為80,幀率為8,就能生成一個(gè)10s的視頻。上述 prompt 每2s(16幀)按照指令變換。
選擇 運(yùn)動(dòng)模型,我使用的 mm_sd_v15_v2,可以配合 lora 來生成動(dòng)畫,如在 propmt 里面添加 ZoomIn 或 PanLeft 等。
保存格式自己選擇,如:GIF 和 MP4。
效果: