
Prompt之文本生成
作者簡介
作者:LaBuenaVida
原文:
https://zhuanlan.zhihu.com/p/521512441
轉(zhuǎn)載者:楊夕
推薦系統(tǒng) 百面百搭地址:
https://github.com/km1994/RES-Interview-Notes
NLP 百面百搭地址:
https://github.com/km1994/NLP-Interview-Notes
個(gè)人筆記:
https://github.com/km1994/nlp_paper_study
NLP && 推薦學(xué)習(xí)群【如果人數(shù)滿了,加微信 blqkm601】
prompt在生成方面的應(yīng)用從兩個(gè)方面進(jìn)行介紹:
評估手段
具體任務(wù)
評估手段
生成任務(wù)的評估手段主要分為四種類型:
1). 基于N-gram匹配 2). 基于編輯距離 3). 基于詞向量 4). 基于可學(xué)習(xí)方式。
本小節(jié)主要介紹BARTSCORE,其使用prompt方式將評估問題轉(zhuǎn)化為文本生成問題的可學(xué)習(xí)方式。
自然語言生成的自動評估的目標(biāo)是評估語義相似性,但通常的方法只是依賴于表面形式的相似性,因此,BERTSCORE借助預(yù)訓(xùn)練模型BERT的embedding來衡量兩個(gè)句子的語義相似性。
BERTSCORE解決了基于N-gram匹配的兩個(gè)問題:
1)、無法魯棒匹配語義;
2)、無法捕捉遠(yuǎn)距離依賴關(guān)系和懲罰重要語義順序的更改。
BARTScore: Evaluating Generated Text as Text
論文鏈接:https://arxiv.org/pdf/2106.11520.pdf
相較于以往的評估方式,在生成評估的背景下,模型如何使用文本生成任務(wù)目標(biāo)進(jìn)行預(yù)訓(xùn)練和如何被使用作為下游任務(wù)的特征提取器之間存在脫節(jié)。這將導(dǎo)致預(yù)訓(xùn)練模型參數(shù)沒有被充分利用。該論文將文本生成的評估問題看作生成問題,能夠從七個(gè)角度評估生成文本的質(zhì)量,并可以通過prompt和fine-tuning來增強(qiáng)BARTSCORE。
BARTSCORE的核心思想為,一個(gè)高質(zhì)量的假設(shè)能夠很容易地基于源文本或參考文本生成,反之亦然。計(jì)算方式如下,wt 為待生成句子中token的權(quán)重(加權(quán)重效果不好):
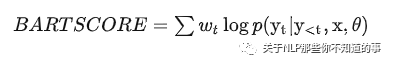
具體計(jì)算含義如下所示:
| Calculation | Implication | Evaluation & Application |
|---|---|---|
| Faithfulness(s->h) | 從source document生成hypothesis的概率 | Factuality,Relevance,Coherence and Fluency |
| Precision(r->h) | 從reference text生成hypothesis的概率 | precision-focused scenario |
| Recall(h->r) | 從hypothesis生成reference text的概率 | semantic coverage |
| F-score(r<->h) | 綜合考慮Precision和Recall | semantic overlap(informativeness,adequacy) |
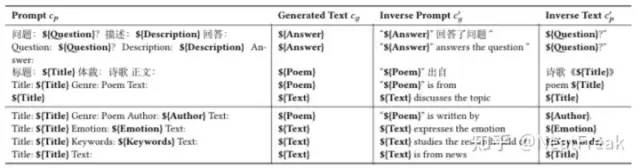
prompt增強(qiáng):對于給定的prompt token:
(i)在source token后添加prompt token:
x = { x 1 , . . . , x n , z 1 , . . . , z l }; (ii)在target token前添加prompt token:
y = { z 1 , . . . , z l , y 1 , . . . , y m } 。prompt的模板集合通過paraphrase重構(gòu)種子模板獲取得到。
fine-tuning 任務(wù):
1). summarization 任務(wù),使用CNNDM數(shù)據(jù)集;
2). paraphrasing任務(wù),使用ParaBank2數(shù)據(jù)集。
在多個(gè)實(shí)驗(yàn)中,BARTSCORE取得了很好的效果,但是引入prompt也有可能會導(dǎo)致效果變差,在事實(shí)性評估角度中,只有少數(shù)的prompt可以提升性能。
具體任務(wù)
本小節(jié)介紹三篇使用prompt進(jìn)行文本生成任務(wù)的論文,涵蓋摘要、QA、詩歌生成、回復(fù)生成多個(gè)任務(wù)。
Generation Planning with Learned Entity Prompts for Abstractive Summarization
論文鏈接:https://arxiv.org/pdf/2103.10685.pdf
該論文通過引入簡單靈活的中間過程來生成摘要,構(gòu)造prompt prefix提示生成對應(yīng)的實(shí)體鏈和摘要,prompt模板為:[ENTITYCHAIN] entity chain [SUMMARY] summary,該方式使模型能夠?qū)W會鏈接生成的摘要和摘要中的實(shí)體鏈。另外,可以通過刪除預(yù)測實(shí)體鏈中的不可靠實(shí)體來生成可靠摘要,更為靈活。
Controllable Generation from Pre-trained Language Models via Inverse Prompting
論文鏈接:https://arxiv.org/pdf/2103.10685.pdf
可控文本中給的提示原不足夠,這導(dǎo)致易在生成過程中逐漸偏離主題,因此該論文提出inverse prompt來更好的控制文本生成,激勵生成文本與prompt之間的聯(lián)系。模型結(jié)構(gòu)如下圖所示:
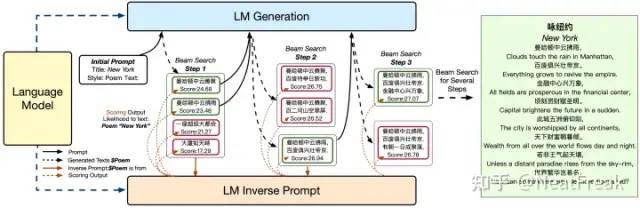
具體做法為:
根據(jù)給定的生成文本構(gòu)造inverse prompt,對應(yīng)圖中表格Inverse Prompt
c g ′ 根據(jù)給定的inverse prompt計(jì)算其原始prompt,對應(yīng)圖中表格Inverse Text
c p ′ 依據(jù)條件似然計(jì)算beam search的分?jǐn)?shù),生成最佳候選。
實(shí)驗(yàn)證明該方法在QA和詩歌生成兩個(gè)任務(wù)上均可以取得很好的效果,能夠給出準(zhǔn)確流利的信息。但同時(shí)也存在數(shù)字輸出混亂和無法理解出現(xiàn)頻率低的詞的問題。
Response Generation with Context-Aware Prompt Learning
論文鏈接:https://arxiv.org/pdf/2111.02643.pdf
該論文設(shè)計(jì)了一個(gè)新穎的動態(tài)prompt編碼器來鼓勵上下文感知的prompt learning,以更好地重利用大規(guī)模預(yù)訓(xùn)練語言模型中的知識并生成更有知識的回復(fù)。模型結(jié)構(gòu)如下圖所示:
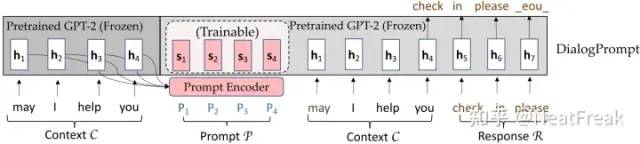
首先將上文文本的embedding送入可學(xué)習(xí)的prompt編碼器中獲得感知上文的prompt編碼表示,再同時(shí)利用prompt的編碼表示和上文文本來預(yù)測下文。論文中實(shí)驗(yàn)證明該方法可以有效利用預(yù)訓(xùn)練語言模型中的知識來促進(jìn)富有知識的高質(zhì)量回復(fù)。