
分享一套 Spark 作業(yè)的性能優(yōu)化方案
這年代,做數(shù)據(jù)的,沒人不知道 Spark 是什么吧。作為最火的大數(shù)據(jù)計(jì)算引擎,現(xiàn)在基本上是各互聯(lián)網(wǎng)大廠的標(biāo)配了。
比如,字節(jié)跳動(dòng)基于 Spark 構(gòu)建的數(shù)據(jù)倉庫,服務(wù)了幾乎所有的產(chǎn)品線,包括抖音、今日頭條、西瓜視頻等。再比如,百度基于 Spark 推出 BigSQL,為海量用戶提供次秒級的即席查詢。可以說,在海量數(shù)據(jù)處理上,Spark 的角色至關(guān)重要。
想到我剛剛接觸 Spark 那會(huì)兒,真心佩服它的開發(fā)效率,是真高啊!MapReduce 上千行代碼才能實(shí)現(xiàn)的業(yè)務(wù)功能,Spark 幾十行代碼就搞定了。
現(xiàn)在就更牛了,去年 6 月,Spark 直接從 2.4 直接升級到了3.0,最大的亮點(diǎn)就在于性能優(yōu)化,它添加了諸如自適應(yīng)查詢執(zhí)行(AQE)、動(dòng)態(tài)分區(qū)剪裁(DPP)、擴(kuò)展的 Join Hints 等新特性。這估計(jì)會(huì)讓 Spark 在未來 5 到 10 年繼續(xù)雄霸大數(shù)據(jù)生態(tài)圈。
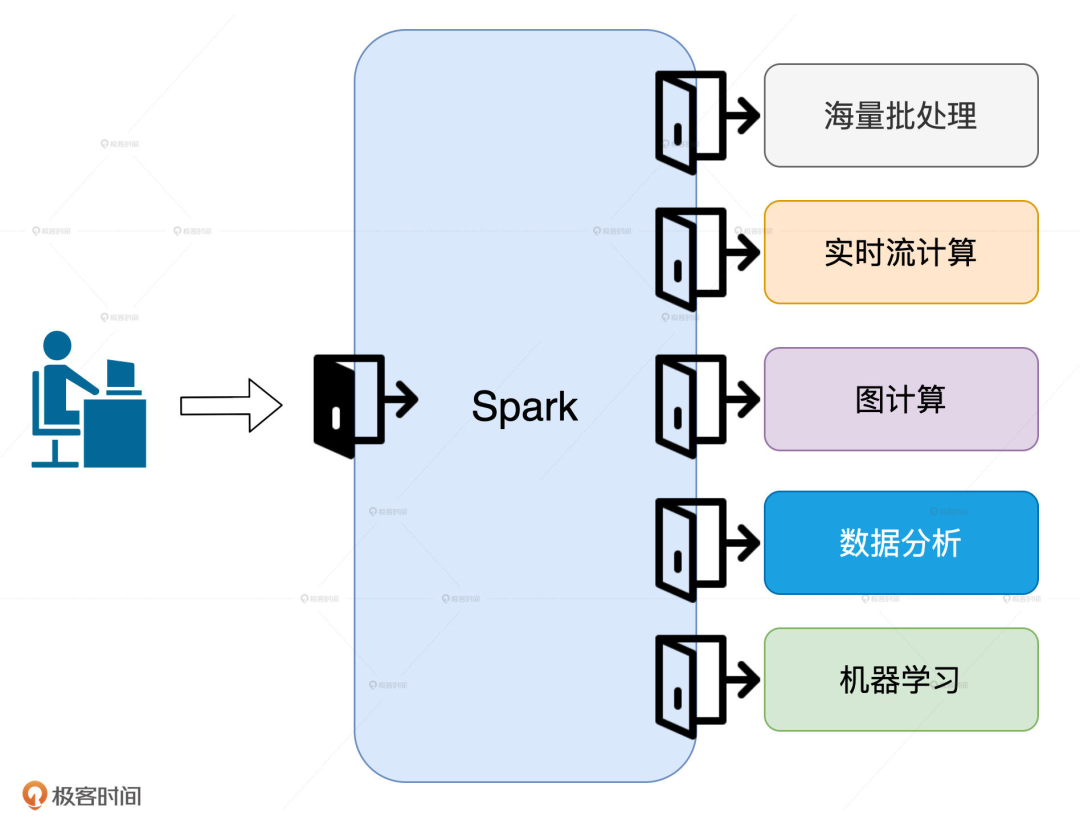
就目前來說,Spark 有海量批處理、實(shí)時(shí)流計(jì)算、圖計(jì)算、數(shù)據(jù)分析和機(jī)器學(xué)習(xí)這 5 大應(yīng)用場景,不論你打算朝哪個(gè)方向深入,「性能調(diào)優(yōu)」都是必須要跨越的一步。
原因很簡單,對于這 5 大場景來說,提高執(zhí)行性能是剛需。想要精通 Spark,就得拿下“性能調(diào)優(yōu)”這把萬能鑰匙。
很多開發(fā)者都意識(shí)到這一點(diǎn),但難就難在,市面上關(guān)于 Spark 性能調(diào)優(yōu)的資料,大都不系統(tǒng),只是在講一些常規(guī)的調(diào)優(yōu)技巧和方法。而對于一些大神分享的調(diào)優(yōu)手段,只是“照葫蘆畫瓢”做出來的東西,也總是達(dá)不到預(yù)期的效果,比如:
明明都是內(nèi)存計(jì)算,為什么我用了 RDD/DataFrame Cache,性能反而更差了?
網(wǎng)上吹得神乎其神的調(diào)優(yōu)手段,為啥到了我這就不好使呢?
并行度設(shè)置得也不低,為啥我的 CPU 利用率還是上不去?
節(jié)點(diǎn)內(nèi)存幾乎全都劃給 Spark 用了,為啥我的應(yīng)用還是 OOM?
這些問題看似簡單,但真不是一兩句話就能說得清的。這需要我們深入Spark的核心原理,不斷去嘗試每一個(gè)API、算子,設(shè)置不同的配置參數(shù),最終找出最佳的排列組合。
說到底,還是需要更多的學(xué)習(xí)案例與實(shí)操。我最近關(guān)注到 FreeWheel 機(jī)器學(xué)習(xí)團(tuán)隊(duì)負(fù)責(zé)人吳磊,總結(jié)了出一套關(guān)于「性能調(diào)優(yōu)的方法論」。挺戳中我的,分享給大家??
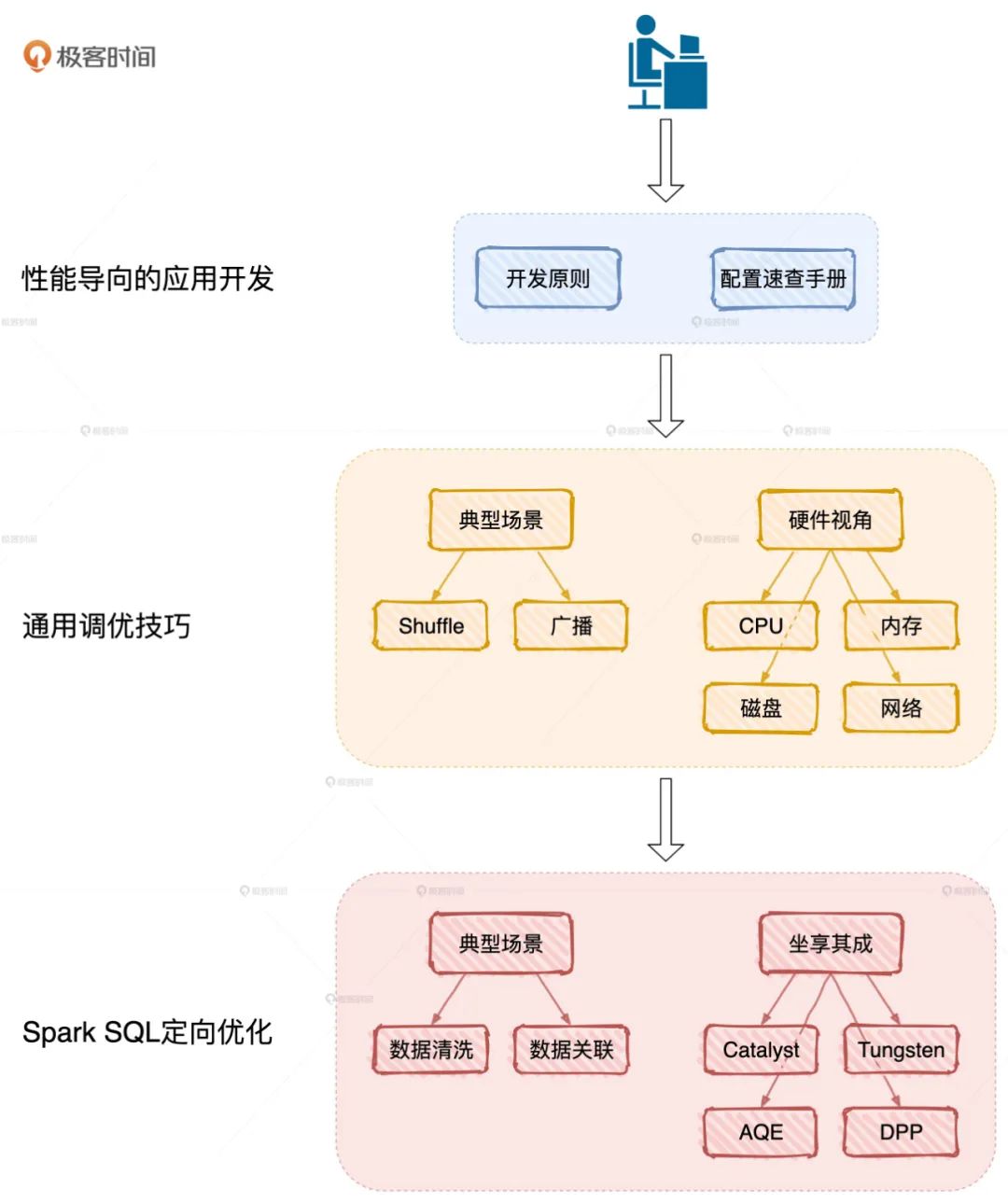
按圖索驥開展性能調(diào)優(yōu)
這張圖來自吳磊的極客時(shí)間專欄《Spark 性能調(diào)優(yōu)實(shí)戰(zhàn)》,剛剛上線,不僅深入淺出的講了 Spark 核心原理,還全面解析 Spark SQL 性能調(diào)優(yōu),總結(jié)了一份應(yīng)用開發(fā)、配置項(xiàng)設(shè)置實(shí)操指南,真心實(shí)用。
最吸引我的是實(shí)操,專欄以「北京市汽油車搖號(hào)」數(shù)據(jù)為例,手把手帶你實(shí)現(xiàn)一個(gè)分布式應(yīng)用。一句話總結(jié),就是能讓你一站式加速 Spark 作業(yè)執(zhí)行性能,是不是很牛。
△ 掃碼免費(fèi)試讀或訂閱
拼團(tuán) + 口令「Happy2021」
立省 ¥30,到手僅 ¥69
更有新人到手價(jià) ¥59.9
作者是吳磊,現(xiàn)任 Comcast Freewheel 機(jī)器學(xué)習(xí)團(tuán)隊(duì)負(fù)責(zé)人,主要負(fù)責(zé)計(jì)算廣告業(yè)務(wù)中機(jī)器學(xué)習(xí)應(yīng)用的實(shí)踐、落地與推廣。之前也任職于 IBM、聯(lián)想研究院、新浪微博,可以說具備豐富的數(shù)據(jù)庫、數(shù)據(jù)倉庫、大數(shù)據(jù)開發(fā)與調(diào)優(yōu)經(jīng)驗(yàn)了。
早之前聽說過他,研究 Spark 是下了功夫的,而且做事兒有股“較真兒”的風(fēng)格,看他上面總結(jié)的方法論圖就知道,是個(gè)嚴(yán)謹(jǐn)、認(rèn)真的人,跟著這樣有實(shí)踐、有理論,懂實(shí)現(xiàn)細(xì)節(jié)的大佬學(xué)習(xí),錯(cuò)不了。
Spark 怎么能“學(xué)得快,還學(xué)得好”?
跟著大佬,能又快又好的學(xué),那就是省“時(shí)間”,找到捷徑、賺到了,目前專欄 3 個(gè)部分的內(nèi)容,干貨不少:
原理篇:聚焦 Spark 底層原理,打通性能調(diào)優(yōu)的任督二脈
Spark 的原理非常多,但專欄聚焦于那些與性能調(diào)優(yōu)息息相關(guān)的核心概念,包括RDD、DAG、調(diào)度系統(tǒng)、存儲(chǔ)系統(tǒng)和內(nèi)存管理。而且用的是最貼切的故事和類比、最少的篇幅,讓你在最短的時(shí)間內(nèi)掌握其核心原理,為后續(xù)的性能調(diào)優(yōu)打下堅(jiān)實(shí)的基礎(chǔ)。
性能篇:實(shí)際案例驅(qū)動(dòng),多角度解讀,全方位解析性能調(diào)優(yōu)技巧
一部分是講解性能調(diào)優(yōu)的通用技巧,包括應(yīng)用開發(fā)的基本原則、配置項(xiàng)的設(shè)置、 Shuffle 的優(yōu)化、資源利用率的提升。另一部分會(huì)專注于數(shù)據(jù)分析領(lǐng)域,借助 Spark內(nèi)置優(yōu)化如 Tungsten、AQE 和典型場景如數(shù)據(jù)關(guān)聯(lián),和你聊聊 Spark SQL 中的調(diào)優(yōu)方法和技巧。
實(shí)戰(zhàn)篇:打造屬于自己的分布式應(yīng)用
專欄以 2011 - 2019 的《北京市汽油車搖號(hào)》數(shù)據(jù)為例,手把手教你打造一個(gè)分布式應(yīng)用,帶你從不同角度洞察汽油車搖號(hào)的趨勢和走向。我相信,通過這個(gè)實(shí)戰(zhàn)案例,你對性能調(diào)優(yōu)技巧和思路的把控肯定會(huì)有一個(gè)“質(zhì)的飛躍”。
除此之外,聽說吳磊還會(huì)不定期地針對熱點(diǎn)話題加餐,比如和 Flink、Presto 相比,Spark 有哪些優(yōu)勢,再比如 Spark 的一些新特性,以及業(yè)界對于 Spark 的新探索。這也能幫助我們更好地面對變化,把握先機(jī)。
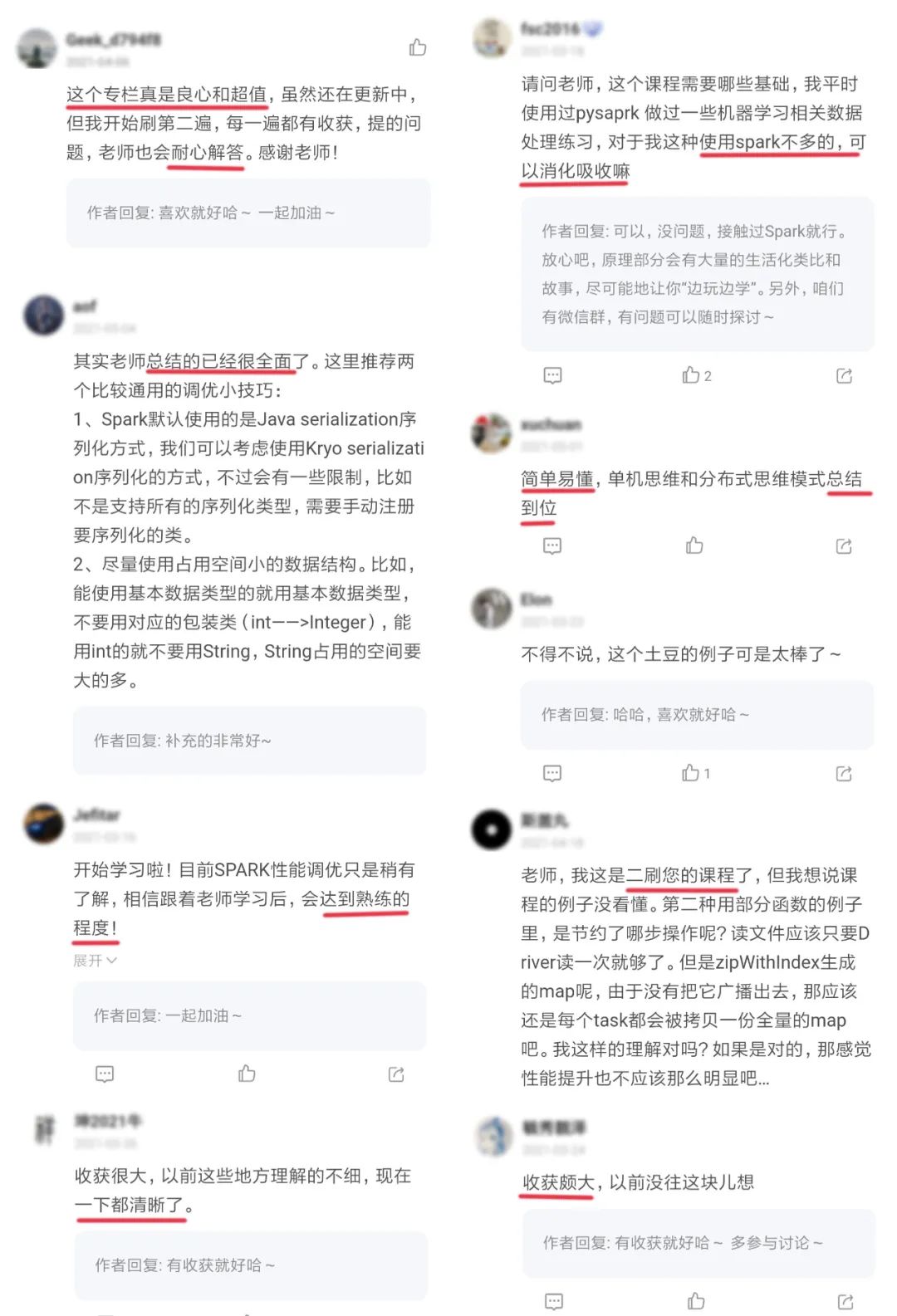
吳磊很有耐心,可以說每條留言都回復(fù)。說實(shí)話,評論區(qū)都能學(xué)到不少東西,口碑有多好,我說了不算,截了一些評價(jià)供你參考:
不僅如此,我們還有一個(gè)特別活躍的 Spark 交流群,群友們每天都在群里互相交流技術(shù)心得,平時(shí)在群里也能漲知識(shí)。
專欄的目錄我也放到這兒了,看著感覺很不錯(cuò),理論和實(shí)踐相結(jié)合。

在現(xiàn)在大數(shù)據(jù)技術(shù)領(lǐng)域,基本上是 Spark 形成了一家獨(dú)大的局面,所以該抓住機(jī)會(huì)學(xué)習(xí)的,還得學(xué)。
再提醒下,原價(jià) ¥99
結(jié)算時(shí)用優(yōu)惠口令「Happy2021」
立省 ¥30,到手僅 ¥69
新人到手價(jià) ¥59.9
走心的努力,才算真的努力。2 杯奶茶的價(jià)格,拿下這套 Spark 性能調(diào)優(yōu)方法論,值了??