
Mask-RCNN最詳細解讀

作者:stone
https://zhuanlan.zhihu.com/p/37998710
本文已授權,未經允許,不得二次轉載
最近在做一個目標檢測項目,用到了Mask RCNN。我僅僅用了50張訓練照片,訓練了1000步之后進行測試,發(fā)現(xiàn)效果好得令人稱奇。就這個任務,很久之前用yolo v1訓練則很難收斂。不過把它們拿來比當然不公平,但我更想說的是,mask RCNN效果真的很好。
所以這篇文章來詳細地總結一下Mask RCNN。
Mask RCNN沿用了Faster RCNN的思想,特征提取采用ResNet-FPN的架構,另外多加了一個Mask預測分支。可見Mask RCNN綜合了很多此前優(yōu)秀的研究成果。為了更好地講解Mask RCNN,我會先回顧一下幾個部分:
Faster RCNN
ResNet-FPN
ResNet-FPN+Fast RCNN
回顧完之后講ResNet-FPN+Fast RCNN+Mask,實際上就是Mask RCNN。
一、Faster RCNN
Faster RCNN是兩階段的目標檢測算法,包括階段一的Region proposal以及階段二的bounding box回歸和分類。用一張圖來直觀展示Faster RCNN的整個流程:
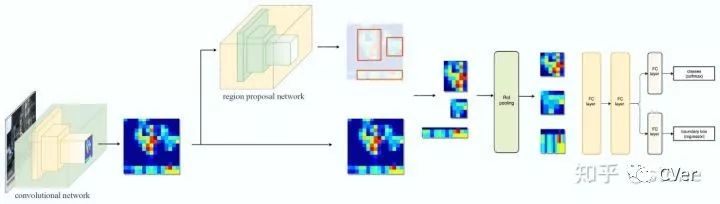
Faster RCNN使用CNN提取圖像特征,然后使用region proposal network(RPN)去提取出ROI,然后使用ROI pooling將這些ROI全部變成固定尺寸,再喂給全連接層進行Bounding box回歸和分類預測。
這里只是簡單地介紹了Faster RCNN前向預測的過程,但Faster RCNN本身的細節(jié)非常多,比一階段的算法復雜度高不少,并非三言兩語能說得清。如果對Faster RCNN算法不熟悉,想了解更多的同學可以看這篇文章:一文讀懂Faster RCNN,這是我看過的解釋得最清晰的文章。link:https://zhuanlan.zhihu.com/p/31426458
二、ResNet-FPN
多尺度檢測在目標檢測中變得越來越重要,對小目標的檢測尤其如此。現(xiàn)在主流的目標檢測方法很多都用到了多尺度的方法,包括最新的yolo v3。Feature Pyramid Network (FPN)則是一種精心設計的多尺度檢測方法,下面就開始簡要介紹FPN。
FPN結構中包括自下而上,自上而下和橫向連接三個部分,如下圖所示。這種結構可以將各個層級的特征進行融合,使其同時具有強語義信息和強空間信息,在特征學習中算是一把利器了。
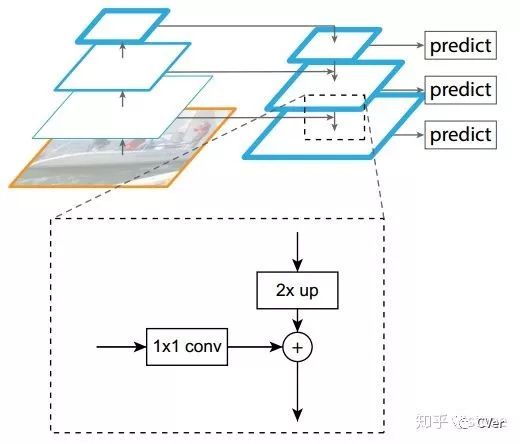
FPN實際上是一種通用架構,可以結合各種骨架網(wǎng)絡使用,比如VGG,ResNet等。Mask RCNN文章中使用了ResNNet-FPN網(wǎng)絡結構。如下圖:

ResNet-FPN包括3個部分,自下而上連接,自上而下連接和橫向連接。下面分別介紹。
自下而上
從下到上路徑。可以明顯看出,其實就是簡單的特征提取過程,和傳統(tǒng)的沒有區(qū)別。具體就是將ResNet作為骨架網(wǎng)絡,根據(jù)feature map的大小分為5個stage。stage2,stage3,stage4和stage5各自最后一層輸出conv2,conv3,conv4和conv5分別定義為? ?,他們相對于原始圖片的stride是{4,8,16,32}。需要注意的是,考慮到內存原因,stage1的conv1并沒有使用。
?,他們相對于原始圖片的stride是{4,8,16,32}。需要注意的是,考慮到內存原因,stage1的conv1并沒有使用。
自上而下和橫向連接
自上而下是從最高層開始進行上采樣,這里的上采樣直接使用的是最近鄰上采樣,而不是使用反卷積操作,一方面簡單,另外一方面可以減少訓練參數(shù)。橫向連接則是將上采樣的結果和自底向上生成的相同大小的feature map進行融合。具體就是對??中的每一層經過一個conv 1x1操作(1x1卷積用于降低通道數(shù)),無激活函數(shù)操作,輸出通道全部設置為相同的256通道,然后和上采樣的feature map進行加和操作。在融合之后還會再采用3*3的卷積核對已經融合的特征進行處理,目的是消除上采樣的混疊效應(aliasing effect)。
實際上,上圖少繪制了一個分支:M5經過步長為2的max pooling下采樣得到 P6,作者指出使用P6是想得到更大的anchor尺度512×512。但P6是只用在 RPN中用來得到region proposal的,并不會作為后續(xù)Fast RCNN的輸入。
總結一下,ResNet-FPN作為RPN輸入的feature map是? ?,而作為后續(xù)Fast RCNN的輸入則是?
?,而作為后續(xù)Fast RCNN的輸入則是? ?。
?。
三、ResNet-FPN+Fast RCNN
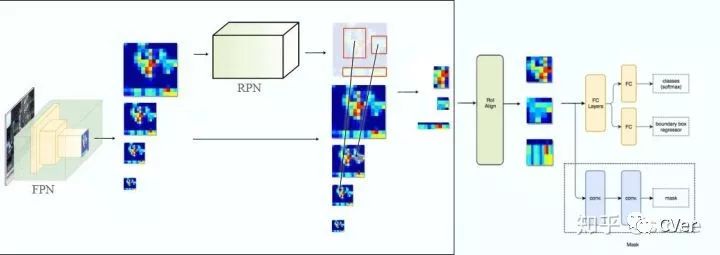
將ResNet-FPN和Fast RCNN進行結合,實際上就是Faster RCNN的了,但與最初的Faster RCNN不同的是,F(xiàn)PN產生了特征金字塔??,而并非只是一個feature map。金字塔經過RPN之后會產生很多region proposal。這些region proposal是分別由? ?經過RPN產生的,但用于輸入到Fast RCNN中的是?,也就是說要在??中根據(jù)region proposal切出ROI進行后續(xù)的分類和回歸預測。問題來了,我們要選擇哪個feature map來切出這些ROI區(qū)域呢?實際上,我們會選擇最合適的尺度的feature map來切ROI。具體來說,我們通過一個公式來決定寬w和高h的ROI到底要從哪個
?經過RPN產生的,但用于輸入到Fast RCNN中的是?,也就是說要在??中根據(jù)region proposal切出ROI進行后續(xù)的分類和回歸預測。問題來了,我們要選擇哪個feature map來切出這些ROI區(qū)域呢?實際上,我們會選擇最合適的尺度的feature map來切ROI。具體來說,我們通過一個公式來決定寬w和高h的ROI到底要從哪個 ?來切:
?來切:
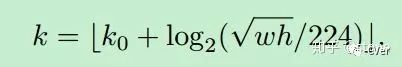
這里224表示用于預訓練的ImageNet圖片的大小。? ?表示面積為?
?表示面積為? ?的ROI所應該在的層級。作者將??設置為4,也就是說??的ROI應該從?
?的ROI所應該在的層級。作者將??設置為4,也就是說??的ROI應該從? ?中切出來。假設ROI的scale小于224(比如說是112 * 112),?
?中切出來。假設ROI的scale小于224(比如說是112 * 112),? ?,就意味著要從更高分辨率的?
?,就意味著要從更高分辨率的? ?中產生。另外 k 值會做取整處理,防止結果不是整數(shù)。
?中產生。另外 k 值會做取整處理,防止結果不是整數(shù)。
這種做法很合理,大尺度的ROI要從低分辨率的feature map上切,有利于檢測大目標,小尺度的ROI要從高分辨率的feature map上切,有利于檢測小目標。
四、ResNet-FPN+Fast RCNN+mask
我們再進一步,將ResNet-FPN+Fast RCNN+mask,則得到了最終的Mask RCNN,如下圖:
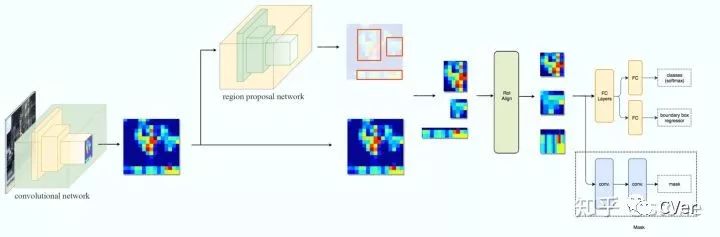
Mask RCNN的構建很簡單,只是在ROI pooling(實際上用到的是ROIAlign,后面會講到)之后添加卷積層,進行mask預測的任務。
下面總結一下Mask RCNN的網(wǎng)絡:
骨干網(wǎng)絡ResNet-FPN,用于特征提取,另外,ResNet還可以是:ResNet-50,ResNet-101,ResNeXt-50,ResNeXt-101;
頭部網(wǎng)絡,包括邊界框識別(分類和回歸)+mask預測。頭部結構見下圖:
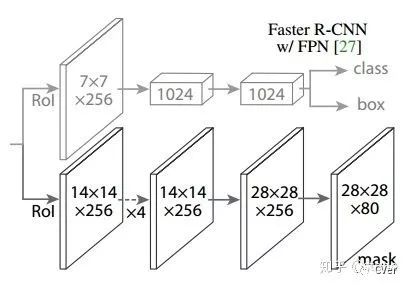
五、ROI Align
實際上,Mask RCNN中還有一個很重要的改進,就是ROIAlign。Faster R-CNN存在的問題是:特征圖與原始圖像是不對準的(mis-alignment),所以會影響檢測精度。而Mask R-CNN提出了RoIAlign的方法來取代ROI pooling,RoIAlign可以保留大致的空間位置。
為了講清楚ROI Align,這里先插入兩個知識,雙線性插值和ROI pooling。
1.雙線性插值
在講雙線性插值之前,還得看最簡單的線性插值。
線性插值
已知數(shù)據(jù)? ?與?
?與? ?,要計算?
?,要計算? ?區(qū)間內某一位置?
?區(qū)間內某一位置? ?在直線上的?
?在直線上的? ?值,如下圖所示。
?值,如下圖所示。

計算方法很簡單,通過斜率相等就可以構建y和x之間的關系,如下: ?
?
仔細看就是用??和? ?,?
?,? ?的距離作為一個權重(除以?
?的距離作為一個權重(除以? ?是歸一化的作用),用于?
?是歸一化的作用),用于? ?和?
?和? ?的加權。這個思想很重要,因為知道了這個思想,理解雙線性插值就非常簡單了。
?的加權。這個思想很重要,因為知道了這個思想,理解雙線性插值就非常簡單了。
雙線性插值
雙線性插值本質上就是在兩個方向上做線性插值。
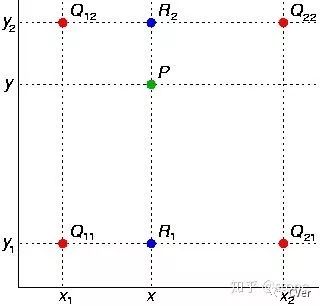
如圖,假設我們想得到P點的插值,我們可以先在x方向上,對? ?和?
?和? ?之間做線性插值得到?
?之間做線性插值得到? ?,
?, ?同理可得。然后在y方向上對??和??進行線性插值就可以得到最終的P。其實知道這個就已經理解了雙線性插值的意思了,如果用公式表達則如下(注意?
?同理可得。然后在y方向上對??和??進行線性插值就可以得到最終的P。其實知道這個就已經理解了雙線性插值的意思了,如果用公式表達則如下(注意? ?前面的系數(shù)看成權重就很好理解了)。
?前面的系數(shù)看成權重就很好理解了)。
首先在?x?方向進行線性插值,得到
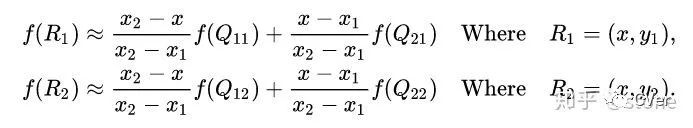
然后在?y?方向進行線性插值,得到
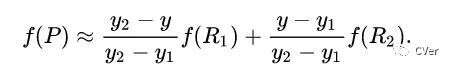
這樣就得到所要的結果? ?
?

參考:維基百科:雙線性插值
https://zh.wikipedia.org/wiki/%E5%8F%8C%E7%BA%BF%E6%80%A7%E6%8F%92%E5%80%BC
2.ROIpooling
ROI pooling就不多解釋了,直接通過一個例子來形象理解。假設現(xiàn)在我們有一個8x8大小的feature map,我們要在這個feature map上得到ROI,并且進行ROI pooling到2x2大小的輸出。

假設ROI的bounding box為? ?。如圖:
?。如圖:
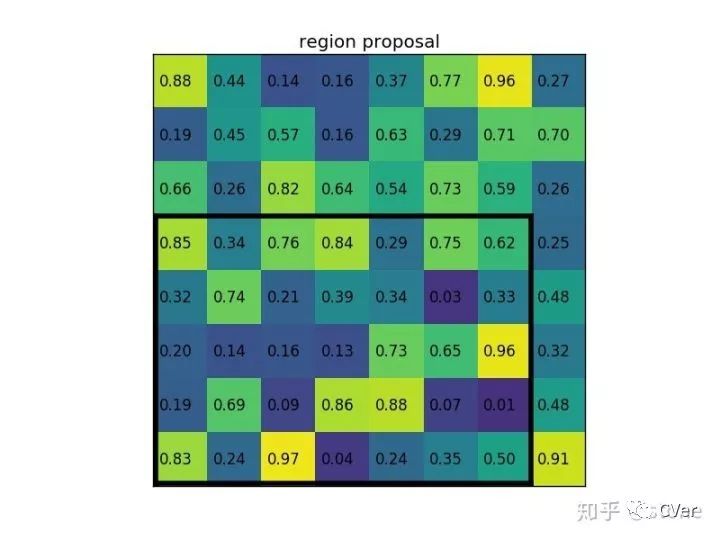
將它劃分為2x2的網(wǎng)格,因為ROI的長寬除以2是不能整除的,所以會出現(xiàn)每個格子大小不一樣的情況。
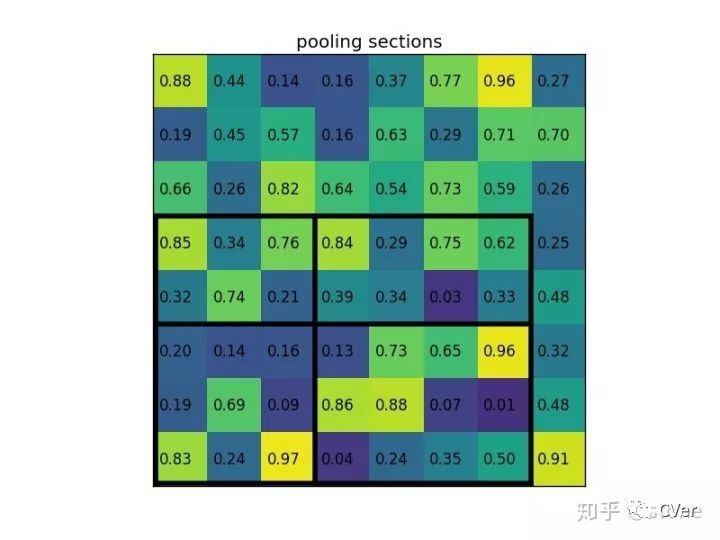
進行max pooling的最終2x2的輸出為:
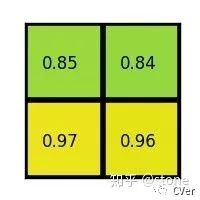
最后以一張動圖形象概括之:

參考:Region of interest pooling explained
https://deepsense.ai/region-of-interest-pooling-explained/
3. ROI Align
在Faster RCNN中,有兩次整數(shù)化的過程:
region proposal的xywh通常是小數(shù),但是為了方便操作會把它整數(shù)化。
將整數(shù)化后的邊界區(qū)域平均分割成 k x k 個單元,對每一個單元的邊界進行整數(shù)化。
兩次整數(shù)化的過程如下圖所示:

事實上,經過上述兩次整數(shù)化,此時的候選框已經和最開始回歸出來的位置有一定的偏差,這個偏差會影響檢測或者分割的準確度。在論文里,作者把它總結為“不匹配問題”(misalignment)。
為了解決這個問題,ROI Align方法取消整數(shù)化操作,保留了小數(shù),使用以上介紹的雙線性插值的方法獲得坐標為浮點數(shù)的像素點上的圖像數(shù)值。但在實際操作中,ROI Align并不是簡單地補充出候選區(qū)域邊界上的坐標點,然后進行池化,而是重新進行設計。
下面通過一個例子來講解ROI Align操作。如下圖所示,虛線部分表示feature map,實線表示ROI,這里將ROI切分成2x2的單元格。如果采樣點數(shù)是4,那我們首先將每個單元格子均分成四個小方格(如紅色線所示),每個小方格中心就是采樣點。這些采樣點的坐標通常是浮點數(shù),所以需要對采樣點像素進行雙線性插值(如四個箭頭所示),就可以得到該像素點的值了。然后對每個單元格內的四個采樣點進行maxpooling,就可以得到最終的ROIAlign的結果。

需要說明的是,在相關實驗中,作者發(fā)現(xiàn)將采樣點設為4會獲得最佳性能,甚至直接設為1在性能上也相差無幾。事實上,ROI Align 在遍歷取樣點的數(shù)量上沒有ROIPooling那么多,但卻可以獲得更好的性能,這主要歸功于解決了misalignment的問題。
六、損失
Mask RCNN定義多任務損失:

 和?
和? ?與faster rcnn的定義沒有區(qū)別。需要具體說明的是?
?與faster rcnn的定義沒有區(qū)別。需要具體說明的是? ?,假設一共有K個類別,則mask分割分支的輸出維度是?
?,假設一共有K個類別,則mask分割分支的輸出維度是? ?, 對于?
?, 對于? ?中的每個點,都會輸出K個二值Mask(每個類別使用sigmoid輸出)。需要注意的是,計算loss的時候,并不是每個類別的sigmoid輸出都計算二值交叉熵損失,而是該像素屬于哪個類,哪個類的sigmoid輸出才要計算損失(如圖紅色方形所示)。并且在測試的時候,我們是通過分類分支預測的類別來選擇相應的mask預測。這樣,mask預測和分類預測就徹底解耦了。
?中的每個點,都會輸出K個二值Mask(每個類別使用sigmoid輸出)。需要注意的是,計算loss的時候,并不是每個類別的sigmoid輸出都計算二值交叉熵損失,而是該像素屬于哪個類,哪個類的sigmoid輸出才要計算損失(如圖紅色方形所示)。并且在測試的時候,我們是通過分類分支預測的類別來選擇相應的mask預測。這樣,mask預測和分類預測就徹底解耦了。
這與FCN方法是不同,F(xiàn)CN是對每個像素進行多類別softmax分類,然后計算交叉熵損失,很明顯,這種做法是會造成類間競爭的,而每個類別使用sigmoid輸出并計算二值損失,可以避免類間競爭。實驗表明,通過這種方法,可以較好地提升性能。
七、代碼
我用到的代碼是github上star最多的Mask RCNN代碼:Mask R-CNN for object detection and instance segmentation on Keras and TensorFlow
https://github.com/matterport/Mask_RCNN
由于篇幅所限,不會在本文中講解代碼。但會由我的一個同事(?@深度眸知乎用戶)視頻講解,視頻即將錄制,錄好之后我會把視頻鏈接發(fā)在這里,感興趣的可以關注。如果對視頻內容有什么需求,歡迎留言。
參考
文章中有些圖片來自medium博主:Jonathan Hui
