
如何構(gòu)建一個通用的Python爬蟲平臺?
閱讀本文大約需要15~20分鐘。? 本文章內(nèi)容較多,非常干貨!如果手機(jī)閱讀體驗(yàn)不好,建議先收藏后到 PC 端閱讀。
之前做爬蟲時,在公司設(shè)計(jì)開發(fā)了一個通用的垂直爬蟲平臺,后來在公司做了內(nèi)部的技術(shù)分享,這篇文章把整個爬蟲平臺的設(shè)計(jì)思路整理了一下,分享給大家。
爬蟲簡介
網(wǎng)絡(luò)爬蟲(又被稱為網(wǎng)頁蜘蛛,網(wǎng)絡(luò)機(jī)器人),是一種按照一定的規(guī)則,自動地抓取網(wǎng)頁信息的程序或者腳本。
通用爬蟲(搜索引擎) 垂直爬蟲(特定領(lǐng)域)
如何寫爬蟲
簡單爬蟲
#?coding:?utf8
"""簡單爬蟲"""
import?requests
from?lxml?import?etree
def?main():
????#?1.?定義頁面URL和解析規(guī)則
????crawl_urls?=?[
????????'https://book.douban.com/subject/25862578/',
????????'https://book.douban.com/subject/26698660/',
????????'https://book.douban.com/subject/2230208/'
????]
????parse_rule?=?"http://div[@id='wrapper']/h1/span/text()"
????for?url?in?crawl_urls:
????????#?2.?發(fā)起HTTP請求
????????response?=?requests.get(url)
????????#?3.?解析HTML
????????result?=?etree.HTML(response.text).xpath(parse_rule)[0]
????????#?4.?保存結(jié)果
????????print?result
if?__name__?==?'__main__':
????main()
定義頁面URL和解析規(guī)則 發(fā)起HTTP請求 解析HTML,拿到數(shù)據(jù) 保存數(shù)據(jù)
異步爬蟲
#?coding:?utf8
"""協(xié)程版本爬蟲,提高抓取效率"""
from?gevent?import?monkey
monkey.patch_all()
import?requests
from?lxml?import?etree
from?gevent.pool?import?Pool
def?main():
????#?1.?定義頁面URL和解析規(guī)則
????crawl_urls?=?[
????????'https://book.douban.com/subject/25862578/',
????????'https://book.douban.com/subject/26698660/',
????????'https://book.douban.com/subject/2230208/'
????]
????rule?=?"http://div[@id='wrapper']/h1/span/text()"
????#?2.?抓取
????pool?=?Pool(size=10)
????for?url?in?crawl_urls:
????????pool.spawn(crawl,?url,?rule)
????pool.join()
def?crawl(url,?rule):
????#?3.?發(fā)起HTTP請求
????response?=?requests.get(url)
????#?4.?解析HTML
????result?=?etree.HTML(response.text).xpath(rule)[0]
????#?5.?保存結(jié)果
????print?result
if?__name__?==?'__main__':
????main()
整站爬蟲
#?coding:?utf8
"""整站爬蟲"""
from?gevent?import?monkey
monkey.patch_all()
from?urlparse?import?urljoin
import?requests
from?lxml?import?etree
from?gevent.pool?import?Pool
from?gevent.queue?import?Queue
base_url?=?'https://book.douban.com'
#?種子URL
start_url?=?'https://book.douban.com/tag/?view=type&icn=index-sorttags-all'
#?解析規(guī)則
rules?=?{
????#?標(biāo)簽頁列表
????'list_urls':?"http://table[@class='tagCol']/tbody/tr/td/a/@href",
????#?詳情頁列表
????'detail_urls':?"http://li[@class='subject-item']/div[@class='info']/h2/a/@href",
????#?頁碼
????'page_urls':?"http://div[@id='subject_list']/div[@class='paginator']/a/@href",
????#?書名
????'title':?"http://div[@id='wrapper']/h1/span/text()",
}
#?定義隊(duì)列
list_queue?=?Queue()
detail_queue?=?Queue()
#?定義協(xié)程池
pool?=?Pool(size=10)
def?crawl(url):
????"""首頁"""
????response?=?requests.get(url)
????list_urls?=?etree.HTML(response.text).xpath(rules['list_urls'])
????for?list_url?in?list_urls:
????????list_queue.put(urljoin(base_url,?list_url))
def?list_loop():
????"""采集列表頁"""
????while?True:
????????list_url?=?list_queue.get()
????????pool.spawn(crawl_list_page,?list_url)
def?detail_loop():
????"""采集詳情頁"""
????while?True:
????????detail_url?=?detail_queue.get()
????????pool.spawn(crawl_detail_page,?detail_url)
def?crawl_list_page(list_url):
????"""采集列表頁"""
????html?=?requests.get(list_url).text
????detail_urls?=?etree.HTML(html).xpath(rules['detail_urls'])
????#?詳情頁
????for?detail_url?in?detail_urls:
????????detail_queue.put(urljoin(base_url,?detail_url))
????#?下一頁
????list_urls?=?etree.HTML(html).xpath(rules['page_urls'])
????for?list_url?in?list_urls:
????????list_queue.put(urljoin(base_url,?list_url))
def?crawl_detail_page(list_url):
????"""采集詳情頁"""
????html?=?requests.get(list_url).text
????title?=?etree.HTML(html).xpath(rules['title'])[0]
????print?title
def?main():
????#?1.?標(biāo)簽頁
????crawl(start_url)
????#?2.?列表頁
????pool.spawn(list_loop)
????#?3.?詳情頁
????pool.spawn(detail_loop)
????#?開始采集
????pool.join()
if?__name__?==?'__main__':
????main()
找到入口,也就是從書籍標(biāo)簽頁進(jìn)入,提取所有標(biāo)簽 URL 進(jìn)入每個標(biāo)簽頁,提取所有列表 URL 進(jìn)入每個列表頁,提取每一頁的詳情URL和下一頁列表 URL 進(jìn)入每個詳情頁,拿到書籍信息 如此往復(fù)循環(huán),直到數(shù)據(jù)抓取完畢
防反爬的整站爬蟲
#?coding:?utf8
"""防反爬的整站爬蟲"""
from?gevent?import?monkey
monkey.patch_all()
import?random
from?urlparse?import?urljoin
import?requests
from?lxml?import?etree
import?gevent
from?gevent.pool?import?Pool
from?gevent.queue?import?Queue
base_url?=?'https://book.douban.com'
#?種子URL
start_url?=?'https://book.douban.com/tag/?view=type&icn=index-sorttags-all'
#?解析規(guī)則
rules?=?{
????#?標(biāo)簽頁列表
????'list_urls':?"http://table[@class='tagCol']/tbody/tr/td/a/@href",
????#?詳情頁列表
????'detail_urls':?"http://li[@class='subject-item']/div[@class='info']/h2/a/@href",
????#?頁碼
????'page_urls':?"http://div[@id='subject_list']/div[@class='paginator']/a/@href",
????#?書名
????'title':?"http://div[@id='wrapper']/h1/span/text()",
}
#?定義隊(duì)列
list_queue?=?Queue()
detail_queue?=?Queue()
#?定義協(xié)程池
pool?=?Pool(size=10)
#?定義代理池
proxy_list?=?[
????'118.190.147.92:15524',
????'47.92.134.176:17141',
????'119.23.32.38:20189',
]
#?定義UserAgent
user_agent_list?=?[
????'Mozilla/5.0?(Windows?NT?6.1)?AppleWebKit/537.36?(KHTML,?like?Gecko)?Chrome/41.0.2228.0?Safari/537.36',
????'Mozilla/5.0?(Windows?NT?6.1;?WOW64;?rv:40.0)?Gecko/20100101?Firefox/40.1',
????'Mozilla/5.0?(Macintosh;?Intel?Mac?OS?X?10_9_3)?AppleWebKit/537.75.14?(KHTML,?like?Gecko)?Version/7.0.3?Safari/7046A194A',
????'Mozilla/5.0?(Windows?NT?6.1;?WOW64;?Trident/7.0;?AS;?rv:11.0)?like?Gecko',
]
def?fetch(url):
????"""發(fā)起HTTP請求"""
????proxies?=?random.choice(proxy_list)
????user_agent?=?random.choice(user_agent_list)
????headers?=?{'User-Agent':?user_agent}
????html?=?requests.get(url,?headers=headers,?proxies=proxies).text
????return?html
def?parse(html,?rule):
????"""解析頁面"""
????return?etree.HTML(html).xpath(rule)
def?crawl(url):
????"""首頁"""
????html?=?fetch(url)
????list_urls?=?parse(html,?rules['list_urls'])
????for?list_url?in?list_urls:
????????list_queue.put(urljoin(base_url,?list_url))
def?list_loop():
????"""采集列表頁"""
????while?True:
????????list_url?=?list_queue.get()
????????pool.spawn(crawl_list_page,?list_url)
def?detail_loop():
????"""采集詳情頁"""
????while?True:
????????detail_url?=?detail_queue.get()
????????pool.spawn(crawl_detail_page,?detail_url)
def?crawl_list_page(list_url):
????"""采集列表頁"""
????html?=?fetch(list_url)
????detail_urls?=?parse(html,?rules['detail_urls'])
????#?詳情頁
????for?detail_url?in?detail_urls:
????????detail_queue.put(urljoin(base_url,?detail_url))
????#?下一頁
????list_urls?=?parse(html,?rules['page_urls'])
????for?list_url?in?list_urls:
????????list_queue.put(urljoin(base_url,?list_url))
def?crawl_detail_page(list_url):
????"""采集詳情頁"""
????html?=?fetch(list_url)
????title?=?parse(html,?rules['title'])[0]
????print?title
def?main():
????#?1.?首頁
????crawl(start_url)
????#?2.?列表頁
????pool.spawn(list_loop)
????#?3.?詳情頁
????pool.spawn(detail_loop)
????#?開始采集
????pool.join()
if?__name__?==?'__main__':
????main()
現(xiàn)有問題
爬蟲腳本繁多,管理和維護(hù)困難 爬蟲規(guī)則定義零散,可能會重復(fù)開發(fā) 爬蟲都是后臺腳本,沒有監(jiān)控 爬蟲腳本輸出的數(shù)據(jù)格式不統(tǒng)一,可能是文件,也可能也數(shù)據(jù)庫 業(yè)務(wù)要想使用爬蟲的數(shù)據(jù)比較困難,沒有統(tǒng)一的對接入口
平臺架構(gòu)
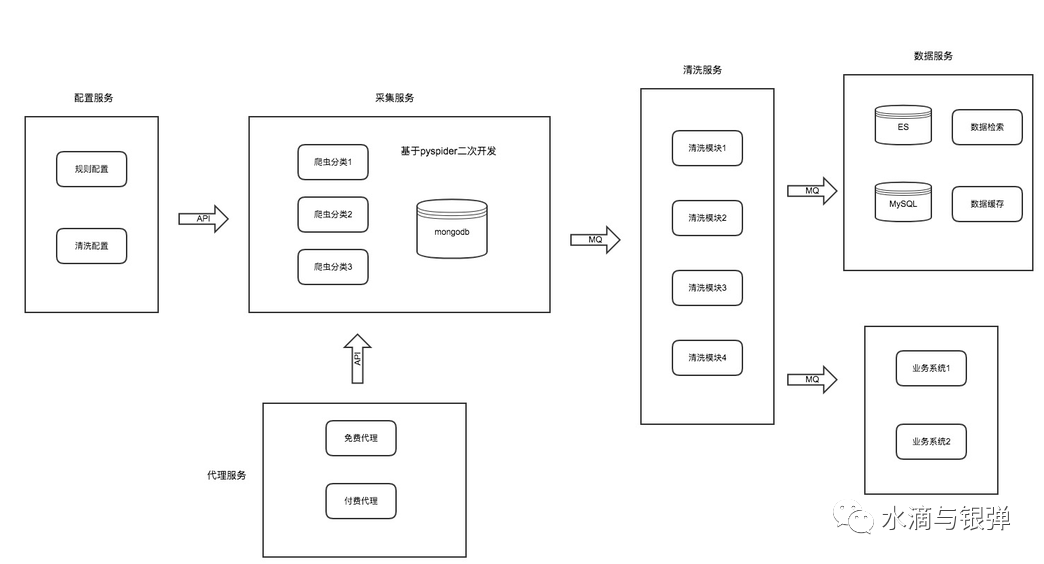
配置服務(wù):包括抓取頁面配置、解析規(guī)則配置、數(shù)據(jù)清洗配置 采集服務(wù):只專注網(wǎng)頁的下載,并配置防爬策略 代理服務(wù):持續(xù)提供穩(wěn)定、可用的代理 IP 清洗服務(wù):針對爬蟲采集到的數(shù)據(jù)進(jìn)行進(jìn)一步清洗和規(guī)整 數(shù)據(jù)服務(wù):爬蟲數(shù)據(jù)的展示,以及業(yè)務(wù)系統(tǒng)對接
詳細(xì)設(shè)計(jì)
配置服務(wù)
正則解析規(guī)則 CSS解析規(guī)則 XPATH解析規(guī)則
采集服務(wù)
支持分布式 配置可視化 可周期采集 支持優(yōu)先級 任務(wù)可監(jiān)控
pyspider架構(gòu)圖如下: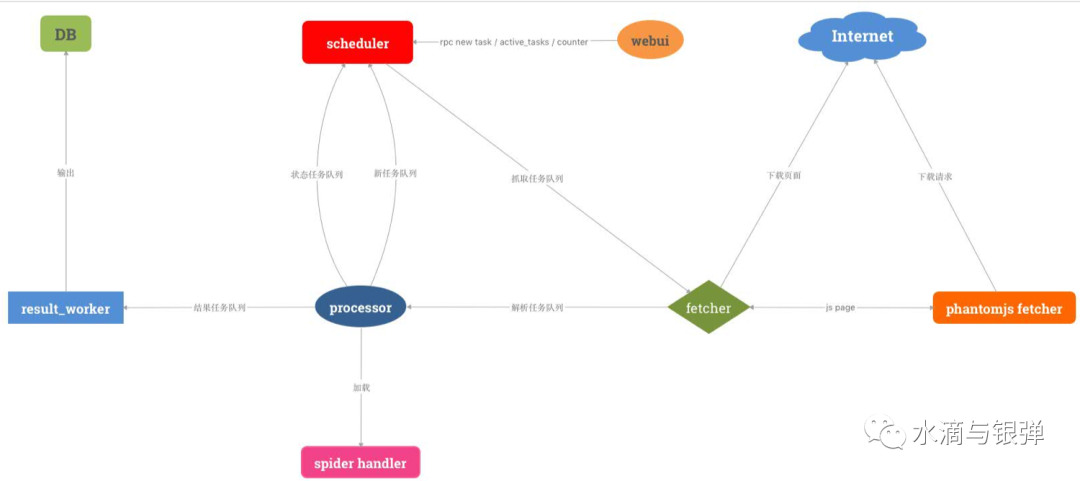
開發(fā)配置解析器,對接配置服務(wù),可以解析配置服務(wù)的多種規(guī)則模式 spider handler模塊定制爬蟲模板,并把爬蟲任務(wù)進(jìn)行分類,定義成模板,降低開發(fā)成本fetcher模塊新增代理 IP 調(diào)度機(jī)制,對接代理服務(wù),并增加代理 IP 調(diào)度策略result_worker模塊把輸出結(jié)果定制化,用來對接清洗服務(wù)
代理服務(wù)
免費(fèi)代理 付費(fèi)代理
免費(fèi)代理
收集代理源 定時采集代理 測試代理 輸出可用代理
付費(fèi)代理
清洗服務(wù)
數(shù)據(jù)服務(wù)
數(shù)據(jù)平臺展示 數(shù)據(jù)推送 數(shù)據(jù)API
解決的問題
爬蟲腳本統(tǒng)一管理、配置可視化 爬蟲模板快速生成爬蟲代碼,降低開發(fā)成本 采集進(jìn)度可監(jiān)控、易跟蹤 采集的數(shù)據(jù)統(tǒng)一輸出 業(yè)務(wù)系統(tǒng)使用爬蟲數(shù)據(jù)更便捷
爬蟲技巧
隨機(jī) UserAgent 模擬不同的客戶端(github有UserAgent庫,非常全面) 隨機(jī)代理 IP(高匿代理 + 代理調(diào)度策略) Cookie池(針對需要登錄的采集行為) JavaScript渲染頁面(使用無界面瀏覽器加載網(wǎng)頁獲取數(shù)據(jù)) 驗(yàn)證碼識別(OCR、機(jī)器學(xué)習(xí))
以上就是構(gòu)建一個垂直爬蟲平臺的設(shè)計(jì)思路,從最簡單的爬蟲腳本,到寫越來越多的爬蟲,到難以維護(hù),再到整個爬蟲平臺的構(gòu)建,一步步都是遇到問題解決問題的產(chǎn)物,在我們真正發(fā)現(xiàn)核心問題時,解決思路也就不難了。
近期文章:
更多Python技術(shù)文,可以關(guān)注上面公眾號
評論
圖片
表情