一個(gè)Python爬蟲(chóng)工程師的修養(yǎng)
練武不練功,到老一場(chǎng)空
練武的人都知道:練武不練功,到老一場(chǎng)空!
說(shuō)的是只練花架子,不練習(xí)內(nèi)功,最終也都是一個(gè)菜鳥(niǎo)級(jí)武師。

學(xué)習(xí)編程何嘗不是!我時(shí)常見(jiàn)到已經(jīng)學(xué)習(xí)相當(dāng)一段時(shí)間的程序員,連稍微深點(diǎn)的基本知識(shí)都沒(méi)有掌握。可嘆,可悲啊!根子不牢,注定走不遠(yuǎn)啊!
基于實(shí)例學(xué)習(xí)編程非常重要,也非常有效,但與此同時(shí),我們也必須不斷的加強(qiáng)基本功的學(xué)習(xí),刻意的加強(qiáng)相關(guān)的技術(shù)。掌握技術(shù)脈絡(luò),加強(qiáng)各項(xiàng)技術(shù),跳出編程語(yǔ)言本身,練好內(nèi)功,才能爬的又快又好,成為一個(gè)高級(jí)的爬蟲(chóng)工程師!

本文從爬蟲(chóng)的技術(shù)原理出發(fā),討論了Python爬蟲(chóng)工程師必須掌握和不斷加強(qiáng)的幾項(xiàng)技術(shù)。
技術(shù)脈絡(luò)
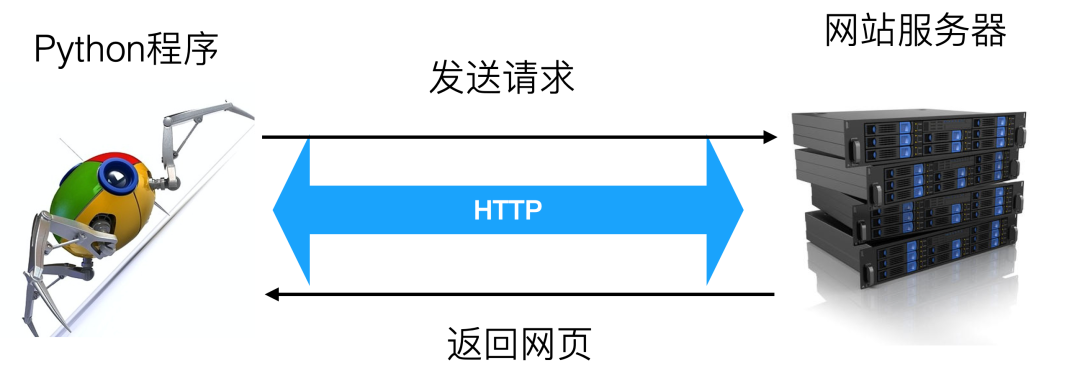
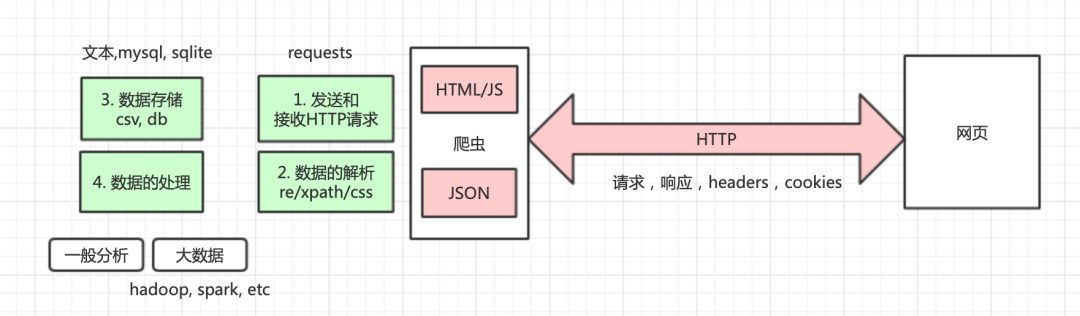
程序發(fā)送請(qǐng)求給網(wǎng)頁(yè)服務(wù)器,請(qǐng)求基于HTTP協(xié)議 服務(wù)器返回網(wǎng)頁(yè)或者數(shù)據(jù),格式為HTML,JSON,XML等。 程序從HTML,JSON,XML等文本中解析返回的網(wǎng)頁(yè),用的技術(shù)包括xpath, 正則表達(dá)式,css選擇器等。 程序把解析好的保存到文件或者數(shù)據(jù)庫(kù)中供后續(xù)分析使用。文件格式通常是cvs,數(shù)據(jù)庫(kù)可以使用關(guān)系型數(shù)據(jù)庫(kù)如MySQL,或者非關(guān)系型數(shù)據(jù)庫(kù)如MongoDB
除此之外,網(wǎng)站會(huì)有各種反爬取技術(shù),爬蟲(chóng)工程師和網(wǎng)站開(kāi)發(fā)工程一個(gè)攻,一個(gè)守,斗智斗勇。
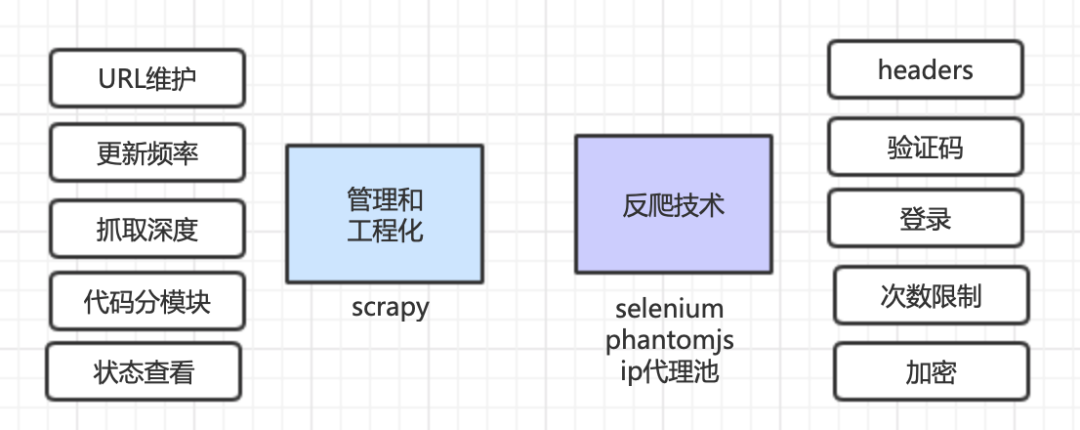
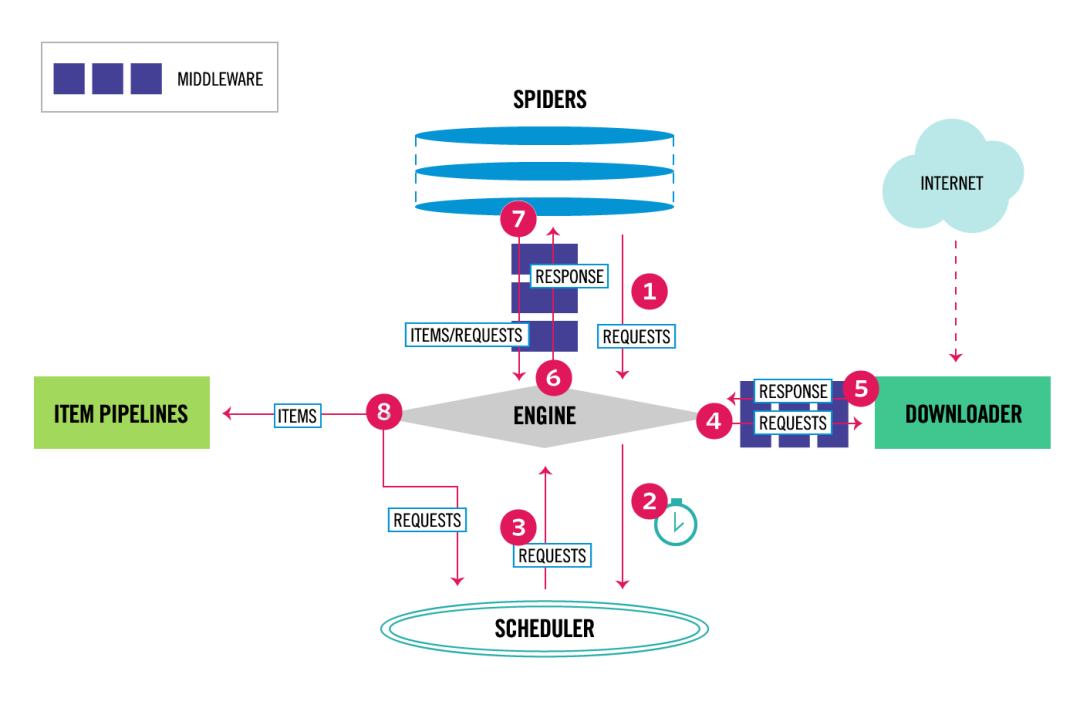
另外,爬蟲(chóng)10個(gè)網(wǎng)頁(yè)和爬取10000個(gè)網(wǎng)站是不同的概念,你需要維護(hù)要爬取的數(shù)以萬(wàn)計(jì)的URL,設(shè)置更新頻率,去掉不需要的URL等等,查看各個(gè)網(wǎng)站的爬取狀態(tài)等,這就是一個(gè)工程化的問(wèn)題。商業(yè)級(jí)的爬蟲(chóng)涉及到很多工程化問(wèn)題。
就像家庭作坊可以就在自己院子里,一家人就能生產(chǎn)出少量的產(chǎn)品。但要大量生成就需要廠房,財(cái)務(wù),人事等企業(yè)框架和管理制度、
Python爬蟲(chóng)工程師的修養(yǎng)
下面列舉了爬蟲(chóng)工程師需要不斷掌握和精進(jìn)的基本功技術(shù):
HTTP協(xié)議
HTTP協(xié)議是爬蟲(chóng)和網(wǎng)頁(yè)交流的語(yǔ)言,如果不懂這個(gè)語(yǔ)言,你肯定不能成為一個(gè)有效的爬蟲(chóng)工程師。你也不需要成為一個(gè)協(xié)議專家,主要掌握請(qǐng)求,相應(yīng),header,cookie等就可以了。

HTTP協(xié)議和下面的5項(xiàng)技術(shù)都可以在這個(gè)網(wǎng)站上學(xué)習(xí):www.w3school.com.cn
網(wǎng)頁(yè)格式:HTML和CSS
我們看到的網(wǎng)頁(yè)基本都是HTML的格式,我們要從HTML的腳本中找出所需要的信息,就必須掌握HTML的格式。

同樣的一個(gè)HTML頁(yè)面,我們可以展現(xiàn)不同的樣式。我們通過(guò)CSS來(lái)指定樣式,比如指定表格用什么背景顏色,文字用什么字體等。
這些樣式,本來(lái)不是爬蟲(chóng)工程師在意的事情,因?yàn)槲覀冎辉谝鈹?shù)據(jù)。但是通過(guò)CSS,我們可以有效的定位到某些數(shù)據(jù),所以CSS還是需要學(xué)習(xí)的,后面的數(shù)據(jù)解析部分會(huì)再次提到CSS。
網(wǎng)頁(yè)格式:JavaScript
HTML是完全靜態(tài)的網(wǎng)頁(yè),為了在網(wǎng)頁(yè)上實(shí)現(xiàn)動(dòng)態(tài)效果,就有了JavaScript。很多網(wǎng)頁(yè)上的數(shù)據(jù)并沒(méi)有直接在HTML中給出,而是通過(guò)JavaScript后續(xù)又加載出來(lái)的。
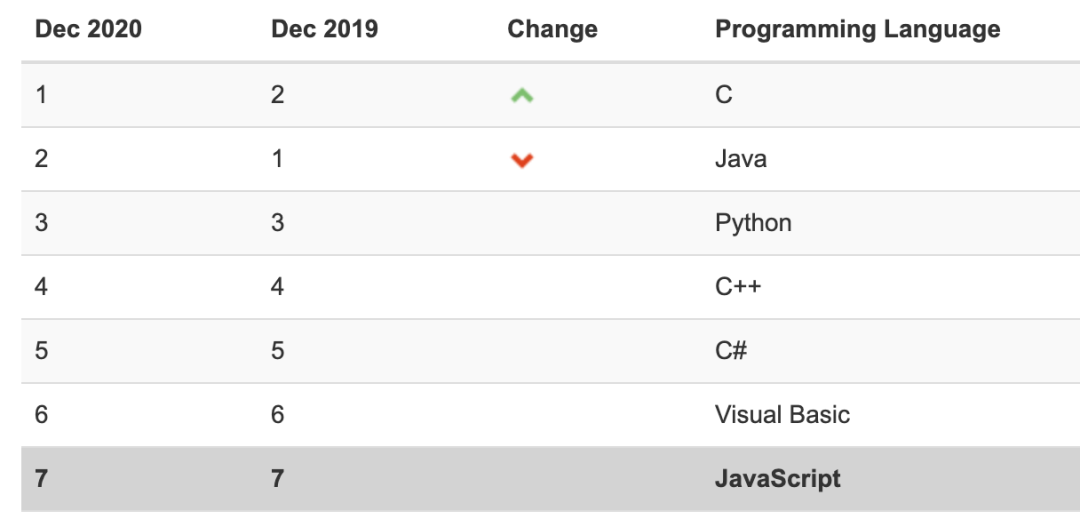
實(shí)際上,JavaScript是編程語(yǔ)言排行榜上很靠前的編程語(yǔ)言,所謂的前端開(kāi)發(fā)者需要精通JavaScript,而爬蟲(chóng)工程師了解基本的知識(shí),知道Ajax請(qǐng)求的相關(guān)原理,有時(shí)候還要知道如何用JavaScript加密,就差不多了。
網(wǎng)頁(yè)格式:JSON
JSON是JavaScript Object Notation的意思,可以理解成一種數(shù)據(jù)結(jié)構(gòu)。一般的數(shù)據(jù)API都是以JSON格式的:

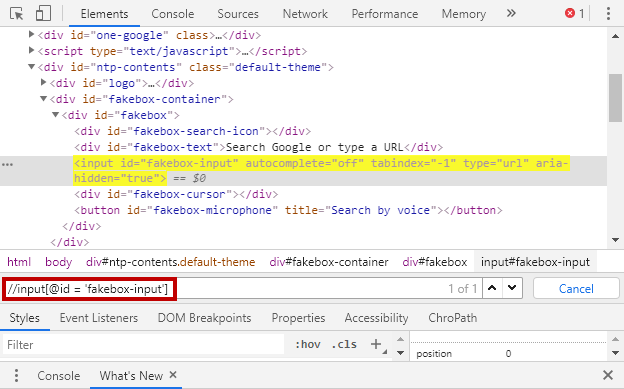
數(shù)據(jù)解析 - xpath
我們需要用某種技術(shù),從HTML中找出我們想要的數(shù)據(jù),xpath是其中一種。簡(jiǎn)單說(shuō),就是通過(guò)路徑來(lái)找到想要的數(shù)據(jù):
數(shù)據(jù)解析 - css選擇器
通過(guò)指定樣式,我們也可以定位到指定的數(shù)據(jù),再解析數(shù)據(jù):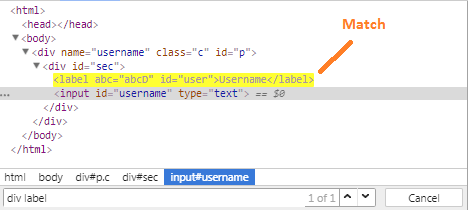
因?yàn)橄矚gJquery的原因,我個(gè)人更喜歡CSS選擇器。
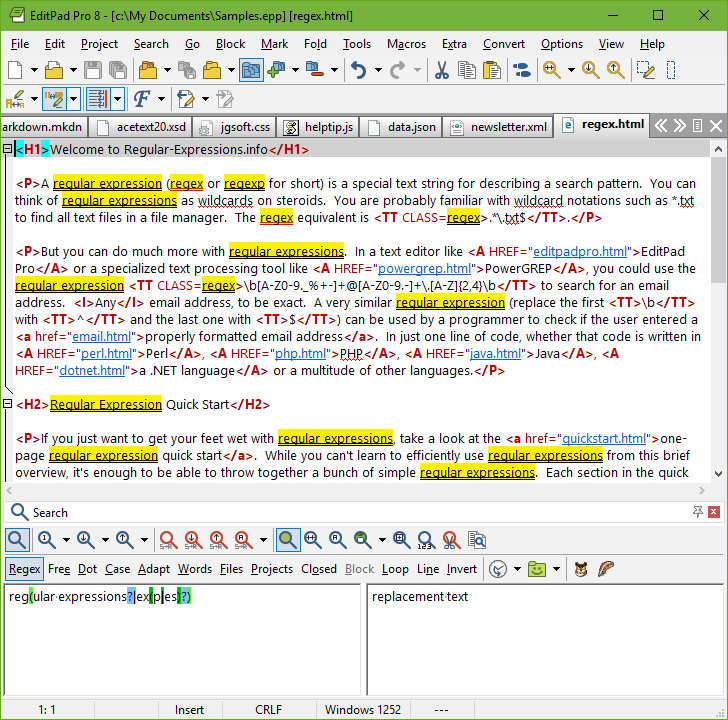
數(shù)據(jù)解析 - 正則表達(dá)式
前兩種數(shù)據(jù)解析都是基于結(jié)構(gòu)的解析方式,而正則表達(dá)式(re)就把HTML當(dāng)成一個(gè)文本,不在意其中的結(jié)構(gòu),用字符串的規(guī)則解析數(shù)據(jù):
數(shù)據(jù)存儲(chǔ) - csv
CSV是用逗號(hào)隔開(kāi)的一種純文本的數(shù)據(jù)格式,是數(shù)據(jù)分析和處理中最常用的格式。CSV可以用記事本打開(kāi),也可以用Excel打開(kāi)。
數(shù)據(jù)存儲(chǔ) - 數(shù)據(jù)庫(kù)
把數(shù)據(jù)存儲(chǔ)在CSV等文本中很方便,但是數(shù)據(jù)的查詢和處理不方便,為了解決這個(gè)問(wèn)題,我們可以會(huì)把數(shù)據(jù)保存在數(shù)據(jù)庫(kù)中。
這是很廣闊的領(lǐng)域,數(shù)據(jù)庫(kù)是計(jì)算機(jī)技術(shù)中最重要分分支之一。值得你不斷地學(xué)習(xí)和精進(jìn)。相比前面的HTML等,你只要幾個(gè)小時(shí)就可以學(xué)會(huì)了,后面也不怎么需要更新知識(shí)。

反爬技術(shù) - ocr, selenium等
關(guān)于反爬技術(shù),請(qǐng)看我另外一篇文章:
搞瘋爬蟲(chóng)程序員的8個(gè)難點(diǎn)!!
工程化框架 - scapy
在Python的世界里,工程化最常用的就是Scrapy框架,它使用組件化的方式分解了爬蟲(chóng)所需要處理的事情,讓你可以集中在最關(guān)鍵的地方,剩下的管理工作交給框架來(lái)完成。