
深度學習中的Attention總結(jié)
【GiantPandaCV導語】 近幾年,Attention-based方法因其可解釋和有效性,受到了學術(shù)界和工業(yè)界的歡迎。但是,由于論文中提出的網(wǎng)絡(luò)結(jié)構(gòu)通常被嵌入到分類、檢測、分割等代碼框架中,導致代碼比較冗余,對于像我這樣的小白很難找到網(wǎng)絡(luò)的核心代碼,導致在論文和網(wǎng)絡(luò)思想的理解上會有一定困難。因此,我把最近看的Attention、MLP和Re-parameter論文的核心代碼進行了整理和復現(xiàn),方便各位讀者理解。本文主要對該項目的Attention部分做簡要介紹。項目會持續(xù)更新最新的論文工作,歡迎大家follow和star該工作,若項目在復現(xiàn)和整理過程中有任何問題,歡迎大家在issue中提出,我會及時回復~
作者信息
廈門大學計算機專業(yè)一年級研究生,歡迎大家關(guān)注Github:xmu-xiaoma666,知乎:努力努力再努力。
項目地址
https://github.com/xmu-xiaoma666/External-Attention-pytorch
1. External Attention
1.1. 引用
Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks.---arXiv 2021.05.05
論文地址:https://arxiv.org/abs/2105.02358
1.2. 模型結(jié)構(gòu)
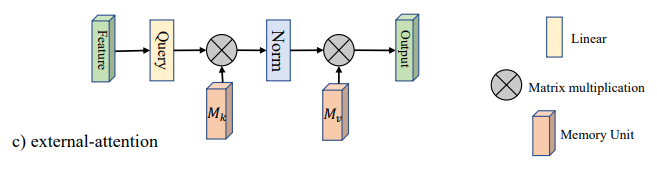
1.3. 簡介
這是五月份在arXiv上的一篇文章,主要解決的Self-Attention(SA)的兩個痛點問題:(1)O(n^2)的計算復雜度;(2)SA是在同一個樣本上根據(jù)不同位置計算Attention,忽略了不同樣本之間的聯(lián)系。因此,本文采用了兩個串聯(lián)的MLP結(jié)構(gòu)作為memory units,使得計算復雜度降低到了O(n);此外,這兩個memory units是基于全部的訓練數(shù)據(jù)學習的,因此也隱式的考慮了不同樣本之間的聯(lián)系。
1.4. 使用方法
from attention.ExternalAttention import ExternalAttention
import torch
input=torch.randn(50,49,512)
ea = ExternalAttention(d_model=512,S=8)
output=ea(input)
print(output.shape)
2. Self Attention
2.1. 引用
Attention Is All You Need---NeurIPS2017
論文地址:https://arxiv.org/abs/1706.03762
2.2. 模型結(jié)構(gòu)
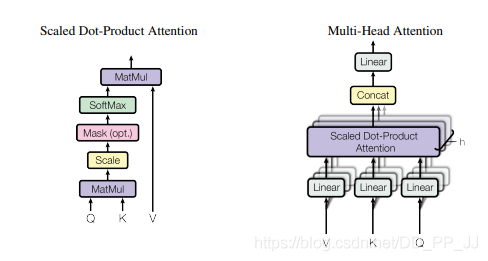
2.3. 簡介
這是Google在NeurIPS2017發(fā)表的一篇文章,在CV、NLP、多模態(tài)等各個領(lǐng)域都有很大的影響力,目前引用量已經(jīng)2.2w+。Transformer中提出的Self-Attention是Attention的一種,用于計算特征中不同位置之間的權(quán)重,從而達到更新特征的效果。首先將input feature通過FC映射成Q、K、V三個特征,然后將Q和K進行點乘的得到attention map,再將attention map與V做點乘得到加權(quán)后的特征。最后通過FC進行特征的映射,得到一個新的特征。(關(guān)于Transformer和Self-Attention目前網(wǎng)上有許多非常好的講解,這里就不做詳細的介紹了)
2.4. 使用方法
from attention.SelfAttention import ScaledDotProductAttention
import torch
input=torch.randn(50,49,512)
sa = ScaledDotProductAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
3. Squeeze-and-Excitation(SE) Attention
3.1. 引用
Squeeze-and-Excitation Networks---CVPR2018
論文地址:https://arxiv.org/abs/1709.01507
3.2. 模型結(jié)構(gòu)

3.3. 簡介
這是CVPR2018的一篇文章,同樣非常具有影響力,目前引用量7k+。本文是做通道注意力的,因其簡單的結(jié)構(gòu)和有效性,將通道注意力掀起了一波小高潮。大道至簡,這篇文章的思想可以說非常簡單,首先將spatial維度進行AdaptiveAvgPool,然后通過兩個FC學習到通道注意力,并用Sigmoid進行歸一化得到Channel Attention Map,最后將Channel Attention Map與原特征相乘,就得到了加權(quán)后的特征。
3.4. 使用方法
from attention.SEAttention import SEAttention
import torch
input=torch.randn(50,512,7,7)
se = SEAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
4. Selective Kernel(SK) Attention
4.1. 引用
Selective Kernel Networks---CVPR2019
論文地址:https://arxiv.org/pdf/1903.06586.pdf
4.2. 模型結(jié)構(gòu)

4.3. 簡介
這是CVPR2019的一篇文章,致敬了SENet的思想。在傳統(tǒng)的CNN中每一個卷積層都是用相同大小的卷積核,限制了模型的表達能力;而Inception這種“更寬”的模型結(jié)構(gòu)也驗證了,用多個不同的卷積核進行學習確實可以提升模型的表達能力。作者借鑒了SENet的思想,通過動態(tài)計算每個卷積核得到通道的權(quán)重,動態(tài)的將各個卷積核的結(jié)果進行融合。
個人認為,之所以所這篇文章也能夠稱之為lightweight,是因為對不同kernel的特征進行通道注意力的時候是參數(shù)共享的(i.e. 因為在做Attention之前,首先將特征進行了融合,所以不同卷積核的結(jié)果共享一個SE模塊的參數(shù))。
本文的方法分為三個部分:Split,Fuse,Select。Split就是一個multi-branch的操作,用不同的卷積核進行卷積得到不同的特征;Fuse部分就是用SE的結(jié)構(gòu)獲取通道注意力的矩陣(N個卷積核就可以得到N個注意力矩陣,這步操作對所有的特征參數(shù)共享),這樣就可以得到不同kernel經(jīng)過SE之后的特征;Select操作就是將這幾個特征進行相加。
4.4. 使用方法
from attention.SKAttention import SKAttention
import torch
input=torch.randn(50,512,7,7)
se = SKAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
5. CBAM Attention
5.1. 引用
CBAM: Convolutional Block Attention Module---ECCV2018
論文地址:https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf
5.2. 模型結(jié)構(gòu)


5.3. 簡介
這是ECCV2018的一篇論文,這篇文章同時使用了Channel Attention和Spatial Attention,將兩者進行了串聯(lián)(文章也做了并聯(lián)和兩種串聯(lián)方式的消融實驗)。
Channel Attention方面,大致結(jié)構(gòu)還是和SE相似,不過作者提出AvgPool和MaxPool有不同的表示效果,所以作者對原來的特征在Spatial維度分別進行了AvgPool和MaxPool,然后用SE的結(jié)構(gòu)提取channel attention,注意這里是參數(shù)共享的,然后將兩個特征相加后做歸一化,就得到了注意力矩陣。
Spatial Attention和Channel Attention類似,先在channel維度進行兩種pool后,將兩個特征進行拼接,然后用7x7的卷積來提取Spatial Attention(之所以用7x7是因為提取的是空間注意力,所以用的卷積核必須足夠大)。然后做一次歸一化,就得到了空間的注意力矩陣。
5.4. 使用方法
from attention.CBAM import CBAMBlock
import torch
input=torch.randn(50,512,7,7)
kernel_size=input.shape[2]
cbam = CBAMBlock(channel=512,reduction=16,kernel_size=kernel_size)
output=cbam(input)
print(output.shape)
6. BAM Attention
6.1. 引用
BAM: Bottleneck Attention Module---BMCV2018
論文地址:https://arxiv.org/pdf/1807.06514.pdf
6.2. 模型結(jié)構(gòu)
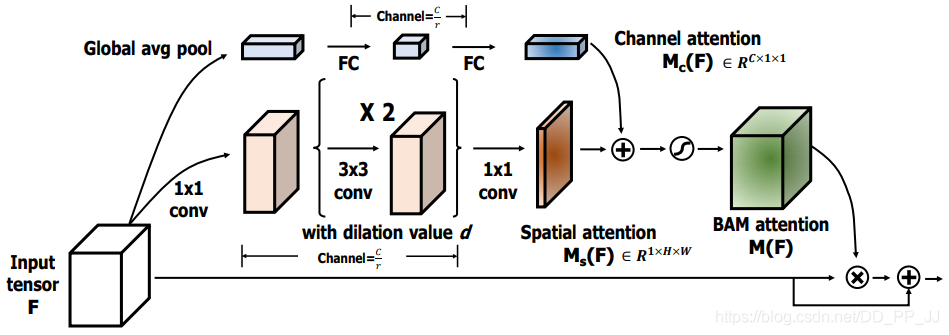
6.3. 簡介
這是CBAM同作者同時期的工作,工作與CBAM非常相似,也是雙重Attention,不同的是CBAM是將兩個attention的結(jié)果串聯(lián);而BAM是直接將兩個attention矩陣進行相加。
Channel Attention方面,與SE的結(jié)構(gòu)基本一樣。Spatial Attention方面,還是在通道維度進行pool,然后用了兩次3x3的空洞卷積,最后將用一次1x1的卷積得到Spatial Attention的矩陣。
最后Channel Attention和Spatial Attention矩陣進行相加(這里用到了廣播機制),并進行歸一化,這樣一來,就得到了空間和通道結(jié)合的attention矩陣。
6.4.使用方法
from attention.BAM import BAMBlock
import torch
input=torch.randn(50,512,7,7)
bam = BAMBlock(channel=512,reduction=16,dia_val=2)
output=bam(input)
print(output.shape)
7. ECA Attention
7.1. 引用
ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks---CVPR2020
論文地址:https://arxiv.org/pdf/1910.03151.pdf
7.2. 模型結(jié)構(gòu)
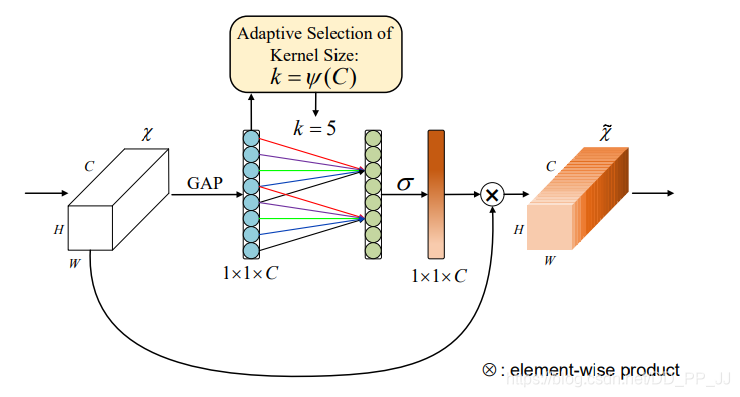
7.3. 簡介
這是CVPR2020的一篇文章。
如上圖所示,SE實現(xiàn)通道注意力是使用兩個全連接層,而ECA是需要一個的卷積。作者這么做的原因一方面是認為計算所有通道兩兩之間的注意力是沒有必要的,另一方面是用兩個全連接層確實引入了太多的參數(shù)和計算量。
因此作者進行了AvgPool之后,只是使用了一個感受野為k的一維卷積(相當于只計算與相鄰k個通道的注意力),這樣做就大大的減少的參數(shù)和計算量。(i.e.相當于SE是一個global的注意力,而ECA是一個local的注意力)。
7.4. 使用方法:
from attention.ECAAttention import ECAAttention
import torch
input=torch.randn(50,512,7,7)
eca = ECAAttention(kernel_size=3)
output=eca(input)
print(output.shape)
8. DANet Attention
8.1. 引用
Dual Attention Network for Scene Segmentation---CVPR2019
論文地址:https://arxiv.org/pdf/1809.02983.pdf
8.2. 模型結(jié)構(gòu)
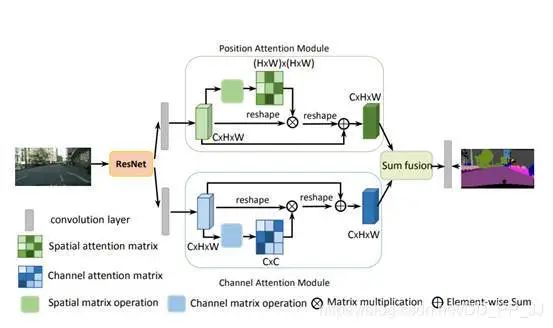
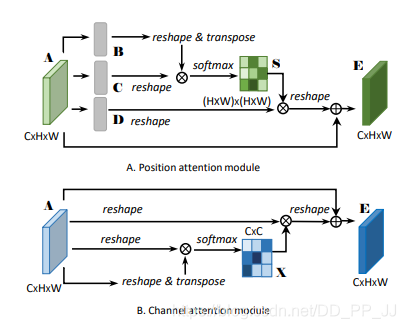
8.3. 簡介
這是CVPR2019的文章,思想上非常簡單,就是將self-attention用到場景分割的任務中,不同的是self-attention是關(guān)注每個position之間的注意力,而本文將self-attention做了一個拓展,還做了一個通道注意力的分支,操作上和self-attention一樣,不同的通道attention中把生成Q,K,V的三個Linear去掉了。最后將兩個attention之后的特征進行element-wise sum。
8.4. 使用方法
from attention.DANet import DAModule
import torch
input=torch.randn(50,512,7,7)
danet=DAModule(d_model=512,kernel_size=3,H=7,W=7)
print(danet(input).shape)
9. Pyramid Split Attention(PSA)
9.1. 引用
EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network---arXiv 2021.05.30
論文地址:https://arxiv.org/pdf/2105.14447.pdf
9.2. 模型結(jié)構(gòu)
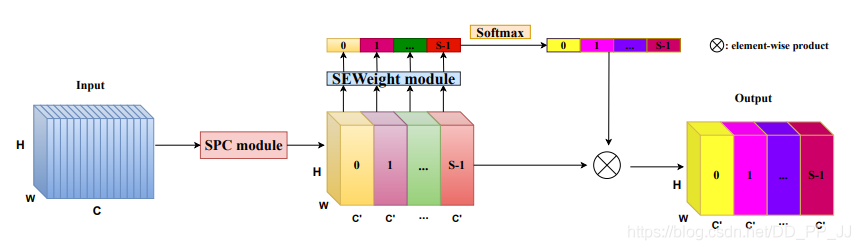
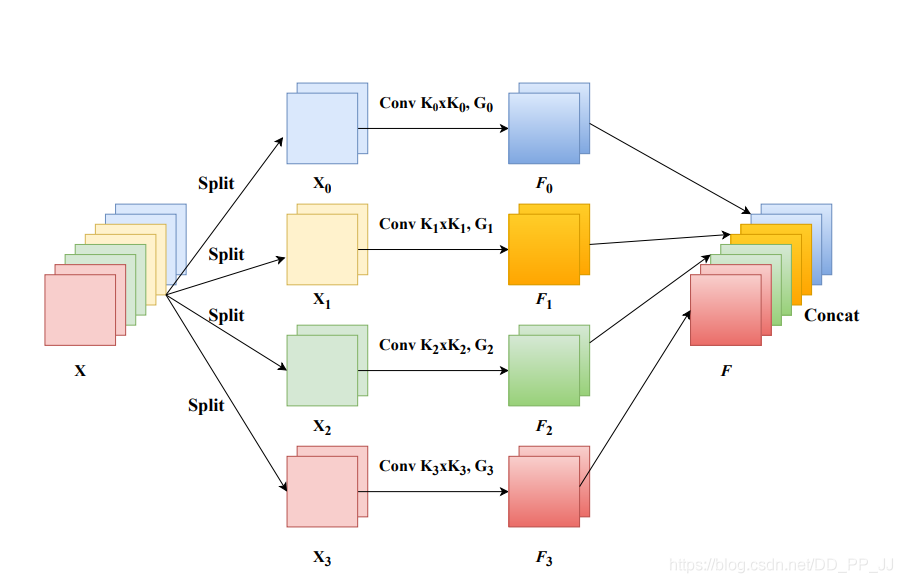
9.3. 簡介
這是深大5月30日在arXiv上上傳的一篇文章,本文的目的是如何獲取并探索不同尺度的空間信息來豐富特征空間。網(wǎng)絡(luò)結(jié)構(gòu)相對來說也比較簡單,主要分成四步,第一步,將原來的feature根據(jù)通道分成n組然后對不同的組進行不同尺度的卷積,得到新的特征W1;第二步,用SE在原來的特征上進行SE,從而獲得不同的阿頭疼托尼;第三步,對不同組進行SOFTMAX;第四步,將獲得attention與原來的特征W1相乘。
9.4. 使用方法
from attention.PSA import PSAimport torchinput=torch.randn(50,512,7,7)psa = PSA(channel=512,reduction=8)output=psa(input)print(output.shape)
10. Efficient Multi-Head Self-Attention(EMSA)
10.1. 引用
ResT: An Efficient Transformer for Visual Recognition---arXiv 2021.05.28
論文地址:https://arxiv.org/abs/2105.13677
10.2. 模型結(jié)構(gòu)
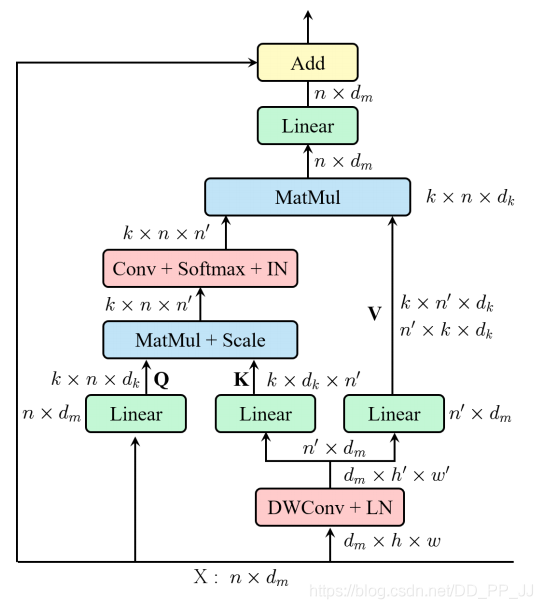
10.3. 簡介
這是南大5月28日在arXiv上上傳的一篇文章。本文解決的主要是SA的兩個痛點問題:(1)Self-Attention的計算復雜度和n(n為空間維度大小)呈平方關(guān)系;(2)每個head只有q,k,v的部分信息,如果q,k,v的維度太小,那么就會導致獲取不到連續(xù)的信息,從而導致性能損失。這篇文章給出的思路也非常簡單,在SA中,在FC之前,用了一個卷積來降低了空間的維度,從而得到空間維度上更小的K和V。
10.4. 使用方法
from attention.EMSA import EMSAimport torchfrom torch import nnfrom torch.nn import functional as Finput=torch.randn(50,64,512)emsa = EMSA(d_model=512, d_k=512, d_v=512, h=8,H=8,W=8,ratio=2,apply_transform=True)output=emsa(input,input,input)print(output.shape)
【寫在最后】
目前該項目整理的Attention的工作確實還不夠全面,后面隨著閱讀量的提高,會不斷對本項目進行完善,歡迎大家star支持。若在文章中有表述不恰、代碼實現(xiàn)有誤的地方,歡迎大家指出~