
一個非常好用的 Python 魔法庫
閱讀本文大概需要 8 分鐘。
來源:Be_melting
https://blog.csdn.net/lys_828/article/details/106489371
【導(dǎo)語】:還在為日常工作中不同的數(shù)據(jù)集的字段進行匹配煩惱?今天跟大家分享? FuzzyWuzzy 一個簡單易用的模糊字符串匹配工具包。讓你多快好省的解決煩惱的匹配問題!
1. 前言
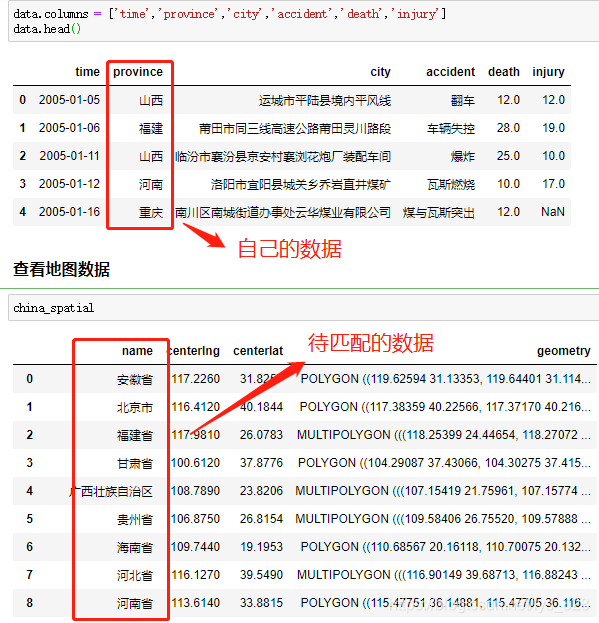
在處理數(shù)據(jù)的過程中,難免會遇到下面類似的場景,自己手里頭獲得的是簡化版的數(shù)據(jù)字段,但是要比對的或者要合并的卻是完整版的數(shù)據(jù)(有時候也會反過來)
最常見的一個例子就是:在進行地理可視化中,自己收集的數(shù)據(jù)只保留的縮寫,比如北京,廣西,新疆,西藏等,但是待匹配的字段數(shù)據(jù)卻是北京市,廣西壯族自治區(qū),新疆維吾爾自治區(qū),西藏自治區(qū)等,如下。因此就需要有沒有一種方式可以很快速便捷的直接進行對應(yīng)字段的匹配并將結(jié)果單獨生成一列,就可以用到 FuzzyWuzzy 庫。
2. FuzzyWuzzy庫介紹
FuzzyWuzzy 是一個簡單易用的模糊字符串匹配工具包。它依據(jù) Levenshtein Distance 算法,計算兩個序列之間的差異。
Levenshtein Distance??算法,又叫 Edit Distance算法,是指兩個字符串之間,由一個轉(zhuǎn)成另一個所需的最少編輯操作次數(shù)。許可的編輯操作包括將一個字符替換成另一個字符,插入一個字符,刪除一個字符。一般來說,編輯距離越小,兩個串的相似度越大。
這里使用的是 Anaconda 下的? jupyter notebook ?編程環(huán)境,因此在? Anaconda 的命令行中輸入一下指令進行第三方庫安裝。
pip?install?-i?https://pypi.tuna.tsinghua.edu.cn/simple?FuzzyWuzzy2.1 fuzz 模塊
該模塊下主要介紹四個函數(shù)(方法),分別為:簡單匹配(Ratio)、非完全匹配(Partial Ratio)、忽略順序匹配(Token Sort Ratio)和去重子集匹配(Token Set Ratio)
注意:?如果直接導(dǎo)入這個模塊的話,系統(tǒng)會提示? warning,當(dāng)然這不代表報錯,程序依舊可以運行(使用的默認算法,執(zhí)行速度較慢),可以按照系統(tǒng)的提示安裝 python-Levenshtein 庫進行輔助,這有利于提高計算的速度。

2.1.1 簡單匹配(Ratio)
簡單的了解一下就行,這個不怎么精確,也不常用
fuzz.ratio("河南省", "河南省")>>> 100>fuzz.ratio("河南", "河南省")>>> 80
2.1.2 非完全匹配(Partial Ratio)
盡量使用非完全匹配,精度較高
fuzz.partial_ratio("河南省", "河南省")>>> 100fuzz.partial_ratio("河南", "河南省")>>> 100
2.1.3 忽略順序匹配(Token Sort Ratio)
原理在于:以?空格?為分隔符,小寫?化所有字母,無視空格外的其它標點符號
fuzz.ratio("西藏 自治區(qū)", "自治區(qū) 西藏")>>> 50fuzz.ratio('I love YOU','YOU LOVE I')>>> 30fuzz.token_sort_ratio("西藏 自治區(qū)", "自治區(qū) 西藏")>>> 100fuzz.token_sort_ratio('I love YOU','YOU LOVE I')>>>?100
2.1.4 去重子集匹配(Token Set Ratio)
相當(dāng)于比對之前有一個集合去重的過程,注意最后兩個,可理解為該方法是在 token_sort_ratio 方法的基礎(chǔ)上添加了集合去重的功能,下面三個匹配的都是倒序
fuzz.ratio("西藏 西藏 自治區(qū)", "自治區(qū) 西藏")> 40fuzz.token_sort_ratio("西藏 西藏 自治區(qū)", "自治區(qū) 西藏")> 80fuzz.token_set_ratio("西藏 西藏 自治區(qū)", "自治區(qū) 西藏")>?100
fuzz 這幾個 ratio() 函數(shù)(方法)最后得到的結(jié)果都是數(shù)字,如果需要獲得匹配度最高的字符串結(jié)果,還需要依舊自己的數(shù)據(jù)類型選擇不同的函數(shù),然后再進行結(jié)果提取,如果但看文本數(shù)據(jù)的匹配程度使用這種方式是可以量化的,但是對于我們要提取匹配的結(jié)果來說就不是很方便了,因此就有了 rocess 模塊。
2.2 process模塊
用于處理備選答案有限的情況,返回模糊匹配的字符串和相似度。
2.2.1 extract提取多條數(shù)據(jù)
類似于爬蟲中 select,返回的是列表,其中會包含很多匹配的數(shù)據(jù)
choices = ["河南省", "鄭州市", "湖北省", "武漢市"]process.extract("鄭州", choices, limit=2)> [('鄭州市', 90), ('河南省', 0)]#?extract之后的數(shù)據(jù)類型是列表,即使limit=1,最后還是列表,注意和下面extractOne的區(qū)別
2.2.2 extractOne提取一條數(shù)據(jù)
如果要提取匹配度最大的結(jié)果,可以使用extractOne,注意這里返回的是?元組?類型, 還有就是匹配度最大的結(jié)果不一定是我們想要的數(shù)據(jù),可以通過下面的示例和兩個實戰(zhàn)應(yīng)用體會一下
process.extractOne("鄭州", choices)>>> ('鄭州市', 90)process.extractOne("北京", choices)>>>?('湖北省',?45)
3. 實戰(zhàn)應(yīng)用
這里舉兩個實戰(zhàn)應(yīng)用的小例子,第一個是公司名稱字段的模糊匹配,第二個是省市字段的模糊匹配
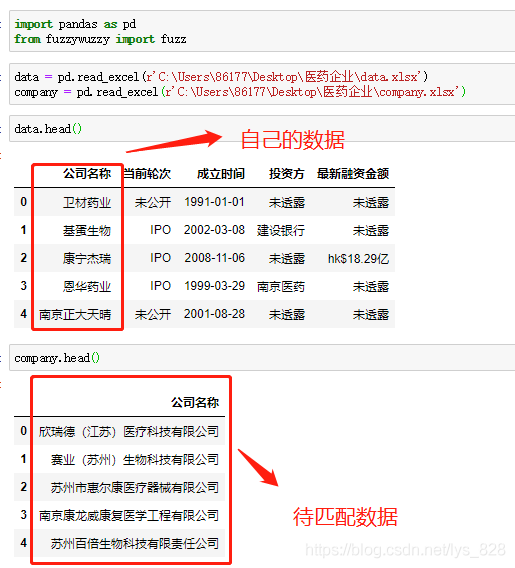
3.1 公司名稱字段模糊匹配
數(shù)據(jù)及待匹配的數(shù)據(jù)樣式如下:自己獲取到的數(shù)據(jù)字段的名稱很簡潔,并不是公司的全稱,因此需要進行兩個字段的合并
直接將代碼封裝為函數(shù),主要是為了方便日后的調(diào)用,這里參數(shù)設(shè)置的比較詳細,執(zhí)行結(jié)果如下:
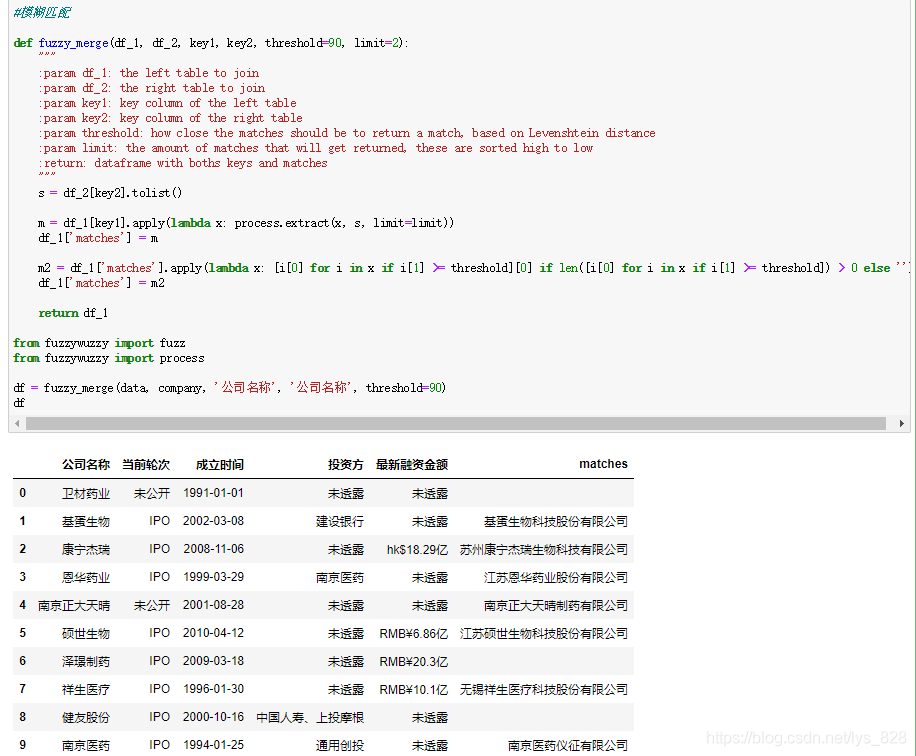
3.1.1 參數(shù)講解:
① 第一個參數(shù)df_1是自己獲取的欲合并的左側(cè)數(shù)據(jù)(這里是data變量);
② 第二個參數(shù)df_2是待匹配的欲合并的右側(cè)數(shù)據(jù)(這里是company變量);
③ 第三個參數(shù)key1是df_1中要處理的字段名稱(這里是data變量里的‘公司名稱’字段)
④ 第四個參數(shù)key2是df_2中要匹配的字段名稱(這里是company變量里的‘公司名稱’字段)
⑤ 第五個參數(shù)threshold是設(shè)定提取結(jié)果匹配度的標準。注意這里就是對extractOne方法的完善,提取到的最大匹配度的結(jié)果并不一定是我們需要的,所以需要設(shè)定一個閾值來評判,這個值就為90,只有是大于等于90,這個匹配結(jié)果我們才可以接受
⑥ 第六個參數(shù),默認參數(shù)就是只返回兩個匹配成功的結(jié)果
⑦ 返回值:為df_1添加‘matches’字段后的新的DataFrame數(shù)據(jù)
3.1.2 核心代碼講解
第一部分代碼如下,可以參考上面講解process.extract方法,這里就是直接使用,所以返回的結(jié)果m就是列表中嵌套元祖的數(shù)據(jù)格式,樣式為: [(‘鄭州市’, 90), (‘河南省’, 0)],因此第一次寫入到’matches’字段中的數(shù)據(jù)也就是這種格式
注意,注意:?元祖中的第一個是匹配成功的字符串,第二個就是設(shè)置的threshold參數(shù)比對的數(shù)字對象
s = df_2[key2].tolist()m = df_1[key1].apply(lambda x: process.extract(x, s, limit=limit))df_1['matches']?=?m
第二部分的核心代碼如下,有了上面的梳理,明確了‘matches’字段中的數(shù)據(jù)類型,然后就是進行數(shù)據(jù)的提取了,需要處理的部分有兩點需要注意的:
① 提取匹配成功的字符串,并對閾值小于90的數(shù)據(jù)填充空值
② 最后把數(shù)據(jù)添加到‘matches’字段
m2 = df_1['matches'].apply(lambda x: [i[0] for i in x if i[1] >= threshold][0] if len([i[0] for i in x if i[1] >= threshold]) > 0 else '')#要理解第一個‘matches’字段返回的數(shù)據(jù)類型是什么樣子的,就不難理解這行代碼了#參考一下這個格式:[('鄭州市', 90), ('河南省', 0)]df_1['matches'] = m2return?df_1
3.2 省份字段模糊匹配
自己的數(shù)據(jù)和待匹配的數(shù)據(jù)背景介紹中已經(jīng)有圖片顯示了,上面也已經(jīng)封裝了模糊匹配的函數(shù),這里直接調(diào)用上面的函數(shù),輸入相應(yīng)的參數(shù)即可,代碼以及執(zhí)行結(jié)果如下:
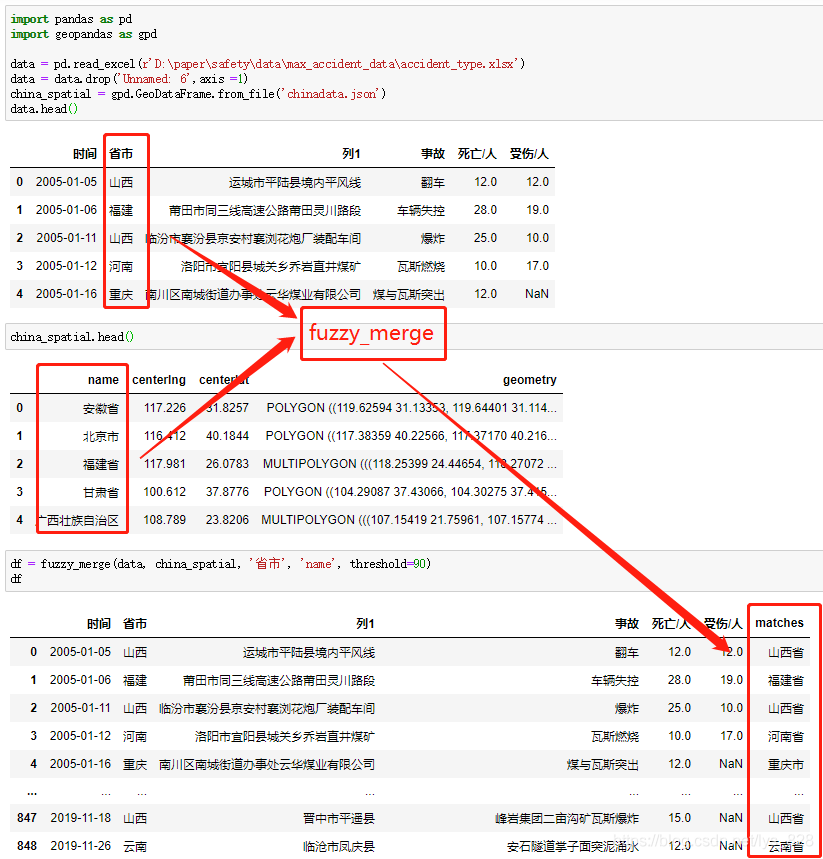
數(shù)據(jù)處理完成,經(jīng)過封裝后的函數(shù)可以直接放在自己自定義的模塊名文件下面,以后可以方便直接導(dǎo)入函數(shù)名即可,可以參考將自定義常用的一些函數(shù)封裝成可以直接調(diào)用的模塊方法。
4. 全部函數(shù)代碼
#模糊匹配def fuzzy_merge(df_1, df_2, key1, key2, threshold=90, limit=2):""":param df_1: the left table to join:param df_2: the right table to join:param key1: key column of the left table:param key2: key column of the right table:param threshold: how close the matches should be to return a match, based on Levenshtein distance:param limit: the amount of matches that will get returned, these are sorted high to low:return: dataframe with boths keys and matches"""s = df_2[key2].tolist()m = df_1[key1].apply(lambda x: process.extract(x, s, limit=limit))df_1['matches'] = mm2 = df_1['matches'].apply(lambda x: [i[0] for i in x if i[1] >= threshold][0] if len([i[0] for i in x if i[1] >= threshold]) > 0 else '')df_1['matches'] = m2return df_1from fuzzywuzzy import fuzzfrom fuzzywuzzy import processdf = fuzzy_merge(data, company, '公司名稱', '公司名稱', threshold=90)df
推薦閱讀
1
2
3
4
崔慶才
靜覓博客博主,《Python3網(wǎng)絡(luò)爬蟲開發(fā)實戰(zhàn)》作者
隱形字
個人公眾號:進擊的Coder


長按識別二維碼關(guān)注