
【Python基礎(chǔ)】安利3個Python數(shù)據(jù)分析EDA神器!

來源:Python數(shù)據(jù)科學(xué)
作者:東哥起飛
1. Pandas_Profiling
這個屬于三個中最輕便、簡單的了。它可以快速生成報告,一覽變量概況。首先,我們需要安裝該軟件包。
#?安裝Jupyter擴(kuò)展widget?
jupyter?nbextension?enable?--py?widgetsnbextension
#?或者通過conda安裝
conda?env?create?-n?pandas-profiling
conda?activate?pandas-profiling
conda?install?-c?conda-forge?pandas-profiling
#?或者直接從源地址安裝
pip?install?https://github.com/pandas-profiling/pandas-profiling/archive/master.zip
安裝成功后即可導(dǎo)入數(shù)據(jù)直接生成報告了。
import?pandas?as?pd
import?seaborn?as?sns
mpg?=?sns.load_dataset('mpg')
mpg.head()
from?pandas_profiling?import?ProfileReport
profile?=?ProfileReport(mpg,?title='MPG?Pandas?Profiling?Report',?explorative?=?True)
profile
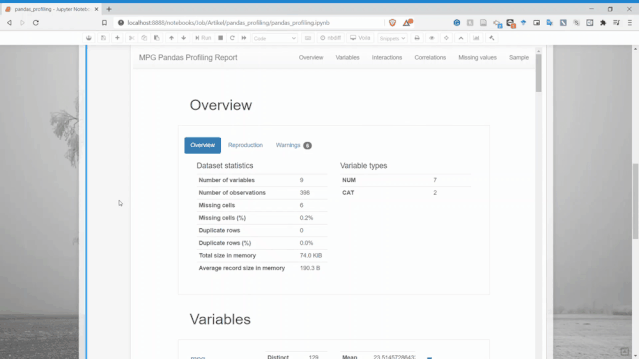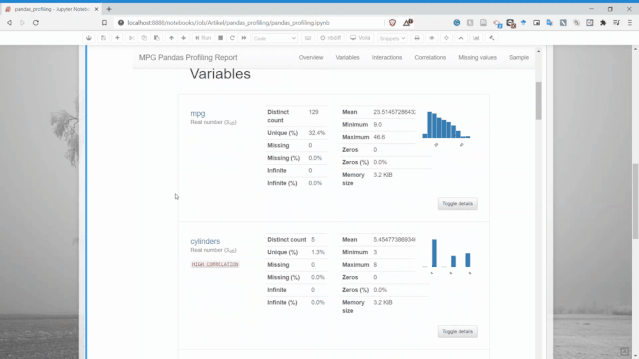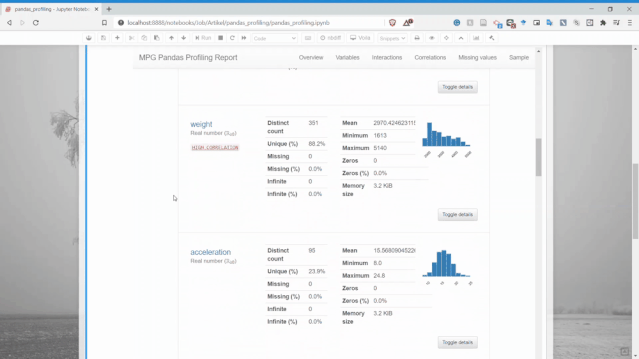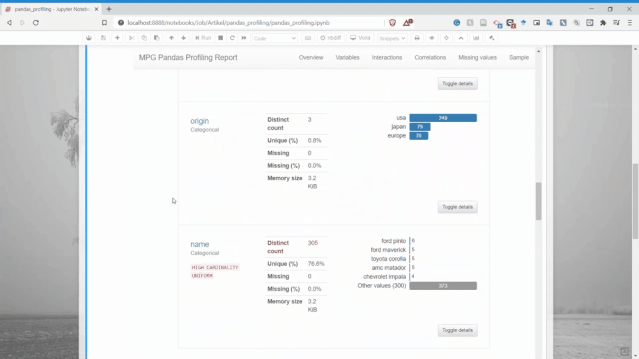
使用Pandas Profiling生成了一個快速的報告,具有很好的可視化效果。報告結(jié)果直接顯示在notebook中,而不是在單獨(dú)的文件中打開。
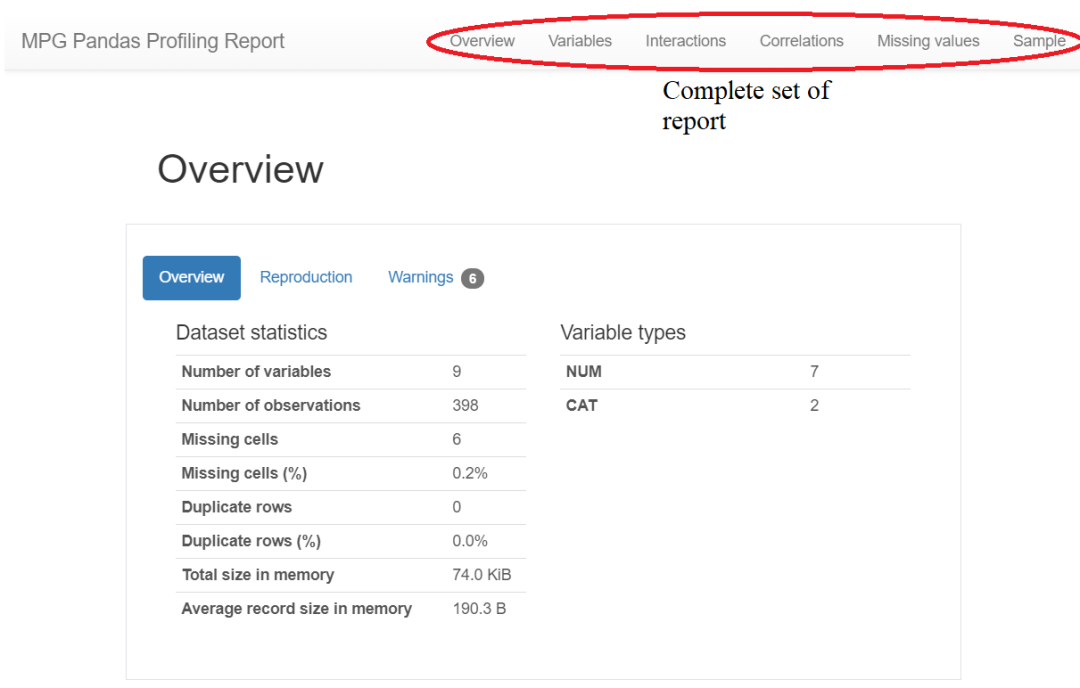
總共提供了六個部分:概述、變量、交互、相關(guān)性,缺失值和樣本。
Pandas profiling的變量部分是完整的,它為每個變量都生成了詳細(xì)的報告。
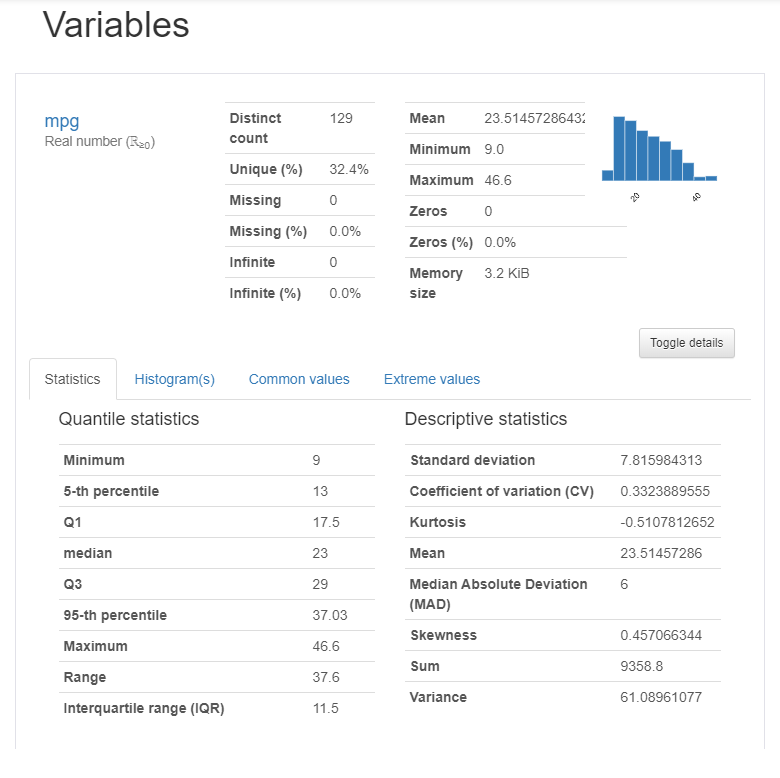
從上圖可以看出,僅一個變量就有太多信息,比如可以獲得描述性信息和分位數(shù)信息。
交互
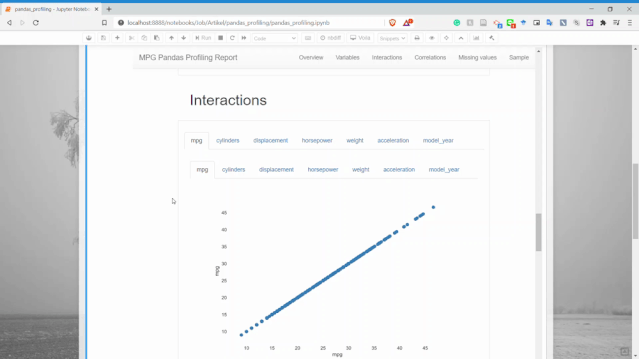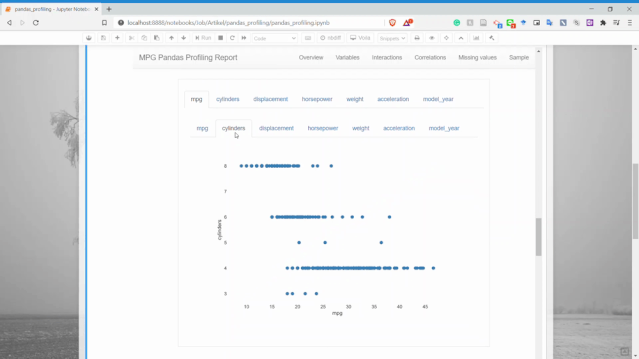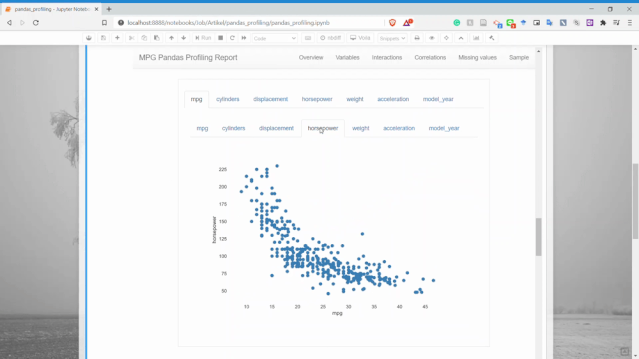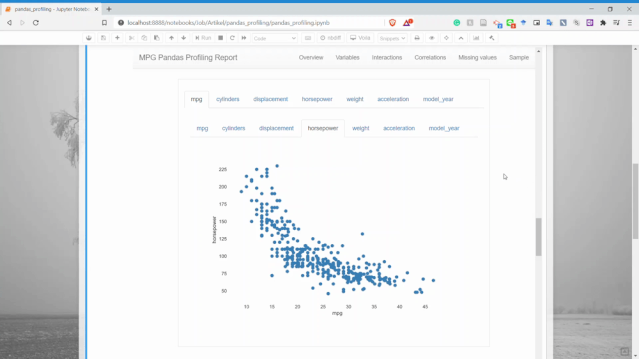
交互部分我們可以獲取兩個數(shù)值變量之間的散點(diǎn)圖。
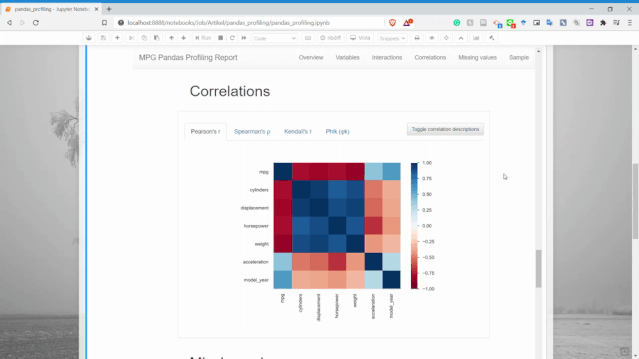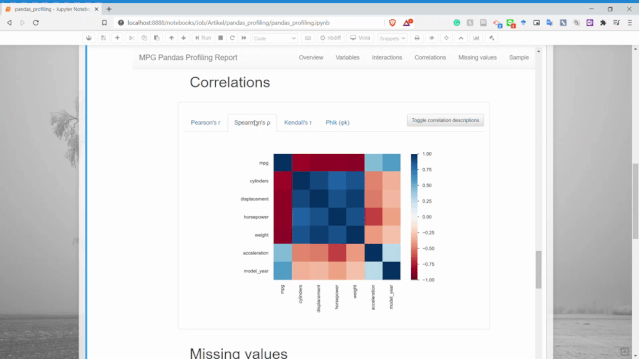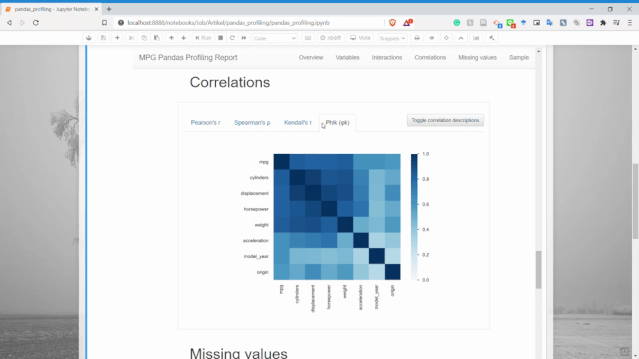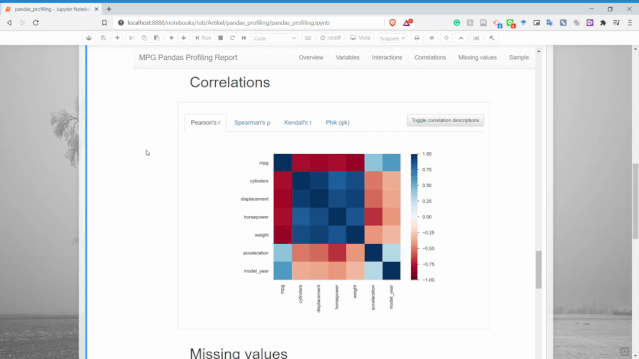
相關(guān)性
可以獲得兩個變量之間的關(guān)系信息。
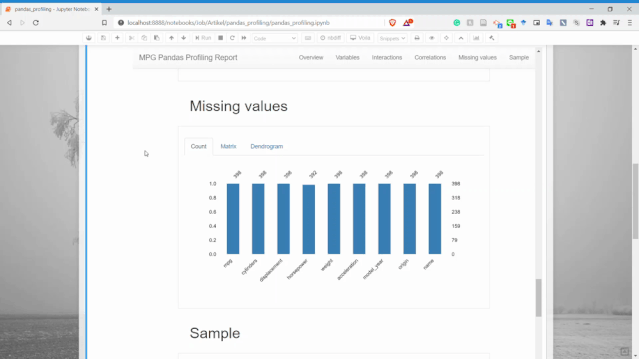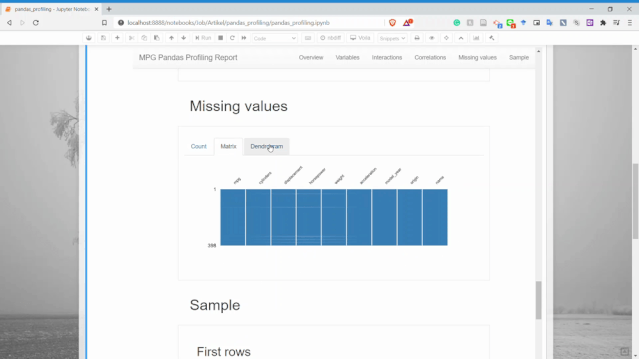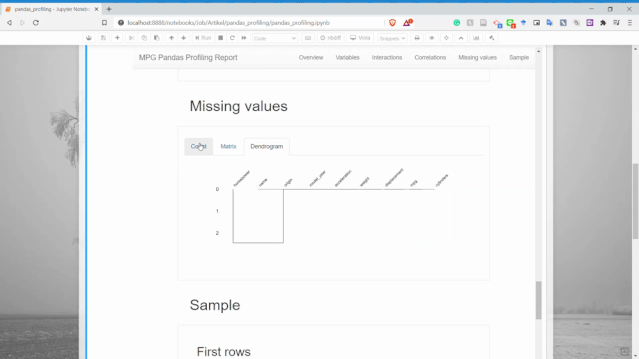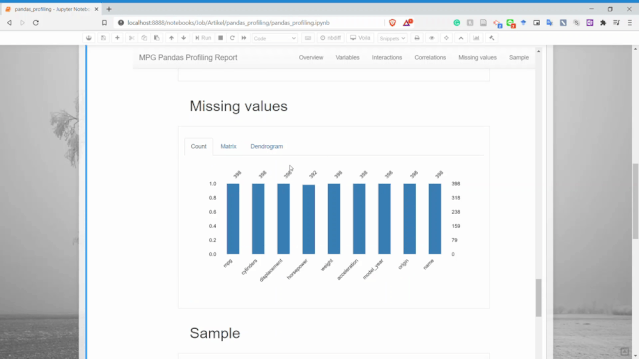
缺失值
可以獲取每個變量的缺失值計數(shù)信息。
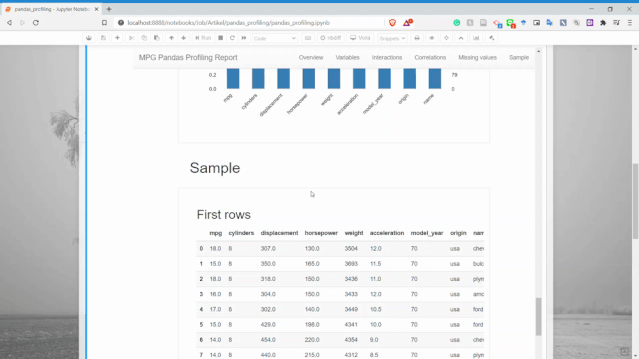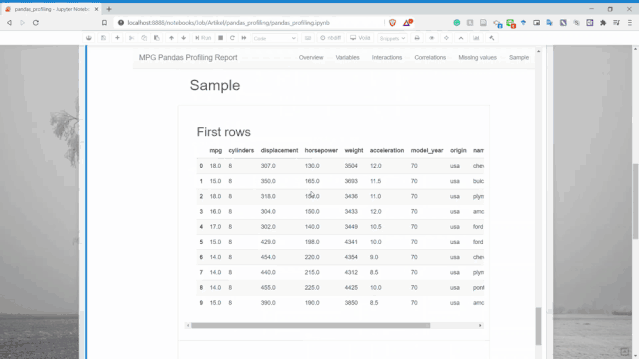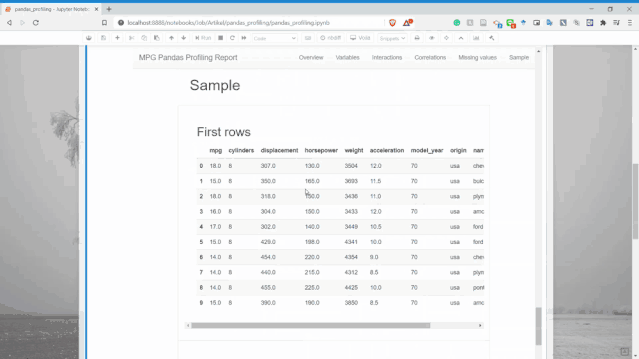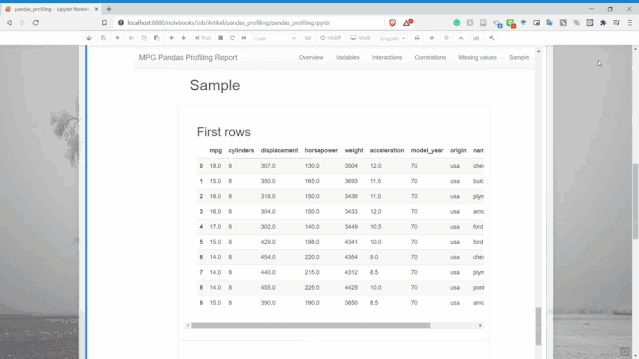
樣本
可以顯示了數(shù)據(jù)集中的樣本行,用于了解數(shù)據(jù)。
2. Sweetviz
Sweetviz是另一個Python的開源代碼包,僅用一行代碼即可生成漂亮的EDA報告。與Pandas Profiling的區(qū)別在于它輸出的是一個完全獨(dú)立的HTML應(yīng)用程序。
使用pip安裝該軟件包
pip?install?sweetviz
安裝完成后,我們可以使用Sweetviz生成報告,下面嘗試一下。
import?sweetviz?as?sv
#?可以選擇目標(biāo)特征
my_report?=?sv.analyze(mpg,?target_feat?='mpg')
my_report.show_html()
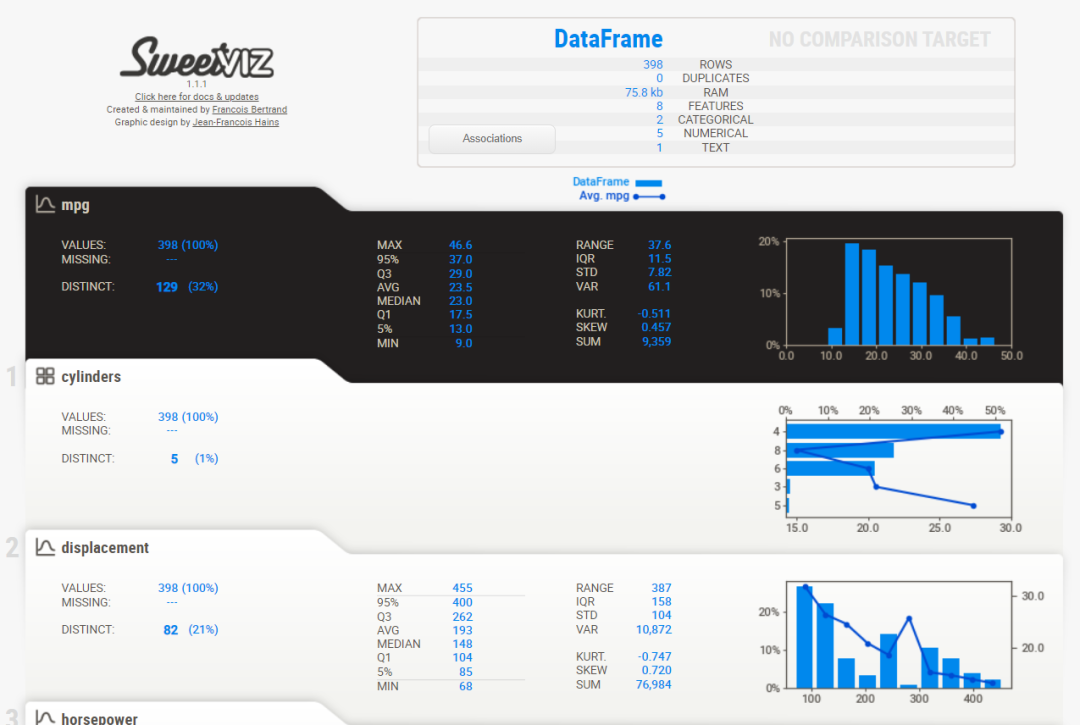
從上圖可以看到,Sweetviz報告生成的內(nèi)容與之前的Pandas Profiling類似,但具有不同的UI。
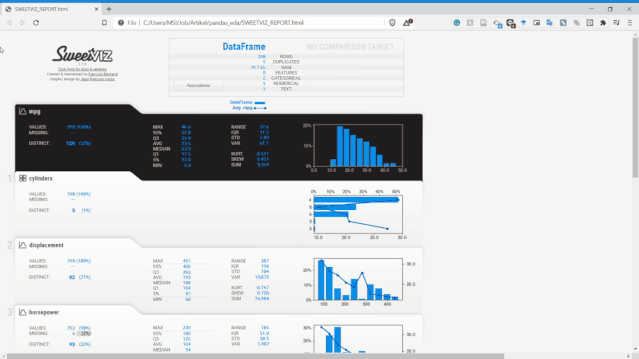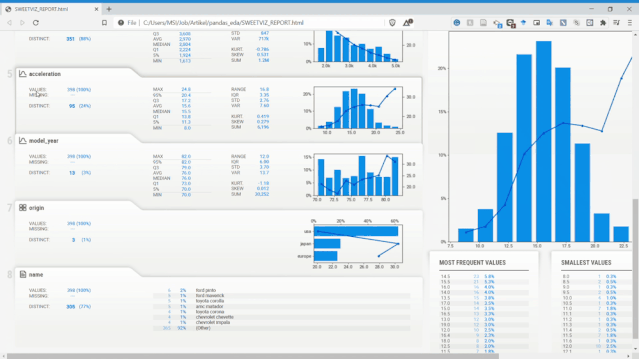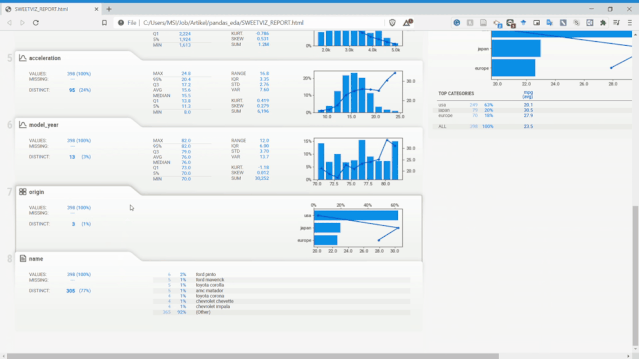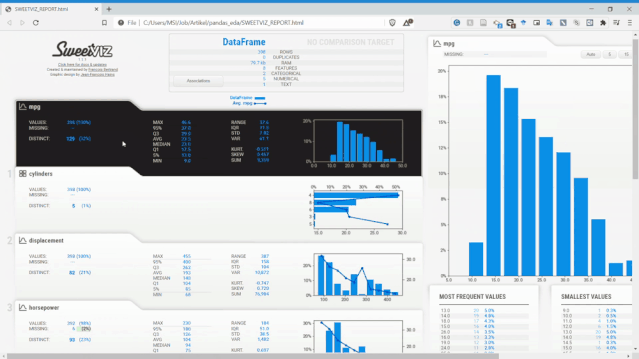
Sweetviz不僅可以查看單變量的分布、統(tǒng)計特性,它還可以設(shè)置目標(biāo)標(biāo)量,將變量和目標(biāo)變量進(jìn)行關(guān)聯(lián)分析。如上面報告最右側(cè),它獲得了所有現(xiàn)有變量的數(shù)值關(guān)聯(lián)和類別關(guān)聯(lián)的相關(guān)性信息。
Sweetviz的優(yōu)勢不在于單個數(shù)據(jù)集上的EDA報告,而在于數(shù)據(jù)集的比較。
可以通過兩種方式比較數(shù)據(jù)集:將其拆分(例如訓(xùn)練和測試數(shù)據(jù)集),或者使用一些過濾器對總體進(jìn)行細(xì)分。
比如下面這個例子,有USA和NOT-USA兩個數(shù)據(jù)集。
#?設(shè)置需要分析的變量
my_report?=?sv.compare_intra(mpg,mpg?[“?origin”]?==“?usa”,[“?USA”,“?NOT-USA”],target_feat?='mpg')
my_report.show_html()
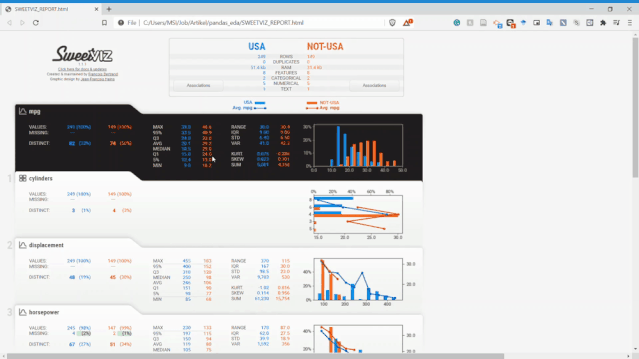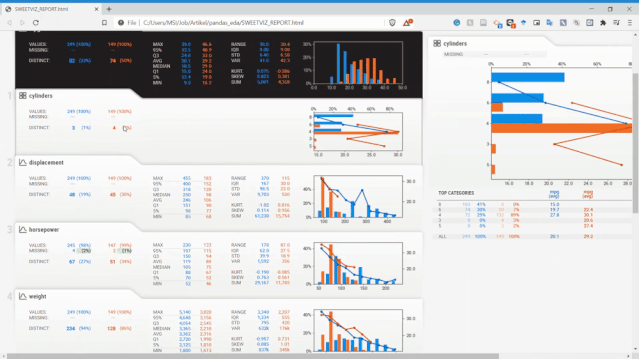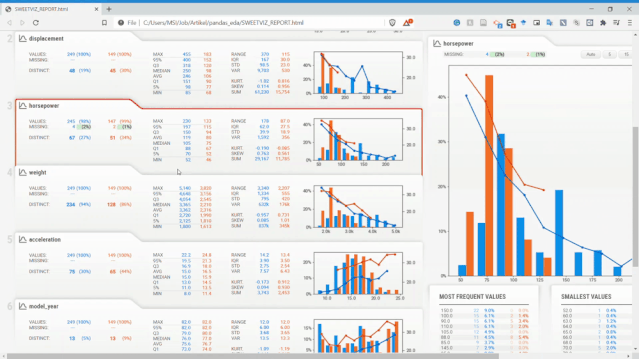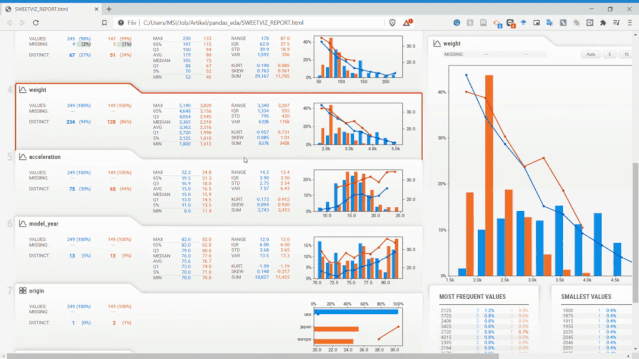
不需要敲太多的代碼就可以讓我們快速分析這些變量,這在EDA環(huán)節(jié)會減少很多工作量,而把時間留給變量的分析和篩選上。
Sweetviz的一些優(yōu)勢在于:
分析有關(guān)目標(biāo)值的數(shù)據(jù)集的能力
兩個數(shù)據(jù)集之間的比較能力
但也有一些缺點(diǎn):
變量之間沒有可視化,例如散點(diǎn)圖
報告在另一個標(biāo)簽中打開
個人是比較喜歡Sweetviz的。
3.?pandasGUI
PandasGUI與前面的兩個不同,PandasGUI不會生成報告,而是生成一個GUI(圖形用戶界面)的數(shù)據(jù)框,我們可以使用它來更詳細(xì)地分析我們的Dataframe。
首先,安裝PandasGUI。
# pip安裝
pip?install?pandasgui
# 或者通過源下載
pip?install?git+https://github.com/adamerose/pandasgui.git
然后,運(yùn)行幾行代碼試一下。
from?pandasgui?import?show
# 部署GUI的數(shù)據(jù)集
gui?=?show(mpg)
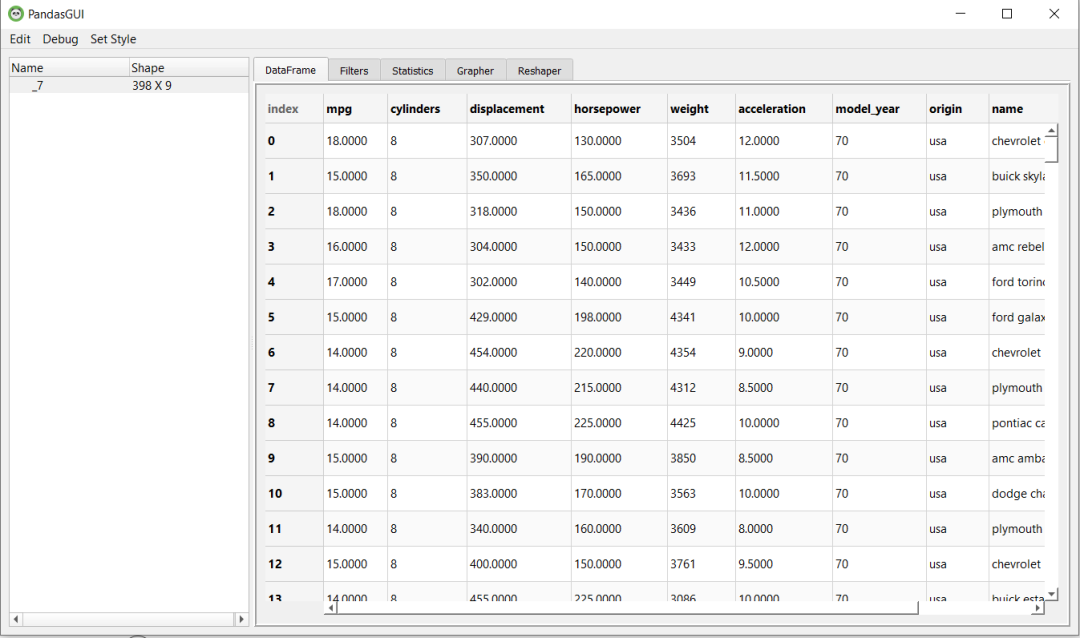
在此GUI中,可以做很多事情,比如過濾、統(tǒng)計信息、在變量之間創(chuàng)建圖表、以及重塑數(shù)據(jù)。這些操作可以根據(jù)需求拖動選項卡來完成。
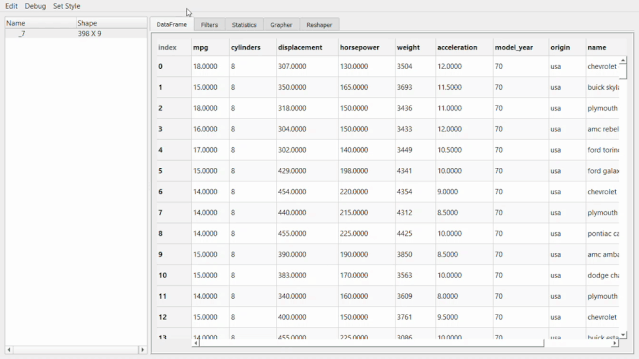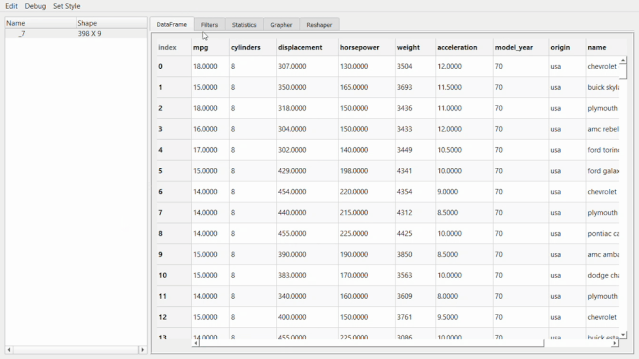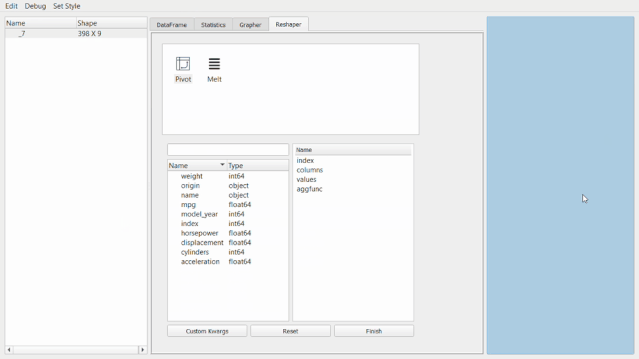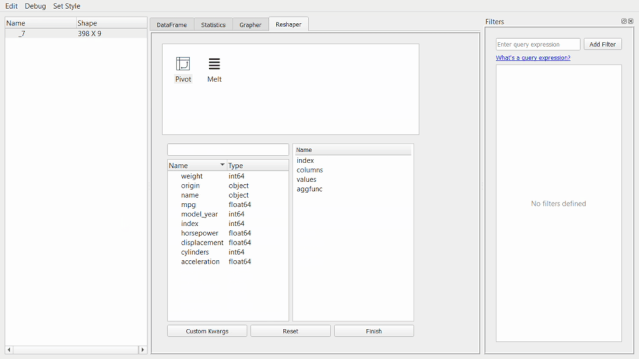
比如像下面這個統(tǒng)計信息。
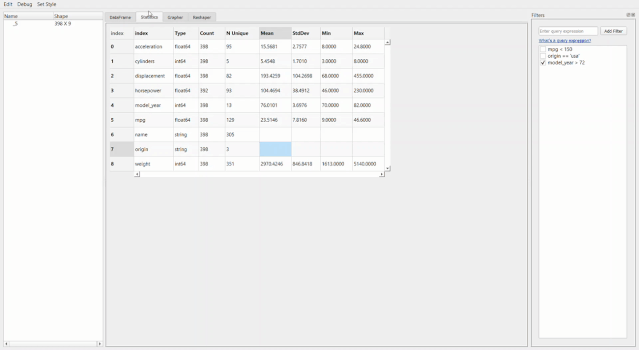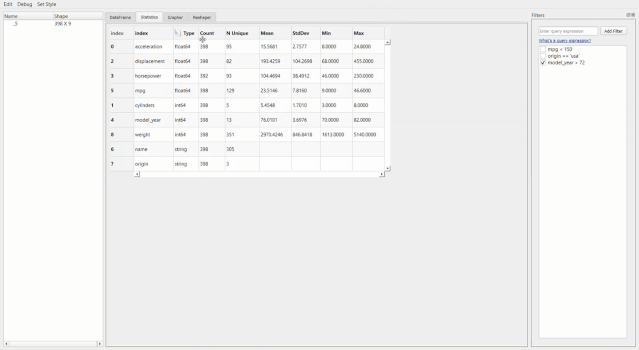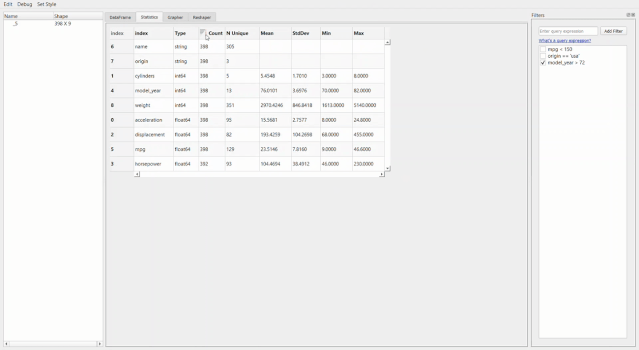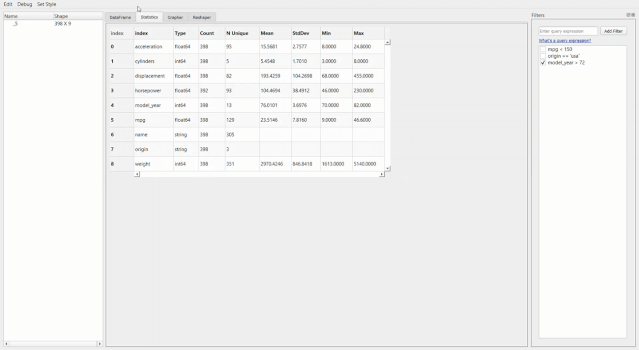
最牛X的就是繪圖器功能了。用它進(jìn)行拖拽操作簡直和excel沒有啥區(qū)別了,操作難度和門檻幾乎為零。
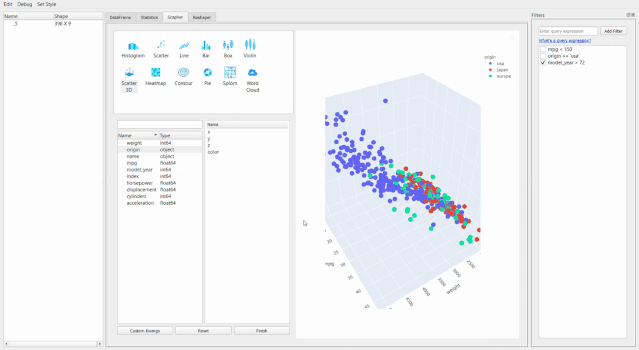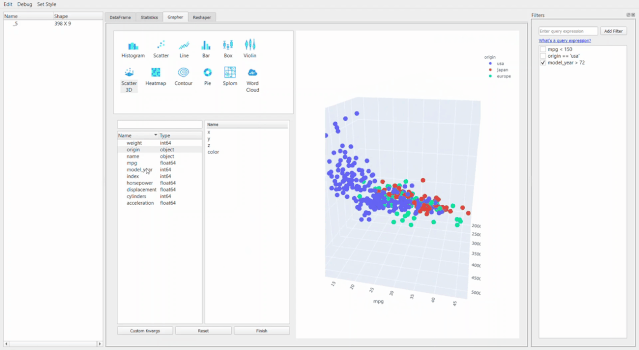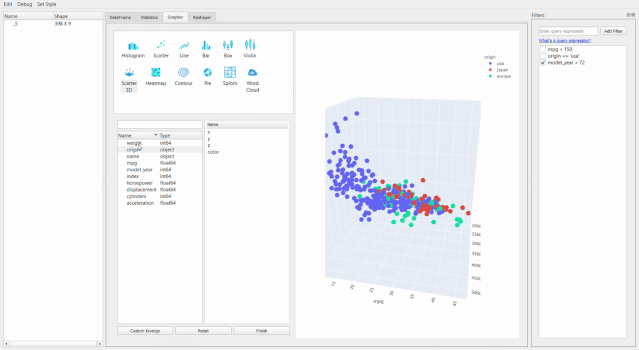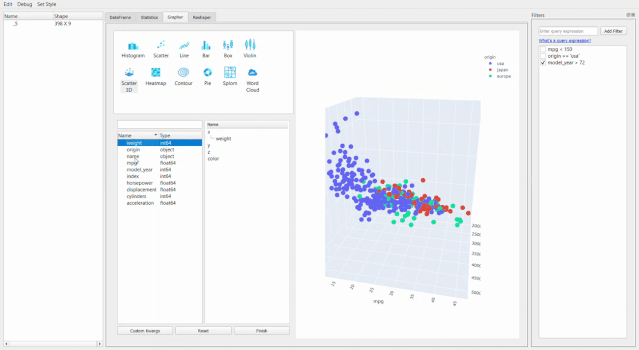
還可以通過創(chuàng)建新的數(shù)據(jù)透視表或者融合數(shù)據(jù)集來進(jìn)行重塑。
然后,處理好的數(shù)據(jù)集可以直接導(dǎo)出成csv。
pandasGUI的一些優(yōu)勢在于:
可以拖拽
快速過濾數(shù)據(jù)
快速繪圖
缺點(diǎn)在于:
沒有完整的統(tǒng)計信息
不能生成報告
4.?結(jié)論
Pandas Profiling、Sweetviz和PandasGUI都很不錯,旨在簡化我們的EDA處理。在不同的工作流程中,每個都有自己的優(yōu)勢和適用性,三個工具具體優(yōu)勢如下:
Pandas Profiling 適用于快速生成單個變量的分析。
Sweetviz 適用于數(shù)據(jù)集之間和目標(biāo)變量之間的分析。
PandasGUI適用于具有手動拖放功能的深度分析。
原創(chuàng)不易,來個三連支持下。
文末贈書福利
贈送新出的書籍《趣學(xué)Python算法100例》5本!由「機(jī)械工業(yè)出版社」贊助提供,如果等不及也可以入手一本學(xué)習(xí)。 介紹:本書以通俗易懂的語言詳盡地介紹了用Python語言編寫的100個算法實(shí)例。這些實(shí)例大體上按照“問題描述→問題分析→算法設(shè)計→確定程序框架→程序編碼實(shí)現(xiàn)→運(yùn)行結(jié)果→問題拓展”的流程進(jìn)行講解,每個實(shí)例又根據(jù)實(shí)際需要有所取舍。這些實(shí)例兼顧了趣味性、實(shí)用性和可操作性,而且大多是圍繞一些經(jīng)典算法問題展開的。 參與方式:本篇文章底部「點(diǎn)贊」+「在看」+「留言」,文章內(nèi)容相關(guān)的優(yōu)質(zhì)留言才可上墻!留言點(diǎn)贊數(shù)量最多前5位讀者將獲得這本書,截止時間「11月12日20:00」,最終獲贈者通過留言聯(lián)系我。 PS:禁止任何機(jī)器等惡意刷贊行為,發(fā)現(xiàn)之后立刻取消精選資格。
推薦閱讀
美國大選拜登獲勝!硅谷 Python 開發(fā)者用這種方式調(diào)侃懂王 騷操作!嵌套 JSON 秒變 Dataframe! 我用 Python 寫了一個 PDF 轉(zhuǎn)換器! 兩篇畢業(yè)論文致謝同一個女朋友?哈哈哈哈! 太震撼了!我用Python畫出全北京的公交線路動圖 學(xué)習(xí)Anaconda一定要了解這幾件事 強(qiáng)勢回歸!比 Python 快 20% 的 Pyston v2.0 來了!
?分享、點(diǎn)贊、在看,給個三連擊唄!?