
【Python數(shù)據(jù)分析基礎(chǔ)】: 數(shù)據(jù)缺失值處理
關(guān)鍵時(shí)刻,第一時(shí)間送達(dá)!

作者:xiaoyu
閱讀全文需要10分鐘
圣人曾說(shuō)過(guò):數(shù)據(jù)和特征決定了機(jī)器學(xué)習(xí)的上限,而模型和算法只是逼近這個(gè)上限而已。
再好的模型,如果沒(méi)有好的數(shù)據(jù)和特征質(zhì)量,那訓(xùn)練出來(lái)的效果也不會(huì)有所提高。數(shù)據(jù)質(zhì)量對(duì)于數(shù)據(jù)分析而言是至關(guān)重要的,有時(shí)候它的意義會(huì)在某種程度上會(huì)勝過(guò)模型算法。
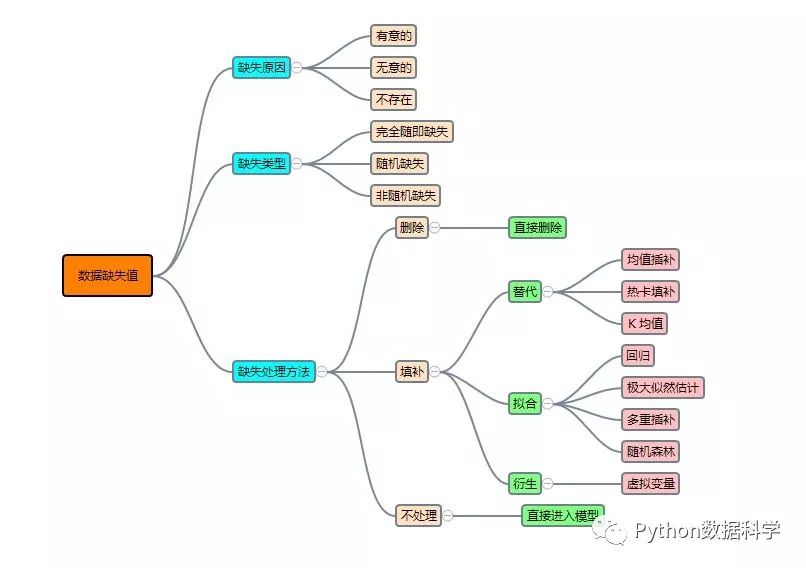
本篇開(kāi)始分享如何使用Python進(jìn)行數(shù)據(jù)分析,主要側(cè)重介紹一些分析的方法和技巧,而對(duì)于pandas和numpy等Pyhon計(jì)算包的使用會(huì)在問(wèn)題中提及,但不詳細(xì)介紹。本篇我們來(lái)說(shuō)說(shuō)面對(duì)數(shù)據(jù)的缺失值,我們?cè)撊绾翁幚怼N哪┯胁┲骺偨Y(jié)的思維導(dǎo)圖。
1?數(shù)據(jù)缺失的原因
首先我們應(yīng)該知道:數(shù)據(jù)為什么缺失?數(shù)據(jù)的缺失是我們無(wú)法避免的,可能的原因有很多種,博主總結(jié)有以下三大類:
無(wú)意的:信息被遺漏,比如由于工作人員的疏忽,忘記而缺失;或者由于數(shù)據(jù)采集器等故障等原因造成的缺失,比如系統(tǒng)實(shí)時(shí)性要求較高的時(shí)候,機(jī)器來(lái)不及判斷和決策而造成缺失;
有意的:有些數(shù)據(jù)集在特征描述中會(huì)規(guī)定將缺失值也作為一種特征值,這時(shí)候缺失值就可以看作是一種特殊的特征值;
不存在:有些特征屬性根本就是不存在的,比如一個(gè)未婚者的配偶名字就沒(méi)法填寫(xiě),再如一個(gè)孩子的收入狀況也無(wú)法填寫(xiě);
總而言之,對(duì)于造成缺失值的原因,我們需要明確:是因?yàn)槭韬龌蜻z漏無(wú)意而造成的,還是說(shuō)故意造成的,或者說(shuō)根本不存在。只有知道了它的來(lái)源,我們才能對(duì)癥下藥,做相應(yīng)的處理。
2?數(shù)據(jù)缺失的類型
在對(duì)缺失數(shù)據(jù)進(jìn)行處理前,了解數(shù)據(jù)缺失的機(jī)制和形式是十分必要的。將數(shù)據(jù)集中不含缺失值的變量稱為完全變量,數(shù)據(jù)集中含有缺失值的變量稱為不完全變量。而從缺失的分布來(lái)將缺失可以分為完全隨機(jī)缺失,隨機(jī)缺失和完全非隨機(jī)缺失。
完全隨機(jī)缺失(missing completely at random,MCAR):指的是數(shù)據(jù)的缺失是完全隨機(jī)的,不依賴于任何不完全變量或完全變量,不影響樣本的無(wú)偏性,如家庭地址缺失;
隨機(jī)缺失(missing at random,MAR):指的是數(shù)據(jù)的缺失不是完全隨機(jī)的,即該類數(shù)據(jù)的缺失依賴于其他完全變量,如財(cái)務(wù)數(shù)據(jù)缺失情況與企業(yè)的大小有關(guān);
非隨機(jī)缺失(missing not at random,MNAR):指的是數(shù)據(jù)的缺失與不完全變量自身的取值有關(guān),如高收入人群不原意提供家庭收入;
對(duì)于隨機(jī)缺失和非隨機(jī)缺失,直接刪除記錄是不合適的,原因上面已經(jīng)給出。隨機(jī)缺失可以通過(guò)已知變量對(duì)缺失值進(jìn)行估計(jì),而非隨機(jī)缺失的非隨機(jī)性還沒(méi)有很好的解決辦法。
3?數(shù)據(jù)缺失的處理方法
重點(diǎn)來(lái)了,對(duì)于各種類型數(shù)據(jù)的缺失,我們到底要如何處理呢?以下是處理缺失值的四種方法:刪除記錄,數(shù)據(jù)填補(bǔ),和不處理。
1. 刪除記錄
優(yōu)點(diǎn):
最簡(jiǎn)單粗暴;
缺點(diǎn):
犧牲了大量的數(shù)據(jù),通過(guò)減少歷史數(shù)據(jù)換取完整的信息,這樣可能丟失了很多隱藏的重要信息;
當(dāng)缺失數(shù)據(jù)比例較大時(shí),特別是缺失數(shù)據(jù)非隨機(jī)分布時(shí),直接刪除可能會(huì)導(dǎo)致數(shù)據(jù)發(fā)生偏離,比如原本的正態(tài)分布變?yōu)榉钦?/span>
這種方法在樣本數(shù)據(jù)量十分大且缺失值不多的情況下非常有效,但如果樣本量本身不大且缺失也不少,那么不建議使用。
Python中的使用:
可以使用?pandas?的?dropna?來(lái)直接刪除有缺失值的特征。
#刪除數(shù)據(jù)表中含有空值的行
df.dropna(how='any')
2. 數(shù)據(jù)填補(bǔ)
對(duì)缺失值的插補(bǔ)大體可分為兩種:替換缺失值,擬合缺失值,虛擬變量。替換是通過(guò)數(shù)據(jù)中非缺失數(shù)據(jù)的相似性來(lái)填補(bǔ),其核心思想是發(fā)現(xiàn)相同群體的共同特征,擬合是通過(guò)其他特征建模來(lái)填補(bǔ),虛擬變量是衍生的新變量代替缺失值。
替換缺失值
均值插補(bǔ):
注:此方法雖然簡(jiǎn)單,但是不夠精準(zhǔn),可能會(huì)引入噪聲,或者會(huì)改變特征原有的分布。
下圖左為填補(bǔ)前的特征分布,圖右為填補(bǔ)后的分布,明顯發(fā)生了畸變。因此,如果缺失值是隨機(jī)性的,那么用平均值比較適合保證無(wú)偏,否則會(huì)改變?cè)植肌?/span>
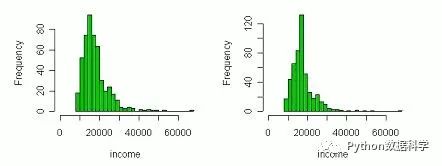
Python中的使用:
#使用price均值對(duì)NA進(jìn)行填充
df['price'].fillna(df['price'].mean())
df['price'].fillna(df['price'].median())
熱卡填補(bǔ)(Hot deck imputation):
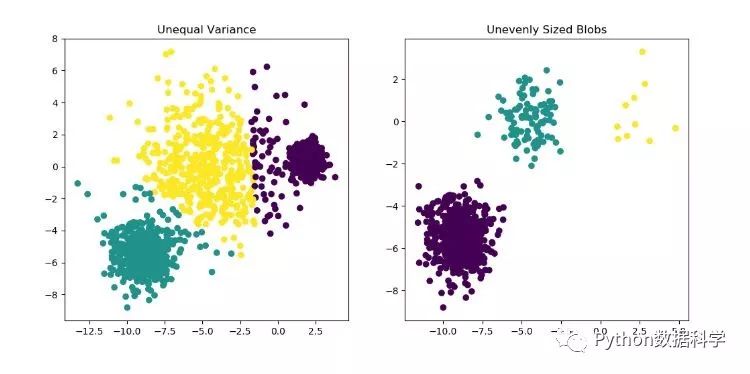
K最近距離鄰法(K-means clustering)
注:缺失值填補(bǔ)的準(zhǔn)確性就要看聚類結(jié)果的好壞了,而聚類結(jié)果的可變性很大,通常與初始選擇點(diǎn)有關(guān),并且在下圖中可看到單獨(dú)的每一類中特征值也有很大的差別,因此使用時(shí)要慎重。
擬合缺失值
擬合就是利用其它變量做模型的輸入進(jìn)行缺失變量的預(yù)測(cè),與我們正常建模的方法一樣,只是目標(biāo)變量變?yōu)榱巳笔е怠?/strong>
注:如果其它特征變量與缺失變量無(wú)關(guān),則預(yù)測(cè)的結(jié)果毫無(wú)意義。如果預(yù)測(cè)結(jié)果相當(dāng)準(zhǔn)確,則又說(shuō)明這個(gè)變量完全沒(méi)有必要進(jìn)行預(yù)測(cè),因?yàn)檫@必然是與特征變量間存在重復(fù)信息。一般情況下,會(huì)介于兩者之間效果為最好,若強(qiáng)行填補(bǔ)缺失值之后引入了自相關(guān),這會(huì)給后續(xù)分析造成障礙。
利用模型預(yù)測(cè)缺失變量的方法有很多,這里僅簡(jiǎn)單介紹幾種。
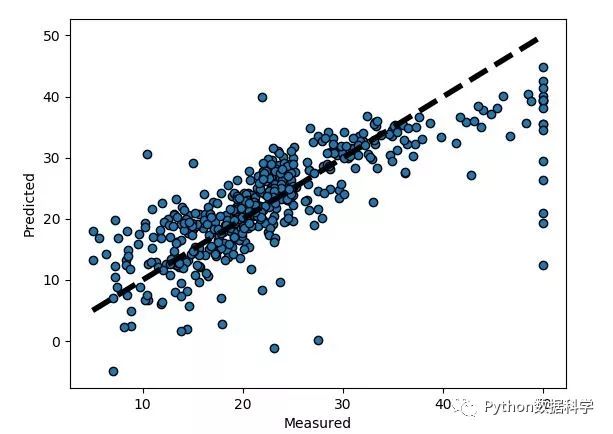
回歸預(yù)測(cè):
缺失值是連續(xù)的,即定量的類型,才可以使用回歸來(lái)預(yù)測(cè)。
極大似然估計(jì)(Maximum likelyhood):
多重插補(bǔ)(Mutiple imputation):
為每個(gè)缺失值產(chǎn)生一套可能的插補(bǔ)值,這些值反映了無(wú)響應(yīng)模型的不確定性;
每個(gè)插補(bǔ)數(shù)據(jù)集合都用針對(duì)完整數(shù)據(jù)集的統(tǒng)計(jì)方法進(jìn)行統(tǒng)計(jì)分析;
對(duì)來(lái)自各個(gè)插補(bǔ)數(shù)據(jù)集的結(jié)果,根據(jù)評(píng)分函數(shù)進(jìn)行選擇,產(chǎn)生最終的插補(bǔ)值;
根據(jù)數(shù)據(jù)缺失機(jī)制、模式以及變量類型,可分別采用回歸、預(yù)測(cè)均數(shù)匹配( predictive mean matching, PMM )、趨勢(shì)得分( propensity score, PS )、Logistic回歸、判別分析以及馬爾可夫鏈蒙特卡羅( Markov Chain Monte Carlo, MCMC) 等不同的方法進(jìn)行填補(bǔ)。
假設(shè)一組數(shù)據(jù),包括三個(gè)變量Y1,Y2,Y3,它們的聯(lián)合分布為正態(tài)分布,將這組數(shù)據(jù)處理成三組,A組保持原始數(shù)據(jù),B組僅缺失Y3,C組缺失Y1和Y2。在多值插補(bǔ)時(shí),對(duì)A組將不進(jìn)行任何處理,對(duì)B組產(chǎn)生Y3的一組估計(jì)值(作Y3關(guān)于Y1,Y2的回歸),對(duì)C組作產(chǎn)生Y1和Y2的一組成對(duì)估計(jì)值(作Y1,Y2關(guān)于Y3的回歸)。?
當(dāng)用多值插補(bǔ)時(shí),對(duì)A組將不進(jìn)行處理,對(duì)B、C組將完整的樣本隨機(jī)抽取形成為m組(m為可選擇的m組插補(bǔ)值),每組個(gè)案數(shù)只要能夠有效估計(jì)參數(shù)就可以了。對(duì)存在缺失值的屬性的分布作出估計(jì),然后基于這m組觀測(cè)值,對(duì)于這m組樣本分別產(chǎn)生關(guān)于參數(shù)的m組估計(jì)值,給出相應(yīng)的預(yù)測(cè),這時(shí)采用的估計(jì)方法為極大似然法,在計(jì)算機(jī)中具體的實(shí)現(xiàn)算法為期望最大化法(EM)。對(duì)B組估計(jì)出一組Y3的值,對(duì)C將利用Y1,Y2,Y3它們的聯(lián)合分布為正態(tài)分布這一前提,估計(jì)出一組(Y1,Y2)。
?
上例中假定了Y1,Y2,Y3的聯(lián)合分布為正態(tài)分布。這個(gè)假設(shè)是人為的,但是已經(jīng)通過(guò)驗(yàn)證(Graham和Schafer于1999),非正態(tài)聯(lián)合分布的變量,在這個(gè)假定下仍然可以估計(jì)到很接近真實(shí)值的結(jié)果。?
注:使用多重插補(bǔ)要求數(shù)據(jù)缺失值為隨機(jī)性缺失,一般重復(fù)次數(shù)20-50次精準(zhǔn)度很高,但是計(jì)算也很復(fù)雜,需要大量計(jì)算。
隨機(jī)森林:
def?set_missing_ages(df):
????#?把已有的數(shù)值型特征取出來(lái)丟進(jìn)Random?Forest?Regressor中
????age_df?=?df[['Age','Fare',?'Parch',?'SibSp',?'Pclass']]
????#?乘客分成已知年齡和未知年齡兩部分
????known_age?=?age_df[age_df.Age.notnull()].as_matrix()
????unknown_age?=?age_df[age_df.Age.isnull()].as_matrix()
????#?y即目標(biāo)年齡
????y?=?known_age[:,?0]
????#?X即特征屬性值
????X?=?known_age[:,?1:]
????#?fit到RandomForestRegressor之中
????rfr?=?RandomForestRegressor(random_state=0,?n_estimators=2000,?n_jobs=-1)
????rfr.fit(X,?y)
????#?用得到的模型進(jìn)行未知年齡結(jié)果預(yù)測(cè)
????predictedAges?=?rfr.predict(unknown_age[:,?1:])
#?????print?predictedAges
????#?用得到的預(yù)測(cè)結(jié)果填補(bǔ)原缺失數(shù)據(jù)
????df.loc[?(df.Age.isnull()),?'Age'?]?=?predictedAges?
????return?df,?rfr虛擬變量
data_train['CabinCat']?=?data_train['Cabin'].copy()
data_train.loc[?(data_train.CabinCat.notnull()),?'CabinCat'?]?=?"No"
data_train.loc[?(data_train.CabinCat.isnull()),?'CabinCat'?]?=?"Yes"
fig,?ax?=?plt.subplots(figsize=(10,5))
sns.countplot(x='CabinCat',?hue='Survived',data=data_train)
plt.show()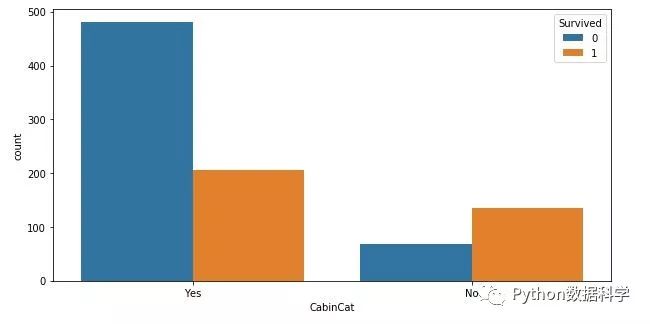
下面可以通過(guò)一行代碼清楚看到衍生的虛擬變量。
data_train[['Cabin','CabinCat']].head(10)
3. 不處理
4?總結(jié)
總而言之,大部分?jǐn)?shù)據(jù)挖掘的預(yù)處理都會(huì)使用比較方便的方法來(lái)處理缺失值,比如均值法,但是效果上并一定好,因此還是需要根據(jù)不同的需要選擇合適的方法,并沒(méi)有一個(gè)解決所有問(wèn)題的萬(wàn)能方法。具體的方法采用還需要考慮多個(gè)方面的:
數(shù)據(jù)缺失的原因;
數(shù)據(jù)缺失值類型;
樣本的數(shù)據(jù)量;
數(shù)據(jù)缺失值隨機(jī)性等;
關(guān)于數(shù)據(jù)缺失值得思維導(dǎo)圖:
如果大家有任何好的其他方法,歡迎補(bǔ)充。
參考:
http://www.restore.ac.uk/PEAS/imputation.php
https://blog.csdn.net/lujiandong1/article/details/52654703
http://blog.sina.com.cn/s/blog_4b0f1da60101d8yb.html
https://www.cnblogs.com/Acceptyly/p/3985687.html
推薦閱讀:
【1】【Kaggle入門(mén)級(jí)競(jìng)賽top5%排名經(jīng)驗(yàn)分享】— 分析篇
【4】一套為你【量身定制】的數(shù)據(jù)分析學(xué)習(xí)路線
【5】【精華分享】:轉(zhuǎn)行數(shù)據(jù)分析的一份學(xué)習(xí)清單
【6】轉(zhuǎn)行數(shù)據(jù)分析的親身經(jīng)歷