
谷歌提出最新時(shí)序框架--Deep Transformer
Deep Transformer Models for TSF

Transformer技術(shù)在諸多問(wèn)題,例如翻譯,文本分類(lèi),搜索推薦問(wèn)題中都取得了巨大的成功,那么能否用于時(shí)間序列相關(guān)的數(shù)據(jù)呢?答案是肯定的,而且效果非常棒。本篇文章我們就基于Transformer的方法動(dòng)態(tài)地學(xué)習(xí)時(shí)間序列數(shù)據(jù)的復(fù)雜模式,并且在時(shí)間序列相關(guān)的問(wèn)題上取得了目前最好的效果。
問(wèn)題定義
假設(shè)時(shí)間序列有個(gè)每周的數(shù)據(jù)點(diǎn):
對(duì)于一個(gè)步的預(yù)測(cè),監(jiān)督的ML模型的輸入就是
我們輸出的就是:
每個(gè)輸出點(diǎn)可以是一個(gè)標(biāo)量或者是一個(gè)包含了大量特征的向量。
模型框架
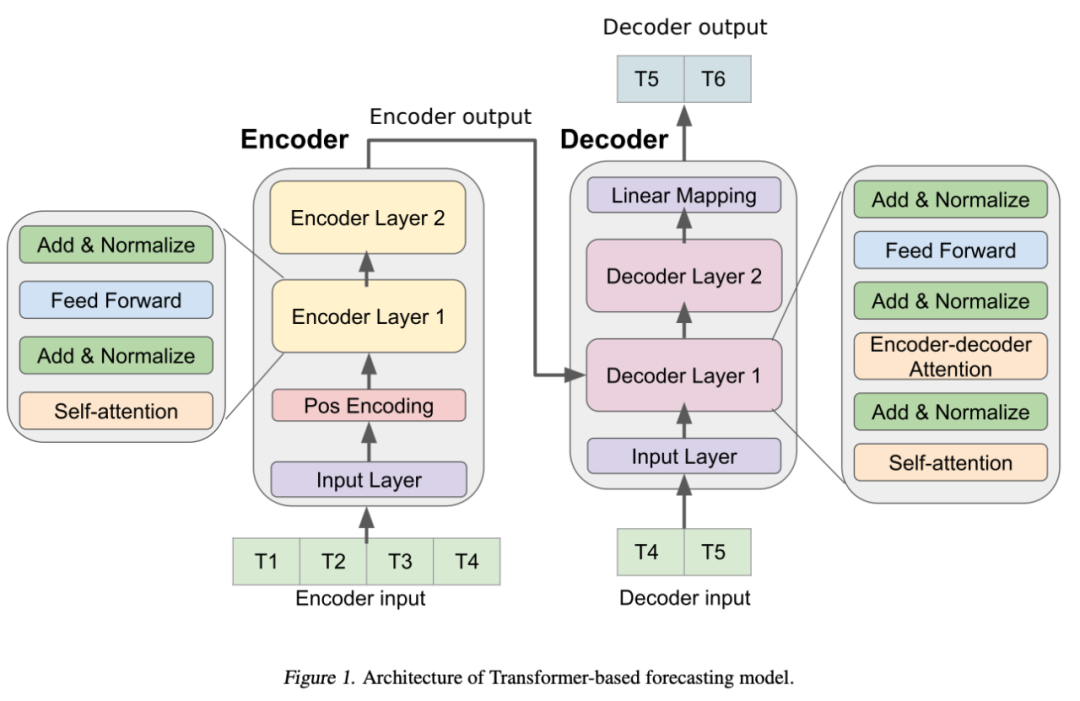
1. Encoder
Encoder由輸入層、位置編碼層和四個(gè)相同編碼器層的堆棧組成。
輸入層通過(guò)一個(gè)完全連接的網(wǎng)絡(luò)將輸入的時(shí)間序列數(shù)據(jù)映射到一個(gè)維度為的向量。這一步對(duì)于模型采用多頭注意機(jī)制至關(guān)重要。
使用sin和cos函數(shù)的位置編碼,通過(guò)將輸入向量與位置編碼向量按元素相加,對(duì)時(shí)間序列數(shù)據(jù)中的順序信息進(jìn)行編碼。
最終的向量被輸入到四個(gè)encoder層。每個(gè)encoder層由兩個(gè)子層組成:一個(gè)self-attention的子層和一個(gè)全連接的前饋?zhàn)訉印C總€(gè)子層后面都有一個(gè)normalization層。編碼器生成一個(gè)維向量,往后傳入decoder層。
2. decoder層
此處Transformer的Decoder設(shè)計(jì)架構(gòu)和最早的Transformer是類(lèi)似的。Decoder包括輸入層、四個(gè)相同的解碼器層和一個(gè)輸出層。Decoder輸入從編碼器輸入的最后一個(gè)數(shù)據(jù)點(diǎn)開(kāi)始。輸入層將解碼器輸入映射到維向量。除了每個(gè)編碼器層中的兩個(gè)子層之外,解碼器插入第三個(gè)子層以在編碼器輸出上應(yīng)用自注意機(jī)制。
最后,還有一個(gè)輸出層,它將最后一個(gè)Decoder層的輸出映射到目標(biāo)時(shí)間序列。
我們?cè)诮獯a器中使用前l(fā)ook-ahead masking和在輸入和目標(biāo)輸出之間的one-position的偏移,以確保時(shí)間序列數(shù)據(jù)點(diǎn)的預(yù)測(cè)將僅依賴(lài)于先前的數(shù)據(jù)點(diǎn)。
效果比較
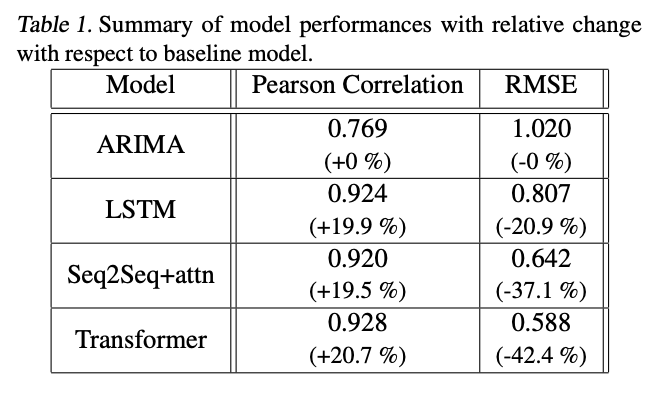
Transformer架構(gòu)的效果遠(yuǎn)好于其他的效果
Time Delay Embedding實(shí)驗(yàn)
對(duì)于一個(gè)標(biāo)量的序列數(shù)據(jù),它的delay embedding(TDE)就是將每個(gè)scalar值映射到一個(gè)唯獨(dú)的time-delay的空間,
我們發(fā)現(xiàn)并非是越大越好,在5-7之間是最好的。
本文提出的基于Transformer的時(shí)間序列數(shù)據(jù)預(yù)測(cè)方法。與其他序列對(duì)齊的深度學(xué)習(xí)方法相比,
Transformer的方法利用self-attention對(duì)序列數(shù)據(jù)進(jìn)行建模,可以從時(shí)間序列數(shù)據(jù)中學(xué)習(xí)不同長(zhǎng)度的復(fù)雜依賴(lài)關(guān)系。 基于Transformer的方案具有非常好的可擴(kuò)展性,適用于單變量和多變量時(shí)間序列數(shù)據(jù)的建模,只需對(duì)模型實(shí)現(xiàn)進(jìn)行最小的修改。
https://arxiv.org/pdf/2001.08317.pdf