
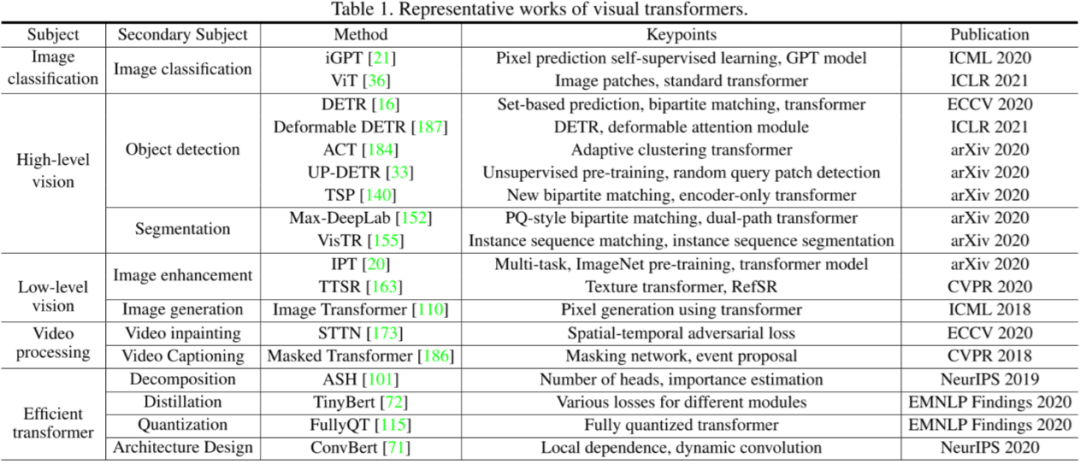
視覺Transformer最新綜述


論文標(biāo)題:
A Survey on Visual Transformer
論文鏈接:
https://arxiv.org/pdf/2012.12556.pdf

Formulation of Transformer

計(jì)算不同輸入向量的得分? 為了梯度的穩(wěn)定性進(jìn)行歸一化? 將得分轉(zhuǎn)化為概率? 最后得到加權(quán)的矩陣?
這整個過程可以被統(tǒng)一為一個簡單的函數(shù):
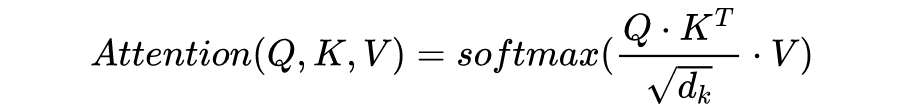
直觀來看,第 1 步計(jì)算兩個不同向量之間的分?jǐn)?shù),這個分?jǐn)?shù)用來確定我們在當(dāng)前位置編碼單詞時對其他單詞的注意程度。步驟 2 標(biāo)準(zhǔn)化得分,使其具有更穩(wěn)定的梯度,以便更好地訓(xùn)練;步驟 3 將得分轉(zhuǎn)換為概率。最后,將每個值向量乘以概率的總和,概率越大的向量將被下面幾層更多地關(guān)注。
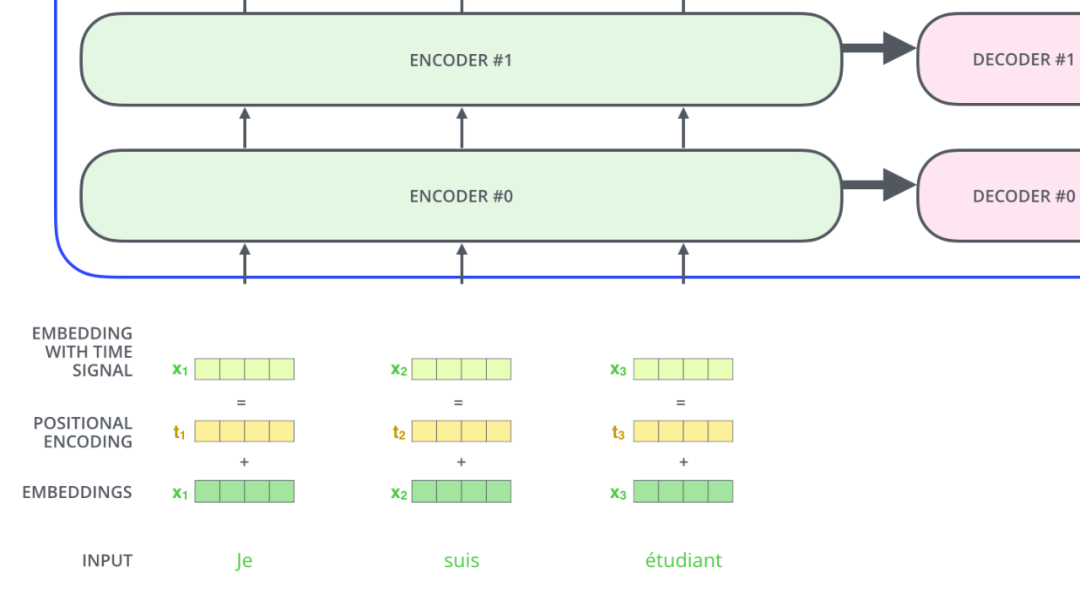
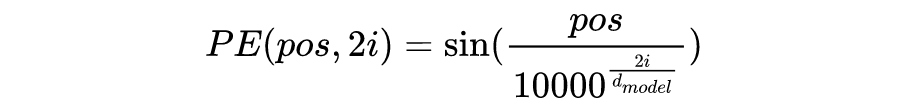
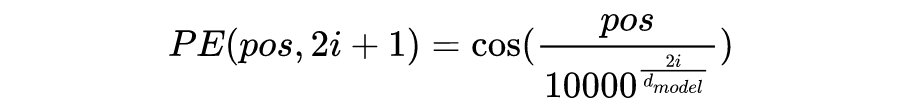
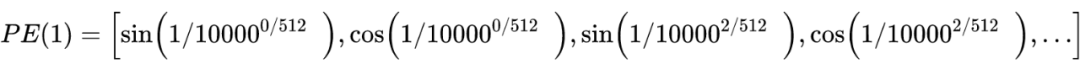
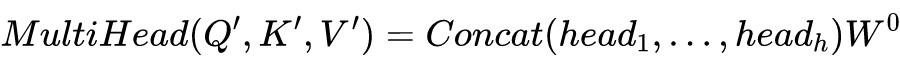
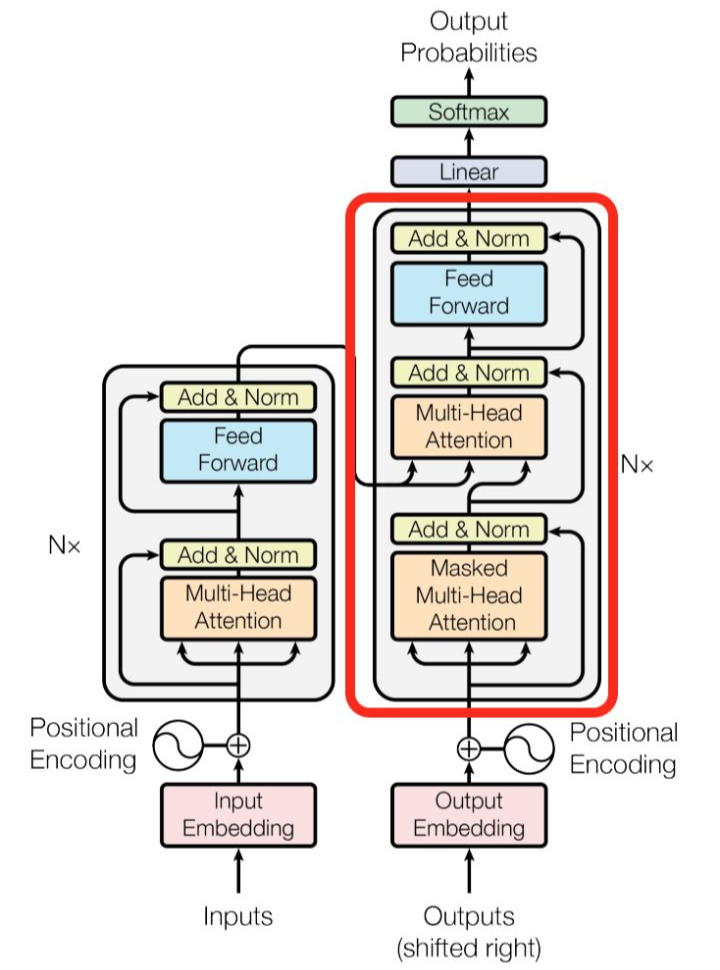
這就是基本的 Multihead Attention 單元,對于 encoder 來說就是利用這些基本單元疊加,其中 key, query, value 均來自前一層 encoder 的輸出,即 encoder 的每個位置都可以注意到之前一層 encoder 的所有位置。
對于 decoder 來講,我們注意到有兩個與 encoder 不同的地方,一個是第一級的 Masked Multi-head,另一個是第二級的 Multi-Head Attention 不僅接受來自前一級的輸出,還要接收 encoder 的輸出,下面分別解釋一下是什么原理。
第一級 decoder 的 key, query, value 均來自前一層 decoder 的輸出,但加入了 Mask 操作,即我們只能attend到前面已經(jīng)翻譯過的輸出的詞語,因?yàn)榉g過程我們當(dāng)前還并不知道下一個輸出詞語,這是我們之后才會推測到的。
而第二級 decoder 也被稱作 encoder-decoder attention layer,即它的 query 來自于之前一級的 decoder 層的輸出,但其 key 和 value 來自于 encoder 的輸出,這使得 decoder 的每一個位置都可以 attend 到輸入序列的每一個位置。
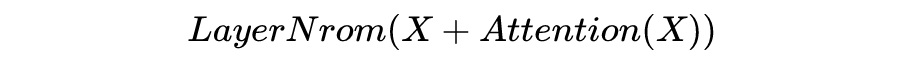
大多數(shù)用于計(jì)算機(jī)視覺任務(wù)的 Transformer 都使用原編碼器模塊。總之,它可以被視為一種不同于 CNN 和遞歸神經(jīng)網(wǎng)絡(luò) RNN 的新型特征選擇器。與只關(guān)注局部特征的 CNN 相比,transformer 能夠捕捉到長距離特征,這意味著 transformer 可以很容易地獲得全局信息。

Transformers 出現(xiàn)后,克服了RNN訓(xùn)練速度慢的缺陷,使得大規(guī)模預(yù)訓(xùn)練模型成為可能。BETR 及其變種(SpanBERT,RoBERTa)等都是基于 transformer 的模型。在 BERT 的預(yù)訓(xùn)練階段,對 BookCorpus 和英語維基百科數(shù)據(jù)集進(jìn)行了兩個任務(wù)
Mask 一部分 token 讓模型來預(yù)測。
輸入兩個句子讓模型預(yù)測第二個句子是否是文檔中的原始句子。在預(yù)訓(xùn)練之后,BERT 可以添加一個輸出層在下游任務(wù)進(jìn)行 fine-tune。在執(zhí)行序列級任務(wù)(如情感分析)時,BERT 使用第一個 token 的表示進(jìn)行分類;而對于 token 級別的任務(wù)(例如,名稱實(shí)體識別),所有 token 都被送入 softmax 層進(jìn)行分類。
Generative Pre-Trained Transformer(GPT2,GPT3)是另一種基于 Transformer 解碼器架構(gòu)的預(yù)訓(xùn)練模型,它使用了帶掩碼的自我注意機(jī)制。
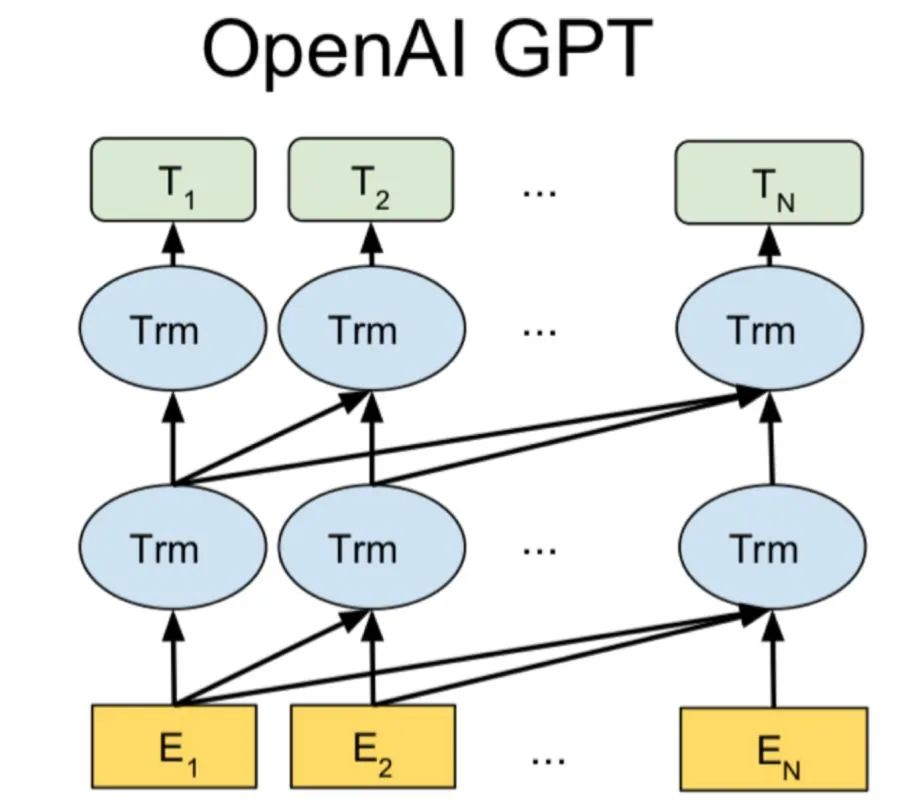
還有一些多模態(tài)的 transformer 和這篇文章比較相關(guān),可以簡單了解一下。VideoBERT 使用基于 CNN 的 module 將圖像轉(zhuǎn)化為 token,然后使用 transformer 的 encoder 來為下游任務(wù)學(xué)習(xí)一個 video-text representation。

圖像作為一種高維、噪聲大、冗余度高的形態(tài),被認(rèn)為是生成建模的難點(diǎn),這也是為什么過了好幾年,transformer 才應(yīng)用到視覺領(lǐng)域。比較初始的應(yīng)用是在 Visual Transformer 一文中,作者使用 CNN 提取 low-level 的特征,然后將這些特征輸 入Visual Transformer [1](VT)。
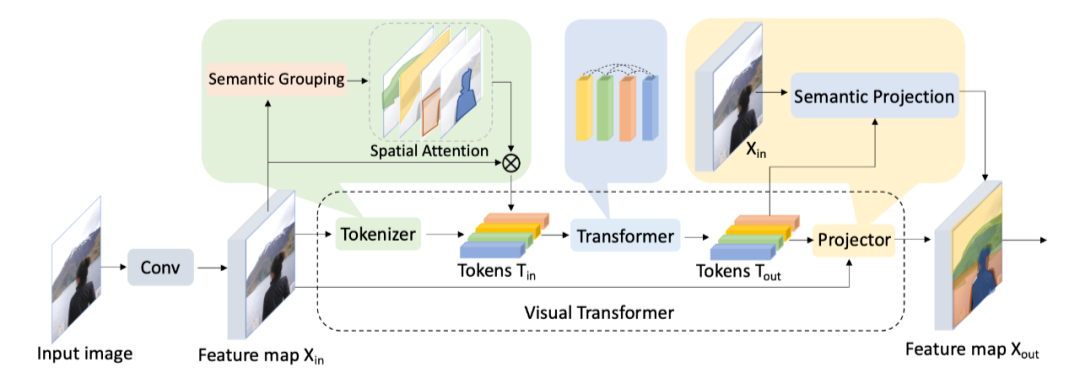
與這項(xiàng)工作不同的是,最近出現(xiàn)的 iGPT , ViT 和 DeiT 都是只使用 transformer 的文章。
在 CV 中使用 transformer,目前來看主要的兩個問題,以及下列文章的核心區(qū)別在于:
得到 Token 的方式
訓(xùn)練的方式
評估 representation 的方式
3.1.1 iGPT

論文標(biāo)題:Generative Pretraining from Pixels
論文鏈接:https://cdn.openai.com/papers/Generative_Pretraining_from_Pixels_V2.pdf
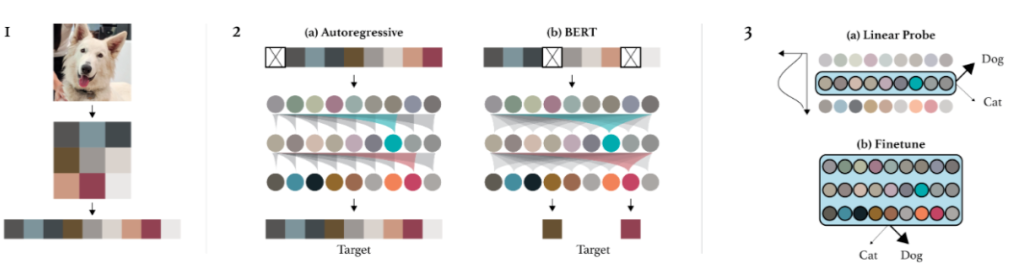
nn.Embedding(num_vocab, embed_dim)提取每個像素 embedding。至此圖片數(shù)據(jù)已經(jīng)完全轉(zhuǎn)化為了 transformer 的輸入形式 。其中 seq_len 取決于 down sample 保留了多少 pixel。attn_mask?=?torch.full(
????????(len(x),?len(x)),?-float("Inf"),?device=x.device,?dtype=x.dtype
)
attn_mask?=?torch.triu(attn_mask,?diagonal=1)#[784,?784]
#attn_mask?=?[[0,-inf,-inf...,-inf],
#????????????[0,0,-inf,...,-inf],
#????????????[0,0,0,...,-inf],
#????????????[0,0,0,...,0]]
Evaluation:兩種評估方式:1)fine-tune:增加了一個小的分類頭,用于優(yōu)化分類目標(biāo)并 adapt 所有權(quán)重;2)Linear-probe:將 pretraining 的模型視作特征提取器,增加一個分類頭,只訓(xùn)練這個分類頭。第二種方式的直覺在于“一個好的特征應(yīng)該能夠區(qū)分不同的類”,除此之外,fine-tune 效果好有可能是因?yàn)榧軜?gòu)很適合下游任務(wù),但是 linear-probe 只取決于特征質(zhì)量。
主要過程的代碼如下,數(shù)字只是為了示例,下面假設(shè)字典長度為 16(pixel 一共 16 種)。
#?x:原始圖像處理后得到的序列?[32*32,?64],64為batchsize,32是下采樣后的長款
length,?batch?=?x.shape
#?將每個pixel作為token求embedding,128為embedding的維度
h?=?self.token_embeddings(x)?#?[32*32,?64,?128]
#?添加位置編碼
h?=?h?+?self.position_embeddings(positions).expand_as(h)
#?transformer
for?layer?in?self.layers:
????h?=?layer(h)
#?自回歸編碼需要輸出logits,映射回字典長度
logits?=?self.head(h)?#?[32*32,64,16]
#?16類的cross_entropy,對每個pixel計(jì)算損失
loss?=?self.criterion(logits.view(-1,?logits.size(-1)),?x.view(-1))
3.1.2 ViT

論文標(biāo)題:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
論文鏈接:https://arxiv.org/abs/2010.11929
代碼鏈接:https://github.com/google-research/vision_transformer
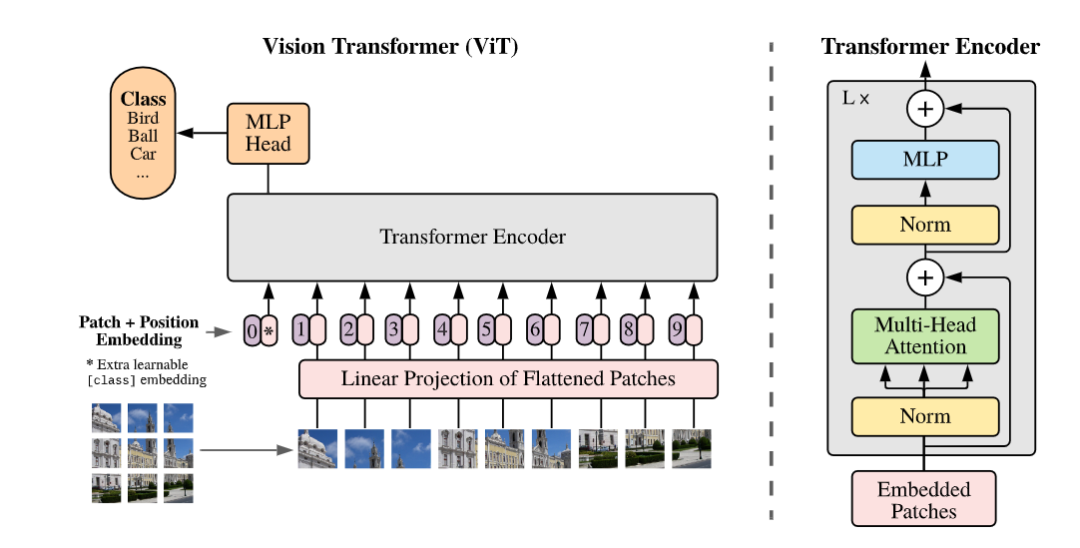
Pretrain:傳統(tǒng)情況下 ViT 也是要預(yù)訓(xùn)練的,不同于 iGPT,這不是一個生成式的模型,只采用了 transformer 的 encoder,因此直接在 imagenet 做分類任務(wù)進(jìn)行 pretrain。文章顯示數(shù)據(jù)集小的時候效果一般,數(shù)據(jù)集大的時候因?yàn)?data bias 已經(jīng)被消除了很多,此時效果非常好。
Evaluation:分類任務(wù)的評價(jià)不再多說。
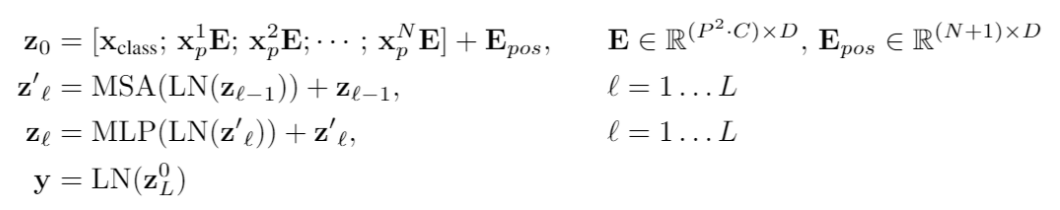
3.2.1 Generic Object Detection
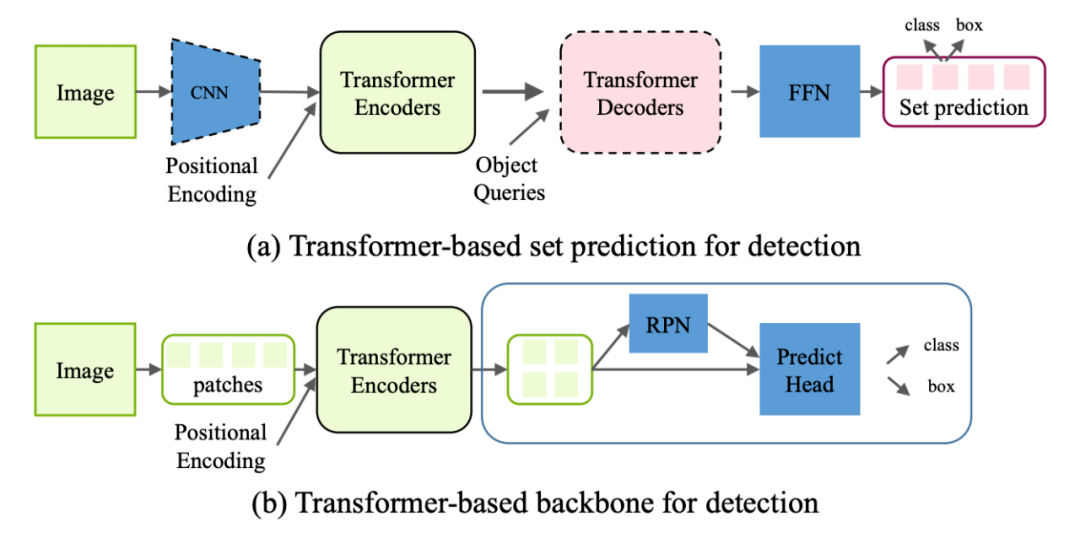
Transformer-based set prediction for detection. DETR [2]?是這類工作的先驅(qū),其將目標(biāo)檢測視為集合預(yù)測問題,去掉了目標(biāo)檢測種很多手工的組件像 NMS,anchor generation 等。
Train:如何將 object detection 轉(zhuǎn)化為 set prediction 然后進(jìn)行訓(xùn)練,這是一個非常有意思的問題。作者使用了 object queries,這實(shí)際上是另一組可學(xué)習(xí)的 positional embedding,其功能類似于 anchor。之后每個 query 進(jìn)過 decoder 后算一個 bbox 和 class prob。
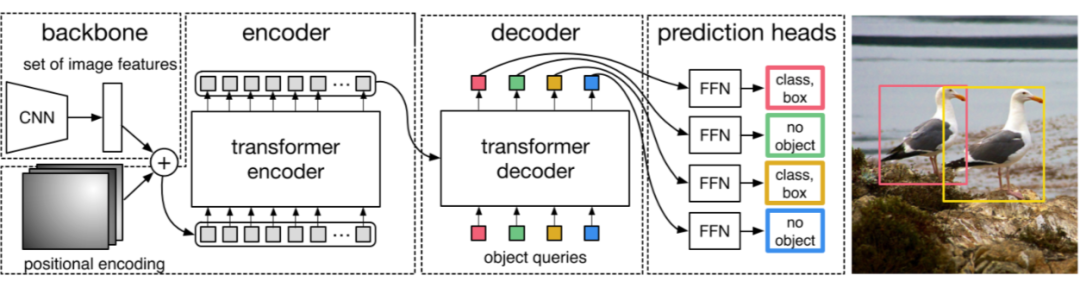
DETR 也大方地承認(rèn)了他的缺點(diǎn):訓(xùn)練周期長,對小物體檢測效果差。
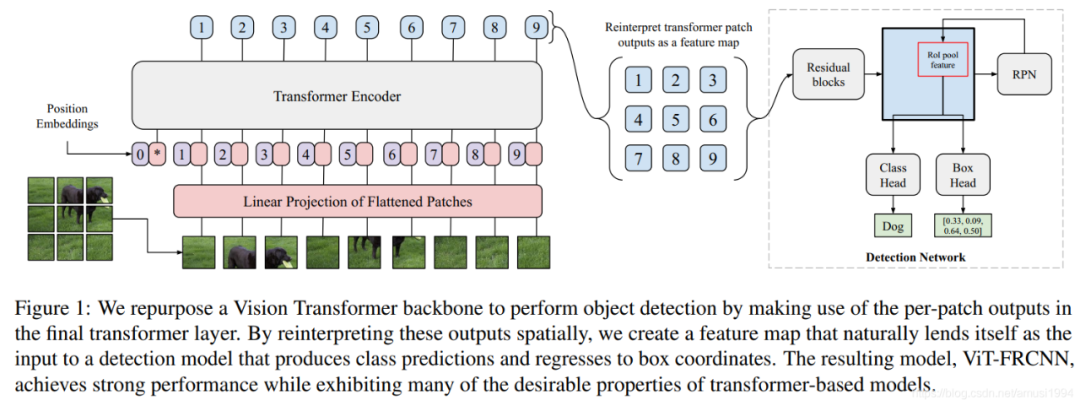
總結(jié)一下,目前 transformer 已經(jīng)在很多視覺應(yīng)用中展現(xiàn)出了強(qiáng)大的實(shí)力。使用 transformer 最重要的兩個問題是如何得到輸入的 embedding(妥善處理position embedding),模型的訓(xùn)練與評估。
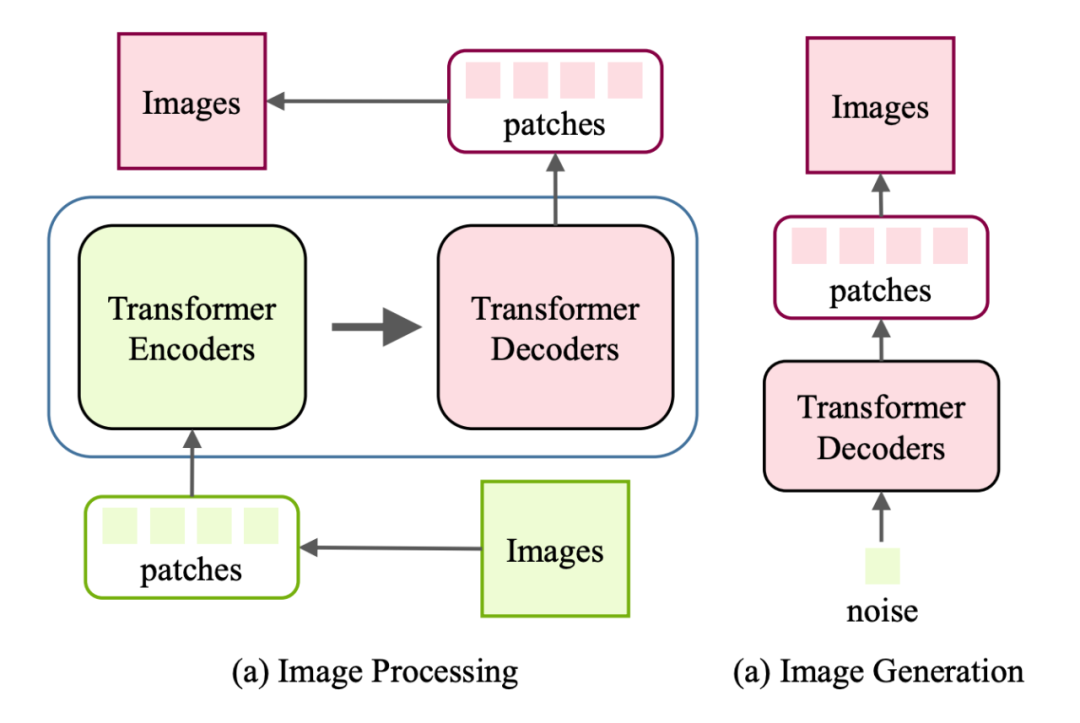
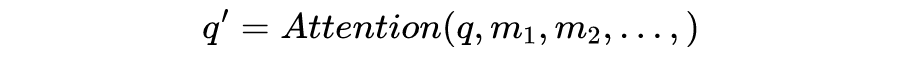
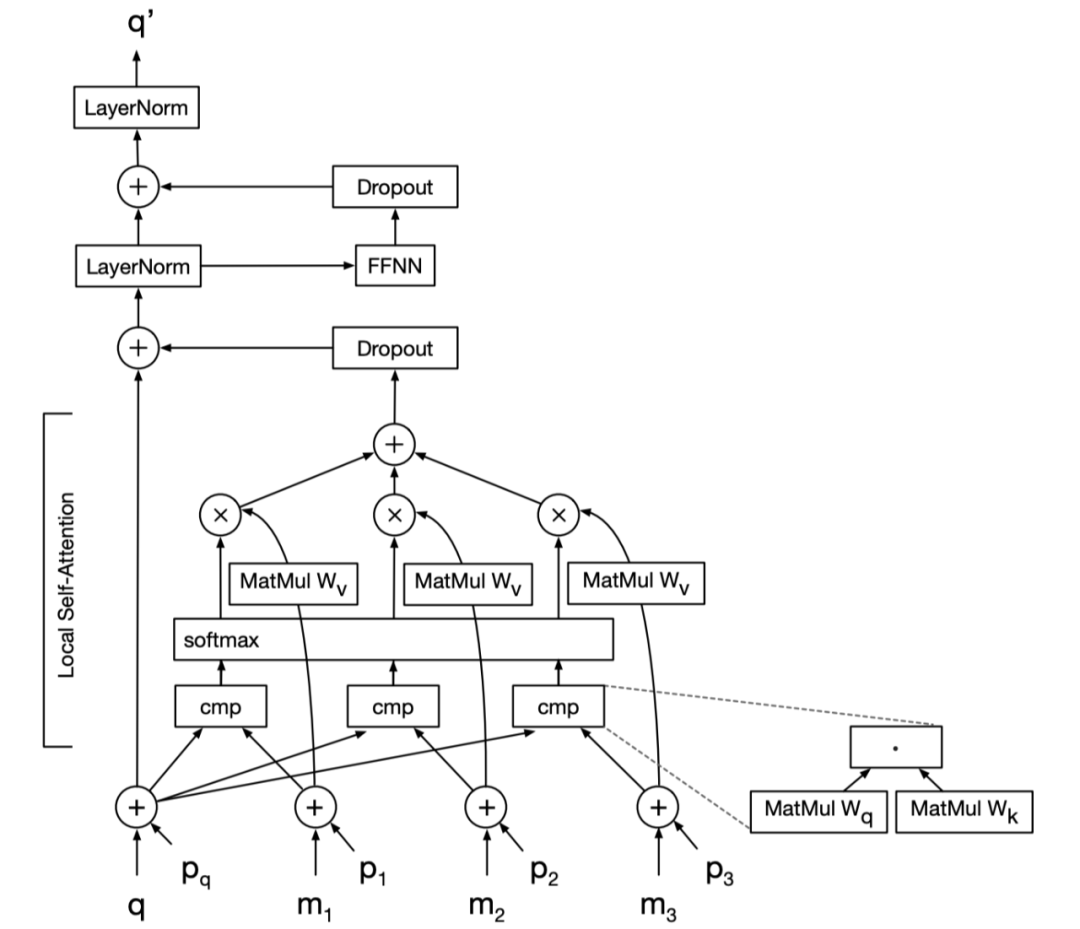
由于解碼器的輸入是原生成的像素,在生成高分辨率圖像時會帶來較大的計(jì)算成本,因此提出了一種局部自注意方案,只使用最接近的生成像素作為解碼器的輸入。結(jié)果表明,該圖像轉(zhuǎn)換器在圖像生成和翻譯任務(wù)上與基于 cnn 的模型具有競爭性能,表明了基于轉(zhuǎn)換器的模型在低層次視覺任務(wù)上的有效性。

Conclusions and Discussions
4.1 Challenges
目前來看,大多數(shù)應(yīng)用都保留了 transformer 在 NLP 任務(wù)中的原始形態(tài),這一形態(tài)不一定適合 images,因此是否會有改進(jìn)版本,更加適合視覺任務(wù)的 transformer 尚且未知。除此之外,transformer 需要的數(shù)據(jù)量太大,缺少像 CNN 一樣的 inductive biases,我們也很難解釋他為什么 work,在本就是黑盒的DL領(lǐng)域又套了一層黑盒。
像 NLP 一樣的大一統(tǒng)模型,一個 transformer 解決所有下游任務(wù)。 高效的部署與運(yùn)行。 可解釋性。

參考文獻(xiàn)
推薦閱讀
GPU底層優(yōu)化 | 如何讓Transformer在GPU上跑得更快?
如何看待Transformer在CV上的應(yīng)用前景,未來有可能替代CNN嗎?

