
SQL優(yōu)化的魅力!從 30248s 到 0.001s

閱讀本文大概需要 7.5 分鐘。
來自:cnblogs.com/tangyanbo/p/4462734.html
場景
create table Course(
c_id int PRIMARY KEY,
name varchar(10)
)
create table Student(
id int PRIMARY KEY,
name varchar(10)
)
CREATE table SC(
sc_id int PRIMARY KEY,
s_id int,
c_id int,
score int
)
select s.* from Student s
where s.s_id in (
select s_id
from SC sc
where sc.c_id = 0 and sc.score = 100 )
EXPLAIN
select s.* from Student s
where s.s_id in (
select s_id
from SC sc
where sc.c_id = 0 and sc.score = 100 )

CREATE index sc_c_id_index on SC(c_id);
CREATE index sc_score_index on SC(score);

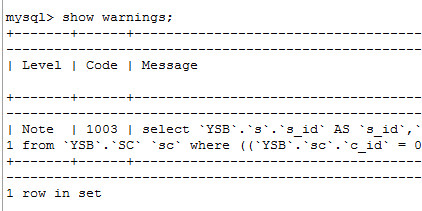
SELECT
`YSB`.`s`.`s_id` AS `s_id`,
`YSB`.`s`.`name` AS `name`
FROM
`YSB`.`Student` `s`
WHERE
< in_optimizer > (
`YSB`.`s`.`s_id` ,< EXISTS > (
SELECT
1
FROM
`YSB`.`SC` `sc`
WHERE
(
(`YSB`.`sc`.`c_id` = 0)
AND (`YSB`.`sc`.`score` = 100)
AND (
< CACHE > (`YSB`.`s`.`s_id`) = `YSB`.`sc`.`s_id`
)
)
)
)
select s_id
from SC sc
where sc.c_id = 0 and sc.score = 100
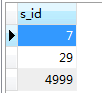
select s.*
from Student s
where s.s_id in(7,29,5000)
SELECT s.* from
Student s
INNER JOIN SC sc
on sc.s_id = s.s_id
where sc.c_id=0 and sc.score=100
sc_c_id_index,sc_score_index 。
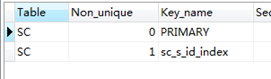
CREATE index sc_s_id_index on SC(s_id);
show index from SC

SELECT
`YSB`.`s`.`s_id` AS `s_id`,
`YSB`.`s`.`name` AS `name`
FROM
`YSB`.`Student` `s`
JOIN `YSB`.`SC` `sc`
WHERE
(
(
`YSB`.`sc`.`s_id` = `YSB`.`s`.`s_id`
)
AND (`YSB`.`sc`.`score` = 100)
AND (`YSB`.`sc`.`c_id` = 0)
)

SELECT
s.*
FROM
(
SELECT
*
FROM
SC sc
WHERE
sc.c_id = 0
AND sc.score = 100
) t
INNER JOIN Student s ON t.s_id = s.s_id

CREATE index sc_c_id_index on SC(c_id);
CREATE index sc_score_index on SC(score);
SELECT
s.*
FROM
(
SELECT
*
FROM
SC sc
WHERE
sc.c_id = 0
AND sc.score = 100
) t
INNER JOIN Student s ON t.s_id = s.s_id

SELECT s.* from
Student s
INNER JOIN SC sc
on sc.s_id = s.s_id
where sc.c_id=0 and sc.score=100

show index from SC
SELECT s.* from
Student s
INNER JOIN SC sc
on sc.s_id = s.s_id
where sc.c_id=81 and sc.score=84

c_id=81檢索的結果是70001,score=84的結果是39425。c_id=81 and score=84 的結果是897,即這兩個字段聯合起來的區(qū)分度是比較高的,因此建立聯合索引查詢效率。alter table SC drop index sc_c_id_index;
alter table SC drop index sc_score_index;
create index sc_c_id_score_index on SC(c_id,score);

總結
mysql嵌套子查詢效率確實比較低 可以將其優(yōu)化成連接查詢 連接表時,可以先用where條件對表進行過濾,然后做表連接
(雖然mysql會對連表語句做優(yōu)化)建立合適的索引,必要時建立多列聯合索引 學會分析sql執(zhí)行計劃,mysql會對sql進行優(yōu)化,所以分析執(zhí)行計劃很重要
索引優(yōu)化
單列索引
select * from user_test_copy where sex = 2 and type = 2 and age = 10
CREATE index user_test_index_sex on user_test_copy(sex);
CREATE index user_test_index_type on user_test_copy(type);
CREATE index user_test_index_age on user_test_copy(age);

type=index_merge多列索引
create index user_test_index_sex_type_age on user_test(sex,type,age);
select * from user_test where sex = 2 and type = 2 and age = 10

select * from user_test where sex = 2
select * from user_test where sex = 2 and type = 2
select * from user_test where sex = 2 and age = 10
索引覆蓋
select sex,type,age from user_test where sex = 2 and type = 2 and age = 10
排序
select * from user_test where sex = 2 and type = 2 ORDER BY user_name
create index user_name_index on user_test(user_name)
列類型盡量定義成數值類型,且長度盡可能短,如主鍵和外鍵,類型字段等等
建立單列索引
根據需要建立多列聯合索引
當單個列過濾之后還有很多數據,那么索引的效率將會比較低,即列的區(qū)分度較低,
那么如果在多個列上建立索引,那么多個列的區(qū)分度就大多了,將會有顯著的效率提高。根據業(yè)務場景建立覆蓋索引
只查詢業(yè)務需要的字段,如果這些字段被索引覆蓋,將極大的提高查詢效率多表連接的字段上需要建立索引 這樣可以極大的提高表連接的效率
where條件字段上需要建立索引
排序字段上需要建立索引
分組字段上需要建立索引
Where條件上不要使用運算函數,以免索引失效
推薦閱讀:
Lombok原理和同時使?@Data和@Builder 的坑
互聯網初中高級大廠面試題(9個G) 內容包含Java基礎、JavaWeb、MySQL性能優(yōu)化、JVM、鎖、百萬并發(fā)、消息隊列、高性能緩存、反射、Spring全家桶原理、微服務、Zookeeper......等技術棧!
?戳閱讀原文領取! 朕已閱
