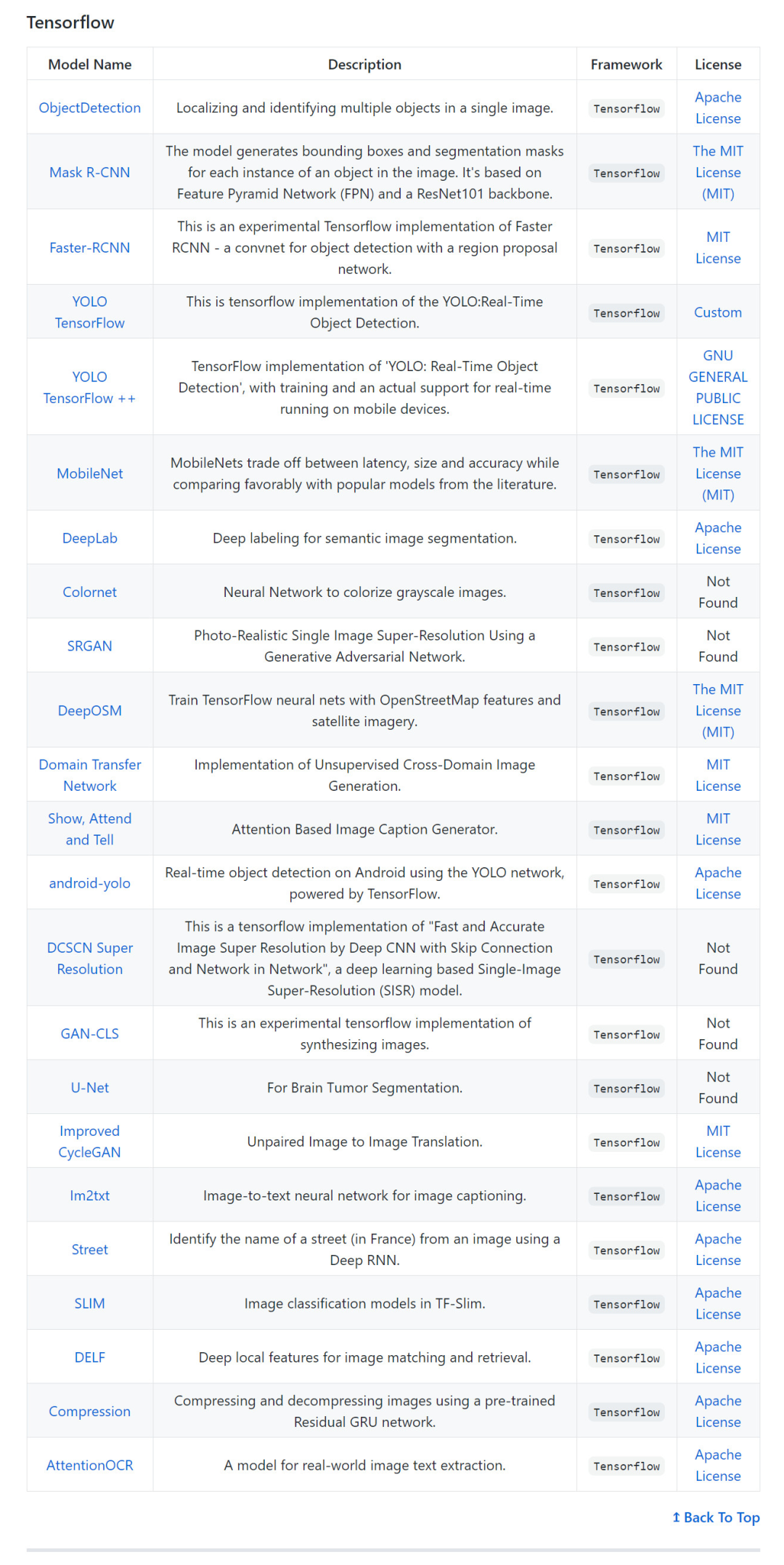
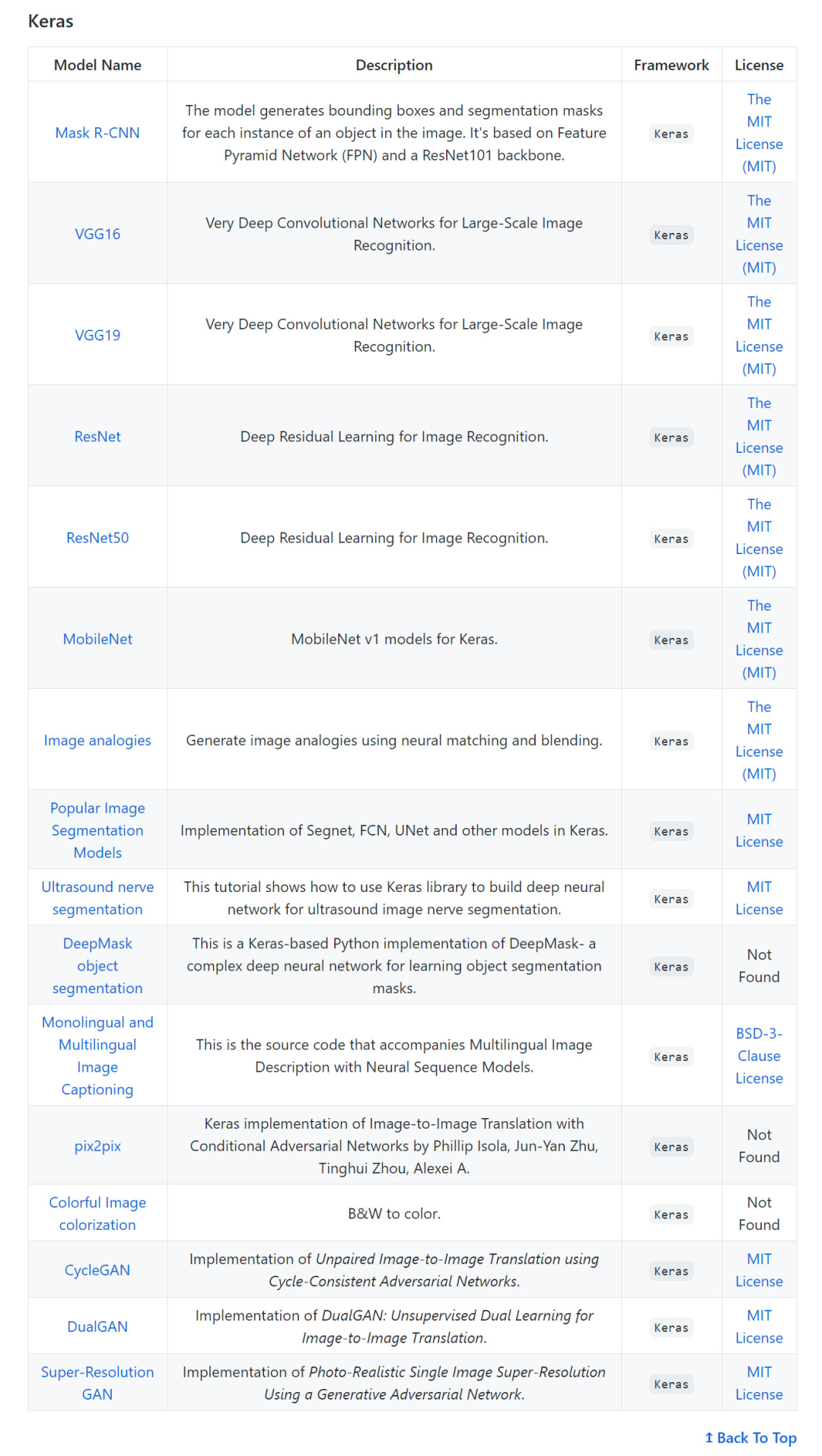
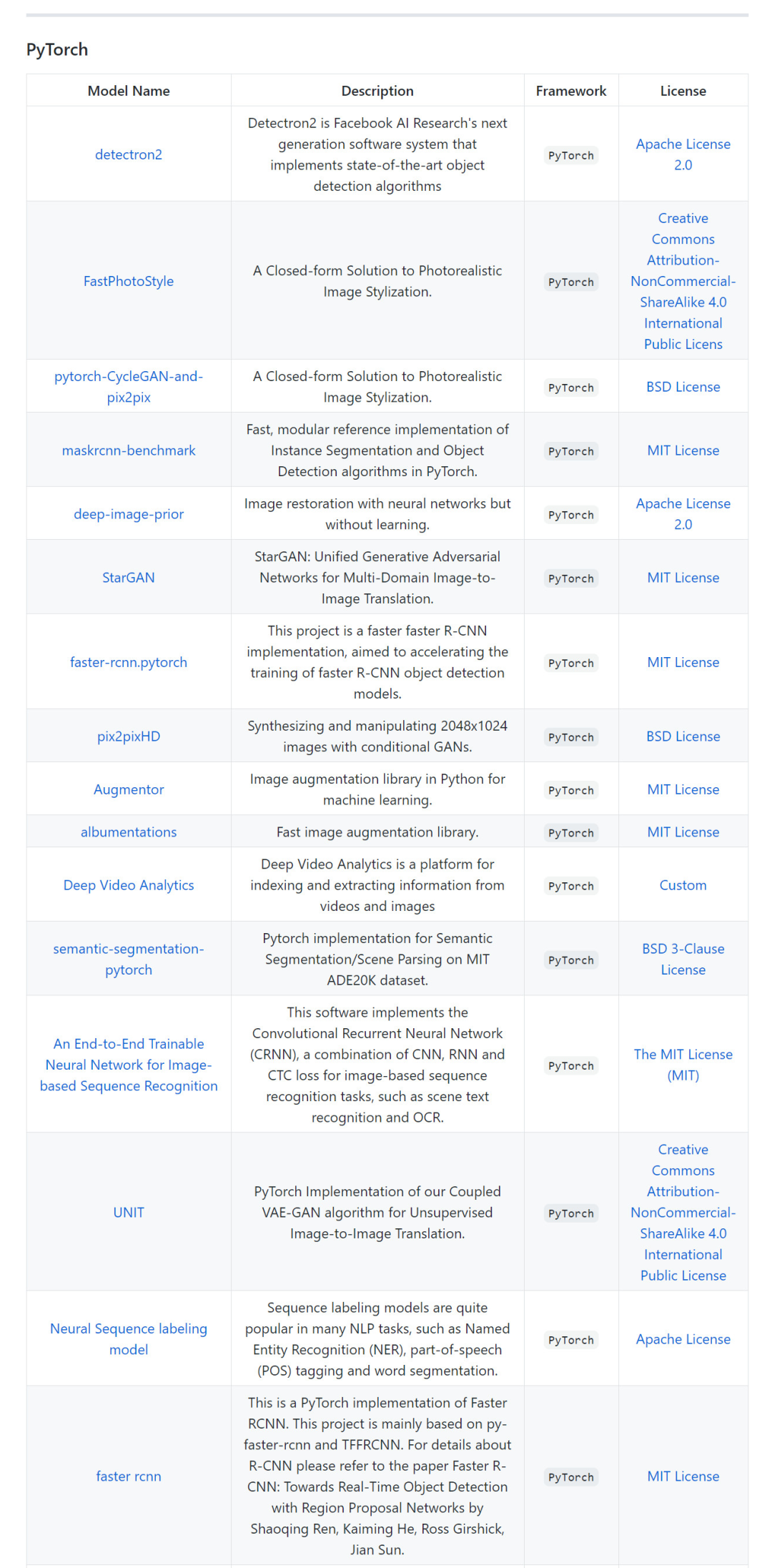
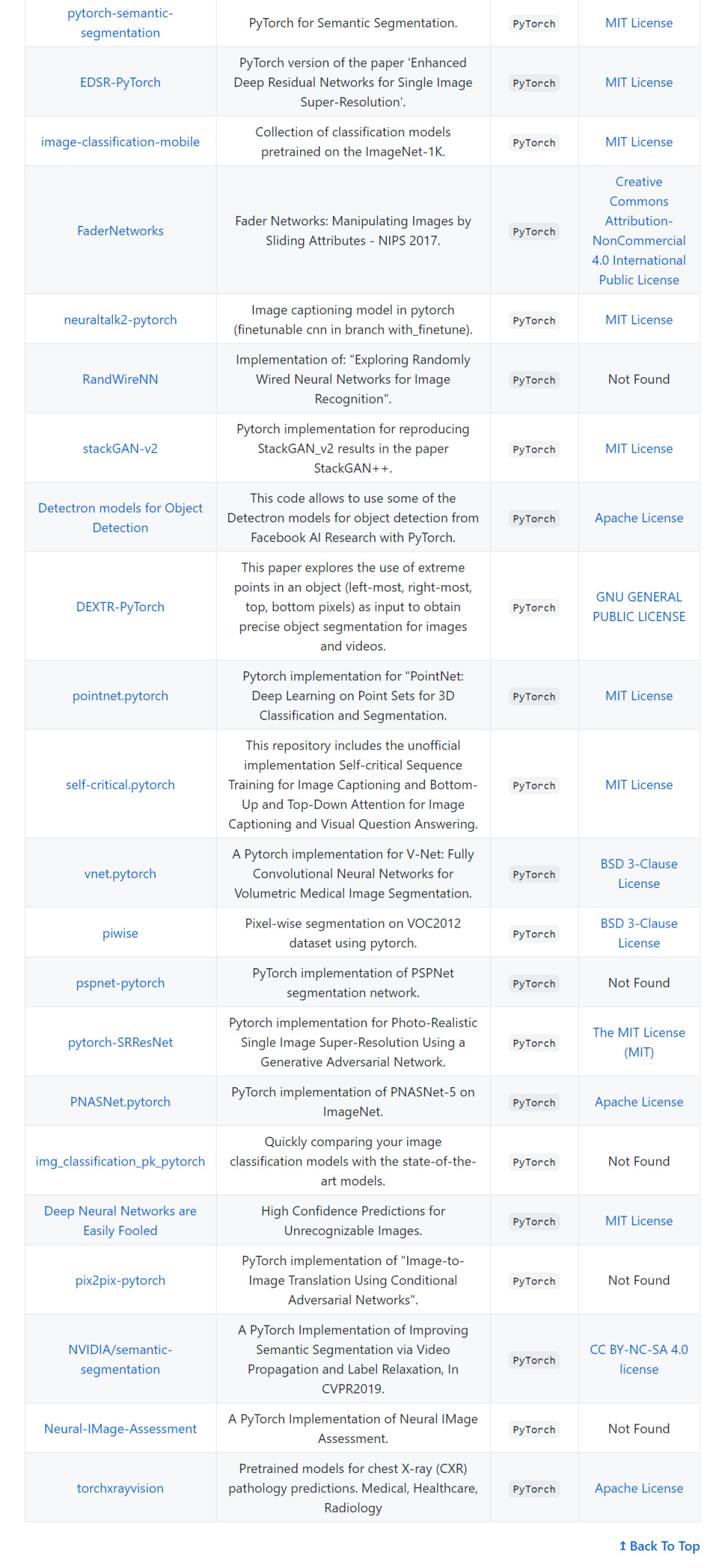
計(jì)算機(jī)視覺(CV)預(yù)訓(xùn)練模型
點(diǎn)擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)
評論
圖片
表情
<b id="afajh"><abbr id="afajh"></abbr></b>
 下載APP
下載APP點(diǎn)擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)
<b id="afajh"><abbr id="afajh"></abbr></b>