
3個Pandas高頻使用函數(shù)

大家好,我是Peter~
本文主要是給大家介紹3個Pandas日常高頻使用函數(shù):apply + agg + transform。
模擬數(shù)據(jù)
模擬了一份簡單的數(shù)據(jù)
In [1]:
import pandas as pd
import numpy as np
In [2]:
df = pd.DataFrame(
{"name":["xiaoming","sunjun","jimmy","tom"],
"sex":["male","female","female","male"],
"chinese":[100,80,90,92],
"math":[90,100,88,90]
})
df
Out[2]:
| name | sex | chinese | math | |
|---|---|---|---|---|
| 0 | xiaoming | male | 100 | 90 |
| 1 | sunjun | female | 80 | 100 |
| 2 | jimmy | female | 90 | 88 |
| 3 | tom | male | 92 | 90 |
函數(shù)apply
一個非常靈活的函數(shù),能夠?qū)φ麄€DataFrame或者Series執(zhí)行給定函數(shù)的操作。
函數(shù)可以是自定義的,也可以是python或者pandas內(nèi)置的函數(shù),還可以是匿名函數(shù)。
使用1:自帶函數(shù)
改變字段類型:從int64變成float64
In [3]:
df.dtypes # 改變前
Out[3]:
name object
sex object
chinese int64
math int64
dtype: object
In [4]:
df["chinese"] = df["chinese"].apply(float)
In [5]:
df.dtypes # 改變后
Out[5]:
name object
sex object
chinese float64
math int64
dtype: object
使用2:自定義函數(shù)
In [6]:
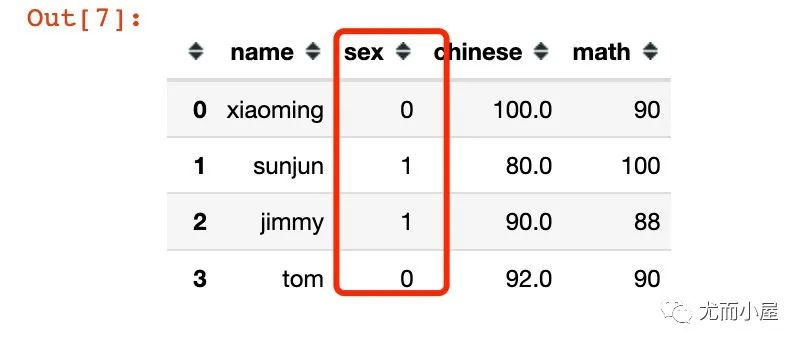
def change_sex(x): # male-0 female-1
return 0 if x == "male" else 1
In [7]:
df["sex"] = df["sex"].apply(change_sex)
df # 改變后
使用3:匿名函數(shù)lambda
In [8]:
# float--->int
df["chinese"] = df["chinese"].apply(lambda x: int(x))
df.dtypes
Out[8]:
name object
sex int64
chinese int64
math int64
dtype: object
In [9]:
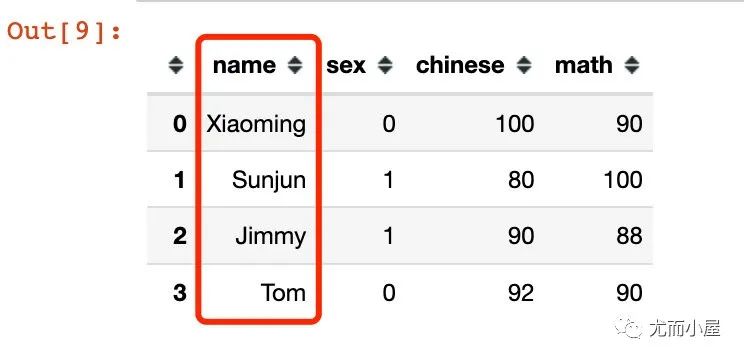
# 將name變成首字母大寫
df["name"] = df["name"].apply(lambda x: x.title())
df
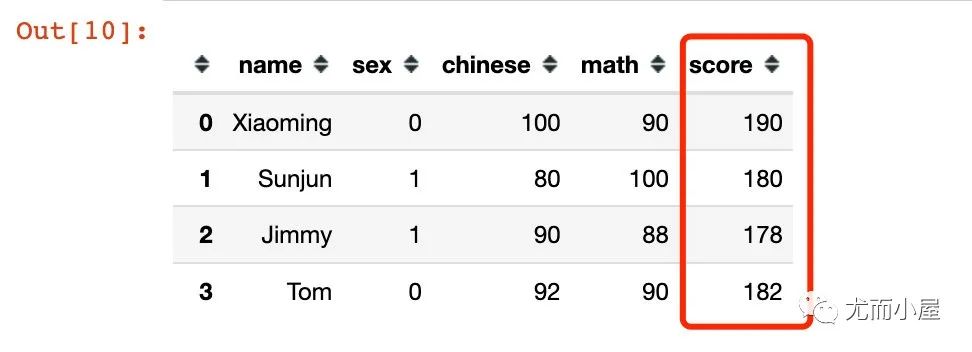
# 同時操作兩列,記得axis=1
df["score"] = df.apply(lambda x: x["chinese"] + x["math"], axis=1)
df
函數(shù)agg
操作Series數(shù)據(jù)
In [11]:
# 1
df["chinese"].agg(["mean", "sum"])
Out[11]:
mean 90.5
sum 362.0
Name: chinese, dtype: float64
操作DataFrame數(shù)據(jù)
In [12]:
# 2
df[["chinese","math"]].agg({"chinese":["sum"], "math":["mean"]})
Out[12]:
| chinese | math | |
|---|---|---|
| sum | 362.0 | NaN |
| mean | NaN | 92.0 |
In [13]:
# 3
df[["chinese","math"]].agg({"chinese":["sum","mean"], "math":["mean"]})
Out[13]:
| chinese | math | |
|---|---|---|
| sum | 362.0 | NaN |
| mean | 90.5 | 92.0 |
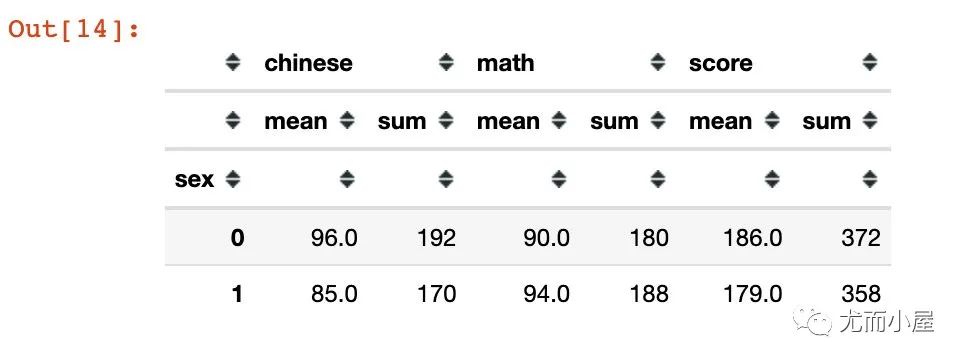
groupby + agg的聯(lián)合使用:
In [14]:
# 4
df.groupby("sex").agg(["mean","sum"])
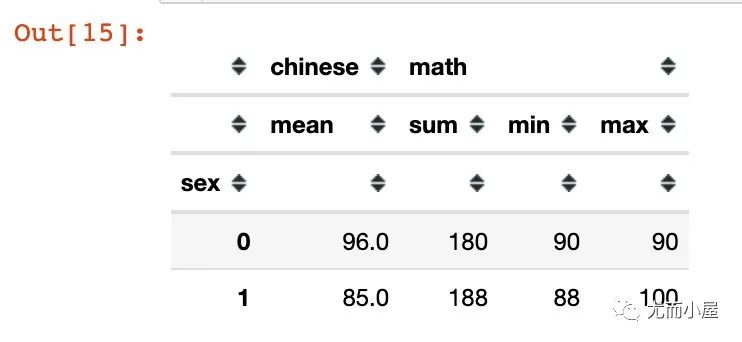
# 5
df.groupby("sex").agg({"chinese":["mean"], "math":["sum","min","max"]})
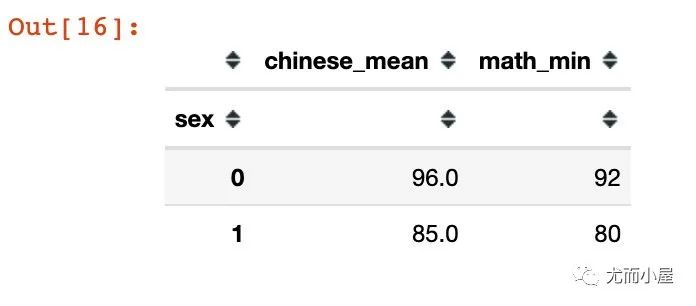
還可以自定義新生成的字段名稱:
df.groupby("sex").agg(chinese_mean=("chinese","mean"), math_min=("chinese","min"))
函數(shù)transform
現(xiàn)在的df是這樣子:
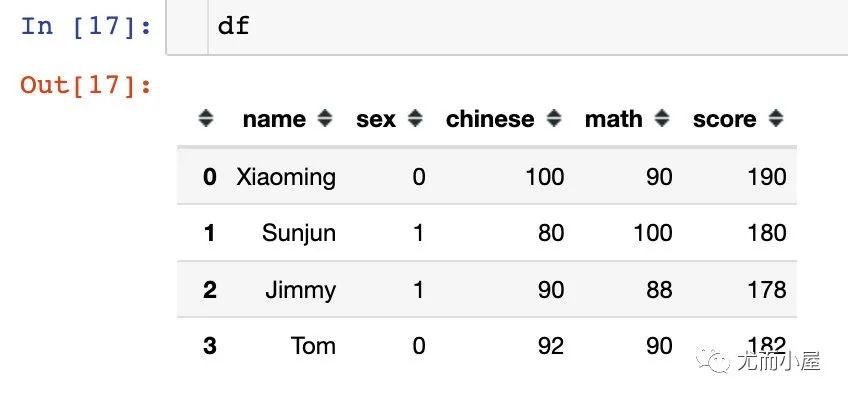
假設有一個需求:統(tǒng)計性別男女 sex 的chinese 的平均分(新增一個字段放在最后面),如何實現(xiàn)?
方法1:使用groupby + merge
In [18]:
# 1、先groupby
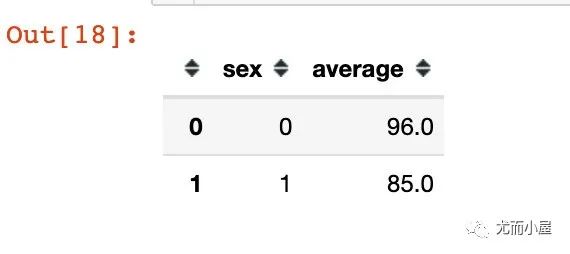
df1 = df.groupby("sex")["chinese"].mean().reset_index()
df1.columns = ["sex", "average"]
df1
# 2、merge
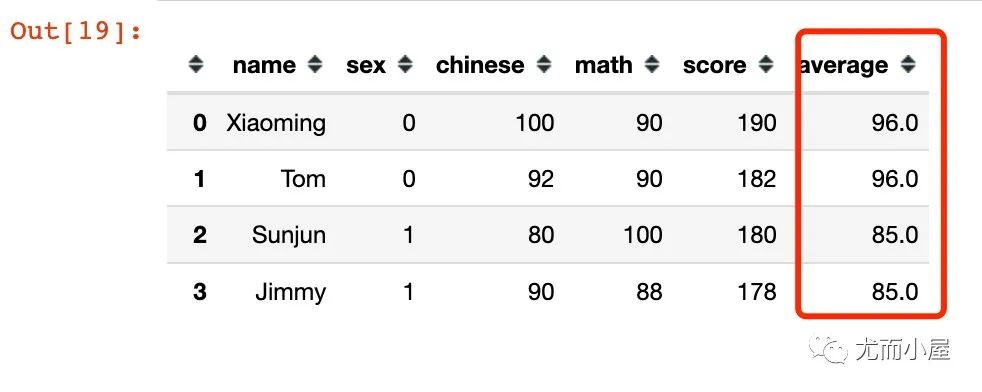
# 結(jié)果
df = pd.merge(df, df1, on="sex")
df
方法2:groupby + map
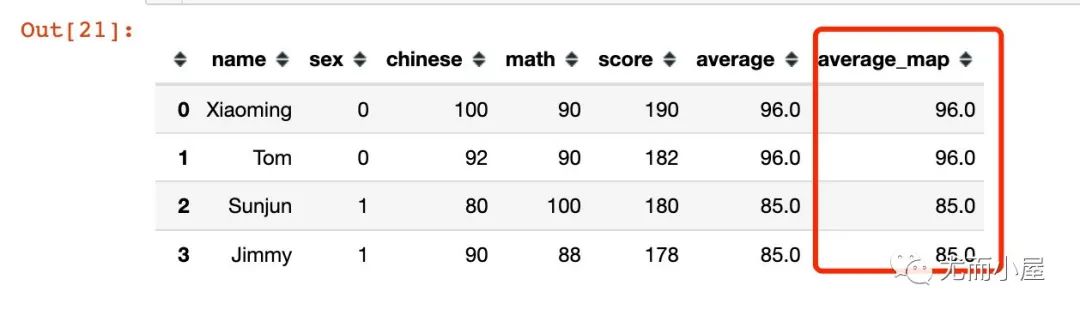
In [20]:
dic = df.groupby("sex")["chinese"].mean().to_dict()
dic
Out[20]:
{0: 96.0, 1: 85.0}
In [21]:
df["average_map"] = df["sex"].map(dic)
df
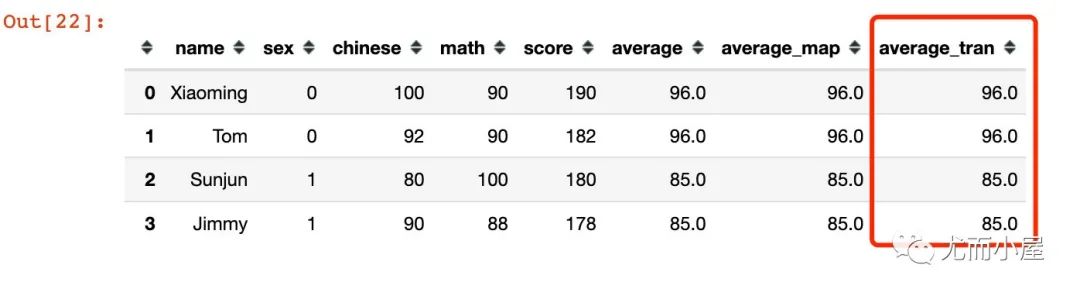
方法3:使用transform
使用transform可以一步到位
df["average_tran"] = df.groupby("sex")["chinese"].transform("mean")
df
往期推薦 1、程序員如何優(yōu)雅地解決線上問題? 2、你這背景太假了,用AI自動合成,假嗎? 3、基于NumPy實現(xiàn)隨機梯度下降算法 4、【干貨原創(chuàng)】一個好用到爆的數(shù)據(jù)分析利器 5、使用 pandas 對數(shù)據(jù)進行移動計算 點擊關注公眾號,閱讀更多精彩內(nèi)容



評論
圖片
表情