
精選22個Pandas函數(shù)!
今天從26個字母中精選出22個Pandas常用的函數(shù),將它們的使用方法簡單介紹給大家,詳細(xì)內(nèi)容可以查看官網(wǎng)學(xué)習(xí)。
import?pandas?as?pd
import?numpy?as?np
apply函數(shù)
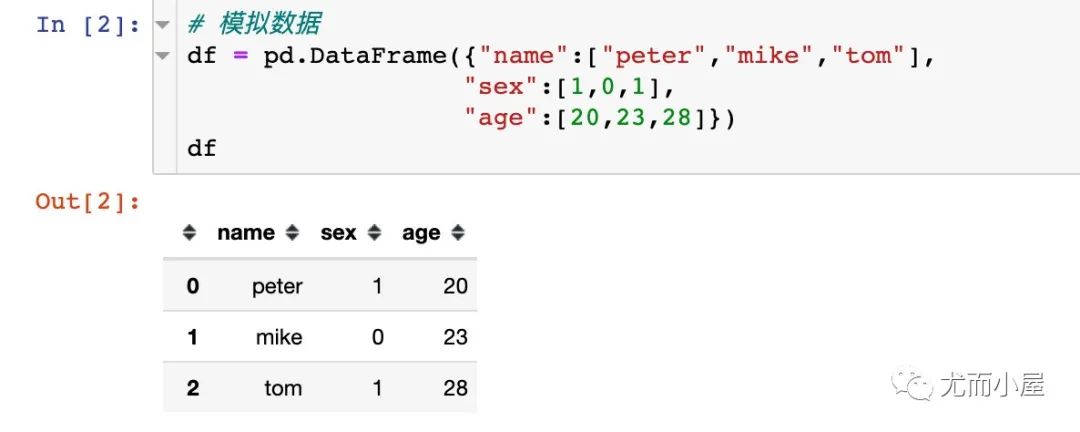
Pandas中一個很實用的函數(shù),下面模擬了一份數(shù)據(jù):
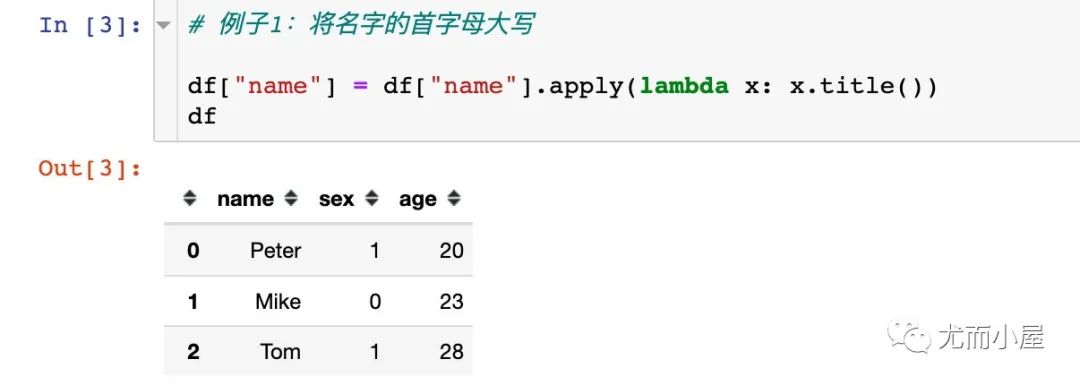
我們分別將python的內(nèi)置函數(shù)、自定義函數(shù)、匿名函數(shù)傳給apply函數(shù):
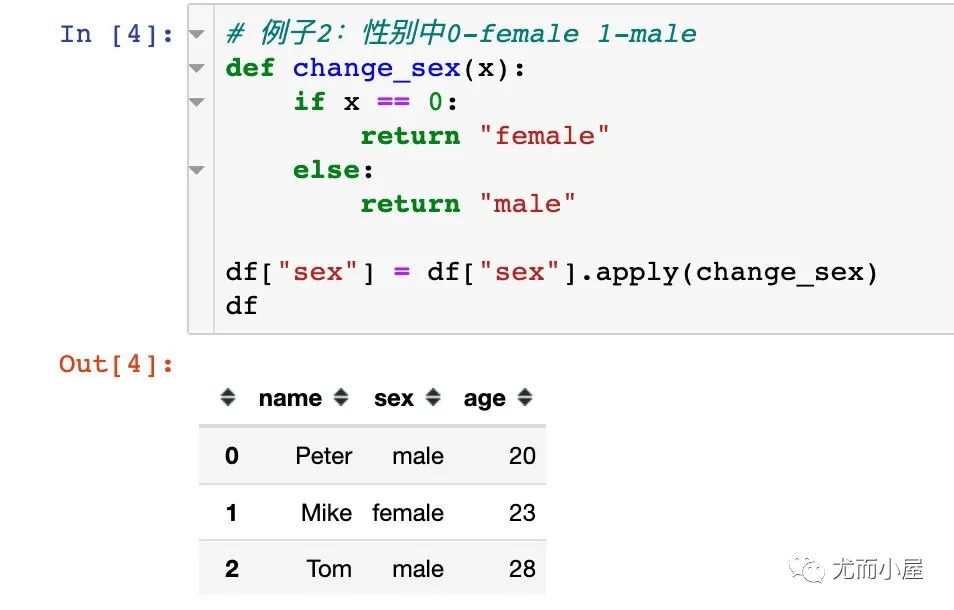
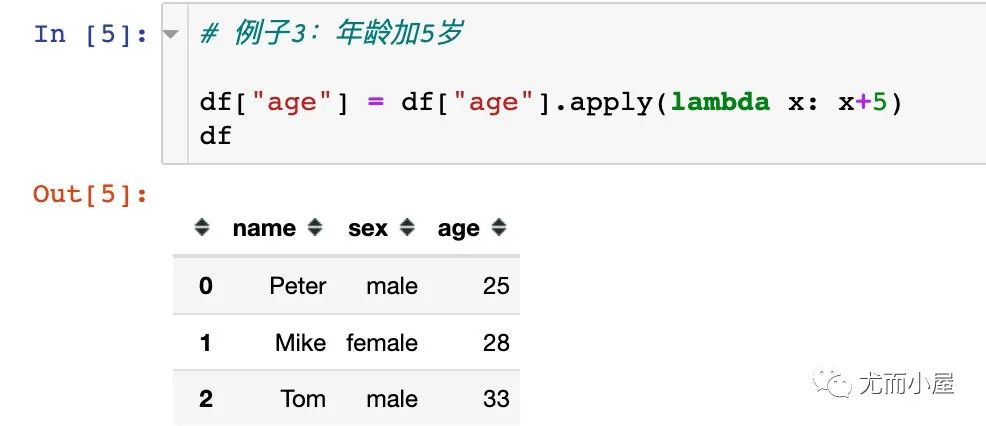
使用Python的匿名函數(shù)來進行傳遞:
between_time
start_time,?
end_time,?
include_start=NoDefault.no_default,
include_end=NoDefault.no_default,?
inclusive=None,?
axis=None
來自官網(wǎng)的案例:
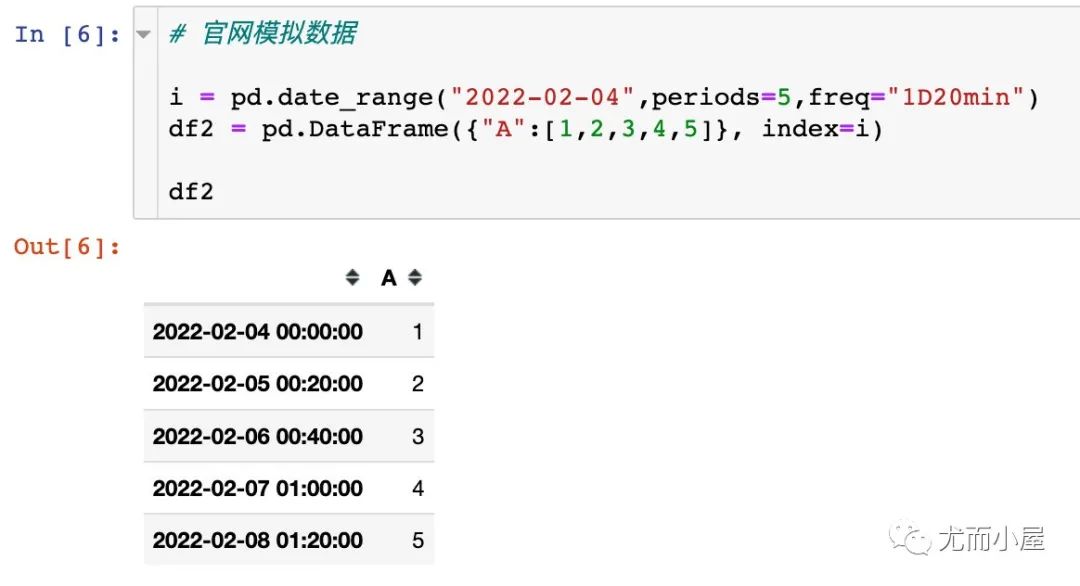
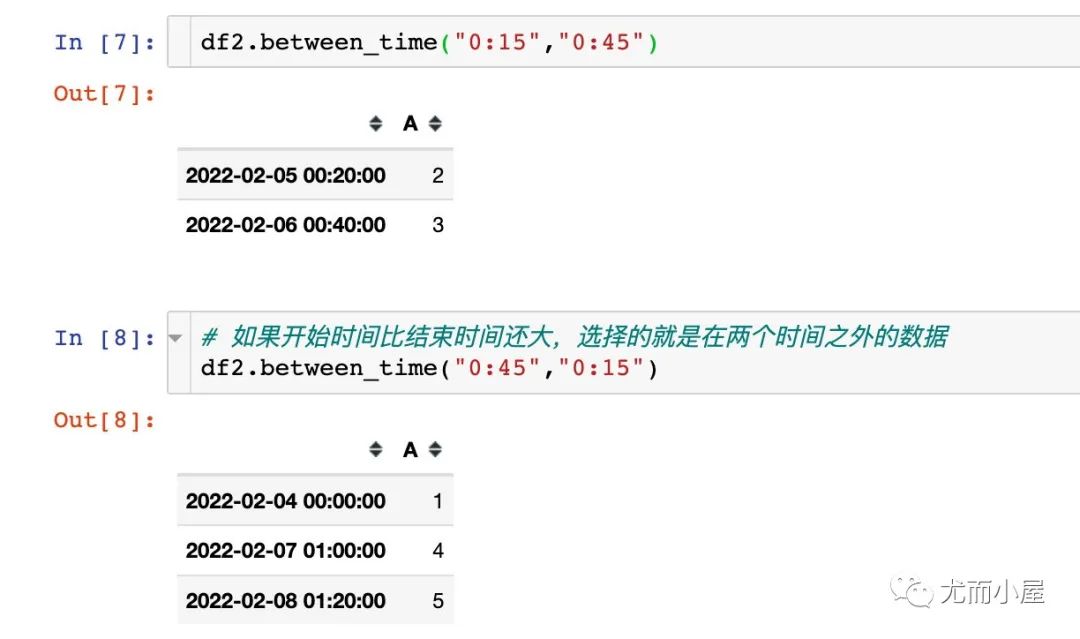
如果在參數(shù)中,開始時間大于結(jié)束時間,則會呈現(xiàn)不同的結(jié)果:
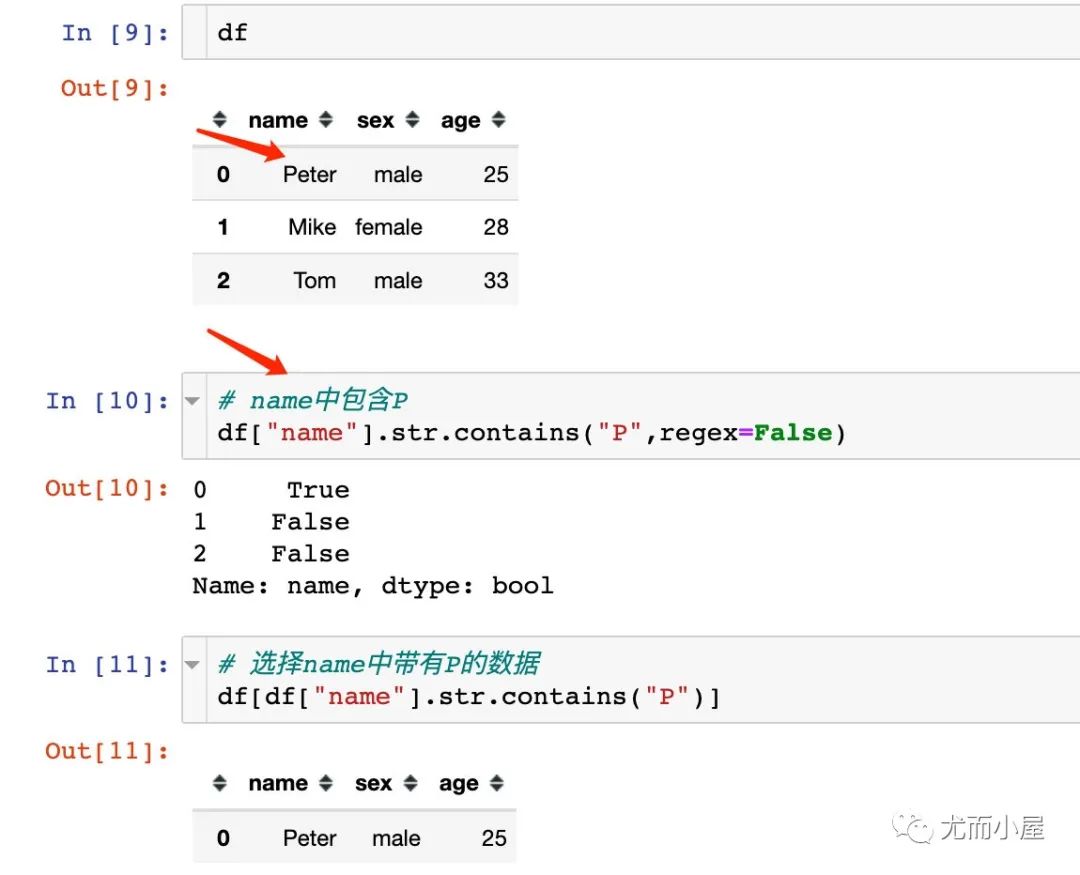
contains函數(shù)
針對Series中的包含字符信息:
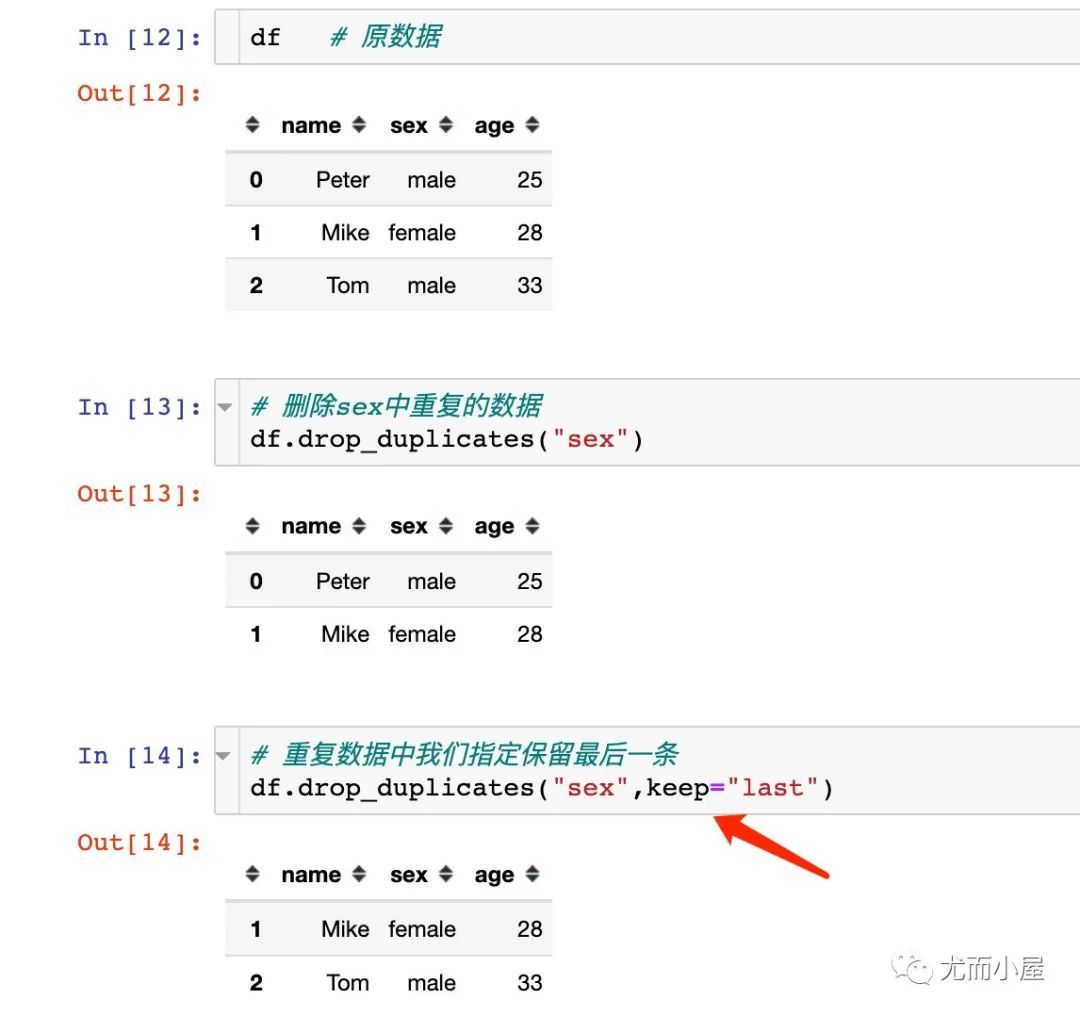
drop_duplicates函數(shù)
刪除數(shù)據(jù)中的重復(fù)值;可以選擇根據(jù)某個或者多個字段來刪除。
在刪除數(shù)據(jù)的時候,默認(rèn)保留的是第一條重復(fù)的數(shù)據(jù),我們可以通過參數(shù)keep來指定保留最后一條
expanding函數(shù)
這是一個窗口函數(shù),實現(xiàn)的是一種類似累計求和的功能
DataFrame.expanding(
??min_periods=1,?
??center=None,?
??axis=0,?
??method='single')
min_periods:每個窗口最少包含的觀測值數(shù)量,小于該數(shù)量的窗口結(jié)果為NA。值可以是int,默認(rèn)None。offset情況下,默認(rèn)為1 center:把窗口的標(biāo)簽設(shè)置為居中,布爾型,默認(rèn)False,居右 axis:默認(rèn)為0,對列進行計算 method:single或者table
模擬了一份數(shù)據(jù):
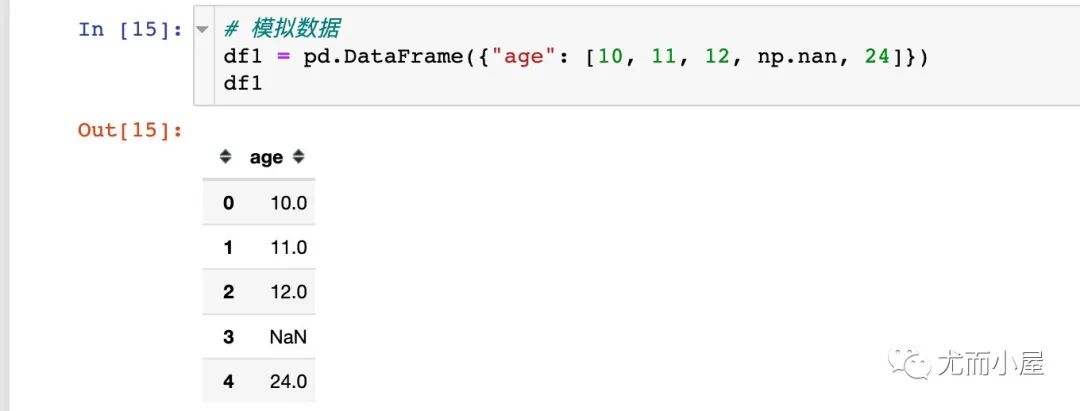
分別指定1-2-3不同的窗口數(shù):
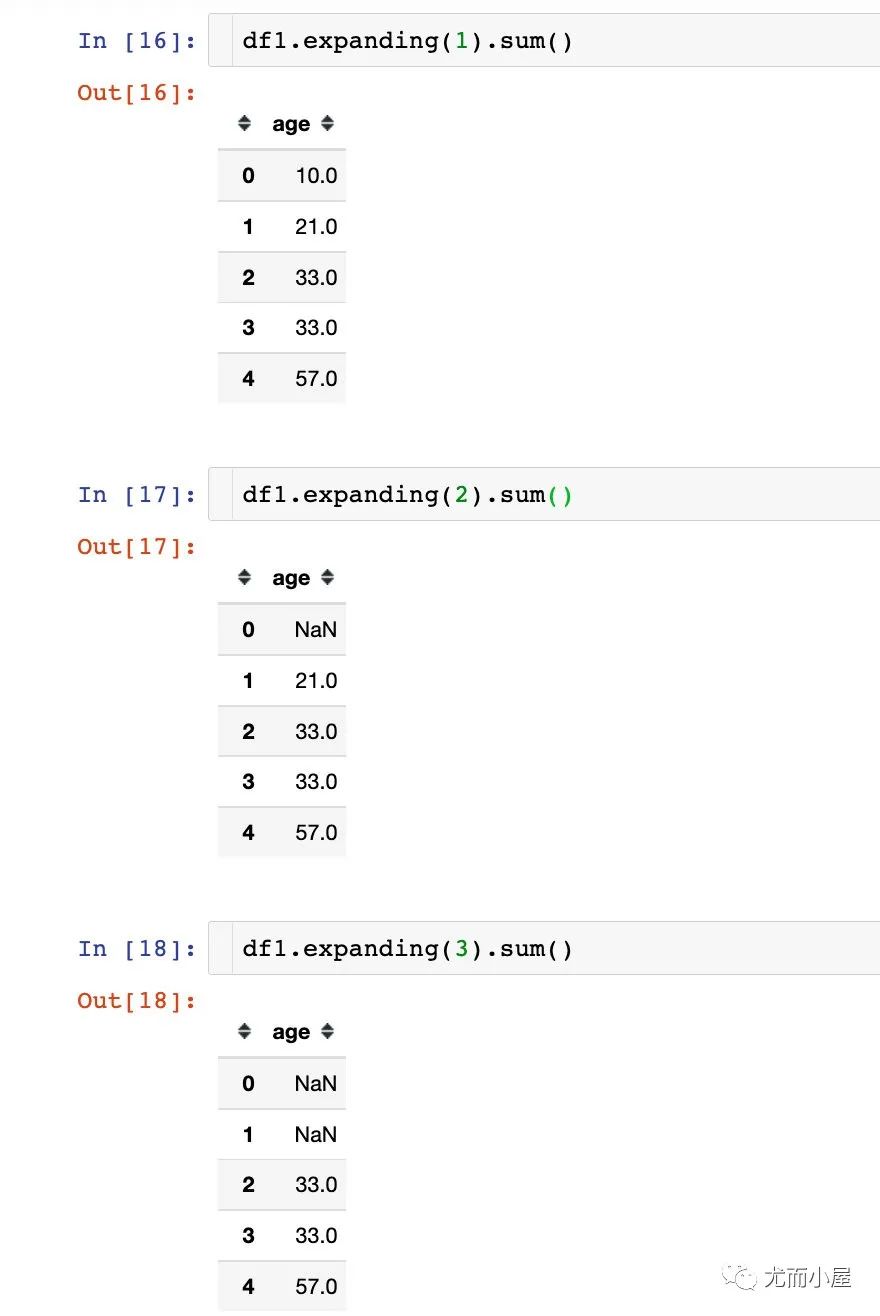
我們發(fā)現(xiàn):當(dāng)窗口數(shù)大于前面的記錄數(shù),則累計和用NaN表示
filter函數(shù)
用來進行數(shù)據(jù)的過濾操作
items:表示包含的字段 regex:表示使用正則
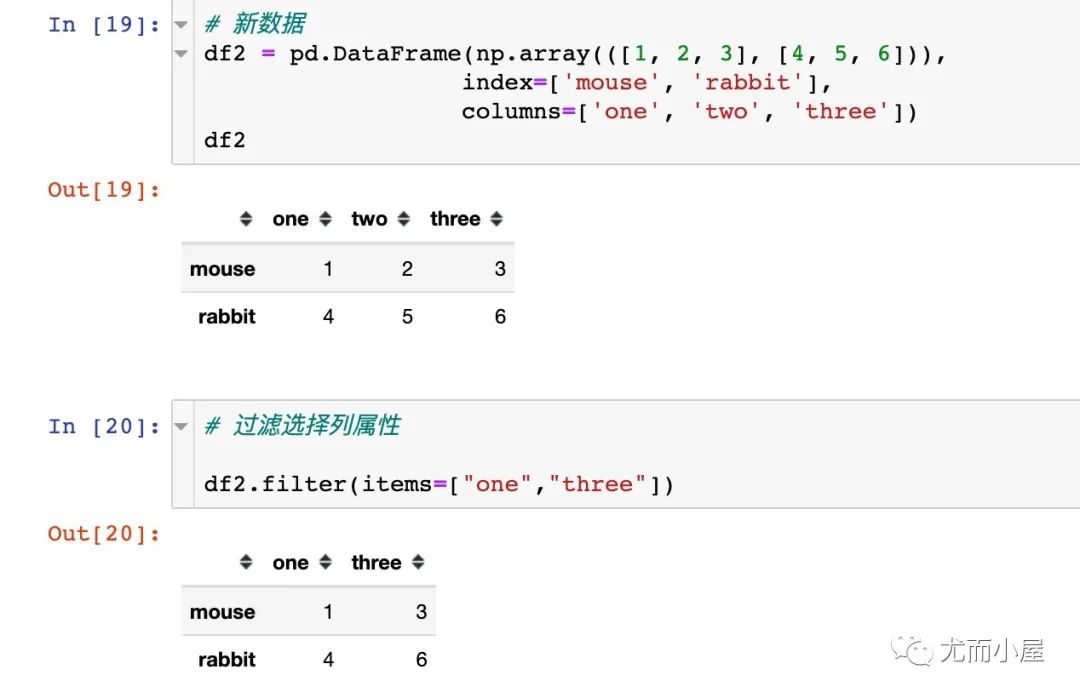
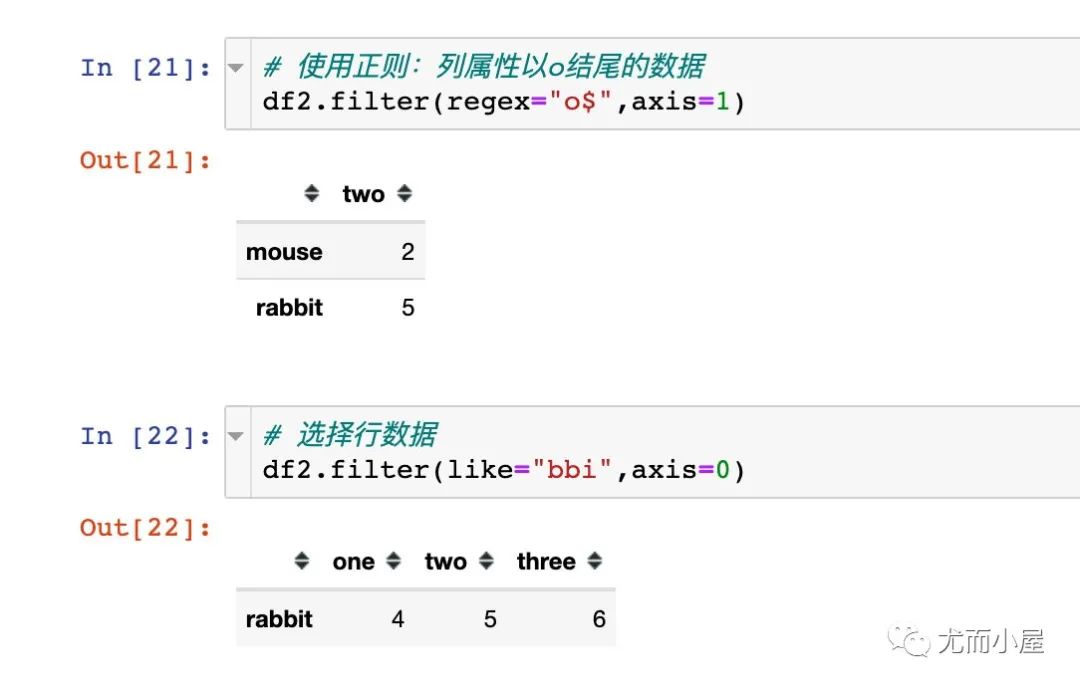
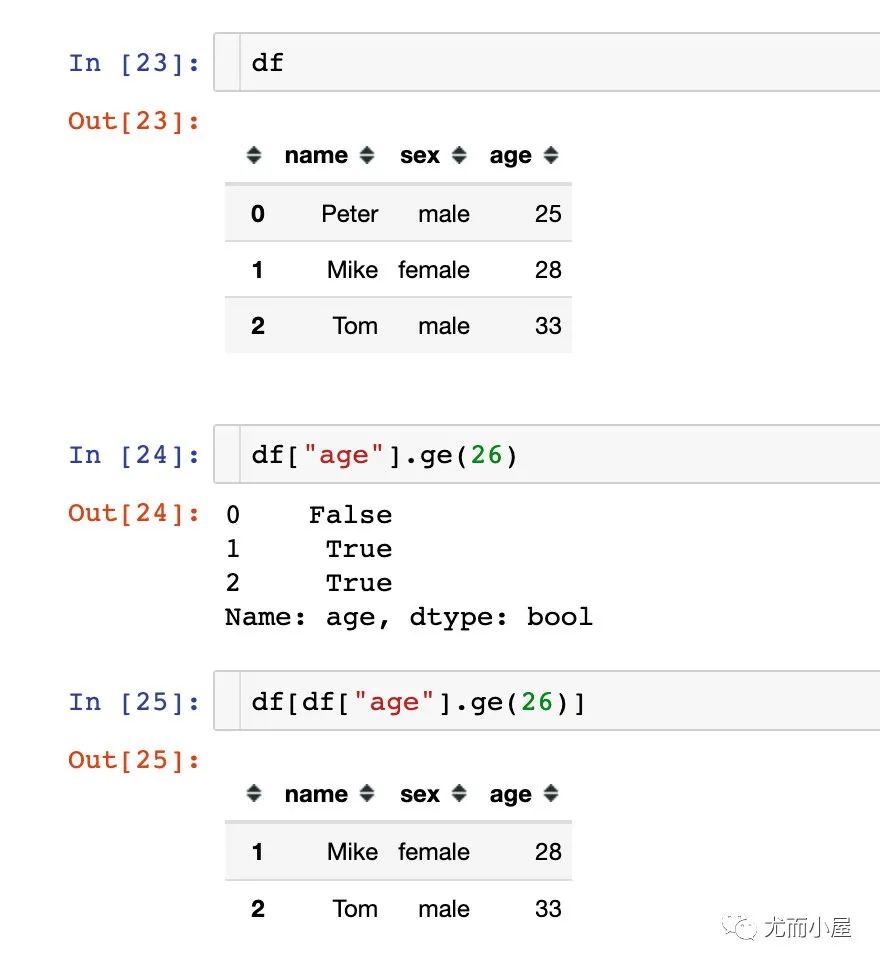
ge函數(shù)
進行比較的一個函數(shù):ge表示greater equal
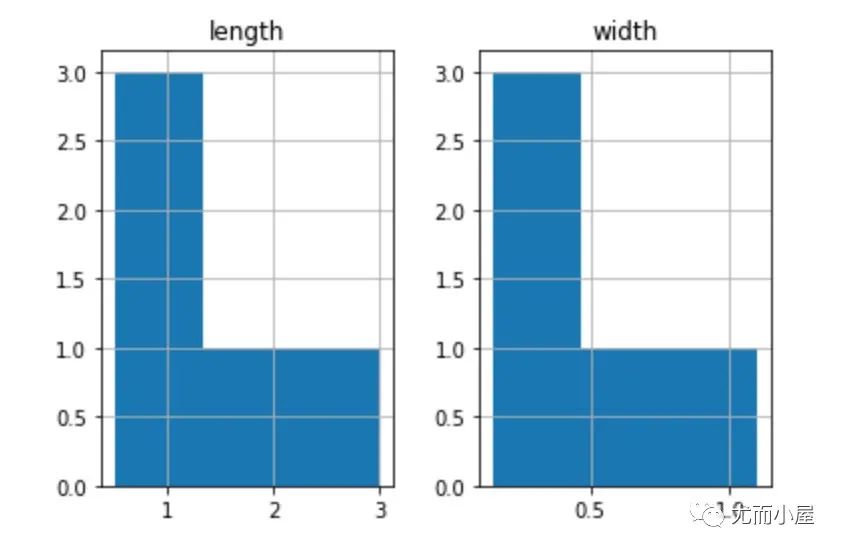
hist函數(shù)
pandas內(nèi)置的繪制直方圖的函數(shù)
df4?=?pd.DataFrame({
????'length':?[1.5,?0.5,?1.2,?0.9,?3],
????'width':?[0.7,?0.2,?0.15,?0.2,?1.1]
????},?index=['pig',?'rabbit',?'duck',?'chicken',?'horse'])
hist?=?df4.hist(bins=3)
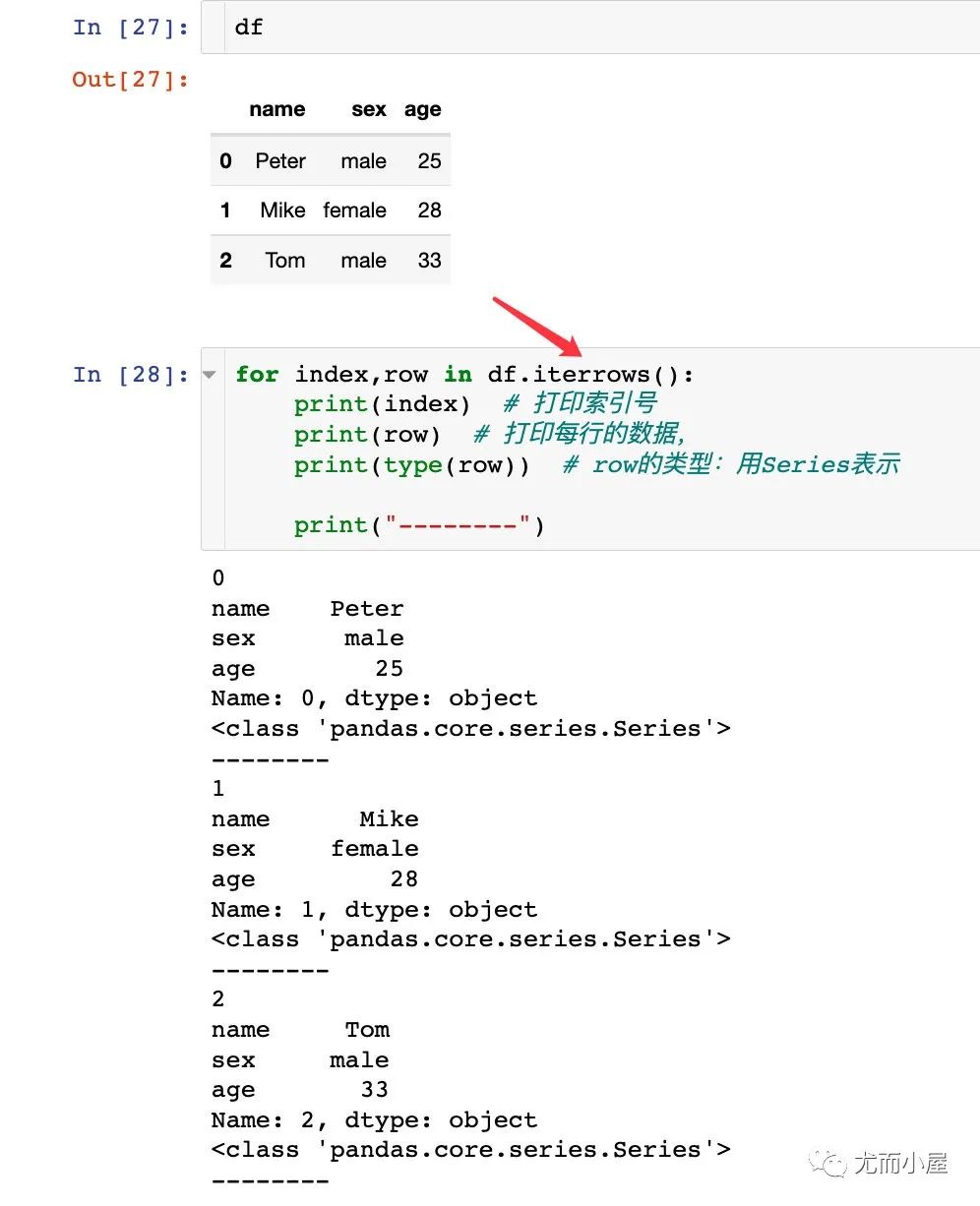
iterrows函數(shù)
iterrows函數(shù)用于對DataFrame進行迭代循環(huán)
join函數(shù)
join函數(shù)用于合并不同的DataFrame


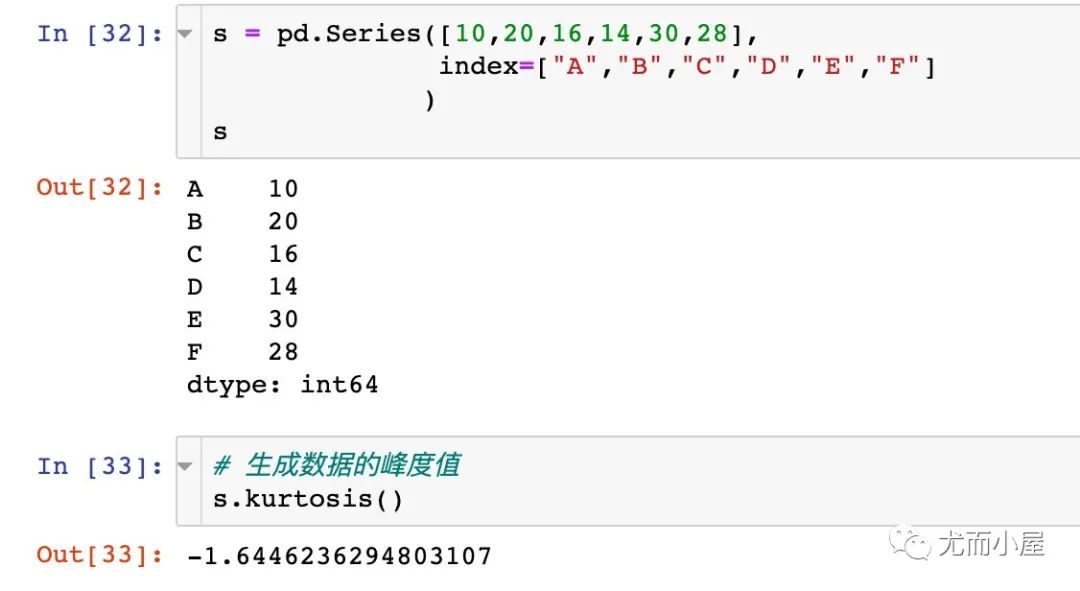
kurtosis函數(shù)
用于查找一組數(shù)據(jù)中的峰度值
kurtosis(axis=index(0)?or?columns(1),?
?????????skipna=True,?
?????????level=None,?
?????????numeric_only=None,?
?????????**kwargs)
axis:要應(yīng)用的函數(shù)的軸。 skipna:計算結(jié)果時排除NA /null值。 level:如果軸是MultiIndex(分層),則沿特定級別計數(shù),并折疊成標(biāo)量。 numeric_only:僅包括float,int,boolean列。 **kwargs:要傳遞給函數(shù)的其他關(guān)鍵字參數(shù)
如果給定的數(shù)據(jù)中存在缺失值,可以使用參數(shù)skipna直接跳過:
s1?=?pd.Series([10,None,16,14,30,None])
s1
0????10.0
1?????NaN
2????16.0
3????14.0
4????30.0
5?????NaN
dtype:?float64
s1.kurtosis(skipna=True)
2.646199227619398
last函數(shù)
這是一個用在基于時間數(shù)據(jù)選擇上的函數(shù)
i?=?pd.date_range('2018-04-09',?#?起始日期
??????????????????periods=4,??#?周期
??????????????????freq='2D')??#?頻率、間隔
i
DatetimeIndex(['2018-04-09',?'2018-04-11',?'2018-04-13',?'2018-04-15'],?dtype='datetime64[ns]',?freq='2D')
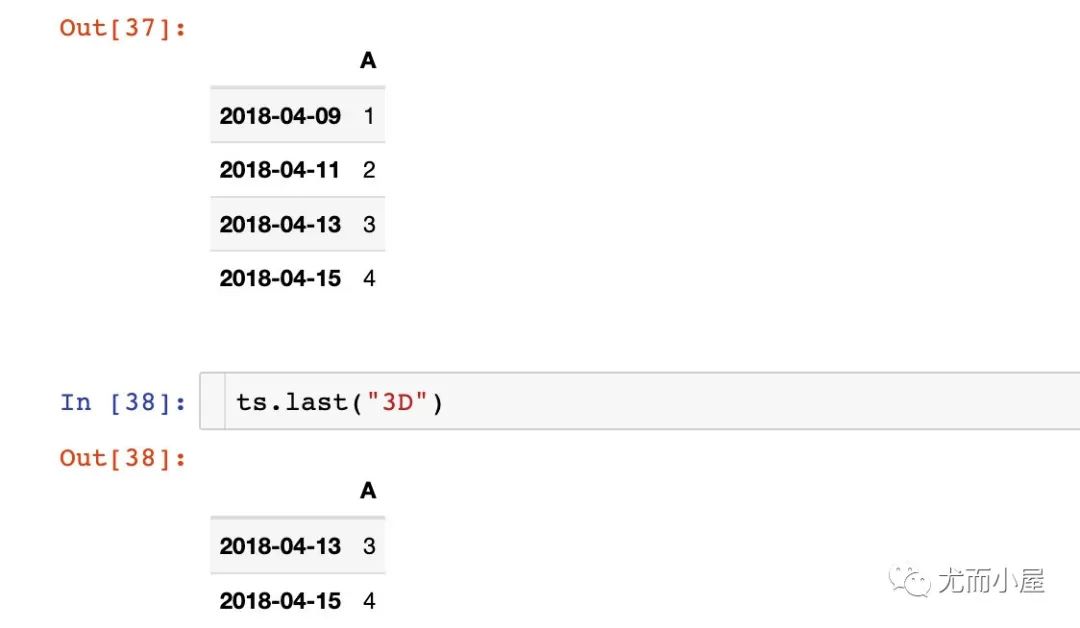
注意:在這里返回的日歷中3個日的數(shù)據(jù),而不是數(shù)據(jù)中的3行記錄。13-14-15剛好是3天
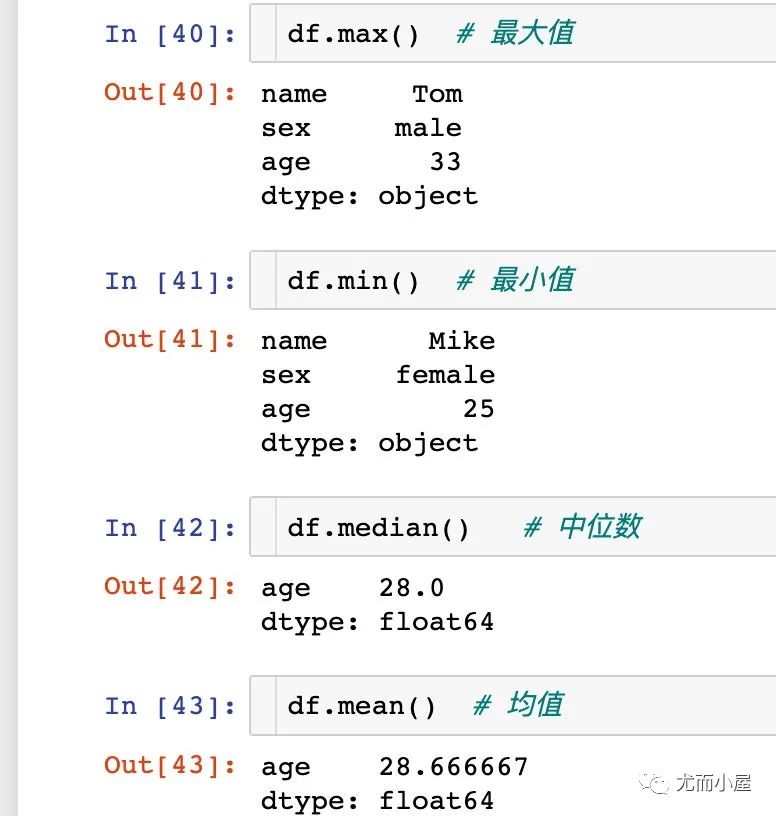
max/min/mean/median
4個基于統(tǒng)計概念的函數(shù):最大值、最小值、均值、中位數(shù)
nlargest函數(shù)
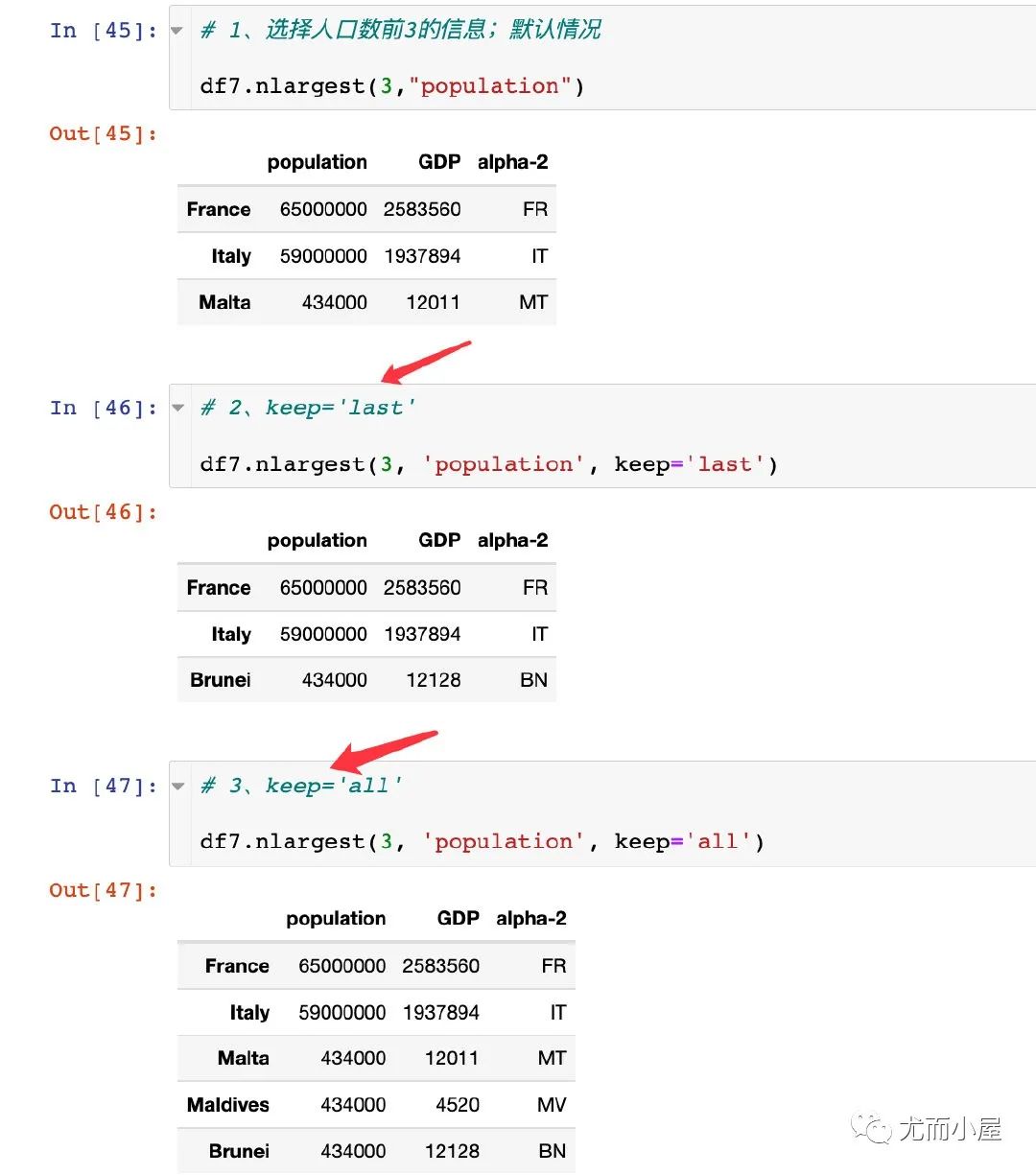
選擇前n個的數(shù)據(jù),其語法如下:
nlargest(n,?columns,?keep='first')
n:整數(shù) columns:根據(jù)一個或者多個字段篩選 keep:選擇first、last、all;默認(rèn)是first
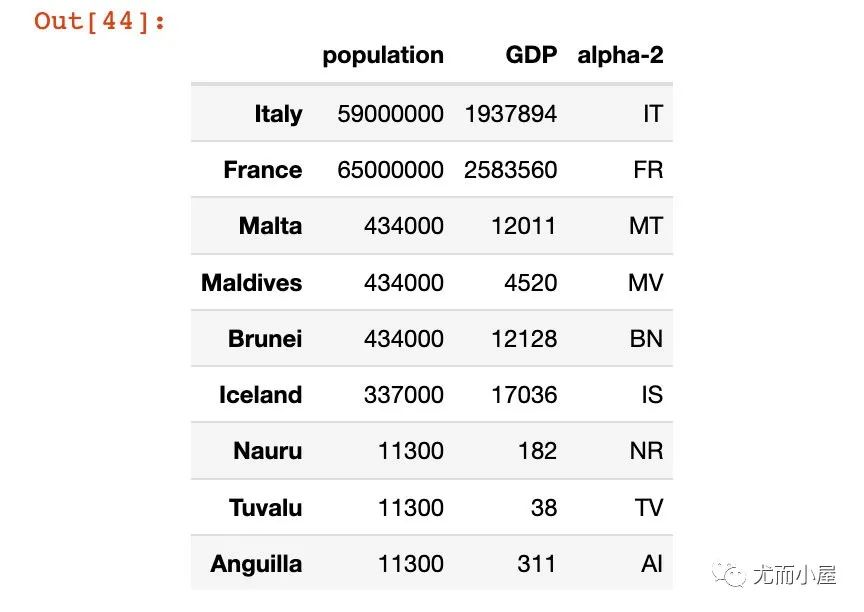
下面的例子來自官網(wǎng):
df7?=?pd.DataFrame({
??'population':?[59000000,?65000000,?434000,434000,?
?????????????????434000,?337000,?11300,11300,?11300],
??'GDP':?[1937894,?2583560?,?12011,?4520,?
??????????12128,17036,?182,?38,?311],
??'alpha-2':?["IT",?"FR",?"MT",?"MV",?"BN",
??????????????"IS",?"NR",?"TV",?"AI"]},
??index=["Italy",?"France",?"Malta",
?????????"Maldives",?"Brunei",?"Iceland",
?????????"Nauru",?"Tuvalu",?"Anguilla"])
#?記錄每個國家的人口數(shù)、GDP和名稱2位大寫
df7
keep參數(shù)在不同取值下的結(jié)果:
pop函數(shù)
表示刪除某個屬性或者字段信息
quantile函數(shù)
quantile就是分位數(shù)的意思,函數(shù)具體的語法規(guī)則為:
DataFrame.quantile(
????q=0.5,??
????axis=0,?
????numeric_only=True,
????interpolation=’linear’)
q : 數(shù)字或者是類列表,范圍只能在0-1之間,默認(rèn)是0.5,即中位數(shù)-第2四分位數(shù) axis :計算方向,0-index, 1-columns,默認(rèn)為 0 numeric_only:只允許是數(shù)值型數(shù)據(jù) interpolation(插值方法):可以是 {‘linear’, ‘lower’, ‘higher’, ‘midpoint’, ‘nearest’}之一,默認(rèn)是linear。
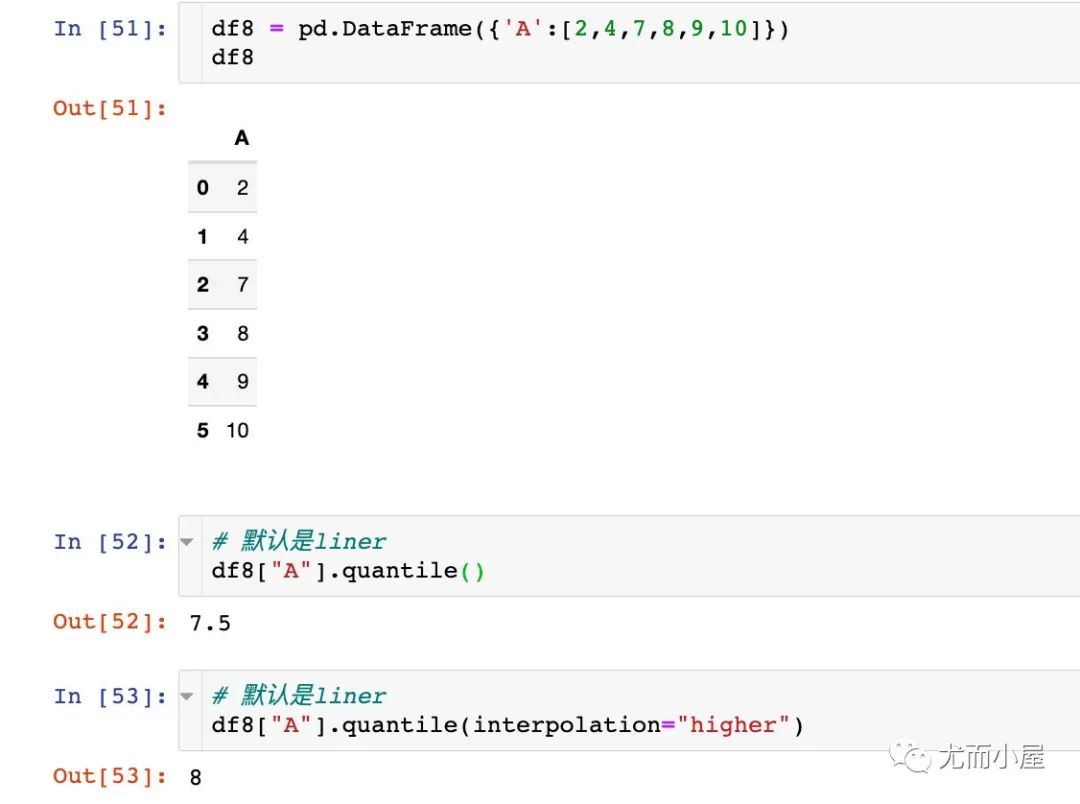
reset_index函數(shù)
reset就是重置的含義,index就是行索引;連起來就是重置行索引
df9?=?pd.DataFrame({"fruit":["蘋果","香蕉","橙子","橙子","蘋果","橙子"],
???????????????????"amount":[100,200,130,150,88,40]})
df9

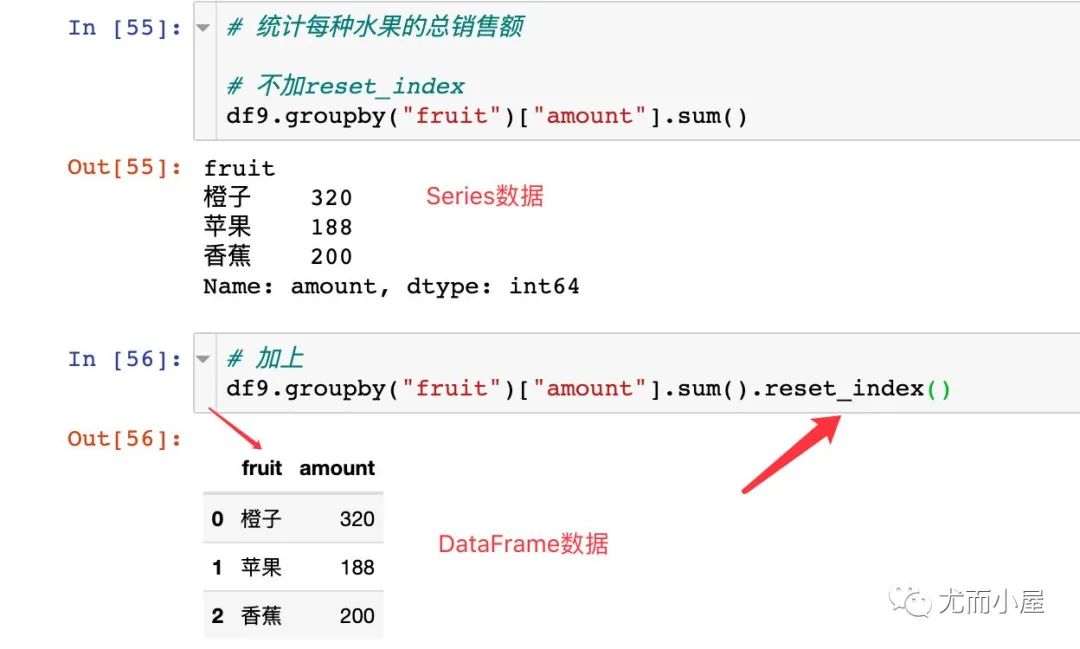
當(dāng)我們統(tǒng)計每種水果的總銷售額,是否使用reset_index函數(shù)的不同效果:
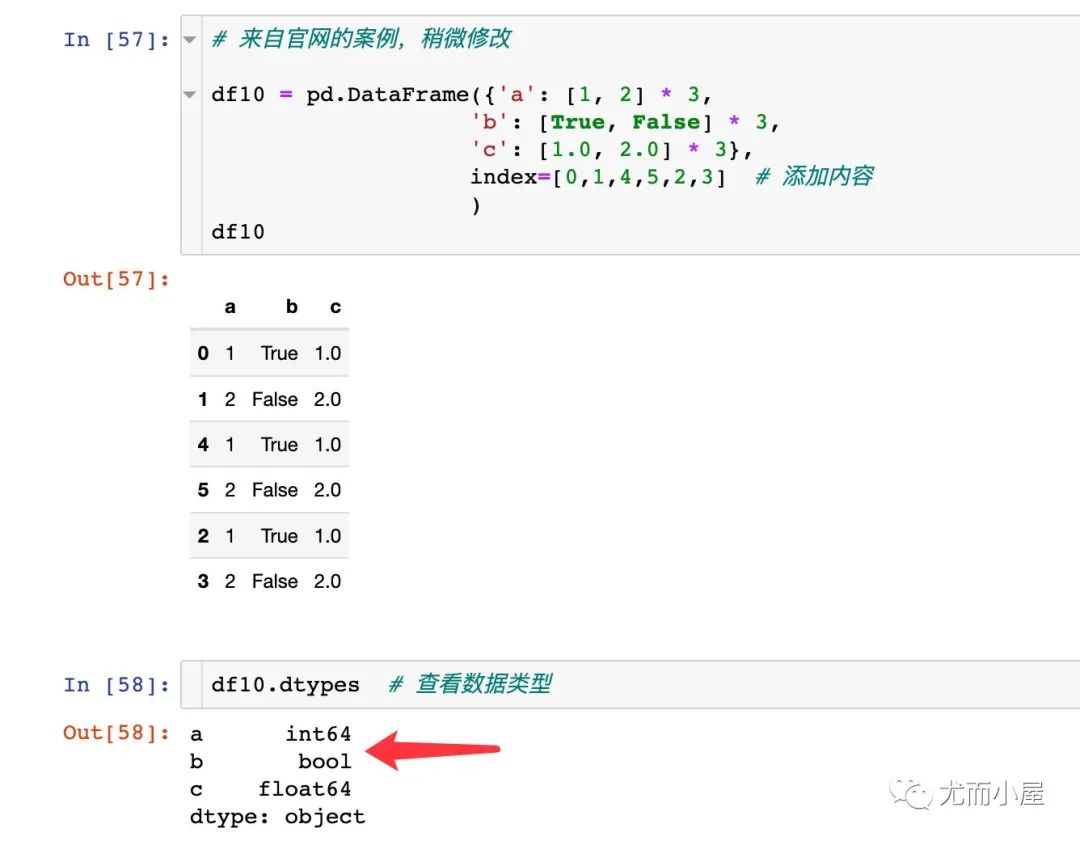
select_dtypes函數(shù)
根據(jù)字段類型來篩選數(shù)據(jù),可以包含或者排除一個或者多個字段類型的數(shù)據(jù)。
下面是官網(wǎng)的案例,稍作修改:生成了3個不同數(shù)據(jù)類型的字段
1、包含字段類型
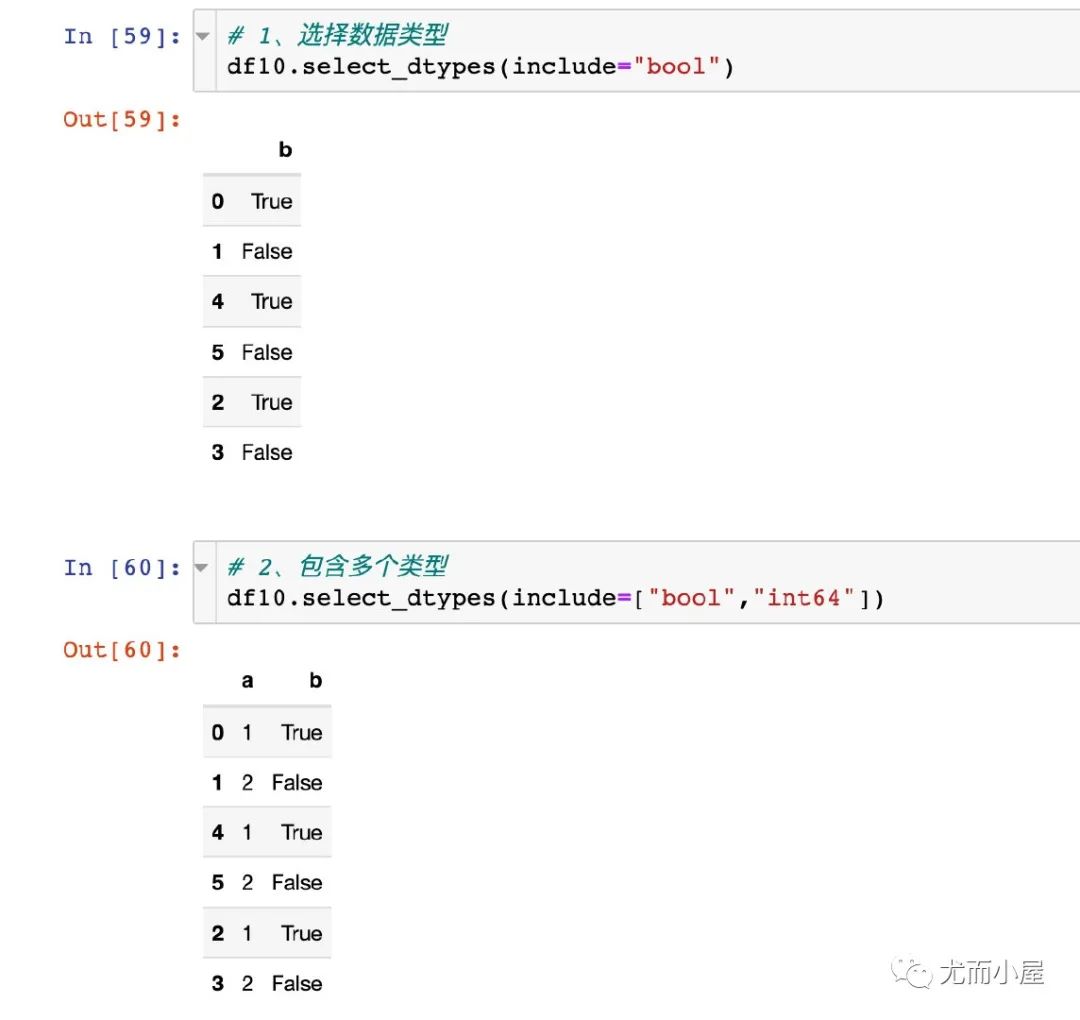
2、排除字段類型

take函數(shù)
也是選擇數(shù)據(jù)的一個函數(shù),具體語法為:
take(indices,?axis=0,?is_copy=None,?**kwargs)
indices:選擇位置:數(shù)組或者切片 axis:選擇的軸,0-index,1-column,默認(rèn)是0 is_copy:是否返回副本;從Pandas1.0開始
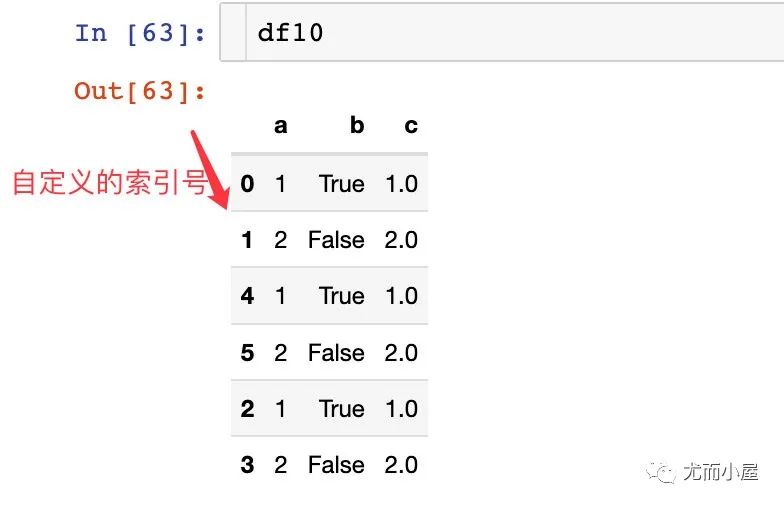
下面是多個例子:

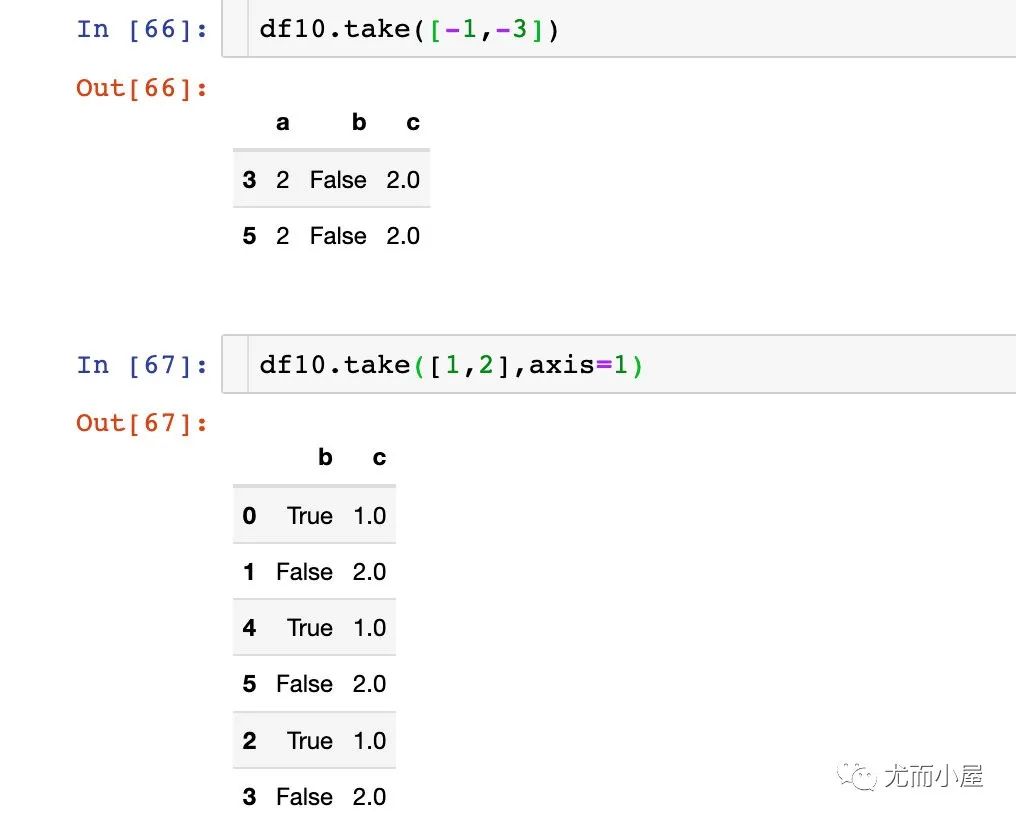
以第一個例子來解釋,指定數(shù)據(jù)的記錄為0和4。表示取出df10中的第1條和第5條數(shù)據(jù)(索引從0開始),而不是看我們自定義的索引號。
update函數(shù)
更新某個DataFrame數(shù)據(jù)框;模擬兩個數(shù)據(jù):
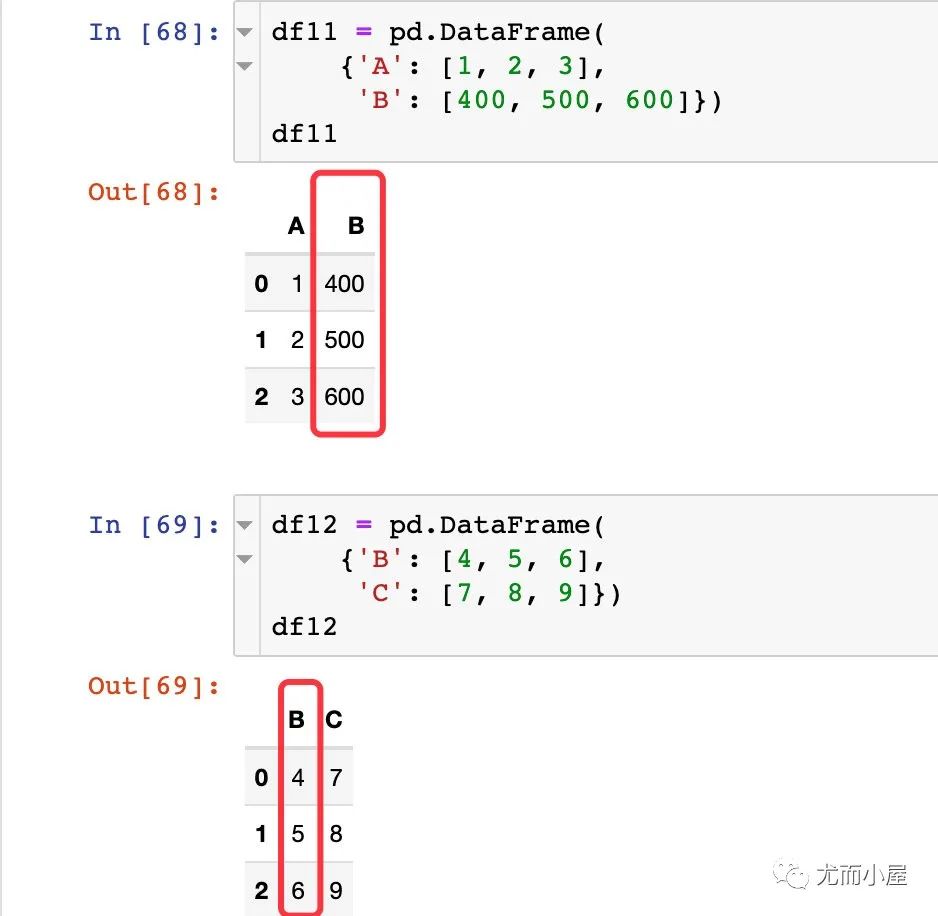
第一次更新的結(jié)果:

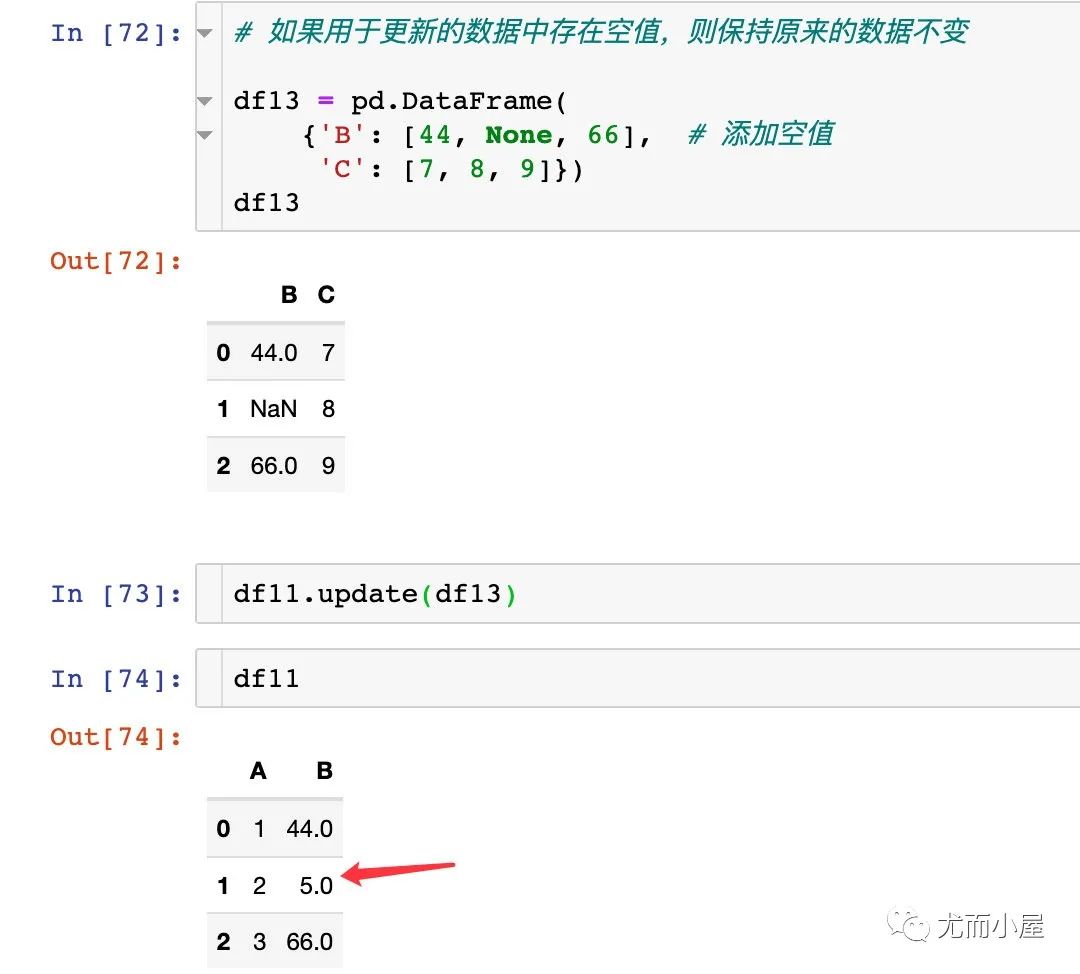
如果用于更新的數(shù)據(jù)中存在空值,則保持原來的數(shù)據(jù)不變
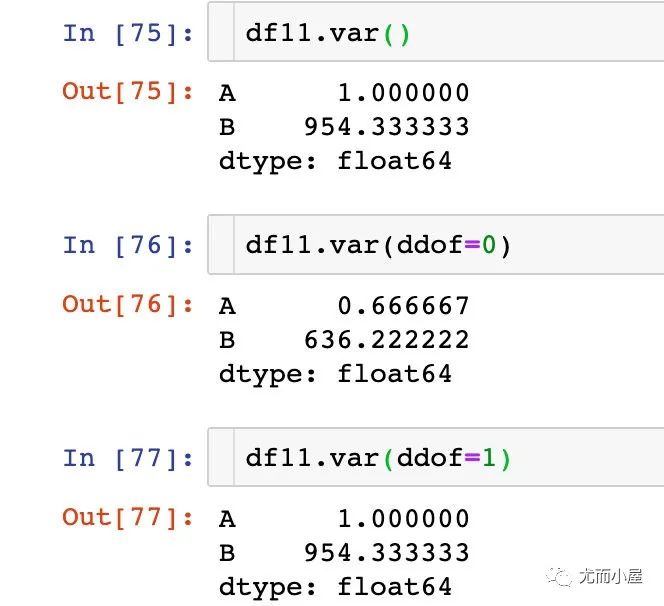
var函數(shù)
用于求一組數(shù)據(jù)的方差
where函數(shù)
用于查找滿足條件的數(shù)據(jù)
w?=?pd.Series(range(5))
w
0????0
1????1
2????2
3????3
4????4
dtype:?int64
#?滿足條件的顯示;不滿足的用空值代替
w.where(w>=2)
0????NaN
1????NaN
2????2.0
3????3.0
4????4.0
dtype:?float64
#?不滿足的用8替代
w.where(w>=2,?8)
0????8??#?8代替
1????8
2????2
3????3
4????4
dtype:?int64對比Excel系列圖書累積銷量達15w冊,讓你輕松掌握數(shù)據(jù)分析技能,可以在全網(wǎng)搜索書名進行了解選購:
