
Kylin 特性 | Kylin 4 最新功能預覽 + 優(yōu)化實踐搶先看
自 Kylin 4.0.0-beta 發(fā)布以來,2021 年上半年 Kylin 社區(qū)一直在積極推動 Kylin 4.0.0 的發(fā)布工作,與有贊、小米等 Kylin 深度用戶一起開發(fā)和測試,包括:
支持手動調(diào)整 Cuboid list 并重構(gòu)歷史 segment;
從 Kylin 3 到 Kylin 4 的元數(shù)據(jù)升級工具;
支持 Spark 3 等;
除了以上新功能外,社區(qū)還對實際使用過程中遇到的一些性能以及穩(wěn)定性問題進行了優(yōu)化。快來一起看看具體有什么新功能和優(yōu)化實踐吧~
1
Kylin 4 功能更新
支持用戶手動調(diào)整 Cuboid List
為了讓用戶可以根據(jù)業(yè)務場景更靈活的調(diào)整 Cube,Kylin 4.0 提供了允許用戶手動調(diào)整 cuboid list 的能力。通過調(diào)用 REST API 為指定 Cube 傳入需要刪除或增加的 cuboids,就可以更新指定 Cube 的 cuboid list。Cuboid list 更新后,Kylin 會對該 Cube 中每個已經(jīng)構(gòu)建過的 segment 生成對應的 optimize segment job 來更新歷史 segment 的 cuboid list。
Optimize segment job 不同于 Refresh segment Job,它不會重新構(gòu)建歷史 segment 中所有的 cuboid,而是從已有的 cuboid 數(shù)據(jù)來構(gòu)建新增 cuboid,并移除需要刪除的 cuboid。所有的 Optimize segment job 完成之后,最后會通過一個 checkpoint job 來統(tǒng)一更新 Cube 元數(shù)據(jù),并進行垃圾清理。在這個過程中用戶的所有查詢?nèi)蝿斩疾粫艿接绊憽?/p>
JIRA issue:
https://issues.apache.org/jira/browse/KYLIN-4966
元數(shù)據(jù)升級工具
對于 Kylin 2.x 和 Kylin 3.x 的老用戶來說,想要升級到 Kylin 4.0,需要對元數(shù)據(jù)進行升級。有贊在升級 Kylin 4.0 的實踐過程中,在 Kylin 提供的 Cube 遷移工具 CubeMigrationCLI 的基礎上,開發(fā)出了元數(shù)據(jù)升級工具,支持將 Kylin 2.x/ Kylin 3.x 版本的元數(shù)據(jù)以不同粒度遷移到 Kylin 4.0,用戶可以選擇指定單個 Cube 遷移、指定 project 遷移或者全量遷移。
JIRA issue:
https://issues.apache.org/jira/browse/KYLIN-4923
使用文檔:
https://cwiki.apache.org/confluence/display/KYLIN/How+to+migrate+metadata+to+Kylin+4
Kylin 4 支持 Spark 3.1.1
小米在試用 Kylin 4.0 的實踐過程中,根據(jù)實際需要將 Spark 版本從 Spark 2.4.6 升級到了 Spark 3.1.1,并且已經(jīng)向社區(qū)提了 PR,目前我們正在 review 和測試,預計將在 Kylin 4.0.0 中提供對 Spark 3.1.1 的支持。
未來在 Kylin 4.0 支持 Spark 3 之后,用戶不僅能夠使用 Spark 3.0 中很多強大的新特性,比如 AQE 等,同時也能夠?qū)崿F(xiàn)對 Hive 2 和 Hive 3 更好的兼容。
JIRA issue:
https://issues.apache.org/jira/browse/KYLIN-4925
2
Kylin 4 性能優(yōu)化實踐
解決構(gòu)建過程中產(chǎn)生的數(shù)據(jù)傾斜問題
對于存在精確去重度量的 Cube,在構(gòu)建 base cuboid 之前,Kylin 需要對 Flat Table 使用全局字典進行編碼。Kylin 4.0 的構(gòu)建引擎在進行編碼時,為了提高編碼效率,會將 Flat Table 按照當前編碼列進行 repartition。當編碼列存在數(shù)據(jù)傾斜時,對它進行 repartition 操作就會導致重分區(qū)后 Flat Table 的某一個或者少數(shù)幾個 partition 的數(shù)據(jù)量特別大,用這樣的 Flat Table 去構(gòu)建 base cuboid 時,數(shù)據(jù)量大的 partition 所對應的 task 可能就會占用特別長的時間,造成不合理的構(gòu)建時長。
為了解決這個問題,Kylin 4.0 在編碼過程之后增加了一個可配置的步驟。該步驟會根據(jù)所有 Rowkey 列再次進行 repartition,糾正根據(jù)編碼列進行重分區(qū)后產(chǎn)生的數(shù)據(jù)傾斜問題,然后數(shù)據(jù)就會比較均勻的分布在各個 partition,這樣再進行后面的構(gòu)建 base cuboid 操作時,各個 task 的用時情況就會比較平均。
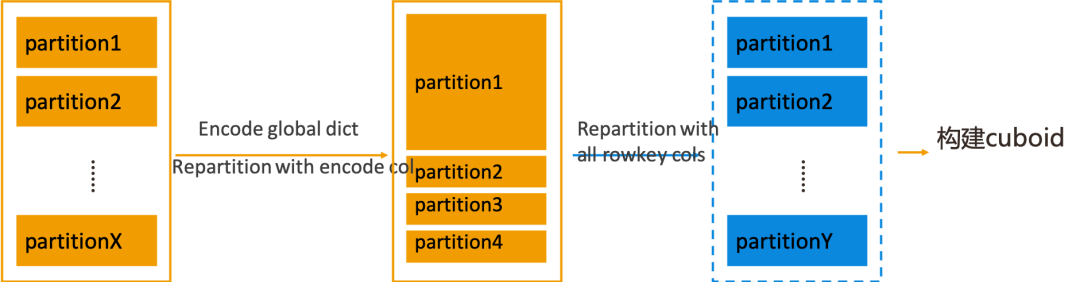
以上這個步驟在默認情況下是關閉的,用戶可以根據(jù)自己的實際場景來決定是否打開,配置項為:kylin.engine.spark.repartition.encoded.dataset。
除了開關以外,此步驟還有一個相關的配置項:kylin.engine.spark.dataset.repartition.num.after.encoding,用于控制該 repartition 步驟的分區(qū)數(shù)量。在默認情況下,會使用之前為編碼列編碼過程中分區(qū)數(shù)量的最大值作為這次重分區(qū)操作的分區(qū)數(shù)。
在有贊的實踐案例中,經(jīng)過以上的優(yōu)化,base cuboid 的構(gòu)建時長可以從 20 分鐘減小至 4 分鐘。
JIRA issue:
https://issues.apache.org/jira/browse/KYLIN-4945
避免構(gòu)建過程中重復讀取 Cuboid 文件
Kylin 4.0 在構(gòu)建過程中會將所有 cuboid 組織成一棵 Spanning tree,構(gòu)建下一層 child cuboid 時將上一層 cuboid 作為 parent cuboid,構(gòu)建 child cuboid 時會從 hdfs 中讀取已經(jīng)構(gòu)建好的 parent cuboid 數(shù)據(jù)。這樣就會造成多個 child cuboid 都使用同一個 parent cuboid 進行構(gòu)建時會重復讀取 HDFS 中的 Cuboid 文件的情況。
針對這個問題,Kylin 4.0 的解決方案是對擁有多個 child cuboid 的 parent cuboid 做 persist 操作。當發(fā)現(xiàn)某個 parent cuboid 的 child cuboid 的數(shù)量大于 1 的時候,就會在首次讀取該 parent cuboid 時將 cuboid dataset persist 到指定 storage level,這樣其他的 child cuboid 需要讀取該 parent cuboid 時,就可以從 cache 中讀取到,不必再去訪問 HDFS,當 parent cuboid 的所有 child cuboid 都構(gòu)建完成后,對應的 cache 會被 release。
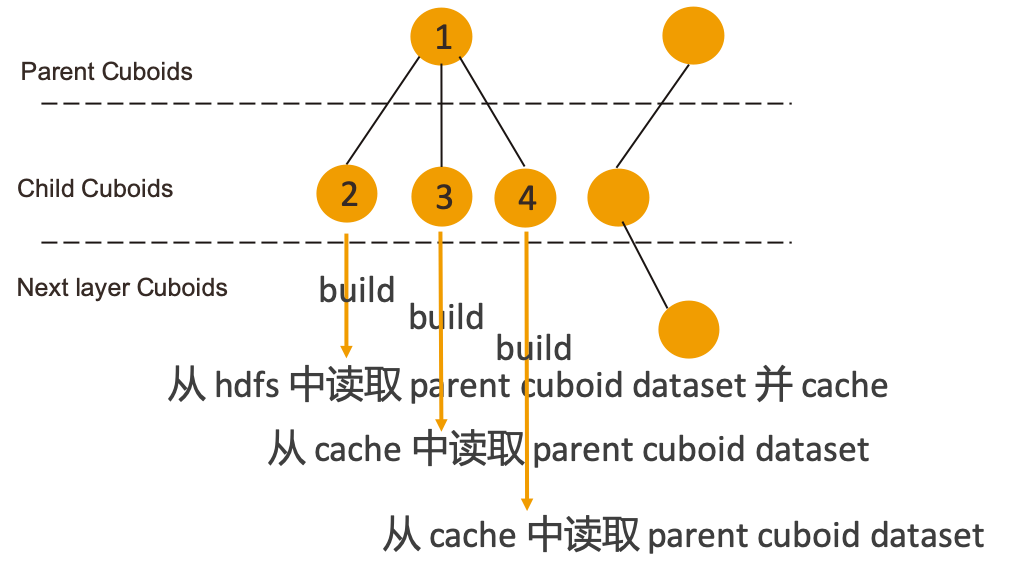
Persist 的 storage level 是需要用戶自己配置的, 配置項為 kylin.engine.spark.parent-dataset.storage.level,默認為 NONE,即不提供緩存。用戶可以將其配置為 MEMORY_ONLY、MEMORY_AND_DISK 等這些 Spark 的 StorageLevel 中提供的類型。
除此之外,為了防止內(nèi)存占用過多,新增配置項 kylin.engine.spark.parent-dataset.max.persist.count 來控制同一時間最多可以 persist 多少個 cuboid dataset,默認為 1。如果這個值配置為 10,那么在并行發(fā)起一層 cuboid 的構(gòu)建時,當 cache 數(shù)量達到 10 時,后續(xù)需要 persist parent cuboid 的 child cuboid 的構(gòu)建任務將會被阻塞,直到 cache 中有 parent cuboid 的緩存被 release,才會繼續(xù)進行后續(xù)的構(gòu)建任務,所以開啟這個功能之后,會在一定程度上影響構(gòu)建的并行度。用戶可以參考自身需求,根據(jù)實際場景來使用。
在有贊的實踐經(jīng)驗中,配置 StorageLevel 為MEMORY_AND_DISK,max persist count 為 5,可以提高 20~30% 的構(gòu)建速度。
JIRA issue:
https://issues.apache.org/jira/browse/KYLIN-4903
優(yōu)化對于精準命中 Cuboid 的 SQL 的處理
Kylin 4 在查詢過程中,需要將 calcite 的 SQL 執(zhí)行計劃轉(zhuǎn)化成 Spark 的執(zhí)行計劃,對于 calcite 中 aggregate 類型的 RelNode,轉(zhuǎn)換到 Spark 執(zhí)行計劃中就是一個 aggregate 算子,Spark 在執(zhí)行 aggregate 的過程會產(chǎn)生 shuffle。大家都知道,shuffle 是一個比較昂貴的操作,它會產(chǎn)生大量的磁盤 IO 和網(wǎng)絡資源以及內(nèi)存消耗。
實際上,對于一條可以與某個 cuboid 精確匹配的 SQL 而言,不需要進行任何上卷聚合,就可以從匹配的 cuboid 中 select 出符合條件的數(shù)據(jù)。
但是 Kylin 4 在將 calcite 執(zhí)行計劃轉(zhuǎn)化成 Spark 執(zhí)行計劃時,無論 cuboid 是否精確匹配,calcite 中的 aggregate 都會轉(zhuǎn)化成 Spark 執(zhí)行計劃中的 aggregate,而在精準匹配 cuboid 的情況下,這里的 aggregate 除了會在操作過程中產(chǎn)生 shuffle,實際上并沒有進行任何的數(shù)據(jù)聚合。
為了優(yōu)化這種查詢場景,我們在將 calcite 的 aggregate 的 relnode 轉(zhuǎn)化成 Spark plan 時,增加了對是否精確匹配 cuboid 的判斷。當 aggregate relnode 中 group by 的列與 cuboid 的列完全一致時,就認為當前聚合是精確匹配到 cuboid 的,不需要進行二次聚合,這時候就會跳過 Spark 中的 aggregate,直接轉(zhuǎn)化成 project。
當然,這里也會有一些特殊情況需要處理,對于查詢的度量是精確去重或者近似去重時,還是需要先計算出去重的結(jié)果。經(jīng)過優(yōu)化,同樣的一條 SQL 查詢?nèi)蝿债a(chǎn)生的 Spark job DAG 圖對比如下:
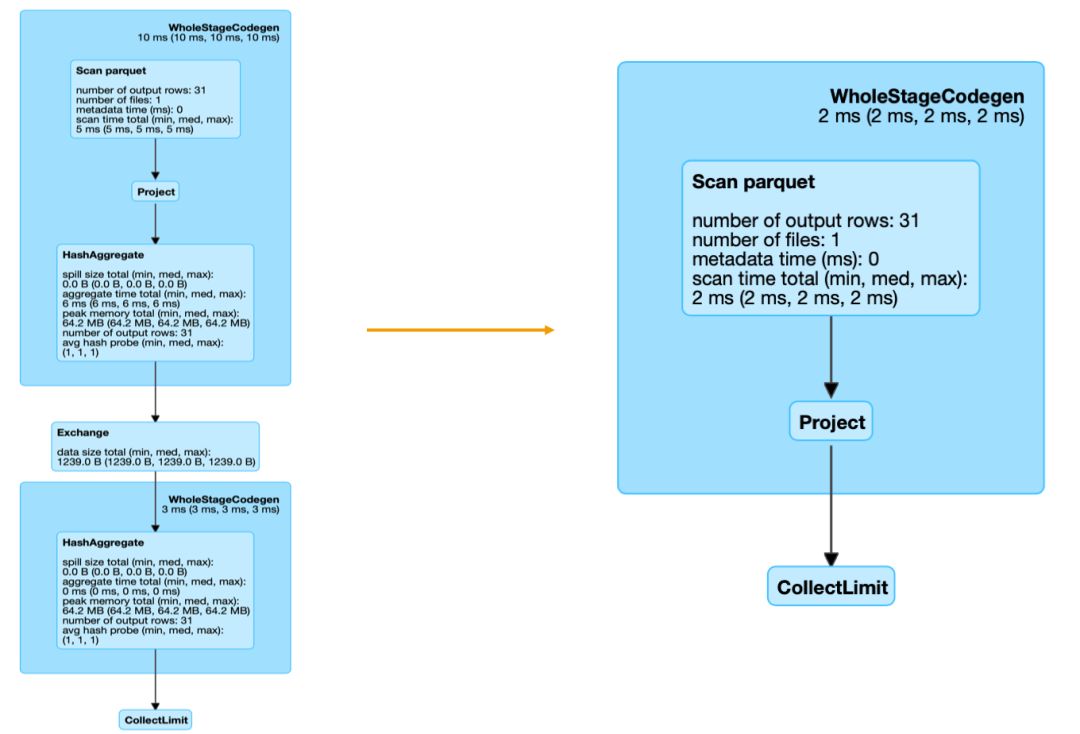
在有贊的實踐案例中,經(jīng)過以上優(yōu)化,對包含去重指標(無論是精確去重還是近似去重)的查詢,QPS 可以從 39 提升到 49,對于沒有去重指標的查詢,QPS 可以從 40 提高到 60。
3
Kylin 4 近期技術會議
目前有贊和小米都在深度試用 Kylin 4.0,已經(jīng)向社區(qū)貢獻了各類優(yōu)化改進等十幾個 PR, 社區(qū)也對他們在試用過程中遇到的各類問題積極響應,這些實踐經(jīng)驗也幫助 Kylin 4.0 變得更快速、更穩(wěn)定。隨著 Kylin 4.0 實踐的深入,近期我們將會在兩場技術大會上分享 Kylin 4.0 的實踐和調(diào)優(yōu)經(jīng)驗:
QCon 全球軟件開發(fā)者大會
在 2021 年 5 月 29 日 - 31 日舉辦的 QCon 全球軟件開發(fā)者大會上,來自有贊的數(shù)據(jù)基礎平臺負責人鄭生俊將會在大數(shù)據(jù)開源框架與應用專題上分享有贊內(nèi)部對 Kylin 4.0 的使用經(jīng)歷和優(yōu)化實踐。
*活動鏈接:
https://qcon.infoq.cn/2021/beijing/presentation/3384
ApacheCon Asia
今年 8 月 6 日 - 8 日即將舉辦首次 ApacheCon Asia 線上大會,來自 Kyligence 的高級架構(gòu)師張智超將會從架構(gòu)升級、構(gòu)建調(diào)優(yōu)、查詢調(diào)優(yōu)等幾個方面來介紹 Apache Kylin 4.0 全新的調(diào)優(yōu)之路,具體活動議程將于六月公布,請大家敬請期待~
*活動鏈接:https://apachecon.com/acasia2021/
歡迎對 Kylin 4.0 感興趣的小伙伴們報名參加!

點擊閱讀原文,試用 Kylin 4.0.0-beta