
Kylin 優(yōu)化 | Kylin 4 云上性能優(yōu)化:本地緩存與軟親和性調(diào)度
一、背景介紹
日前,Apache Kylin 社區(qū)發(fā)布了全新架構(gòu)的 Kylin 4.0。Kylin 4.0 的架構(gòu)支持存儲和計算分離,這使得 Kylin 用戶可以采取更加靈活、計算資源可以彈性伸縮的云上部署方式來運行 Kylin 4.0。借助云上的基礎(chǔ)設(shè)施,用戶可以選擇使用便宜且可靠的對象存儲來儲存 cube 數(shù)據(jù),比如 S3 等。不過在存儲與計算分離的架構(gòu)下,我們需要考慮到,計算節(jié)點通過網(wǎng)絡(luò)從遠(yuǎn)端存儲讀取數(shù)據(jù)仍然是一個代價較大的操作,往往會帶來性能的損耗。
為了提高 Kylin 4.0 在使用云上對象存儲作為存儲時的查詢性能,我們嘗試在 Kylin 4.0 的查詢引擎中引入本地緩存(Local Cache)機(jī)制,在執(zhí)行查詢時,將經(jīng)常使用的數(shù)據(jù)緩存在本地磁盤,減小從遠(yuǎn)程對象存儲中拉取數(shù)據(jù)帶來的延遲,實現(xiàn)更快的查詢響應(yīng);除此之外,為了避免同樣的數(shù)據(jù)在大量 spark executor 上同時緩存浪費磁盤空間,并且計算節(jié)點可以更多的從本地緩存讀取所需數(shù)據(jù),我們引入了 軟親和性(Soft Affinity )的調(diào)度策略,所謂軟親和性策略,就是通過某種方法在 spark executor 和數(shù)據(jù)文件之間建立對應(yīng)關(guān)系,使得同樣的數(shù)據(jù)在大部分情況下能夠總是在同一個 executor 上面讀取,從而提高緩存的命中率。
二、實現(xiàn)原理
在 Kylin 4.0 執(zhí)行查詢時,主要經(jīng)過以下幾個階段,其中用虛線標(biāo)注出了可以使用本地緩存來提升性能的階段:
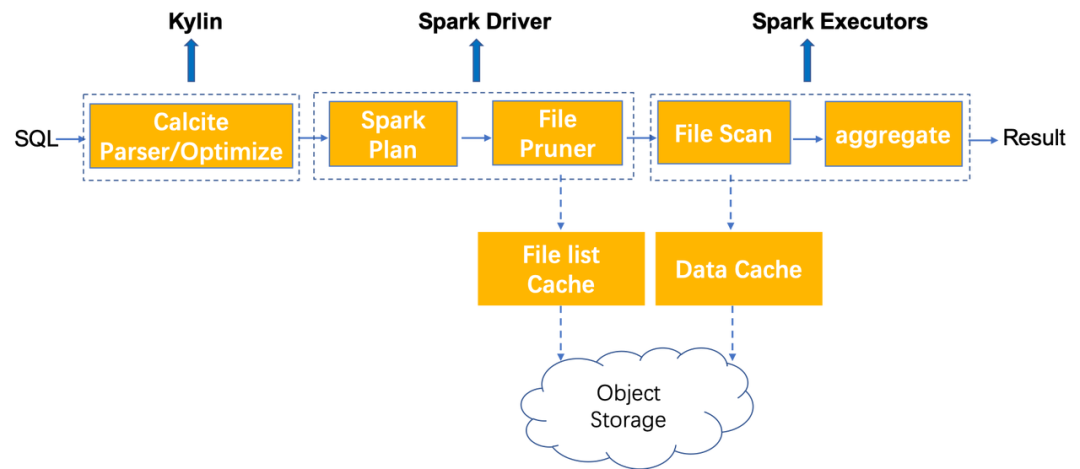
File list cache:在 spark driver 端對 file status 進(jìn)行緩存。在執(zhí)行查詢時,spark driver 需要讀取文件列表,獲取一些文件信息進(jìn)行后續(xù)的調(diào)度執(zhí)行,這里會將 file status 信息緩存到本地避免頻繁讀取遠(yuǎn)程文件目錄。
Data cache:在 spark executor 端對數(shù)據(jù)進(jìn)行緩存。用戶可以設(shè)置將數(shù)據(jù)緩存到內(nèi)存或是磁盤,若設(shè)置為緩存到內(nèi)存,則需要適當(dāng)調(diào)大 executor memory,保證 executor 有足夠的內(nèi)存可以進(jìn)行數(shù)據(jù)緩存;若是緩存到磁盤,需要用戶設(shè)置數(shù)據(jù)緩存目錄,最好設(shè)置為 SSD 磁盤目錄。除此之外,緩存數(shù)據(jù)的最大容量、備份數(shù)量等均可由用戶配置調(diào)整。
基于以上設(shè)計,在 Kylin 4.0 的查詢引擎 sparder 的 driver 端和 executor 端分別做不同類型的緩存,基本架構(gòu)如下:
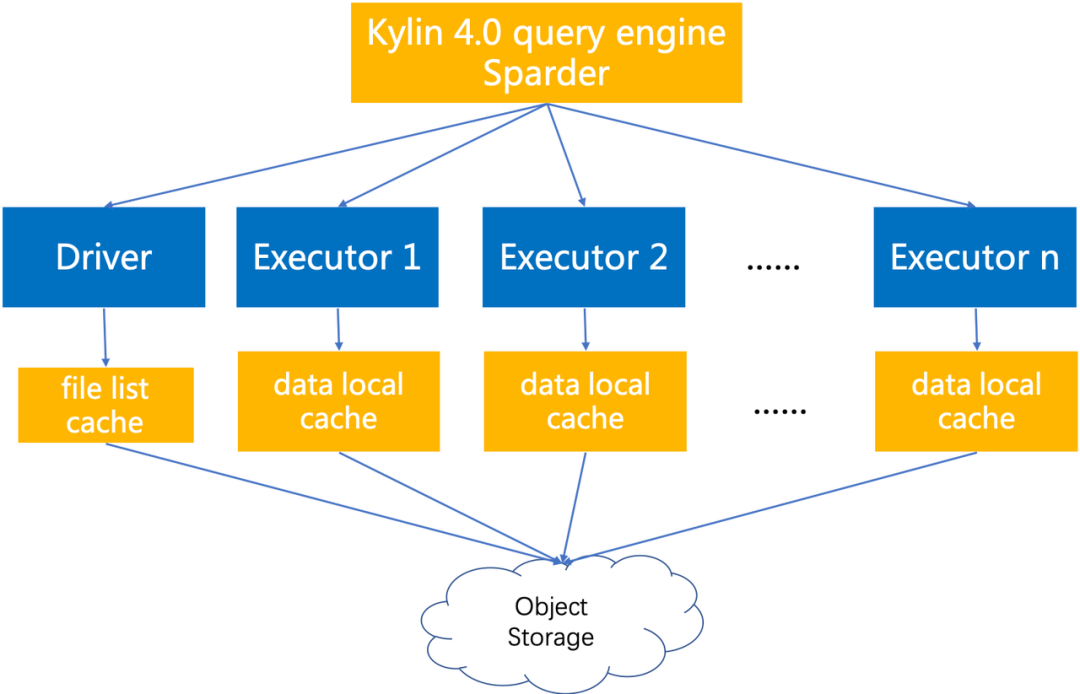
在 executor 端做 data cache 時,如果在所有的 executor 上都緩存全部的數(shù)據(jù),那么緩存數(shù)據(jù)的大小將會非常可觀,極大的浪費磁盤空間,同時也容易導(dǎo)致緩存數(shù)據(jù)被頻繁清理。為了最大化 spark executor 的緩存命中率,spark driver 需要將同一文件的 task 在資源條件滿足的情況下盡可能調(diào)度到同樣的 executor,這樣可以保證相同文件的數(shù)據(jù)能夠緩存在特定的某個或者某幾個 executor 上,再次讀取時便可以通過緩存讀取數(shù)據(jù)。
為此,我們采取根據(jù)文件名計算 hash 之后再與 executors num 取模的結(jié)果來計算目標(biāo) executor 列表,在多少個 executor 上面做緩存由用戶配置的緩存?zhèn)浞輸?shù)量決定,一般情況下,緩存?zhèn)浞輸?shù)量越大,擊中緩存的概率越高。當(dāng)目標(biāo) executor 均不可達(dá)或者沒有資源供調(diào)度時,調(diào)度程序?qū)⒒赝说?spark 的隨機(jī)調(diào)度機(jī)制上。這種調(diào)度方式便稱為軟親和性調(diào)度策略,它雖然不能保證 100% 擊中緩存,但能夠有效提高緩存命中率,在盡量不損失性能的前提下避免 full cache 浪費大量磁盤空間。
三、相關(guān)配置
根據(jù)以上原理,我們在 Kylin 4.0 中實現(xiàn)了本地緩存+軟親和性調(diào)度的基礎(chǔ)功能,并分別基于 SSB 數(shù)據(jù)集和 TPCH 數(shù)據(jù)集做了查詢性能測試。
這里列出幾個比較重要的配置項供用戶了解,實際使用的配置將在結(jié)尾鏈接中給出:
是否開啟軟親和性調(diào)度策略:kylin.query.spark-conf.spark.kylin.soft-affinity.enabled
是否開啟本地緩存:kylin.query.spark-conf.spark.hadoop.spark.kylin.local-cache.enabled
Data cache 的備份數(shù)量,即在多少個 executor 上對同一數(shù)據(jù)文件進(jìn)行緩存:kylin.query.spark-conf.spark.kylin.soft-affinity.replications.num
緩存到內(nèi)存中還是本地目錄,緩存到內(nèi)存設(shè)置為 BUFF,緩存到本地設(shè)置為 LOCAL:kylin.query.spark-conf.spark.hadoop.alluxio.user.client.cache.store.type
最大緩存容量:kylin.query.spark-conf.spark.hadoop.alluxio.user.client.cache.size
四、性能對比
我們在 AWS EMR 環(huán)境下進(jìn)行了 3 種場景的性能測試,在 scale factor = 10的情況下,對 SSB 數(shù)據(jù)集進(jìn)行單并發(fā)查詢測試、TPCH 數(shù)據(jù)集進(jìn)行單并發(fā)查詢以及 4 并發(fā)查詢測試,實驗組和對照組均配置 S3 作為存儲,在實驗組中開啟本地緩存和軟親和性調(diào)度,對照組則不開啟。除此之外,我們還將實驗組結(jié)果與相同環(huán)境下 HDFS 作為存儲時的結(jié)果進(jìn)行對比,以便用戶可以直觀的感受到 本地緩存+軟親和性調(diào)度 對云上部署 Kylin 4.0 使用對象存儲作為存儲場景下的優(yōu)化效果。
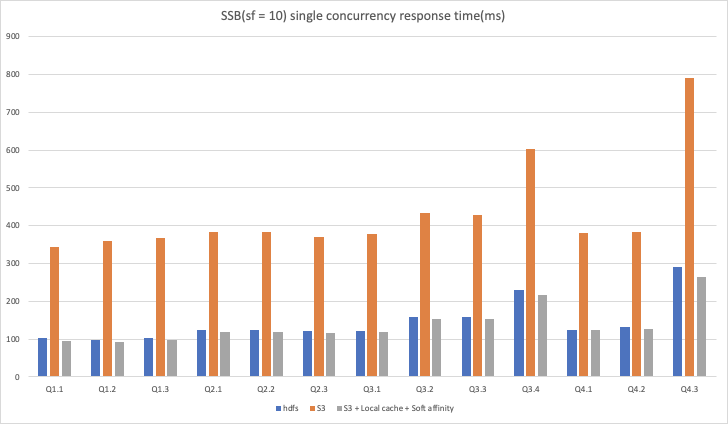
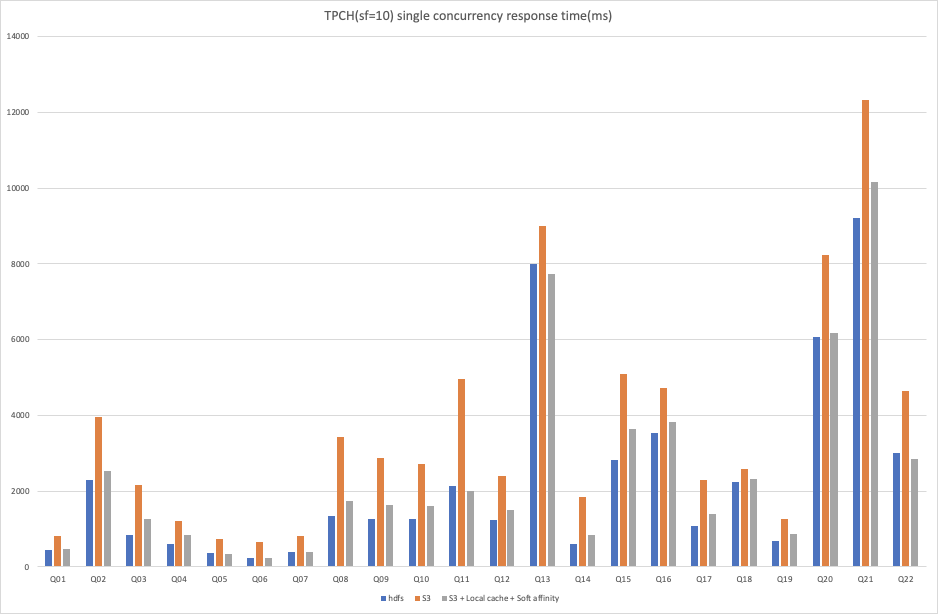
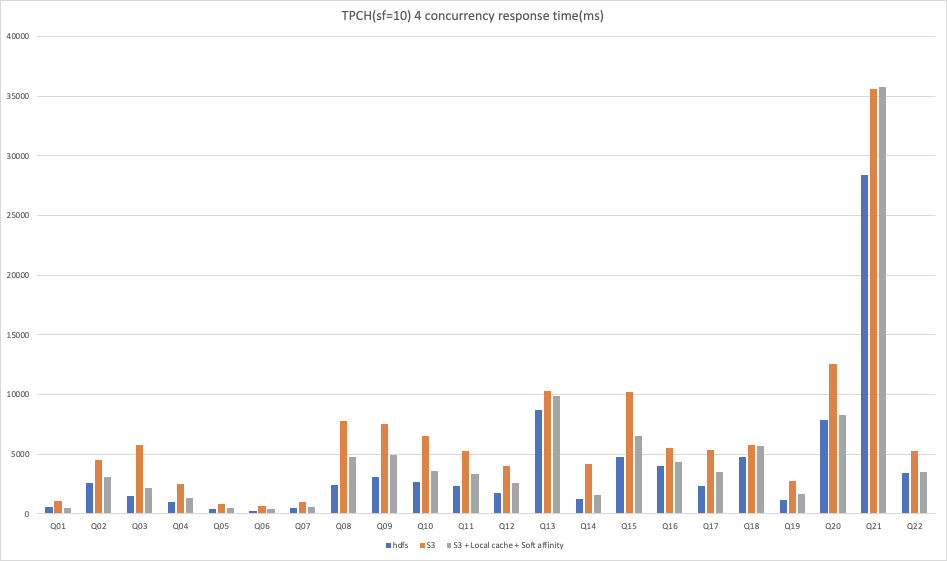
從以上結(jié)果可以看出:
在 SSB?10 數(shù)據(jù)集單并發(fā)場景下,使用 S3 作為存儲時,開啟本地緩存和軟親和性調(diào)度能夠獲得3倍左右的性能提升,可以達(dá)到與 HDFS 作為存儲時的相同性能甚至還有 5% 左右的提升。
在 TPCH?10 數(shù)據(jù)集下,使用 S3 作為存儲時,無論是單并發(fā)查詢還是多并發(fā)查詢,開啟本地緩存和軟親和性調(diào)度后,基本在所有查詢中都能夠獲得大幅度的性能提升。
不過在 TPCH 10 數(shù)據(jù)集的 4 并發(fā)測試下的 Q21 的對比結(jié)果中,我們觀察到,開啟本地緩存和軟親和性調(diào)度的結(jié)果反而比單獨使用 S3 作為存儲時有所下降,這里可能是由于某種原因?qū)е聸]有通過緩存讀取數(shù)據(jù),深層原因在此次測試中沒有進(jìn)行進(jìn)一步的分析,在后續(xù)的優(yōu)化過程中我們會逐步改進(jìn)。由于 TPCH 的查詢比較復(fù)雜且 SQL 類型各異,與 HDFS 作為存儲時的結(jié)果相比,仍然有部分 SQL 的性能略有不足,不過總體來說已經(jīng)與 HDFS 的結(jié)果比較接近。
本次性能測試的結(jié)果是一次對 本地緩存+軟親和性調(diào)度 性能提升效果的初步驗證,從總體上來看,本地緩存+軟親和性調(diào)度 無論對于簡單查詢還是復(fù)雜查詢都能夠獲得明顯的性能提升,但是在高并發(fā)查詢下相比單并發(fā)查詢存在一定的性能損失。
如果用戶使用云上對象存儲作為 Kylin 4.0 的存儲,在開啟 本地緩存+ 軟親和性調(diào)度的情況下,是可以獲得很好的性能體驗的,這為 Kylin 4.0 在云上使用計算和存儲分離架構(gòu)提供了性能保障。
五、代碼實現(xiàn)
由于目前的代碼實現(xiàn)還處于比較基礎(chǔ)的階段,還有許多細(xì)節(jié)需要完善,比如實現(xiàn)一致性哈希、當(dāng) executor 數(shù)量發(fā)生變化時如何處理已有 cache 等,所以作者還未向社區(qū)代碼庫提交 PR,想要提前預(yù)覽的開發(fā)者可以通過下面的鏈接查看源碼:
https://github.com/apache/kylin/commit/4e75b7fa4059dd2eaed24061fda7797fecaf2e35
相關(guān)鏈接
想要了解更多詳情,可通過鏈接查閱性能測試結(jié)果數(shù)據(jù)和 kylin.properties:
https://github.com/Kyligence/kylin-tpch/issues/9