
幾十行代碼爬取貓眼電影Top100榜單
基本信息
今天,手把手教你入門 Python 爬蟲,爬取貓眼電影 TOP100 榜信息。
貓眼電影的網(wǎng)址為:http://maoyan.com/,但這不是我們此次想爬取的站點(diǎn),我們爬取的站點(diǎn)是這個:http://maoyan.com/board/4(TOP100榜單)
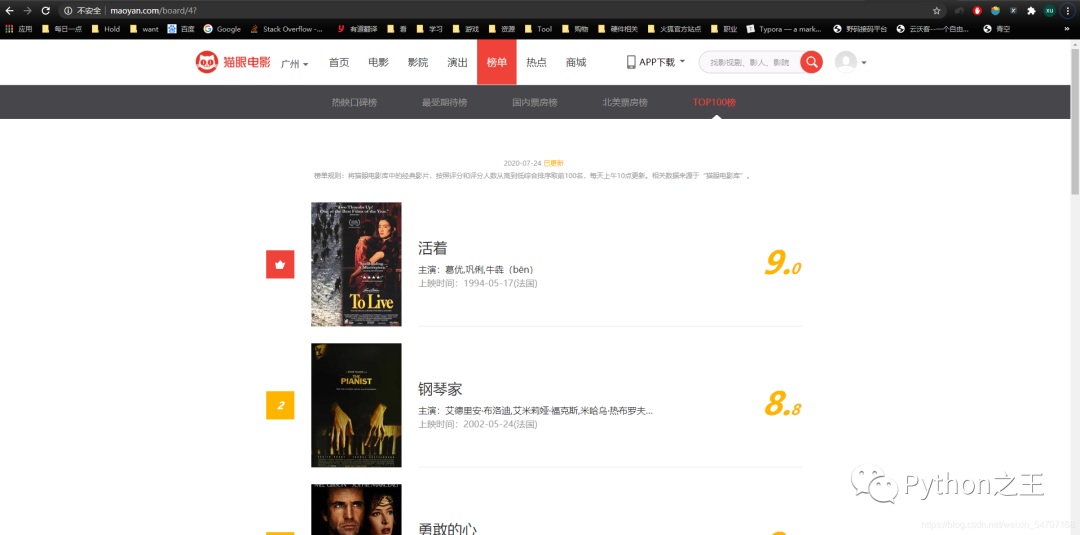
前100的電影的信息爬下來,保存起來。
下面是爬取結(jié)果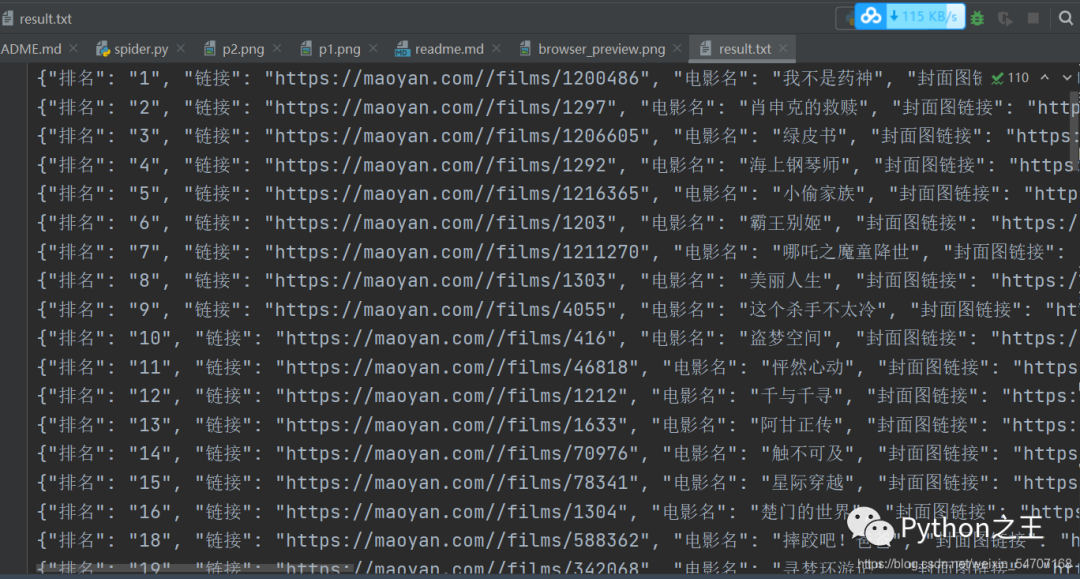
描述
靜態(tài)網(wǎng)頁,非常簡單 ?。通過觀察我們需要爬取的內(nèi)容有:片名,圖片,排名,主演,上映時間和評分這6部分。

使用的包/工具/技術(shù)
| 步驟 | 包/工具/技術(shù) |
|---|---|
| 網(wǎng)頁分析 | Chrome |
| 爬取網(wǎng)頁 | requests |
| 解析網(wǎng)頁 | re |
問題與對應(yīng)處理
IP訪問頻率
懶得弄代理,選擇每次爬取后等待一段時間
User-Agent限制
請求頭對應(yīng)項(xiàng)填寫一下即可
分析
翻頁參數(shù)


翻頁的參數(shù)每一次加10而不是1
如何通過Re解析
我們先將源代碼:view-source:https://maoyan.com/board/4?offset=10。
復(fù)制到:http://www.regexp.cn/Regex
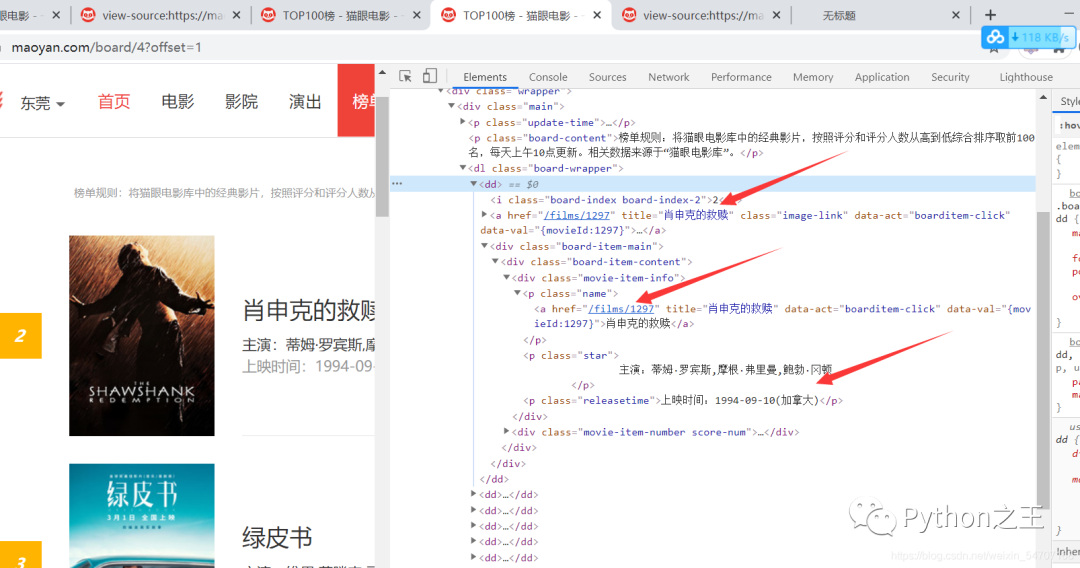
最終我們的正則表達(dá)式是這樣的:
[\s\S]*?board-index-.+?>(.*?)<[\s\S]+?href="(.*?)" title="(.*?)"[\s\S]+?[\s\S]*?主演:(.*?)\n[\s\S]*?上映時間:(\d+-\d+-\d+).*?<[\s\S]*?class="integer">(.*?)<[\s\S]*?class="fraction">(.*?)<
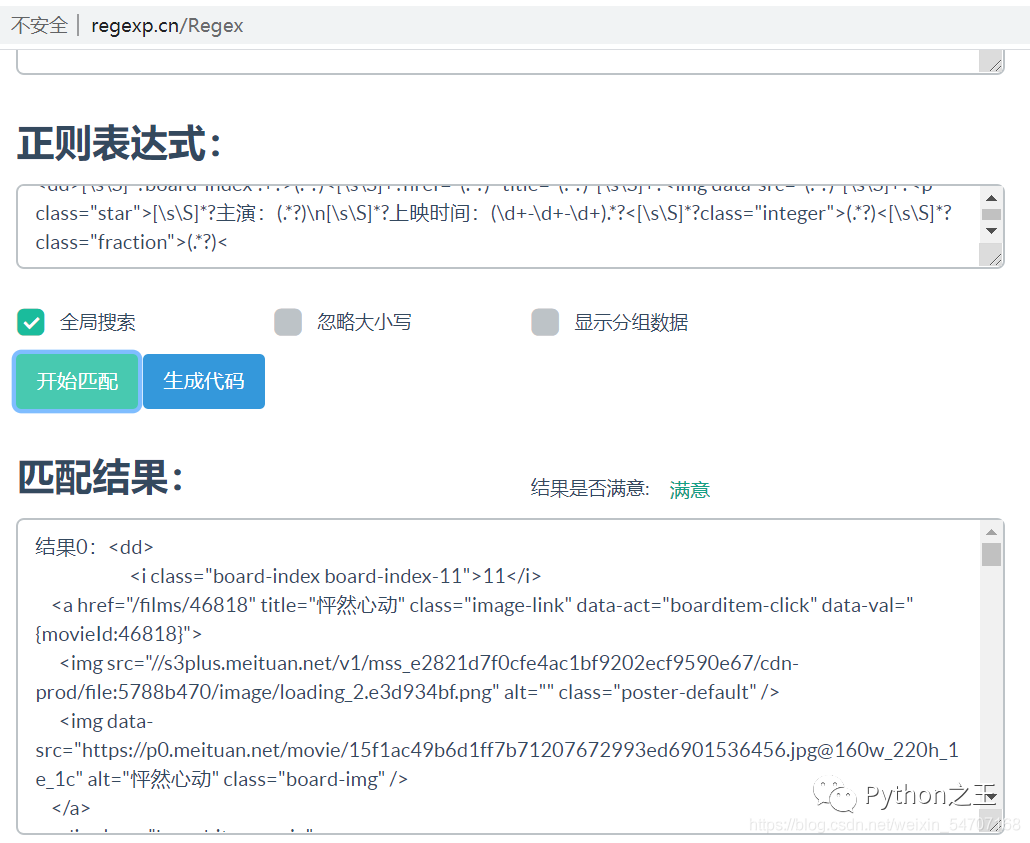
下面就是正則解析的代碼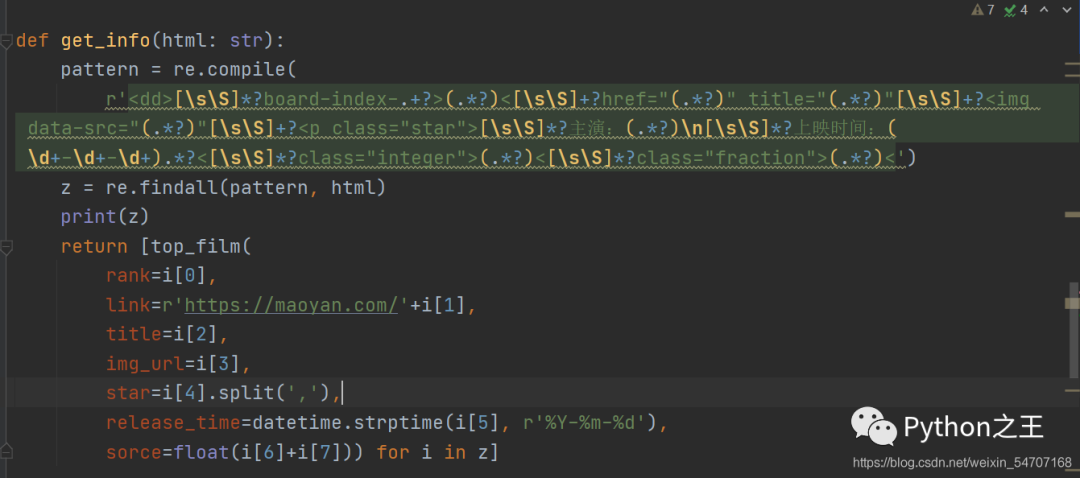

最后就是封裝代碼,實(shí)現(xiàn)整套爬蟲的代碼
import?requests
from?requests.exceptions?import?RequestException
import?re
from?datetime?import?datetime
import?json
import?time
class?top_film(object):
????def?__init__(self,?rank:?int,?link:?str,?title:?str,?img_url:?str,?star:?list,?release_time:?datetime,?sorce:?float):
????????self.rank?=?rank
????????self.link?=?link
????????self.title?=?title
????????self.img_url?=?img_url
????????self.star?=?star
????????self.release_time?=?release_time
????????self.sorce?=?sorce
????def?to_dict(self):
????????return?{
????????????'排名':?self.rank,
????????????'鏈接':?self.link,
????????????'電影名':?self.title,
????????????'封面圖鏈接':?self.img_url,
????????????'主演:':?str(self.star),
????????????'上映時間':?self.release_time.strftime(r'%Y-%m-%d'),
????????????'貓眼評分':?str(self.sorce)
????????}
def?get_a_page(page_num):
????url?=?'https://maoyan.com/board/4?offset='?+?str(page_num*10)
????headers?=?{
????????'User-Agent':?'Mozilla/5.0?(Windows?NT?10.0;?Win64;?x64)?AppleWebKit/537.36?(KHTML,?like?Gecko)?Chrome/83.0.4103.116?Safari/537.36',
????}
????try:
????????response?=?requests.get(url,?headers=headers)
????????if?response.status_code?==?200:
????????????return?response.text
????except?RequestException?as?e:
????????time.sleep(3)
????????print(e)
????????return?None
def?get_info(html:?str):
????pattern?=?re.compile(
????????r'[\s\S]*?board-index-.+?>(.*?)<[\s\S]+?href="(.*?)" title="(.*?)"[\s\S]+?[\s\S]*?主演:(.*?)\n[\s\S]*?上映時間:(\d+-\d+-\d+).*?<[\s\S]*?class="integer">(.*?)<[\s\S]*?class="fraction">(.*?)<' )
????z?=?re.findall(pattern,?html)
????print(z)
????return?[top_film(
????????rank=i[0],
????????link=r'https://maoyan.com/'+i[1],
????????title=i[2],
????????img_url=i[3],
????????star=i[4].split(','),
????????release_time=datetime.strptime(i[5],?r'%Y-%m-%d'),
????????sorce=float(i[6]+i[7]))?for?i?in?z]
def?crawl_maoyan_top_100():
????result?=?[]
????for?page_num?in?range(0,?10):
????????html?=?get_a_page(page_num)
????????print(get_info(html))
????????result.extend(get_info(html))
????????print(page_num)
????return?result
if?__name__?==?"__main__":
????result?=?crawl_maoyan_top_100()
????print(result)
????with?open('result.txt',?'w',?encoding='utf-8')as?f:
????????for?film?in?result:
????????????f.write(json.dumps(film.to_dict(),?ensure_ascii=False)?+?'\n')
評論
圖片
表情