
簡單到出人意料的CNN圖像分類策略
在這篇文章中,作者展示了為什么最先進(jìn)的深度神經(jīng)網(wǎng)絡(luò)仍能很好地識別亂碼圖像,探究其中原因有助于揭示DNN使用讓人意想不到的簡單策略,對自然圖像進(jìn)行分類。
在ICLR 2019一篇論文指出上述發(fā)現(xiàn)能夠:
解決ImageNet比許多人想象的要簡單得多
使我們能夠構(gòu)建更具解釋性和透明度的圖像分類pipeline
解釋了現(xiàn)代CNN中觀察到的一些現(xiàn)象,例如對紋理的偏見以及忽略了對象部分的空間排序
復(fù)古bag-of-features模型
在深度學(xué)習(xí)出現(xiàn)之前,自然圖像中的對象識別過程相當(dāng)粗暴簡單:定義一組關(guān)鍵視覺特征(“單詞”),識別每個視覺特征在圖像中的存在頻率(“包”),然后根據(jù)這些數(shù)字對圖像進(jìn)行分類。這些模型被稱為“特征包”模型(BoF模型)。
舉個例子,給定一個人眼和一個羽毛,我們想把圖像分類為“人”和“鳥”兩類。最簡單的BoF模型工作流程是這樣的:對于圖像中的每只眼睛,它將“人類”的證據(jù)增加+1。反之亦然;對于圖像中的每個羽毛,它將增加“鳥”的證據(jù)+1;無論什么類積累,圖像中的大多數(shù)證據(jù)都是預(yù)測的。
這個最簡單的BoF模型有一個很好的特性,是它的可解釋性和透明的決策制定。我們可以準(zhǔn)確地檢查哪個圖像特征攜帶了給定的類的證據(jù),證據(jù)的空間整合是非常簡單的(與深度神經(jīng)網(wǎng)絡(luò)中的深度非線性特征整合相比),很容易理解模型如何做出決定。
傳統(tǒng)的BoF模型在深度學(xué)習(xí)開始之前一直非常先進(jìn)、非常流行。但由于其分類性能過低,而很快失寵。可是,我們怎么確定深度神經(jīng)網(wǎng)絡(luò)有沒有使用與BoF模型截然不同的決策策略呢?
一個很深卻可解釋的BoF網(wǎng)絡(luò)(BagNet)
為了測試這一點(diǎn),研究人員將BoF模型的可解釋性和透明度與DNN的性能結(jié)合起來。
將圖像分割成小的q x q圖像色塊
通過DNN傳遞補(bǔ)丁以獲取每個補(bǔ)丁的類證據(jù)(logits)
對所有補(bǔ)丁的證據(jù)求和,以達(dá)到圖像級決策
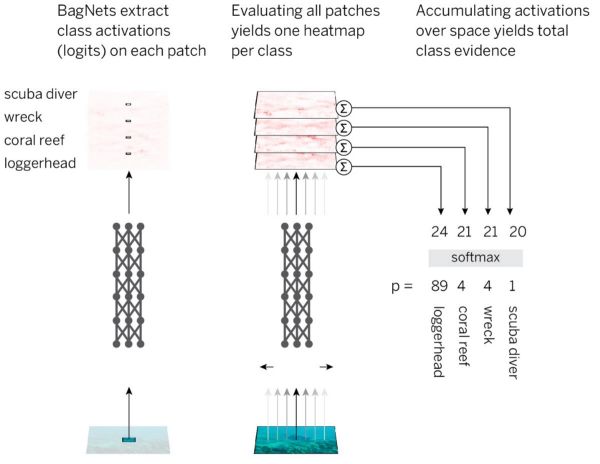
BagNets的分類策略:對于每個補(bǔ)丁,我們使用DNN提取類證據(jù)(logits)并總結(jié)所有補(bǔ)丁的總類證據(jù)
為了以最簡單和最有效的方式實現(xiàn)這一策略,我們采用標(biāo)準(zhǔn)的ResNet-50架構(gòu),用1x1卷積替換大多數(shù)(但不是全部)3x3卷積。
在這種情況下,最后一個卷積層中的隱藏單元每個只“看到”圖像的一小部分(即它們的感受野遠(yuǎn)小于圖像的大小)。
這就避免了對圖像的顯式分區(qū),并且盡可能接近標(biāo)準(zhǔn)CNN,同時仍然實現(xiàn)概述的策略,我們稱之為模型結(jié)構(gòu)BagNet-q:其中q代表最頂層的感受域大小(我們測試q=9,17和33)。BagNet-q的運(yùn)行時間大約是ResNet-50的運(yùn)行時間的2.5倍。
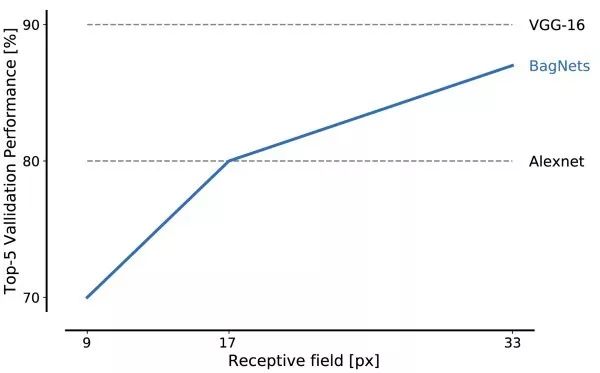
在ImageNet上具有不同貼片尺寸的BagNets的性能。
即使對于非常小的貼片尺寸,BagNet上的BagNets性能也令人印象深刻:尺寸為17 x 17像素的圖像特征足以達(dá)到AlexNet級別的性能,而尺寸為33 x 33像素的特征足以達(dá)到約87%的前5精度。通過更仔細(xì)地放置3 x 3卷積和額外的超參數(shù)調(diào)整,可以實現(xiàn)更高的性能值。
這是我們得到的第一個重要結(jié)果:只需使用一組小圖的特性即可解決ImageNet問題。對象形狀或?qū)ο蟛糠种g的關(guān)系等遠(yuǎn)程空間關(guān)系可以完全忽略,并且不需要解決任務(wù)。
BagNets的一大特色是他們透明的決策。例如,我們現(xiàn)在可以查看哪個圖像特征對于給定的類最具預(yù)測性。

圖像功能具有最多的類證據(jù)。我們展示了正確預(yù)測類(頂行)的功能和預(yù)測錯誤類(底行)的分散注意力的功能
上圖中,最上面的手指圖像被識別成tench(丁鱥guì,是淡水釣魚的主要魚種,也是鱸魚等獵食性魚類的飼料),因為這個類別中的大多數(shù)圖像,都有一個漁民像舉獎杯一樣舉起丁鱥。
同樣,我們還得到一個精確定義的熱圖,顯示圖像的哪些部分促使神經(jīng)網(wǎng)絡(luò)做出某個決定。

來自BagNets的熱圖顯示了確切的圖像部分對決策的貢獻(xiàn)。熱圖不是近似的,而是顯示每個圖像部分的真實貢獻(xiàn)。
ResNet-50與BagNets驚人相似
BagNets表明,基于本地圖像特征和對象類別之間的弱統(tǒng)計相關(guān)性,可以在ImageNet上達(dá)到高精度。
如果這就夠了,為什么像ResNet-50這樣的標(biāo)準(zhǔn)深網(wǎng)會學(xué)到任何根本不同的東西?如果豐富的本地圖像特征足以解決任務(wù),那為什么ResNet-50還需要了解復(fù)雜的大尺度關(guān)系(如對象的形狀)?
為了驗證現(xiàn)代DNN遵循與簡單的特征包網(wǎng)絡(luò)類似的策略的假設(shè),我們在BagNets的以下“簽名”上測試不同的ResNets,DenseNets和VGG:
決策對圖像特征的空間改組是不變的(只能在VGG模型上測試)
不同圖像部分的修改應(yīng)該是獨(dú)立的(就其對總類證據(jù)的影響而言)
標(biāo)準(zhǔn)CNN和BagNets產(chǎn)生的錯誤應(yīng)該類似
標(biāo)準(zhǔn)CNN和BagNets應(yīng)對類似功能敏感
在所有四個實驗中,我們發(fā)現(xiàn)CNN和BagNets之間的行為非常相似。例如,在上一個實驗中,我們展示了BagNets最敏感的那些圖像部分(例如,如果你遮擋那些部分)與CNN最敏感的那些基本相同。
實際上,BagNets的熱圖(靈敏度的空間圖)比由DeepLift(直接為DenseNet-169計算熱圖)等歸因方法生成的熱圖,更好地預(yù)測了DenseNet-169的靈敏度。
當(dāng)然,DNN并不完全類似于特征包模型,但確實顯示出一些偏差。特別是,我們發(fā)現(xiàn)網(wǎng)絡(luò)越深入,功能越來越大,遠(yuǎn)程依賴性也越來越大。
因此,更深層的神經(jīng)網(wǎng)絡(luò)確實改進(jìn)了更簡單的特征包模型,但我認(rèn)為核心分類策略并沒有真正改變。
解釋CNN幾個奇怪的現(xiàn)象
將CNN的決策視為一種BoF策略,可以解釋有關(guān)CNN的幾個奇怪的觀察。首先,它將解釋為什么CNN具有如此強(qiáng)烈的紋理偏差;其次,它可以解釋為什么CNN對圖像部分的混亂如此不敏感;甚至可以解釋一般的對抗性貼紙和對抗性擾動的存在,比如人們在圖像中的任何地方放置誤導(dǎo)信號,并且無論這些信號是否適合圖像的其余部分,CNN仍然可以可靠地接收信號。
我們的成果顯示,CNN利用自然圖像中存在的許多弱統(tǒng)計規(guī)律進(jìn)行分類,并且不會像人類一樣跳向圖像部分的對象級整合。其他任務(wù)和感官方式也是如此。
我們必須認(rèn)真思考如何構(gòu)建架構(gòu)、任務(wù)和學(xué)習(xí)方法,以抵消這種弱統(tǒng)計相關(guān)性的趨勢。一種方式,是將CNN的歸納偏差從小的局部特征改善為更全局的特征;另一種方式,是刪除、或替換網(wǎng)絡(luò)不應(yīng)該依賴的那些特征。
然而,最大的問題之一當(dāng)然是圖像分類本身的任務(wù):如果局部圖像特征足以解決任務(wù),也就不需要去學(xué)習(xí)自然界的真實“物理學(xué)”,這樣我們就必須重構(gòu)任務(wù),推著模型去學(xué)習(xí)對象的物理本質(zhì)。
這樣就很可能需要跳出純粹只通過觀察學(xué)習(xí),獲得輸入和輸出特征之間相關(guān)性的方式,以便允許模型提取因果依賴性。
總結(jié)
總之,我們的結(jié)果表明CNN可能遵循極其簡單的分類策略。科學(xué)家認(rèn)為這個發(fā)現(xiàn)可能在2019繼續(xù)成為關(guān)注的焦點(diǎn),凸顯了我們對深度神經(jīng)網(wǎng)絡(luò)的內(nèi)部運(yùn)作了解甚少。
缺乏理解使我們無法從根本上發(fā)展出更好的模型和架構(gòu),來縮小人與機(jī)器之間的差距。深化我們的理解,將使我們能夠找到彌合這一差距的方法。
這將帶來異常豐厚的回報:當(dāng)我們試圖將CNN偏向物體的更多物理特性時,我們突然達(dá)到了接近人類的噪聲穩(wěn)健性。
我們繼續(xù)期待在2019年,在這一領(lǐng)域上會出現(xiàn)更多令人興奮的結(jié)果,獲得真正了解了真實世界中,物理和因果性質(zhì)的卷積神經(jīng)網(wǎng)絡(luò)。
僅用于學(xué)術(shù)分享,版權(quán)屬于原作者。
猜您喜歡:
等你著陸!【GAN生成對抗網(wǎng)絡(luò)】知識星球!
CVPR 2021 | GAN的說話人驅(qū)動、3D人臉論文匯總
CVPR 2021 | 圖像轉(zhuǎn)換 今如何?幾篇GAN論文
CVPR 2021生成對抗網(wǎng)絡(luò)GAN部分論文匯總
最新最全20篇!基于 StyleGAN 改進(jìn)或應(yīng)用相關(guān)論文
附下載 | 經(jīng)典《Think Python》中文版
附下載 | 最新2020李沐《動手學(xué)深度學(xué)習(xí)》
附下載 | 《可解釋的機(jī)器學(xué)習(xí)》中文版
附下載 |《TensorFlow 2.0 深度學(xué)習(xí)算法實戰(zhàn)》