Author:louwill
From:深度學(xué)習(xí)筆記
在對(duì)卷積的含義有了一定的理解之后,我們便可以對(duì)CNN在最簡(jiǎn)單的計(jì)算機(jī)視覺(jué)任務(wù)圖像分類中的經(jīng)典網(wǎng)絡(luò)進(jìn)行探索。CNN在近幾年的發(fā)展歷程中,從經(jīng)典的LeNet5網(wǎng)絡(luò)到最近號(hào)稱最好的圖像分類網(wǎng)絡(luò)EfficientNet,大量學(xué)者不斷的做出了努力和創(chuàng)新。本講我們就來(lái)梳理經(jīng)典的圖像分類網(wǎng)絡(luò)。
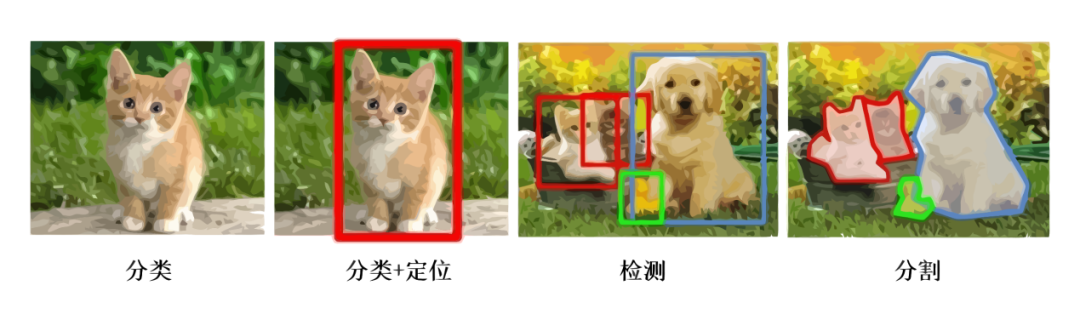
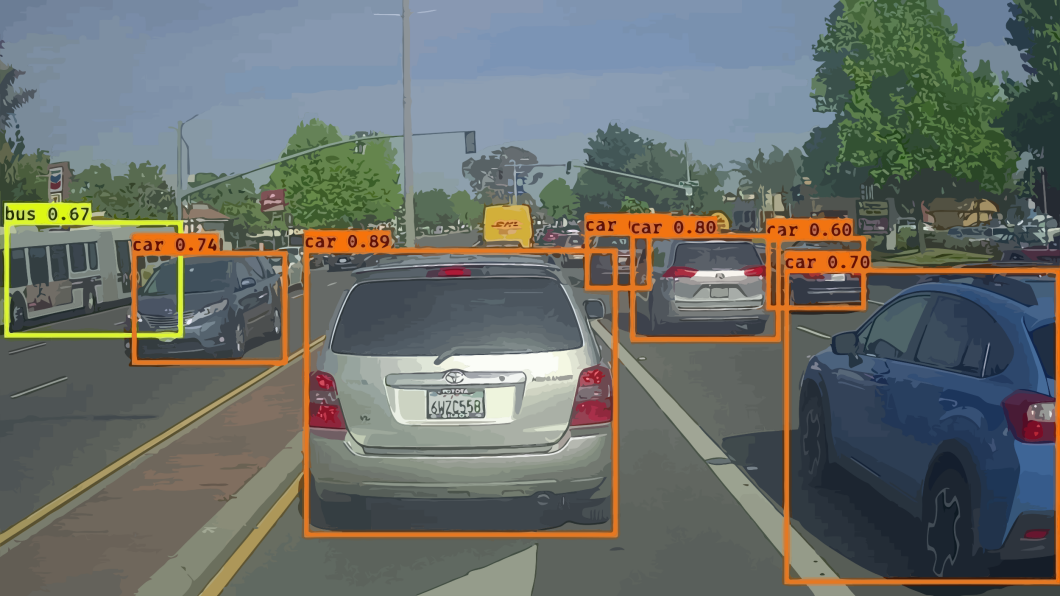
計(jì)算機(jī)視覺(jué)的三大任務(wù)自從神經(jīng)網(wǎng)絡(luò)和深度學(xué)習(xí)方法引入到圖像領(lǐng)域,經(jīng)過(guò)近些年來(lái)的發(fā)展,從一開(kāi)始的圖像分類逐漸延伸到目標(biāo)檢測(cè)和圖像分割領(lǐng)域,深度學(xué)習(xí)也逐漸在計(jì)算機(jī)視覺(jué)領(lǐng)域占據(jù)絕對(duì)的主導(dǎo)地位。如果要想利用深度學(xué)習(xí)技術(shù)開(kāi)啟計(jì)算機(jī)視覺(jué)領(lǐng)域的研究,明確并深刻理解計(jì)算機(jī)視覺(jué)的三大任務(wù)非常關(guān)鍵。計(jì)算機(jī)視覺(jué)三大任務(wù)如圖1所示。圖1 計(jì)算機(jī)視覺(jué)的三大任務(wù)從圖中我們可以簡(jiǎn)單描述計(jì)算機(jī)視覺(jué)三大任務(wù)的要義。圖像分類就是要回答這張圖像是一只貓的問(wèn)題,跟傳統(tǒng)的機(jī)器學(xué)習(xí)任務(wù)并無(wú)區(qū)別,只是我們的輸入由數(shù)值數(shù)據(jù)變成圖片數(shù)據(jù)。本節(jié)的內(nèi)容就是介紹CNN在圖像分類的發(fā)展歷史上出現(xiàn)的一些經(jīng)典的網(wǎng)絡(luò)。而目標(biāo)檢測(cè)則不僅需要回答圖像中有什么,而且還得給出這些物體在圖像中位置問(wèn)題,以圖中為例就是不僅要識(shí)別圖中的貓和狗,還得給出貓和狗的具體定位。所以目標(biāo)檢測(cè)的任務(wù)簡(jiǎn)單而言就是分類+定位。在無(wú)人駕駛的應(yīng)用中,我們的目標(biāo)是訓(xùn)練出一個(gè)具有極高準(zhǔn)確率的物體檢測(cè)器,在工業(yè)產(chǎn)品的瑕疵檢測(cè)中,我們的目標(biāo)是能夠快速準(zhǔn)確的找出產(chǎn)品中的瑕疵區(qū)域,在醫(yī)學(xué)肺部結(jié)節(jié)的檢測(cè)中,我們的任務(wù)是能夠根據(jù)病人肺部影像很好的檢測(cè)出結(jié)節(jié)的位置。圖2是一個(gè)自動(dòng)駕駛場(chǎng)景下對(duì)于各個(gè)目標(biāo)物體的檢測(cè)和識(shí)別。圖2 無(wú)人駕駛的目標(biāo)檢測(cè)示例圖像分割則是需要實(shí)現(xiàn)像素級(jí)的圖像分割,以圖中為例就是要把每個(gè)物體以像素級(jí)的標(biāo)準(zhǔn)分割開(kāi)來(lái),這對(duì)算法的要求則更高。圖3就是一個(gè)定位和實(shí)例分割示例。
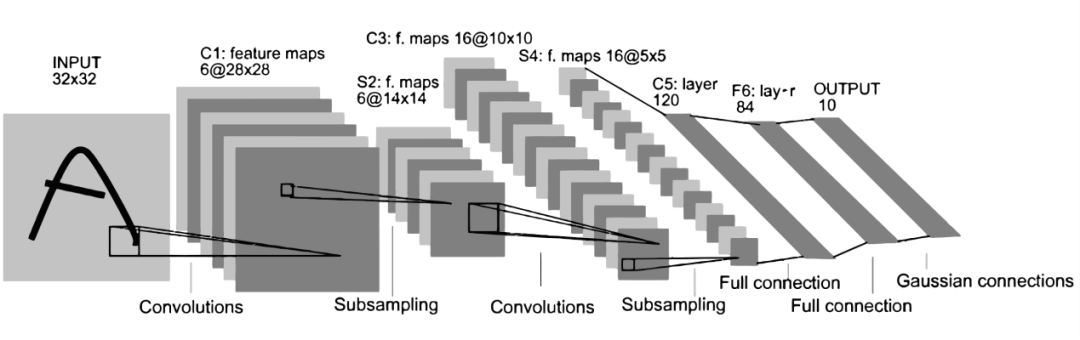
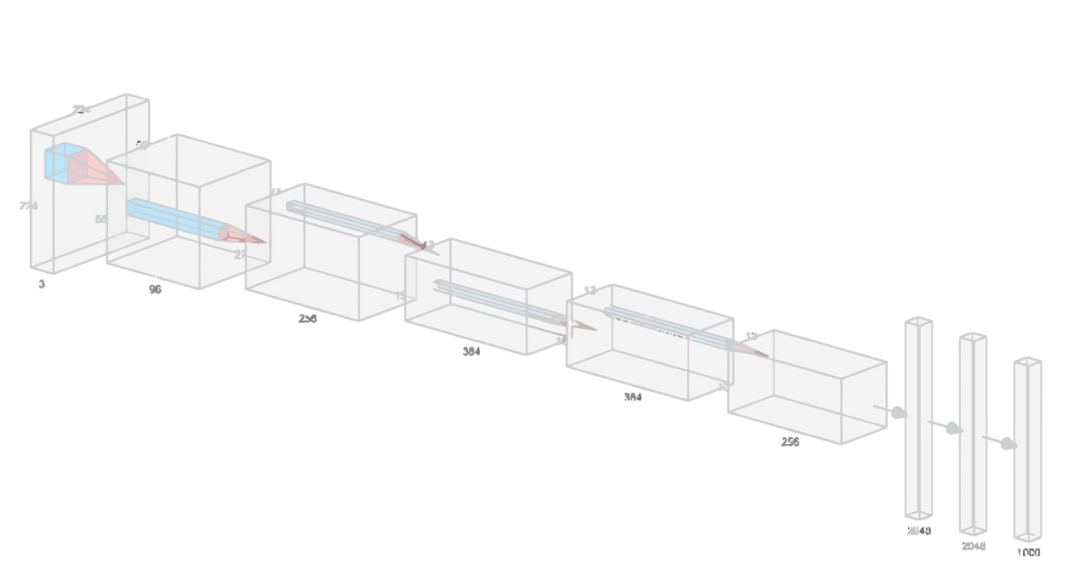
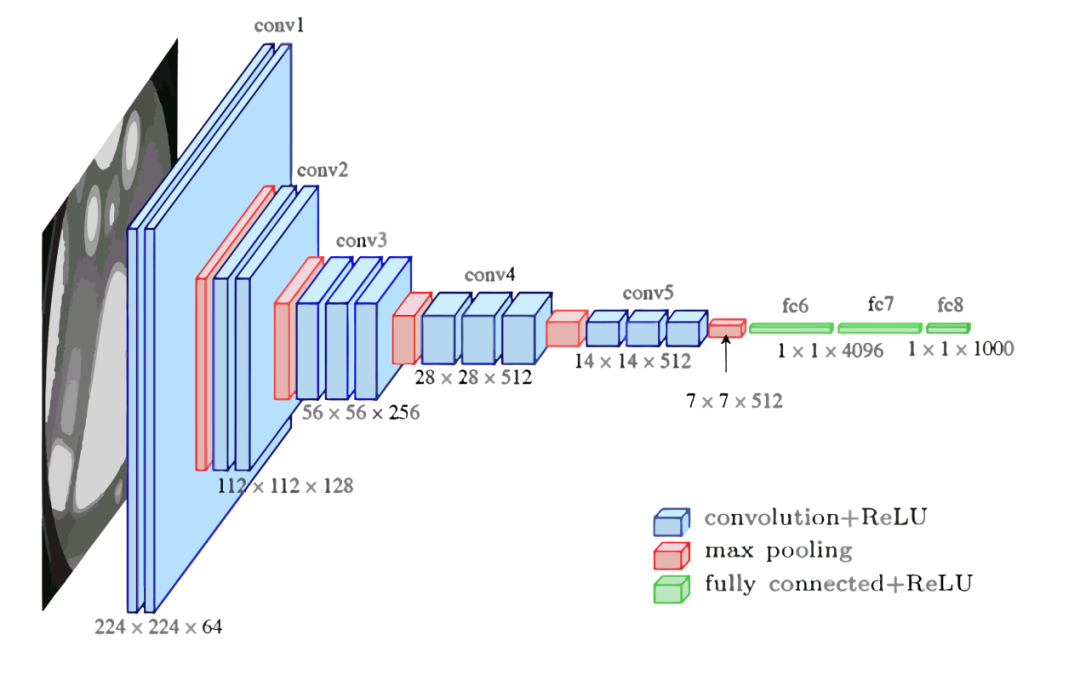
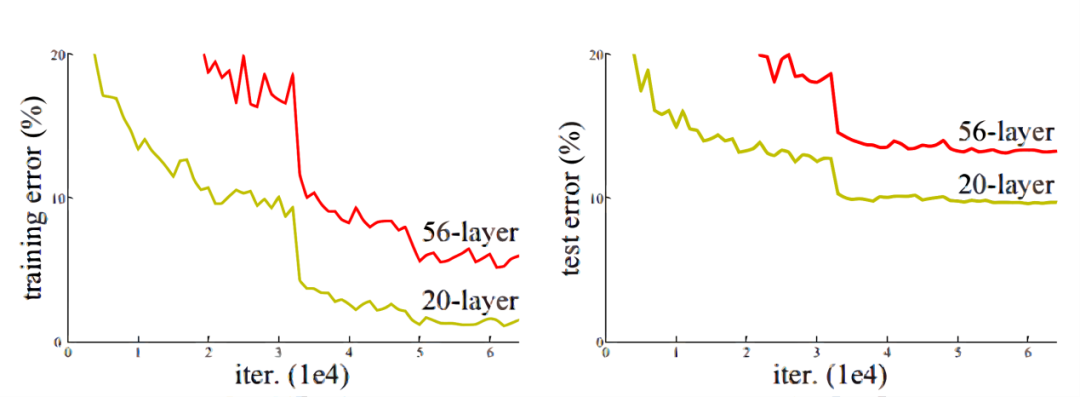
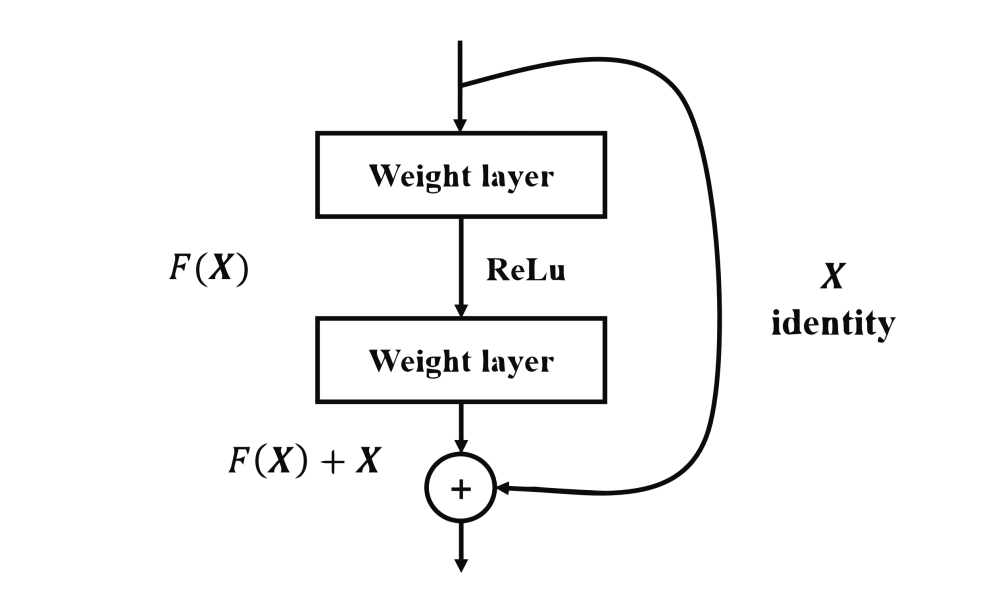
在神經(jīng)網(wǎng)絡(luò)和深度學(xué)習(xí)領(lǐng)域,Yann LeCun可以說(shuō)是元老級(jí)人物。他于1998年在 IEEE 上發(fā)表了一篇42頁(yè)的長(zhǎng)文,文中首次提出卷積-池化-全連接的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),由LeCun提出的七層網(wǎng)絡(luò)命名為L(zhǎng)eNet5,因而也為他贏得了卷積神經(jīng)網(wǎng)絡(luò)之父的美譽(yù)。LeNet5的網(wǎng)絡(luò)結(jié)構(gòu)如圖4所示。LeNet5共有7層,輸入層不計(jì)入層數(shù),每層都有一定的訓(xùn)練參數(shù),其中三個(gè)卷積層的訓(xùn)練參數(shù)較多,每層都有多個(gè)濾波器,也叫特征圖,每個(gè)濾波器都對(duì)上一層的輸出提取不同的像素特征。所以LeNet5的簡(jiǎn)略結(jié)構(gòu)是這樣:輸入-卷積-池化-卷積-池化-卷積(全連接)-全連接-全連接(輸出)。作為標(biāo)準(zhǔn)的卷積網(wǎng)絡(luò)結(jié)構(gòu),LeNet5對(duì)后世的影響深遠(yuǎn),以至于在16年后,谷歌提出 Inception網(wǎng)絡(luò)時(shí)也將其命名為GoogLeNet,以致敬Yann LeCun對(duì)卷積神經(jīng)網(wǎng)絡(luò)發(fā)展的貢獻(xiàn)。然而LeNet5提出后的十幾年里,由于神經(jīng)網(wǎng)絡(luò)的可解釋性以及數(shù)據(jù)和計(jì)算資源等原因,神經(jīng)網(wǎng)絡(luò)的發(fā)展一直處于低谷。故事的轉(zhuǎn)折發(fā)展在2012年,也就是現(xiàn)代意義上的深度學(xué)習(xí)元年。2012年,深度學(xué)習(xí)三巨頭之一Geoffrey Hinton的學(xué)生Alex Krizhevsky率先提出了AlexNet,并在當(dāng)年度的ILSVRC(ImageNet大規(guī)模視覺(jué)挑戰(zhàn)賽)以顯著的優(yōu)勢(shì)獲得當(dāng)屆冠軍,top5的錯(cuò)誤率降至了16.4%,相比于第二名26.2%的錯(cuò)誤率有了極大的提升。這一成績(jī)引起了學(xué)界和業(yè)界的極大關(guān)注,計(jì)算機(jī)視覺(jué)也開(kāi)始逐漸進(jìn)入深度學(xué)習(xí)主導(dǎo)的時(shí)代。AlexNet繼承了LeCun的LeNet5思想,將卷積神經(jīng)網(wǎng)絡(luò)的發(fā)展到很寬很深的網(wǎng)絡(luò)當(dāng)中,相較于LeNet5的六萬(wàn)個(gè)參數(shù),AlexNet包含了6億3千萬(wàn)條連接,6000萬(wàn)個(gè)參數(shù)和65萬(wàn)個(gè)神經(jīng)元,其網(wǎng)絡(luò)結(jié)構(gòu)包括5層卷積,其中第一、第二和第五層卷積后面連接了最大池化層,然后是3個(gè)全連接層。AlexNet的網(wǎng)絡(luò)架構(gòu)圖5所示。AlexNet不算池化層總共有8層,前5層為卷積層,其中第一、第二和第五層卷積都包含了一個(gè)最大池化層,后三層為全連接層。所以 AlexNet 的簡(jiǎn)略結(jié)構(gòu)如下:輸入-卷積-池化-卷積-池化-卷積-卷積-卷積-池化-全連接-全連接-全連接-輸出。AlexNet 就像是打開(kāi)了深度學(xué)習(xí)的潘多拉魔盒,此后不斷有新的網(wǎng)絡(luò)被提出,這些都極大的繁榮了深度學(xué)習(xí)的理論和實(shí)踐,致使深度學(xué)習(xí)逐漸發(fā)展興盛起來(lái)。在2013年的ILSVRC 大賽中,Zeiler和Fergus在AlexNet的基礎(chǔ)上對(duì)其進(jìn)行了微調(diào)提出了ZFNet,使得top5的錯(cuò)誤率下降到11.2%,奪得當(dāng)年的第一,ZFNet和AlexNet的結(jié)構(gòu)很相似,這里就不再單獨(dú)細(xì)述。到了2014年,不斷的積累實(shí)踐和日益強(qiáng)大的計(jì)算能力使得研究人員敢于將神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu)推向更深層。在2014年提出的 VGG中,首次將卷積網(wǎng)絡(luò)結(jié)構(gòu)拓展至16和19層,也就是著名的VGG16 和VGG19。相較于此前的LeNet5和AlexNet的5*5卷積和11*11卷積,VGG結(jié)構(gòu)中大量使用3*3的卷積濾波器和2*2的池化濾波器。VGG的網(wǎng)絡(luò)雖然開(kāi)始加深但其結(jié)構(gòu)并不復(fù)雜,但作者的實(shí)踐卻證明了卷積網(wǎng)絡(luò)深度的重要性。深度卷積網(wǎng)絡(luò)能夠提取圖像低層次、中層次和高層次的特征,因而網(wǎng)絡(luò)結(jié)構(gòu)需要的一定的深度來(lái)提取圖像不同層次的特征。VGG16的結(jié)構(gòu)如圖6所示。VGG 的網(wǎng)絡(luò)結(jié)構(gòu)非常規(guī)整,2-2-3-3-3的卷積結(jié)構(gòu)也非常利于編程實(shí)現(xiàn)。卷積層的濾波器數(shù)量的變化也存在明顯的規(guī)律,由64到128再到256和512,每一次卷積都是像素呈規(guī)律的減少和通道數(shù)呈規(guī)律的增加。VGG16在當(dāng)年的ILSVRC以7.32%的top5錯(cuò)誤率取得了當(dāng)年大賽的第二名。這么厲害的網(wǎng)絡(luò)為什么是第二名?因?yàn)楫?dāng)年有比VGG更厲害的網(wǎng)絡(luò),也就是前文提到的致敬LeNet5的GoogLeNet。GoogLeNet在借鑒此前1*1卷積思想的基礎(chǔ)上,通過(guò)濾波器組合構(gòu)建Inception模塊,使得網(wǎng)絡(luò)可以走向更深且表達(dá)能力更強(qiáng)。從2014 年獲得當(dāng)屆ILSVRC冠軍的Inception v1到現(xiàn)在,Inception網(wǎng)絡(luò)已經(jīng)更新到v4了,Inception真正實(shí)現(xiàn)了Go Deeper的目的。通常在構(gòu)建卷積結(jié)構(gòu)時(shí),我們需要考慮是使用1*1卷積、3*3卷積還是5*5卷積以及是否需要添加池化操作。而GoogLeNet的Inception模塊就是幫你決定采用什么樣的卷積結(jié)構(gòu)。簡(jiǎn)單而言,Inception模塊就是分別采用了1*1卷積、3*3卷積和5*5卷積構(gòu)建了一個(gè)卷積組合然后輸出也是一個(gè)卷積組合后的輸出。對(duì)于28*28*192的像素輸入,我們分別采用1*1卷積、3*3卷積和5*5卷積以及最大池化四個(gè)濾波器對(duì)輸入進(jìn)行操作,將對(duì)應(yīng)的輸出進(jìn)行堆積,即32+32+128+64=256,最后的輸出大小為 28*28*256。所以總的而言,Inception網(wǎng)絡(luò)的基本思想就是不需要人為的去決定使用哪個(gè)卷積結(jié)構(gòu)或者池化,而是由網(wǎng)絡(luò)自己決定這些參數(shù),決定有哪些濾波器組合。這是Inception的通道組合功能。Inception另一個(gè)關(guān)鍵在于大量使用1*1卷積來(lái)生成瓶頸層(Bottleneck Layer)來(lái)達(dá)到降維的目的,在不降低網(wǎng)絡(luò)性能的情況下大大縮減了計(jì)算量,可謂是Inception網(wǎng)絡(luò)的點(diǎn)睛之筆。一個(gè)基于1*1卷積的Inception模塊如圖7所示。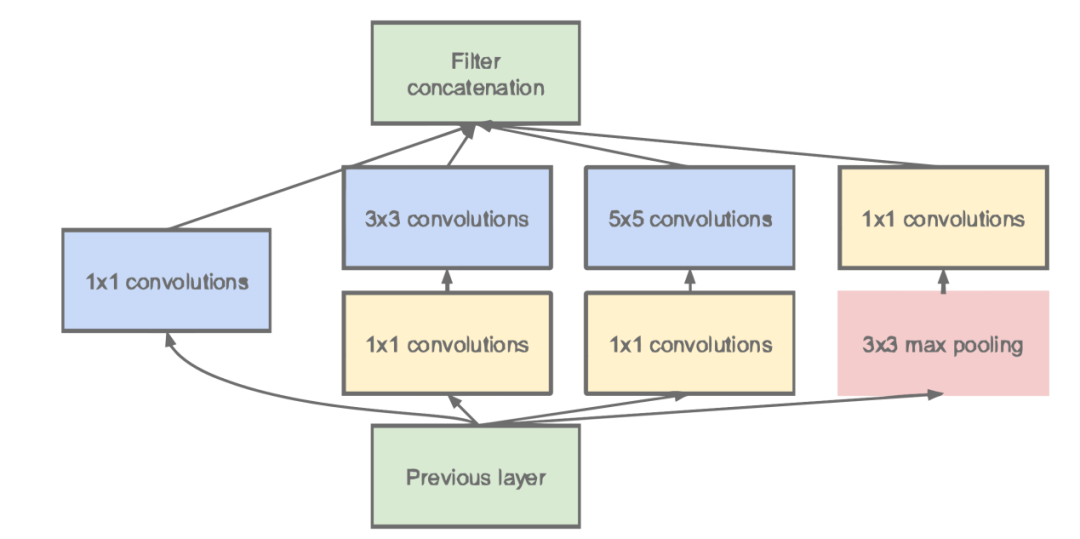 構(gòu)建好Inception模塊后,將多個(gè)類似結(jié)構(gòu)Inception模塊組合起來(lái)便是一個(gè)Inception網(wǎng)絡(luò),這是最初的Inception v1版本。Inception v2對(duì)網(wǎng)絡(luò)加入了BN(Batch Normalization)層,進(jìn)一步提高了網(wǎng)絡(luò)的性能。Inception v3在v2的基礎(chǔ)上提出了卷積分解的方法,比如將3*3卷積分解為1*3和3*1,這樣做的好處是既可以提高計(jì)算速度又可以將一個(gè)卷積拆分為兩個(gè),從而加深網(wǎng)絡(luò)深度。Inception v4最大的特點(diǎn)是在v3的基礎(chǔ)上加入了殘差連接,形成了Inception-ResNet v1和Inception-ResNet v2兩個(gè)優(yōu)秀的網(wǎng)絡(luò)結(jié)構(gòu)。Inception v1在當(dāng)年度激烈的ILSVRC大賽中以6.67%的top5錯(cuò)誤率榮膺第一名,讓同樣出色的VGG只能屈居第二,此后每一版本的Inception網(wǎng)絡(luò)在ImageNet任務(wù)上均能達(dá)到SOTA(State of the Art)的水準(zhǔn)。通過(guò)VGG和GoogLeNet 中,我們了解到卷積神經(jīng)網(wǎng)絡(luò)也可以進(jìn)行到很深層,VGG16 和VGG19就是證明。但卷積網(wǎng)絡(luò)變得更深呢?當(dāng)然是可以的。深度神經(jīng)網(wǎng)絡(luò)能夠從提取圖像各個(gè)層級(jí)的特征,使得圖像識(shí)別的準(zhǔn)確率越來(lái)越高。但在2014年前后,將卷積網(wǎng)絡(luò)變深且取得不錯(cuò)的訓(xùn)練效果并不是一件容易的事。深度卷積網(wǎng)絡(luò)一開(kāi)始面臨的最主要的問(wèn)題是梯度消失和梯度爆炸。那什么是梯度消失和梯度爆炸呢?所謂梯度消失,就是在深層神經(jīng)網(wǎng)絡(luò)的訓(xùn)練過(guò)程中,計(jì)算得到的梯度越來(lái)越小,使得權(quán)值得不到更新的情形,這樣算法也就失效了。而梯度爆炸則是相反的情況,是指在神經(jīng)網(wǎng)絡(luò)訓(xùn)練過(guò)程中梯度變得越來(lái)越大,權(quán)值得到瘋狂更新的情形,這樣算法得不到收斂,模型也就失效了。當(dāng)然,通過(guò)設(shè)置ReLu和歸一化激活函數(shù)層等手段使得我們很好的解決這些問(wèn)題。但當(dāng)我們將網(wǎng)絡(luò)層數(shù)加到更深時(shí)卻發(fā)現(xiàn)訓(xùn)練的準(zhǔn)確率在逐漸降低。這種并不是由過(guò)擬合造成的神經(jīng)網(wǎng)絡(luò)訓(xùn)練數(shù)據(jù)識(shí)別準(zhǔn)確率降低的現(xiàn)象我們稱之為退化(Degradation)。圖6.8是兩個(gè)網(wǎng)絡(luò)訓(xùn)練和測(cè)試誤差情況。我們可以看到56層的普通卷積網(wǎng)絡(luò)不管是在訓(xùn)練集還是測(cè)試集上的訓(xùn)練誤差都要高于20層的卷積網(wǎng)絡(luò),這是個(gè)典型的退化現(xiàn)象。退化問(wèn)題不解決,深度學(xué)習(xí)就無(wú)法go deeper. 于是何愷明等一眾學(xué)者就提出了殘差網(wǎng)絡(luò)ResNet。要理解殘差網(wǎng)絡(luò),就必須理解殘差塊(residual block)這個(gè)結(jié)構(gòu),因?yàn)闅埐顗K是殘差網(wǎng)絡(luò)的基本組成部分。回憶一下我們之前學(xué)到的各種卷積網(wǎng)絡(luò)結(jié)構(gòu)(LeNet5/AlexNet/VGG),通常結(jié)構(gòu)就是卷積池化再卷積池化,中間的卷積池化操作可以很多層。類似這樣的網(wǎng)絡(luò)結(jié)構(gòu)何愷明在論文中將其稱為普通網(wǎng)絡(luò)(Plain Network),何凱明認(rèn)為普通網(wǎng)絡(luò)解決不了退化問(wèn)題,我們需要在網(wǎng)絡(luò)結(jié)構(gòu)上做出創(chuàng)新。何愷明給出的創(chuàng)新在于給網(wǎng)絡(luò)之間添加一個(gè)捷徑(shortcuts)或者也叫跳躍連接(skip connection),可以讓捷徑之間的網(wǎng)絡(luò)能夠?qū)W習(xí)一個(gè)恒等函數(shù),使得在加深網(wǎng)絡(luò)的情形下訓(xùn)練效果至少不會(huì)變差。殘差塊的基本結(jié)構(gòu)如圖9所示。殘差塊是一個(gè)兩層的網(wǎng)絡(luò)結(jié)構(gòu),輸入X經(jīng)過(guò)兩層的加權(quán)和激活得到F(X)的輸出,這是典型的普通卷積網(wǎng)絡(luò)結(jié)構(gòu)。但殘差塊的區(qū)別在于添加了一個(gè)從輸入X到兩層網(wǎng)絡(luò)輸出單元的shortcut,這使得輸入節(jié)點(diǎn)的信息單元直接獲得了與輸出節(jié)點(diǎn)的信息單元通信的能力 ,這時(shí)候在進(jìn)行ReLu激活之前的輸出就不再是F(X)了,而是F(X)+X。當(dāng)很多個(gè)具備類似結(jié)構(gòu)的這樣的殘差塊組建到一起時(shí),就構(gòu)成了殘差網(wǎng)絡(luò)。殘差網(wǎng)絡(luò)能夠順利訓(xùn)練很深層的卷積網(wǎng)絡(luò),能夠很好的解決網(wǎng)絡(luò)的退化問(wèn)題。或許你可能會(huì)問(wèn)憑什么加了一條從輸入到輸出的捷徑網(wǎng)絡(luò)就能防止退化訓(xùn)練更深層的卷積網(wǎng)絡(luò)?或是說(shuō)殘差網(wǎng)絡(luò)為什么能有效?我們將上述殘差塊的兩層輸入輸出符號(hào)改為和 ,相應(yīng)的就有:? ? ? ? ? ? ? ? ? ? ?
構(gòu)建好Inception模塊后,將多個(gè)類似結(jié)構(gòu)Inception模塊組合起來(lái)便是一個(gè)Inception網(wǎng)絡(luò),這是最初的Inception v1版本。Inception v2對(duì)網(wǎng)絡(luò)加入了BN(Batch Normalization)層,進(jìn)一步提高了網(wǎng)絡(luò)的性能。Inception v3在v2的基礎(chǔ)上提出了卷積分解的方法,比如將3*3卷積分解為1*3和3*1,這樣做的好處是既可以提高計(jì)算速度又可以將一個(gè)卷積拆分為兩個(gè),從而加深網(wǎng)絡(luò)深度。Inception v4最大的特點(diǎn)是在v3的基礎(chǔ)上加入了殘差連接,形成了Inception-ResNet v1和Inception-ResNet v2兩個(gè)優(yōu)秀的網(wǎng)絡(luò)結(jié)構(gòu)。Inception v1在當(dāng)年度激烈的ILSVRC大賽中以6.67%的top5錯(cuò)誤率榮膺第一名,讓同樣出色的VGG只能屈居第二,此后每一版本的Inception網(wǎng)絡(luò)在ImageNet任務(wù)上均能達(dá)到SOTA(State of the Art)的水準(zhǔn)。通過(guò)VGG和GoogLeNet 中,我們了解到卷積神經(jīng)網(wǎng)絡(luò)也可以進(jìn)行到很深層,VGG16 和VGG19就是證明。但卷積網(wǎng)絡(luò)變得更深呢?當(dāng)然是可以的。深度神經(jīng)網(wǎng)絡(luò)能夠從提取圖像各個(gè)層級(jí)的特征,使得圖像識(shí)別的準(zhǔn)確率越來(lái)越高。但在2014年前后,將卷積網(wǎng)絡(luò)變深且取得不錯(cuò)的訓(xùn)練效果并不是一件容易的事。深度卷積網(wǎng)絡(luò)一開(kāi)始面臨的最主要的問(wèn)題是梯度消失和梯度爆炸。那什么是梯度消失和梯度爆炸呢?所謂梯度消失,就是在深層神經(jīng)網(wǎng)絡(luò)的訓(xùn)練過(guò)程中,計(jì)算得到的梯度越來(lái)越小,使得權(quán)值得不到更新的情形,這樣算法也就失效了。而梯度爆炸則是相反的情況,是指在神經(jīng)網(wǎng)絡(luò)訓(xùn)練過(guò)程中梯度變得越來(lái)越大,權(quán)值得到瘋狂更新的情形,這樣算法得不到收斂,模型也就失效了。當(dāng)然,通過(guò)設(shè)置ReLu和歸一化激活函數(shù)層等手段使得我們很好的解決這些問(wèn)題。但當(dāng)我們將網(wǎng)絡(luò)層數(shù)加到更深時(shí)卻發(fā)現(xiàn)訓(xùn)練的準(zhǔn)確率在逐漸降低。這種并不是由過(guò)擬合造成的神經(jīng)網(wǎng)絡(luò)訓(xùn)練數(shù)據(jù)識(shí)別準(zhǔn)確率降低的現(xiàn)象我們稱之為退化(Degradation)。圖6.8是兩個(gè)網(wǎng)絡(luò)訓(xùn)練和測(cè)試誤差情況。我們可以看到56層的普通卷積網(wǎng)絡(luò)不管是在訓(xùn)練集還是測(cè)試集上的訓(xùn)練誤差都要高于20層的卷積網(wǎng)絡(luò),這是個(gè)典型的退化現(xiàn)象。退化問(wèn)題不解決,深度學(xué)習(xí)就無(wú)法go deeper. 于是何愷明等一眾學(xué)者就提出了殘差網(wǎng)絡(luò)ResNet。要理解殘差網(wǎng)絡(luò),就必須理解殘差塊(residual block)這個(gè)結(jié)構(gòu),因?yàn)闅埐顗K是殘差網(wǎng)絡(luò)的基本組成部分。回憶一下我們之前學(xué)到的各種卷積網(wǎng)絡(luò)結(jié)構(gòu)(LeNet5/AlexNet/VGG),通常結(jié)構(gòu)就是卷積池化再卷積池化,中間的卷積池化操作可以很多層。類似這樣的網(wǎng)絡(luò)結(jié)構(gòu)何愷明在論文中將其稱為普通網(wǎng)絡(luò)(Plain Network),何凱明認(rèn)為普通網(wǎng)絡(luò)解決不了退化問(wèn)題,我們需要在網(wǎng)絡(luò)結(jié)構(gòu)上做出創(chuàng)新。何愷明給出的創(chuàng)新在于給網(wǎng)絡(luò)之間添加一個(gè)捷徑(shortcuts)或者也叫跳躍連接(skip connection),可以讓捷徑之間的網(wǎng)絡(luò)能夠?qū)W習(xí)一個(gè)恒等函數(shù),使得在加深網(wǎng)絡(luò)的情形下訓(xùn)練效果至少不會(huì)變差。殘差塊的基本結(jié)構(gòu)如圖9所示。殘差塊是一個(gè)兩層的網(wǎng)絡(luò)結(jié)構(gòu),輸入X經(jīng)過(guò)兩層的加權(quán)和激活得到F(X)的輸出,這是典型的普通卷積網(wǎng)絡(luò)結(jié)構(gòu)。但殘差塊的區(qū)別在于添加了一個(gè)從輸入X到兩層網(wǎng)絡(luò)輸出單元的shortcut,這使得輸入節(jié)點(diǎn)的信息單元直接獲得了與輸出節(jié)點(diǎn)的信息單元通信的能力 ,這時(shí)候在進(jìn)行ReLu激活之前的輸出就不再是F(X)了,而是F(X)+X。當(dāng)很多個(gè)具備類似結(jié)構(gòu)的這樣的殘差塊組建到一起時(shí),就構(gòu)成了殘差網(wǎng)絡(luò)。殘差網(wǎng)絡(luò)能夠順利訓(xùn)練很深層的卷積網(wǎng)絡(luò),能夠很好的解決網(wǎng)絡(luò)的退化問(wèn)題。或許你可能會(huì)問(wèn)憑什么加了一條從輸入到輸出的捷徑網(wǎng)絡(luò)就能防止退化訓(xùn)練更深層的卷積網(wǎng)絡(luò)?或是說(shuō)殘差網(wǎng)絡(luò)為什么能有效?我們將上述殘差塊的兩層輸入輸出符號(hào)改為和 ,相應(yīng)的就有:? ? ? ? ? ? ? ? ? ? ?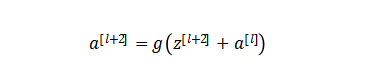
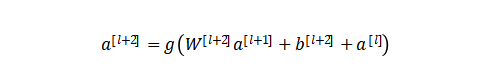 ? ? ? ? ? ? ? ?? ? 在網(wǎng)絡(luò)中加入L2正則化進(jìn)行權(quán)值衰減或者其他情形下,l+2層的權(quán)值是很容易衰減為零的,假設(shè)偏置同樣為零的情形下就有等號(hào)成立。深度學(xué)習(xí)的試驗(yàn)表明學(xué)習(xí)這個(gè)恒等式并不困難,這就意味著,在擁有跳躍連接的普通網(wǎng)絡(luò)即使多加幾層,其效果也并不遜色于加深之前的網(wǎng)絡(luò)效果。當(dāng)然,我們的目標(biāo)不是保持網(wǎng)絡(luò)不退化,而是需要提升網(wǎng)絡(luò)表現(xiàn),當(dāng)隱藏層能夠?qū)W到一些有用的信息時(shí),殘差網(wǎng)絡(luò)的效果就會(huì)提升。所以,殘差網(wǎng)絡(luò)之所以有效是在于它能夠很好的學(xué)習(xí)上述那個(gè)恒等式,而普通網(wǎng)絡(luò)學(xué)習(xí)恒等式都很困難,殘差網(wǎng)絡(luò)在兩者相較中自然勝出。
? ? ? ? ? ? ? ?? ? 在網(wǎng)絡(luò)中加入L2正則化進(jìn)行權(quán)值衰減或者其他情形下,l+2層的權(quán)值是很容易衰減為零的,假設(shè)偏置同樣為零的情形下就有等號(hào)成立。深度學(xué)習(xí)的試驗(yàn)表明學(xué)習(xí)這個(gè)恒等式并不困難,這就意味著,在擁有跳躍連接的普通網(wǎng)絡(luò)即使多加幾層,其效果也并不遜色于加深之前的網(wǎng)絡(luò)效果。當(dāng)然,我們的目標(biāo)不是保持網(wǎng)絡(luò)不退化,而是需要提升網(wǎng)絡(luò)表現(xiàn),當(dāng)隱藏層能夠?qū)W到一些有用的信息時(shí),殘差網(wǎng)絡(luò)的效果就會(huì)提升。所以,殘差網(wǎng)絡(luò)之所以有效是在于它能夠很好的學(xué)習(xí)上述那個(gè)恒等式,而普通網(wǎng)絡(luò)學(xué)習(xí)恒等式都很困難,殘差網(wǎng)絡(luò)在兩者相較中自然勝出。
當(dāng)多個(gè)殘差塊組合到一起便形成了殘差網(wǎng)絡(luò)ResNet。ResNet在2015年ILSVRC大賽上 top5單模型的錯(cuò)誤率縮小到了3.57%,在其他數(shù)據(jù)集上也有著驚人的表現(xiàn),結(jié)果當(dāng)然就是收割各類獎(jiǎng)項(xiàng)了。以上幾個(gè)網(wǎng)絡(luò)除了早期的LeNet5之外都是在ILSVRC大賽的助力下不斷向前發(fā)展的,從這一點(diǎn)來(lái)看,ILSVRC大賽和ImageNet數(shù)據(jù)集對(duì)深度學(xué)習(xí)的發(fā)展具有重大意義。ILSVRC大賽于2017年正式停辦,但在開(kāi)辦的6年來(lái)極大地促進(jìn)了深度學(xué)習(xí)和計(jì)算機(jī)視覺(jué)的發(fā)展。ImageNet歷年top方案如表1所示。 | | | |
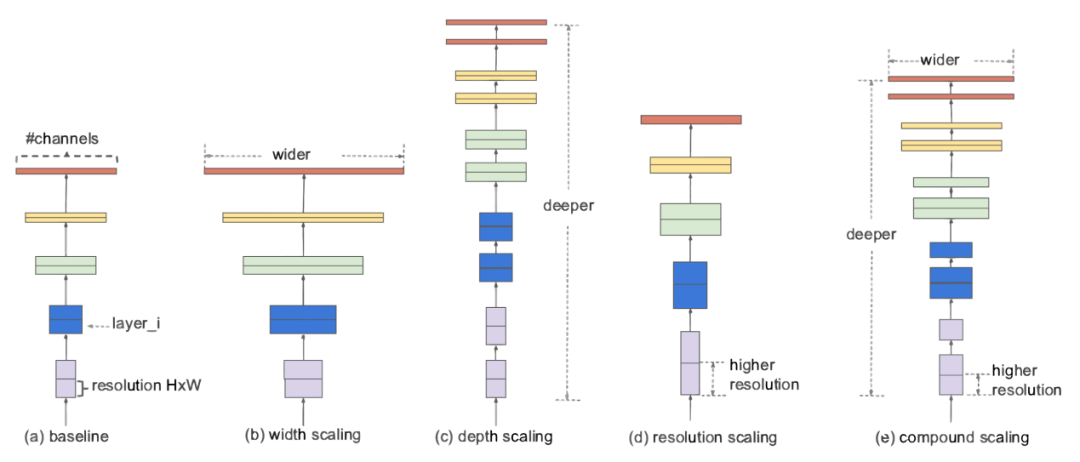
| | | ImageNet Classification with Deep Convolutional Neural Networks |
| | | Visualizing and understanding convolutional networks |
| | | Going Deeper with Convolutions |
| | | Very deep convolutional networks for large-scale image recognition |
| | | Deep Residual Learning for Image Recognition |
| | | Aggregated Residual Transformations for Deep Neural Networks |
| | | Squeeze-and-Excitation Networks |
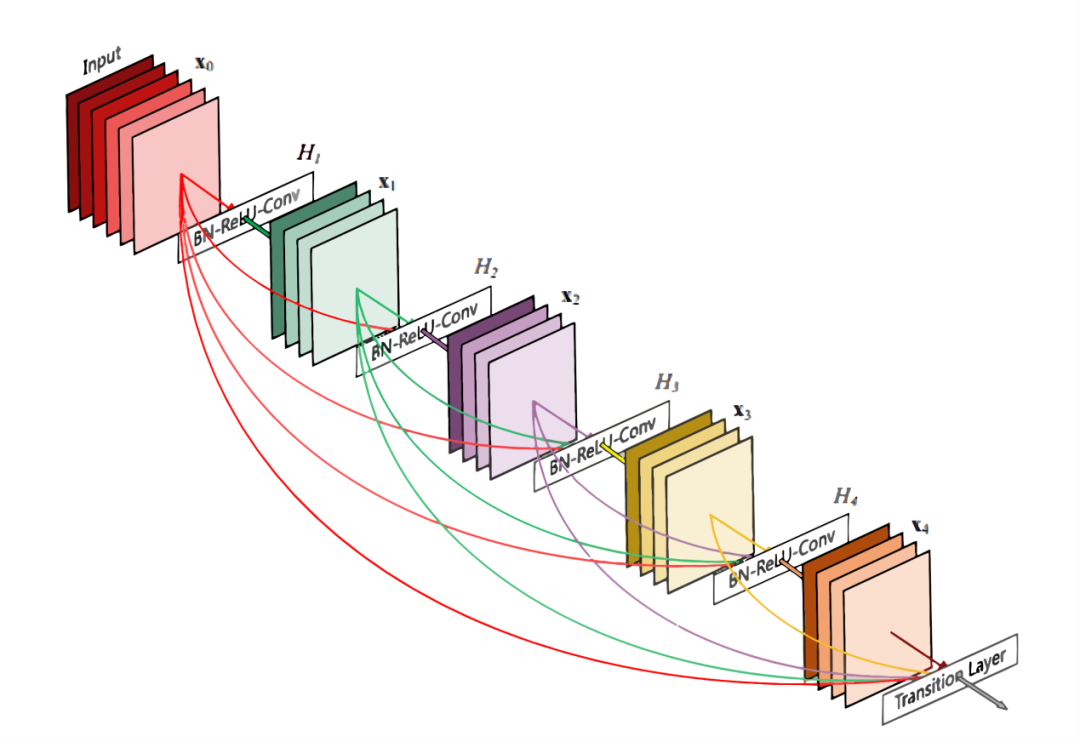
由表1可以看到,2017年的冠軍方案SENet的錯(cuò)誤率已經(jīng)降至2.25%,這個(gè)精度已經(jīng)超過(guò)人類視覺(jué)水平,I LSVRC大賽也在這一年停辦,但深度學(xué)習(xí)和計(jì)算機(jī)視覺(jué)的研究仍然繼續(xù)向前發(fā)展。2017年,劉壯等人在ResNet的基礎(chǔ)上提出了DenseNet網(wǎng)絡(luò),作為2017年CVPR的最佳論文,作者通過(guò)大量使用跨層的密集連接,強(qiáng)化了卷積過(guò)程中特征重要性,另外也縮減了模型參數(shù),進(jìn)一步提高了深度卷積網(wǎng)絡(luò)的性能。DenseNet密集連接結(jié)構(gòu)如圖10所示。除了以上各種優(yōu)秀的深度卷積網(wǎng)絡(luò)之外,近幾年各種網(wǎng)絡(luò)都在存儲(chǔ)和速度問(wèn)題上不斷做出改進(jìn)和創(chuàng)新。近兩年提出的SqueezeNet、MobileNet、ShuffleNet、NASNet和Xception等深度網(wǎng)絡(luò)正是致力于讓CNN走出實(shí)驗(yàn)室達(dá)到工業(yè)應(yīng)用的目的而提出的網(wǎng)絡(luò)結(jié)構(gòu)。作為本節(jié)的結(jié)尾,我們想重點(diǎn)提一下去年5月份谷歌大腦發(fā)布的號(hào)稱目前最好的CNN分類網(wǎng)絡(luò)的EfficientNet。EfficientNet在吸取此前的各種網(wǎng)絡(luò)優(yōu)化經(jīng)驗(yàn)的基礎(chǔ)上提出了更加泛化的解決方法。什么叫更加泛化的方法呢?作者認(rèn)為,我們之前關(guān)于網(wǎng)絡(luò)性能優(yōu)化要么是從網(wǎng)絡(luò)深度、要么是從網(wǎng)絡(luò)寬度(通道數(shù))、要么是從輸入圖像的分辨率單獨(dú)來(lái)進(jìn)行模型縮放調(diào)優(yōu)的。但實(shí)際上網(wǎng)絡(luò)性能在這三個(gè)維度上并不是相互獨(dú)立的。EfficientNet的核心在于提出了一種混合的模型縮放方法(Compound Model Scaling)算法來(lái)綜合優(yōu)化網(wǎng)絡(luò)深度、寬度和分辨率,通過(guò)這種思想設(shè)計(jì)出來(lái)的網(wǎng)絡(luò)能夠在達(dá)到當(dāng)前最優(yōu)精度的同時(shí),大大減少參數(shù)數(shù)量和提高計(jì)算速度。Compound Model Scaling的設(shè)計(jì)思想如圖11所示。作為谷歌這樣超級(jí)巨頭,自然有大量的數(shù)據(jù)資源和計(jì)算資源來(lái)做出這樣更加泛化的研究。對(duì)于普通人而言,很難有這樣的算力來(lái)進(jìn)行成百上千次的大規(guī)模調(diào)參。但EfficientNet也提高了我們普通人做深度學(xué)習(xí)的baseline,站在巨人的肩膀上,一直都是件值得興奮的事情。LeCun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[C]//Advances in neural information processing systems. 2012: 1097-1105.Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J]. arXiv preprint arXiv:1409.1556, 2014.Szegedy C, Liu W, Jia Y, et al. Going deeper with convolutions[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 1-9.He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.Huang G, Liu Z, Van Der Maaten L, et al. Densely connected convolutional networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 4700-4708.Tan M, Le Q V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks[J]. arXiv preprint arXiv:1905.11946, 2019.