
基于 Python 的 Stacking 集成機器學習實踐

堆疊是一種集成的機器學習算法,可學習如何最佳地組合來自多個性能良好的機器學習模型的預測。 scikit-learn庫提供了Python中堆棧集成的標準實現(xiàn)。 如何使用堆疊集成進行回歸和分類預測建模。
堆疊概括 堆疊Scikit-Learn API 堆疊分類 堆疊回歸
與Bagging不同,在堆疊中,模型通常是不同的(例如,并非所有決策樹)并且適合于同一數(shù)據(jù)集(例如,而不是訓練數(shù)據(jù)集的樣本)。 與Boosting不同,在堆疊中,使用單個模型來學習如何最佳地組合來自貢獻模型的預測(例如,而不是校正先前模型的預測的一系列模型)。
0級模型(基本模型):模型適合訓練數(shù)據(jù),并會編譯其預測。 1級模型(元模型):學習如何最好地組合基礎模型的預測的模型。
回歸元模型:線性回歸。 分類元模型:邏輯回歸。
#?check?scikit-learn?version
import?sklearn
print(sklearn.__version__)
0.22.1
models?=?[('lr',LogisticRegression()),('svm',SVC())
stacking?=?StackingClassifier(estimators=models)
models?=?[('lr',LogisticRegression()),('svm',make_pipeline(StandardScaler(),SVC()))
stacking?=?StackingClassifier(estimators=models)
make_classification()函數(shù)創(chuàng)建具有1,000個示例和20個輸入功能的綜合二進制分類問題。下面列出了完整的示例。#?test?classification?dataset
from?sklearn.datasets?import?make_classification
#?define?dataset
X,?y?=?make_classification(n_samples=1000,?n_features=20,?n_informative=15,?n_redundant=5,?random_state=1)
#?summarize?the?dataset
print(X.shape,?y.shape)
(1000,?20)?(1000,)
邏輯回歸。 k最近鄰居。 決策樹。 支持向量機。 天真貝葉斯。
get_models()創(chuàng)建我們要評估的模型。#?get?a?list?of?models?to?evaluate
def?get_models():
?models?=?dict()
?models['lr']?=?LogisticRegression()
?models['knn']?=?KNeighborsClassifier()
?models['cart']?=?DecisionTreeClassifier()
?models['svm']?=?SVC()
?models['bayes']?=?GaussianNB()
?return?models
valuate_model()函數(shù)采用一個模型實例,并從分層的10倍交叉驗證的三個重復中返回分數(shù)列表。#?evaluate?a?given?model?using?cross-validation
def?evaluate_model(model,?X,?y):
?cv?=?RepeatedStratifiedKFold(n_splits=10,?n_repeats=3,?random_state=1)
?scores?=?cross_val_score(model,?X,?y,?scoring='accuracy',?cv=cv,?n_jobs=-1,?error_score='raise')
?return?scores
#?compare?standalone?models?for?binary?classification
from?numpy?import?mean
from?numpy?import?std
from?sklearn.datasets?import?make_classification
from?sklearn.model_selection?import?cross_val_score
from?sklearn.model_selection?import?RepeatedStratifiedKFold
from?sklearn.linear_model?import?LogisticRegression
from?sklearn.neighbors?import?KNeighborsClassifier
from?sklearn.tree?import?DecisionTreeClassifier
from?sklearn.svm?import?SVC
from?sklearn.naive_bayes?import?GaussianNB
from?matplotlib?import?pyplot
?
#?get?the?dataset
def?get_dataset():
?X,?y?=?make_classification(n_samples=1000,?n_features=20,?n_informative=15,?n_redundant=5,?random_state=1)
?return?X,?y
?
#?get?a?list?of?models?to?evaluate
def?get_models():
?models?=?dict()
?models['lr']?=?LogisticRegression()
?models['knn']?=?KNeighborsClassifier()
?models['cart']?=?DecisionTreeClassifier()
?models['svm']?=?SVC()
?models['bayes']?=?GaussianNB()
?return?models
?
#?evaluate?a?given?model?using?cross-validation
def?evaluate_model(model,?X,?y):
?cv?=?RepeatedStratifiedKFold(n_splits=10,?n_repeats=3,?random_state=1)
?scores?=?cross_val_score(model,?X,?y,?scoring='accuracy',?cv=cv,?n_jobs=-1,?error_score='raise')
?return?scores
?
#?define?dataset
X,?y?=?get_dataset()
#?get?the?models?to?evaluate
models?=?get_models()
#?evaluate?the?models?and?store?results
results,?names?=?list(),?list()
for?name,?model?in?models.items():
?scores?=?evaluate_model(model,?X,?y)
?results.append(scores)
?names.append(name)
?print('>%s?%.3f?(%.3f)'?%?(name,?mean(scores),?std(scores)))
#?plot?model?performance?for?comparison
pyplot.boxplot(results,?labels=names,?showmeans=True)
pyplot.show()
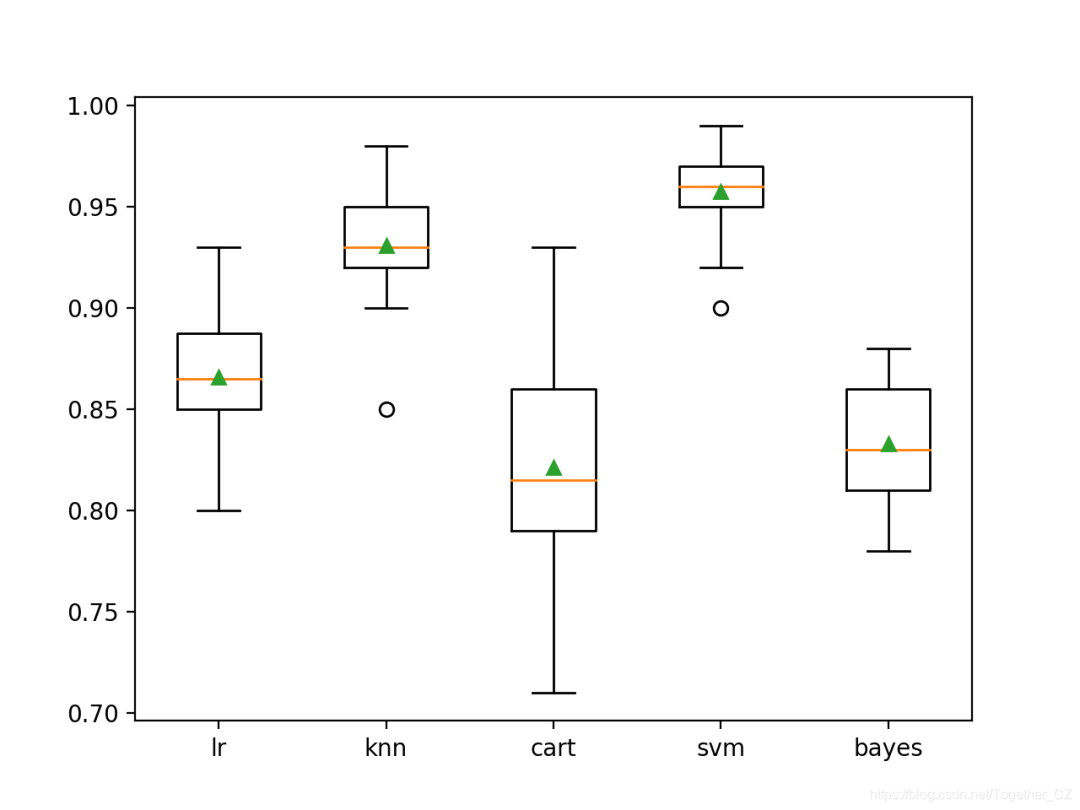
>lr?0.866?(0.029)
>knn?0.931?(0.025)
>cart?0.821?(0.050)
>svm?0.957?(0.020)
>bayes?0.833?(0.031)
#?get?a?stacking?ensemble?of?models
def?get_stacking():
?#?define?the?base?models
?level0?=?list()
?level0.append(('lr',?LogisticRegression()))
?level0.append(('knn',?KNeighborsClassifier()))
?level0.append(('cart',?DecisionTreeClassifier()))
?level0.append(('svm',?SVC()))
?level0.append(('bayes',?GaussianNB()))
?#?define?meta?learner?model
?level1?=?LogisticRegression()
?#?define?the?stacking?ensemble
?model?=?StackingClassifier(estimators=level0,?final_estimator=level1,?cv=5)
?return?model
#?get?a?list?of?models?to?evaluate
def?get_models():
?models?=?dict()
?models['lr']?=?LogisticRegression()
?models['knn']?=?KNeighborsClassifier()
?models['cart']?=?DecisionTreeClassifier()
?models['svm']?=?SVC()
?models['bayes']?=?GaussianNB()
?models['stacking']?=?get_stacking()
?return?models
#?compare?ensemble?to?each?baseline?classifier
from?numpy?import?mean
from?numpy?import?std
from?sklearn.datasets?import?make_classification
from?sklearn.model_selection?import?cross_val_score
from?sklearn.model_selection?import?RepeatedStratifiedKFold
from?sklearn.linear_model?import?LogisticRegression
from?sklearn.neighbors?import?KNeighborsClassifier
from?sklearn.tree?import?DecisionTreeClassifier
from?sklearn.svm?import?SVC
from?sklearn.naive_bayes?import?GaussianNB
from?sklearn.ensemble?import?StackingClassifier
from?matplotlib?import?pyplot
?
#?get?the?dataset
def?get_dataset():
?X,?y?=?make_classification(n_samples=1000,?n_features=20,?n_informative=15,?n_redundant=5,?random_state=1)
?return?X,?y
?
#?get?a?stacking?ensemble?of?models
def?get_stacking():
?#?define?the?base?models
?level0?=?list()
?level0.append(('lr',?LogisticRegression()))
?level0.append(('knn',?KNeighborsClassifier()))
?level0.append(('cart',?DecisionTreeClassifier()))
?level0.append(('svm',?SVC()))
?level0.append(('bayes',?GaussianNB()))
?#?define?meta?learner?model
?level1?=?LogisticRegression()
?#?define?the?stacking?ensemble
?model?=?StackingClassifier(estimators=level0,?final_estimator=level1,?cv=5)
?return?model
?
#?get?a?list?of?models?to?evaluate
def?get_models():
?models?=?dict()
?models['lr']?=?LogisticRegression()
?models['knn']?=?KNeighborsClassifier()
?models['cart']?=?DecisionTreeClassifier()
?models['svm']?=?SVC()
?models['bayes']?=?GaussianNB()
?models['stacking']?=?get_stacking()
?return?models
?
#?evaluate?a?give?model?using?cross-validation
def?evaluate_model(model,?X,?y):
?cv?=?RepeatedStratifiedKFold(n_splits=10,?n_repeats=3,?random_state=1)
?scores?=?cross_val_score(model,?X,?y,?scoring='accuracy',?cv=cv,?n_jobs=-1,?error_score='raise')
?return?scores
?
#?define?dataset
X,?y?=?get_dataset()
#?get?the?models?to?evaluate
models?=?get_models()
#?evaluate?the?models?and?store?results
results,?names?=?list(),?list()
for?name,?model?in?models.items():
?scores?=?evaluate_model(model,?X,?y)
?results.append(scores)
?names.append(name)
?print('>%s?%.3f?(%.3f)'?%?(name,?mean(scores),?std(scores)))
#?plot?model?performance?for?comparison
pyplot.boxplot(results,?labels=names,?showmeans=True)
pyplot.show()
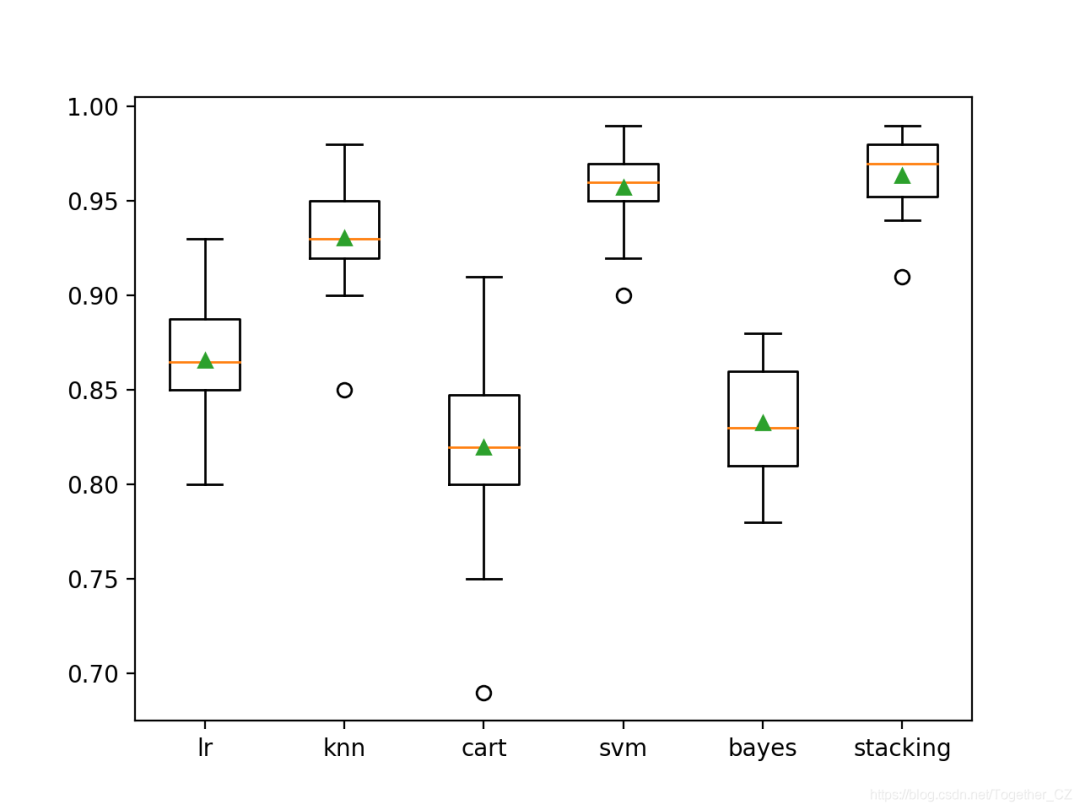
>lr?0.866?(0.029)
>knn?0.931?(0.025)
>cart?0.820?(0.044)
>svm?0.957?(0.020)
>bayes?0.833?(0.031)
>stacking?0.964?(0.019)
#?make?a?prediction?with?a?stacking?ensemble
from?sklearn.datasets?import?make_classification
from?sklearn.ensemble?import?StackingClassifier
from?sklearn.linear_model?import?LogisticRegression
from?sklearn.neighbors?import?KNeighborsClassifier
from?sklearn.tree?import?DecisionTreeClassifier
from?sklearn.svm?import?SVC
from?sklearn.naive_bayes?import?GaussianNB
#?define?dataset
X,?y?=?make_classification(n_samples=1000,?n_features=20,?n_informative=15,?n_redundant=5,?random_state=1)
#?define?the?base?models
level0?=?list()
level0.append(('lr',?LogisticRegression()))
level0.append(('knn',?KNeighborsClassifier()))
level0.append(('cart',?DecisionTreeClassifier()))
level0.append(('svm',?SVC()))
level0.append(('bayes',?GaussianNB()))
#?define?meta?learner?model
level1?=?LogisticRegression()
#?define?the?stacking?ensemble
model?=?StackingClassifier(estimators=level0,?final_estimator=level1,?cv=5)
#?fit?the?model?on?all?available?data
model.fit(X,?y)
#?make?a?prediction?for?one?example
data?=?[[2.47475454,0.40165523,1.68081787,2.88940715,0.91704519,-3.07950644,4.39961206,0.72464273,-4.86563631,-6.06338084,-1.22209949,-0.4699618,1.01222748,-0.6899355,-0.53000581,6.86966784,-3.27211075,-6.59044146,-2.21290585,-3.139579]]
yhat?=?model.predict(data)
print('Predicted?Class:?%d'?%?(yhat))
Predicted?Class:?0
make_regression()函數(shù)創(chuàng)建具有1000個示例和20個輸入要素的綜合回歸問題。下面列出了完整的示例。#?test?regression?dataset
from?sklearn.datasets?import?make_regression
#?define?dataset
X,?y?=?make_regression(n_samples=1000,?n_features=20,?n_informative=15,?noise=0.1,?random_state=1)
#?summarize?the?dataset
print(X.shape,?y.shape)
(1000,?20)?(1000,)
k近鄰 決策樹 支持向量回歸
#?get?a?list?of?models?to?evaluate
def?get_models():
?models?=?dict()
?models['knn']?=?KNeighborsRegressor()
?models['cart']?=?DecisionTreeRegressor()
?models['svm']?=?SVR()
?return?models
valuate_model()函數(shù)采用一個模型實例,并從三個重復的10倍交叉驗證中返回分數(shù)列表。#?evaluate?a?given?model?using?cross-validation
def?evaluate_model(model,?X,?y):
?cv?=?RepeatedKFold(n_splits=10,?n_repeats=3,?random_state=1)
?scores?=?cross_val_score(model,?X,?y,?scoring='neg_mean_absolute_error',?cv=cv,?n_jobs=-1,?error_score='raise')
?return?scores
#?compare?machine?learning?models?for?regression
from?numpy?import?mean
from?numpy?import?std
from?sklearn.datasets?import?make_regression
from?sklearn.model_selection?import?cross_val_score
from?sklearn.model_selection?import?RepeatedKFold
from?sklearn.linear_model?import?LinearRegression
from?sklearn.neighbors?import?KNeighborsRegressor
from?sklearn.tree?import?DecisionTreeRegressor
from?sklearn.svm?import?SVR
from?matplotlib?import?pyplot
?
#?get?the?dataset
def?get_dataset():
?X,?y?=?make_regression(n_samples=1000,?n_features=20,?n_informative=15,?noise=0.1,?random_state=1)
?return?X,?y
?
#?get?a?list?of?models?to?evaluate
def?get_models():
?models?=?dict()
?models['knn']?=?KNeighborsRegressor()
?models['cart']?=?DecisionTreeRegressor()
?models['svm']?=?SVR()
?return?models
?
#?evaluate?a?given?model?using?cross-validation
def?evaluate_model(model,?X,?y):
?cv?=?RepeatedKFold(n_splits=10,?n_repeats=3,?random_state=1)
?scores?=?cross_val_score(model,?X,?y,?scoring='neg_mean_absolute_error',?cv=cv,?n_jobs=-1,?error_score='raise')
?return?scores
?
#?define?dataset
X,?y?=?get_dataset()
#?get?the?models?to?evaluate
models?=?get_models()
#?evaluate?the?models?and?store?results
results,?names?=?list(),?list()
for?name,?model?in?models.items():
?scores?=?evaluate_model(model,?X,?y)
?results.append(scores)
?names.append(name)
?print('>%s?%.3f?(%.3f)'?%?(name,?mean(scores),?std(scores)))
#?plot?model?performance?for?comparison
pyplot.boxplot(results,?labels=names,?showmeans=True)
pyplot.show()
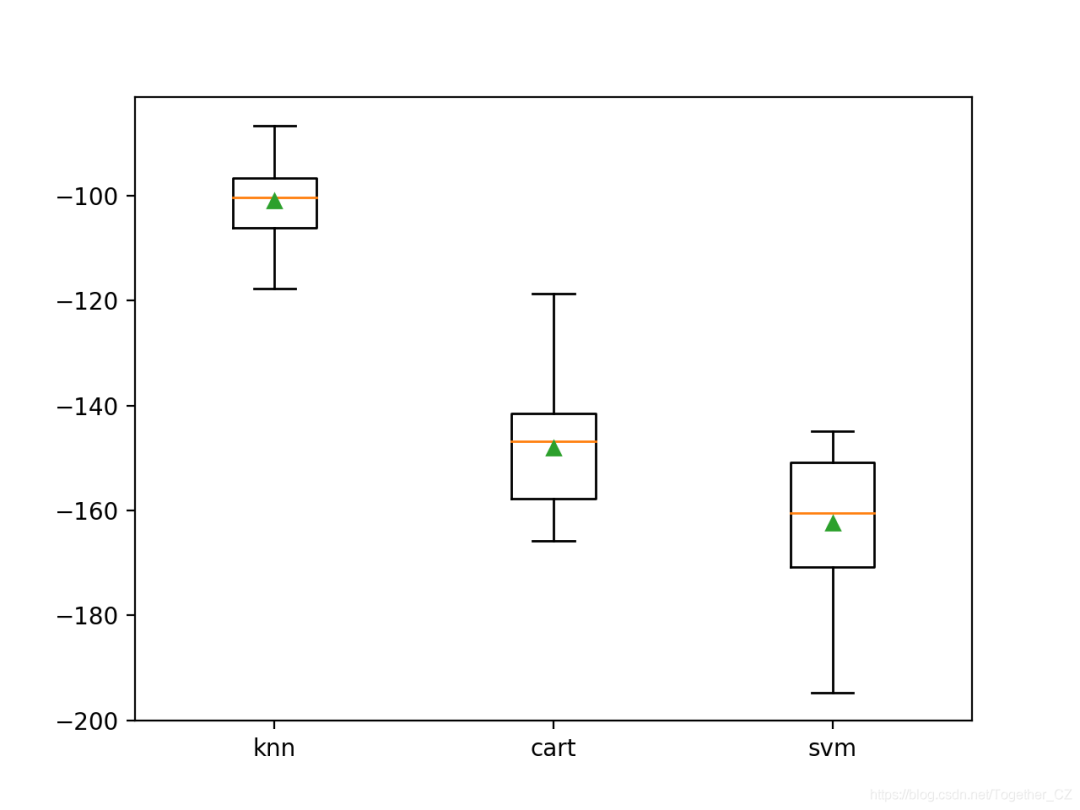
>knn?-101.019?(7.161)
>cart?-148.100?(11.039)
>svm?-162.419?(12.565)
get_stacking()函數(shù)通過首先為三個基本模型定義一個元組列表,然后定義線性回歸元模型以使用5倍交叉驗證組合來自基本模型的預測來定義StackingRegressor模型。#?get?a?stacking?ensemble?of?models
def?get_stacking():
?#?define?the?base?models
?level0?=?list()
?level0.append(('knn',?KNeighborsRegressor()))
?level0.append(('cart',?DecisionTreeRegressor()))
?level0.append(('svm',?SVR()))
?#?define?meta?learner?model
?level1?=?LinearRegression()
?#?define?the?stacking?ensemble
?model?=?StackingRegressor(estimators=level0,?final_estimator=level1,?cv=5)
?return?model
#?get?a?list?of?models?to?evaluate
def?get_models():
?models?=?dict()
?models['knn']?=?KNeighborsRegressor()
?models['cart']?=?DecisionTreeRegressor()
?models['svm']?=?SVR()
?models['stacking']?=?get_stacking()
?return?models
#?compare?ensemble?to?each?standalone?models?for?regression
from?numpy?import?mean
from?numpy?import?std
from?sklearn.datasets?import?make_regression
from?sklearn.model_selection?import?cross_val_score
from?sklearn.model_selection?import?RepeatedKFold
from?sklearn.linear_model?import?LinearRegression
from?sklearn.neighbors?import?KNeighborsRegressor
from?sklearn.tree?import?DecisionTreeRegressor
from?sklearn.svm?import?SVR
from?sklearn.ensemble?import?StackingRegressor
from?matplotlib?import?pyplot
?
#?get?the?dataset
def?get_dataset():
?X,?y?=?make_regression(n_samples=1000,?n_features=20,?n_informative=15,?noise=0.1,?random_state=1)
?return?X,?y
?
#?get?a?stacking?ensemble?of?models
def?get_stacking():
?#?define?the?base?models
?level0?=?list()
?level0.append(('knn',?KNeighborsRegressor()))
?level0.append(('cart',?DecisionTreeRegressor()))
?level0.append(('svm',?SVR()))
?#?define?meta?learner?model
?level1?=?LinearRegression()
?#?define?the?stacking?ensemble
?model?=?StackingRegressor(estimators=level0,?final_estimator=level1,?cv=5)
?return?model
?
#?get?a?list?of?models?to?evaluate
def?get_models():
?models?=?dict()
?models['knn']?=?KNeighborsRegressor()
?models['cart']?=?DecisionTreeRegressor()
?models['svm']?=?SVR()
?models['stacking']?=?get_stacking()
?return?models
?
#?evaluate?a?given?model?using?cross-validation
def?evaluate_model(model,?X,?y):
?cv?=?RepeatedKFold(n_splits=10,?n_repeats=3,?random_state=1)
?scores?=?cross_val_score(model,?X,?y,?scoring='neg_mean_absolute_error',?cv=cv,?n_jobs=-1,?error_score='raise')
?return?scores
?
#?define?dataset
X,?y?=?get_dataset()
#?get?the?models?to?evaluate
models?=?get_models()
#?evaluate?the?models?and?store?results
results,?names?=?list(),?list()
for?name,?model?in?models.items():
?scores?=?evaluate_model(model,?X,?y)
?results.append(scores)
?names.append(name)
?print('>%s?%.3f?(%.3f)'?%?(name,?mean(scores),?std(scores)))
#?plot?model?performance?for?comparison
pyplot.boxplot(results,?labels=names,?showmeans=True)
pyplot.show()
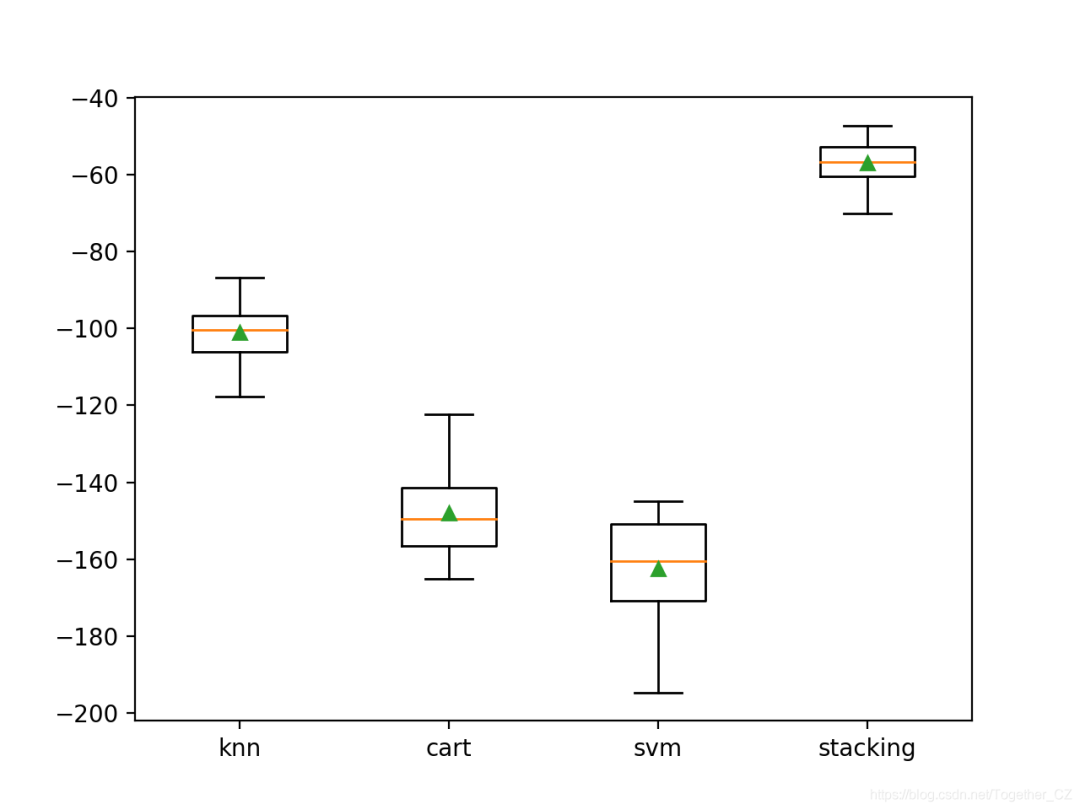
>knn?-101.019?(7.161)
>cart?-148.017?(10.635)
>svm?-162.419?(12.565)
>stacking?-56.893?(5.253)
#?make?a?prediction?with?a?stacking?ensemble
from?sklearn.datasets?import?make_regression
from?sklearn.linear_model?import?LinearRegression
from?sklearn.neighbors?import?KNeighborsRegressor
from?sklearn.tree?import?DecisionTreeRegressor
from?sklearn.svm?import?SVR
from?sklearn.ensemble?import?StackingRegressor
#?define?dataset
X,?y?=?make_regression(n_samples=1000,?n_features=20,?n_informative=15,?noise=0.1,?random_state=1)
#?define?the?base?models
level0?=?list()
level0.append(('knn',?KNeighborsRegressor()))
level0.append(('cart',?DecisionTreeRegressor()))
level0.append(('svm',?SVR()))
#?define?meta?learner?model
level1?=?LinearRegression()
#?define?the?stacking?ensemble
model?=?StackingRegressor(estimators=level0,?final_estimator=level1,?cv=5)
#?fit?the?model?on?all?available?data
model.fit(X,?y)
#?make?a?prediction?for?one?example
data?=?[[0.59332206,-0.56637507,1.34808718,-0.57054047,-0.72480487,1.05648449,0.77744852,0.07361796,0.88398267,2.02843157,1.01902732,0.11227799,0.94218853,0.26741783,0.91458143,-0.72759572,1.08842814,-0.61450942,-0.69387293,1.69169009]]
yhat?=?model.predict(data)
print('Predicted?Value:?%.3f'?%?(yhat))
Predicted?Value:?556.264
作者:沂水寒城,CSDN博客專家,個人研究方向:機器學習、深度學習、NLP、CV
Blog:?http://yishuihancheng.blog.csdn.net
贊 賞 作 者

更多閱讀
特別推薦

點擊下方閱讀原文加入社區(qū)會員
評論
圖片
表情