
OpenCV實現(xiàn)基于邊緣的模板匹配--適用部分遮擋和光照變化情形(附源碼)
點擊下方卡片,關(guān)注“新機(jī)器視覺”公眾號
視覺/圖像重磅干貨,第一時間送達(dá)
原文作者:Shiju PK 原文鏈接:
https://www.codeproject.com/articles/99457/edge-based-template-matching
翻譯整理:Color Space
來源:Opencv與AI深度學(xué)習(xí)
介紹
模板匹配是一個圖像處理問題,當(dāng)其姿態(tài)(X,Y,θ)未知時,使用另一張搜索圖像中的模板圖像找到對象的位置。在本文中,我們實現(xiàn)了一種算法,該算法使用對象的邊緣信息來識別搜索圖像中的對象。
背景
由于其速度和可靠性問題,模板匹配本質(zhì)上是一個棘手的問題。當(dāng)對象部分可見或與其他對象混合時,該解決方案應(yīng)對亮度變化具有魯棒性,最重要的是,該算法應(yīng)具有計算效率。解決這個問題主要有兩種方法,基于灰度值的匹配(或基于區(qū)域的匹配)和基于特征的匹配(非基于區(qū)域的匹配)。
基于灰度值的方法:在基于灰度值的匹配中,歸一化互相關(guān) (NCC) 算法早在過去就已為人所知。這通常在每一步通過減去平均值并除以標(biāo)準(zhǔn)偏差來完成。模板 t(x, y) 與子圖像 f(x, y) 的互相關(guān)為:
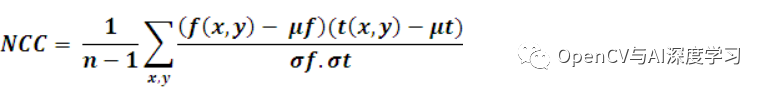
其中 n 是 t(x, y) 和 f(x, y) 中的像素數(shù)。[維基]
盡管該方法對線性光照變化具有魯棒性,但當(dāng)對象部分可見或?qū)ο笈c其他對象混合時,該算法將失敗。此外,該算法的計算成本很高,因為它需要計算模板圖像中所有像素與搜索圖像之間的相關(guān)性。
基于特征的方法:在圖像處理領(lǐng)域中使用了幾種基于特征的模板匹配方法。與基于邊緣的物體識別一樣,物體邊緣是用于匹配的特征,在廣義霍夫變換中,物體的幾何特征將用于匹配。
在本文中,我們實現(xiàn)了一種算法,該算法使用對象的邊緣信息來識別搜索圖像中的對象。此實現(xiàn)使用開源計算機(jī)視覺庫作為平臺。
編譯示例代碼
我們使用 OpenCV 2.0 和 Visual Studio 2008 來開發(fā)此代碼。要編譯示例代碼,我們需要安裝 OpenCV。
OpenCV 可以從這里免費(fèi)下載。OpenCV的(開放源碼?動態(tài)數(shù)值V ision)是一種用于實時計算機(jī)視覺編程功能的庫。下載 OpenCV 并將其安裝在您的系統(tǒng)中。安裝信息可以從這里閱讀。
我們需要配置我們的 Visual Studio 環(huán)境。可以從此處閱讀此信息。
算法
在這里,我們將解釋基于邊緣的模板匹配技術(shù)。邊緣可以定義為數(shù)字圖像中圖像亮度急劇變化或具有不連續(xù)性的點。從技術(shù)上講,它是一種離散微分運(yùn)算,計算圖像強(qiáng)度函數(shù)的梯度近似值。
邊緣檢測的方法有很多,但大多數(shù)可以分為兩類:基于搜索的和基于過零的。基于搜索的方法通過首先計算邊緣強(qiáng)度的度量來檢測邊緣,通常是一階導(dǎo)數(shù)表達(dá)式,例如梯度幅度,然后使用計算的局部方向的估計來搜索梯度幅度的局部方向最大值邊緣,通常是梯度方向。在這里,我們使用了一種由 Sobel 實現(xiàn)的方法,稱為 Sobel 算子。操作員計算每個點的圖像強(qiáng)度梯度,給出從明到暗的最大可能增加方向以及該方向的變化率。
我們在 X 方向和 Y 方向使用這些梯度或?qū)?shù)進(jìn)行匹配。
該算法包括兩個步驟。首先,我們需要為模板圖像創(chuàng)建一個基于邊緣的模型,然后我們使用這個模型在搜索圖像中進(jìn)行搜索。
創(chuàng)建基于邊緣的模板模型
我們首先從模板圖像的邊緣創(chuàng)建一個數(shù)據(jù)集或模板模型,用于在搜索圖像中查找該對象的姿態(tài)。
在這里,我們使用 Canny 邊緣檢測方法的變體來查找邊緣。您可以在此處閱讀有關(guān) Canny 邊緣檢測的更多信息。對于邊緣提取,Canny 使用以下步驟:
第一步:求圖像的強(qiáng)度梯度
在模板圖像上使用 Sobel 過濾器,它返回 X (Gx) 和 Y (Gy) 方向的梯度。根據(jù)這個梯度,我們將使用以下公式計算邊緣大小和方向:

我們正在使用 OpenCV 函數(shù)來查找這些值。
cvSobel( src, gx, 1,0, 3 ); //gradient in X directioncvSobel( src, gy, 0, 1, 3 ); //gradient in Y directionfor( i = 1; i < Ssize.height-1; i++ ){for( j = 1; j < Ssize.width-1; j++ ){_sdx = (short*)(gx->data.ptr + gx->step*i);_sdy = (short*)(gy->data.ptr + gy->step*i);fdx = _sdx[j]; fdy = _sdy[j];// read x, y derivatives//Magnitude = Sqrt(gx^2 +gy^2)MagG = sqrt((float)(fdx*fdx) + (float)(fdy*fdy));//Direction = invtan (Gy / Gx)direction =cvFastArctan((float)fdy,(float)fdx);magMat[i][j] = MagG;if(MagG>MaxGradient)MaxGradient=MagG;// get maximum gradient value for normalizing.// get closest angle from 0, 45, 90, 135 setif ( (direction>0 && direction < 22.5) ||(direction >157.5 && direction < 202.5) ||(direction>337.5 && direction<360) )direction = 0;else if ( (direction>22.5 && direction < 67.5) ||(direction >202.5 && direction <247.5) )direction = 45;else if ( (direction >67.5 && direction < 112.5)||(direction>247.5 && direction<292.5) )direction = 90;else if ( (direction >112.5 && direction < 157.5)||(direction>292.5 && direction<337.5) )direction = 135;elsedirection = 0;orients[count] = (int)direction;count++;}}
一旦找到邊緣方向,下一步就是關(guān)聯(lián)圖像中可以追蹤的邊緣方向。有四種可能的方向來描述周圍的像素:0 度、45 度、90 度和 135 度。我們將所有方向分配給這些角度中的任何一個。
步驟 2:應(yīng)用非極大值抑制
找到邊緣方向后,我們會做一個非極大值抑制算法。非極大值抑制沿邊緣方向跟蹤左右像素,如果當(dāng)前像素幅度小于左右像素幅度,則抑制當(dāng)前像素幅度。這將導(dǎo)致圖像變薄。
for( i = 1; i < Ssize.height-1; i++ ){for( j = 1; j < Ssize.width-1; j++ ){switch ( orients[count] ){case 0:leftPixel = magMat[i][j-1];rightPixel = magMat[i][j+1];break;case 45:leftPixel = magMat[i-1][j+1];rightPixel = magMat[i+1][j-1];break;case 90:leftPixel = magMat[i-1][j];rightPixel = magMat[i+1][j];break;case 135:leftPixel = magMat[i-1][j-1];rightPixel = magMat[i+1][j+1];break;}// compare current pixels value with adjacent pixelsif (( magMat[i][j] < leftPixel ) || (magMat[i][j] < rightPixel ) )(nmsEdges->data.ptr + nmsEdges->step*i)[j]=0;Else(nmsEdges->data.ptr + nmsEdges->step*i)[j]=(uchar)(magMat[i][j]/MaxGradient*255);count++;}}
第三步:做滯后閾值
用滯后做閾值需要兩個閾值:高和低。我們應(yīng)用高閾值來標(biāo)記那些我們可以相當(dāng)確定是真實的邊緣。從這些開始,使用先前導(dǎo)出的方向信息,可以通過圖像追蹤其他邊緣。在跟蹤邊緣時,我們應(yīng)用較低的閾值,只要我們找到一個起點,我們就可以跟蹤邊緣的微弱部分。
_sdx = (short*)(gx->data.ptr + gx->step*i);_sdy = (short*)(gy->data.ptr + gy->step*i);fdx = _sdx[j]; fdy = _sdy[j];MagG = sqrt(fdx*fdx + fdy*fdy); //Magnitude = Sqrt(gx^2 +gy^2)DirG =cvFastArctan((float)fdy,(float)fdx); //Direction = tan(y/x)////((uchar*)(imgGDir->imageData + imgGDir->widthStep*i))[j]= MagG;flag=1;if(((double)((nmsEdges->data.ptr + nmsEdges->step*i))[j]) < maxContrast){if(((double)((nmsEdges->data.ptr + nmsEdges->step*i))[j])< minContrast){(nmsEdges->data.ptr + nmsEdges->step*i)[j]=0;flag=0; // remove from edge////((uchar*)(imgGDir->imageData + imgGDir->widthStep*i))[j]=0;}else{ // if any of 8 neighboring pixel is not greater than max contraxt remove from edgeif( (((double)((nmsEdges->data.ptr + nmsEdges->step*(i-1)))[j-1]) < maxContrast) &&(((double)((nmsEdges->data.ptr + nmsEdges->step*(i-1)))[j]) < maxContrast) &&(((double)((nmsEdges->data.ptr + nmsEdges->step*(i-1)))[j+1]) < maxContrast) &&(((double)((nmsEdges->data.ptr + nmsEdges->step*i))[j-1]) < maxContrast) &&(((double)((nmsEdges->data.ptr + nmsEdges->step*i))[j+1]) < maxContrast) &&(((double)((nmsEdges->data.ptr + nmsEdges->step*(i+1)))[j-1]) < maxContrast) &&(((double)((nmsEdges->data.ptr + nmsEdges->step*(i+1)))[j]) < maxContrast) &&(((double)((nmsEdges->data.ptr + nmsEdges->step*(i+1)))[j+1]) < maxContrast)){(nmsEdges->data.ptr + nmsEdges->step*i)[j]=0;flag=0;////((uchar*)(imgGDir->imageData + imgGDir->widthStep*i))[j]=0;}}}
第 4 步:保存數(shù)據(jù)集
提取邊緣后,我們將所選邊緣的 X 和 Y 導(dǎo)數(shù)與坐標(biāo)信息一起保存為模板模型。這些坐標(biāo)將重新排列以反映作為重心的起點。
找到基于邊的模板模型
算法中的下一個任務(wù)是使用模板模型在搜索圖像中找到對象。我們可以看到我們從包含一組點的模板圖像創(chuàng)建的模型:
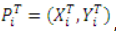
,以及它在 X 和 Y 方向上的梯度
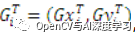
,其中i = 1…n,n是模板 (T) 數(shù)據(jù)集中的元素數(shù)。
我們還可以在搜索圖像 (S) 中找到梯度
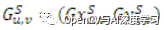
,其中 u = 1...搜索圖像中的行數(shù),v = 1...搜索圖像中的列數(shù)。
在匹配過程中,應(yīng)使用相似性度量將模板模型與所有位置的搜索圖像進(jìn)行比較。相似性度量背后的思想是取模板圖像梯度向量的所有歸一化點積之和,并在模型數(shù)據(jù)集中的所有點上搜索圖像。這會導(dǎo)致搜索圖像中每個點的分?jǐn)?shù)。這可以表述如下:
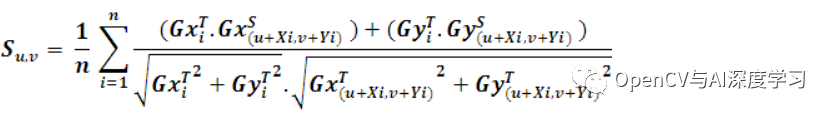
如果模板模型和搜索圖像之間存在完美匹配,則此函數(shù)將返回分?jǐn)?shù) 1。該分?jǐn)?shù)對應(yīng)于搜索圖像中可見的對象部分。如果搜索圖像中不存在對象,則分?jǐn)?shù)將為 0。
cvSobel( src, Sdx, 1, 0, 3 ); // find X derivativescvSobel( src, Sdy, 0, 1, 3 ); // find Y derivativesfor( i = 0; i < Ssize.height; i++ ){for( j = 0; j < Ssize.width; j++ ){partialSum = 0; // initilize partialSum measurefor(m=0;m<noOfCordinates;m++){curX = i + cordinates[m].x ; // template X coordinatecurY = j + cordinates[m].y ; // template Y coordinateiTx = edgeDerivativeX[m]; // template X derivativeiTy = edgeDerivativeY[m]; // template Y derivativeif(curX<0 ||curY<0||curX>Ssize.height-1 ||curY>Ssize.width-1)continue;_Sdx = (short*)(Sdx->data.ptr + Sdx->step*(curX));_Sdy = (short*)(Sdy->data.ptr + Sdy->step*(curX));iSx=_Sdx[curY]; // get curresponding X derivative from source imageiSy=_Sdy[curY];// get curresponding Y derivative from source imageif((iSx!=0 || iSy!=0) && (iTx!=0 || iTy!=0)){//partial Sum = Sum of(((Source X derivative* Template X drivative)//+ Source Y derivative * Template Y derivative)) / Edge//magnitude of(Template)* edge magnitude of(Source))partialSum = partialSum + ((iSx*iTx)+(iSy*iTy))*(edgeMagnitude[m] * matGradMag[curX][curY]);}
在實際情況下,我們需要加快搜索過程。這可以使用各種方法來實現(xiàn)。第一種方法是使用平均的屬性。在尋找相似性度量時,如果我們可以為相似性度量設(shè)置一個最小分?jǐn)?shù)(S min),我們就不需要評估模板模型中的所有點。為了檢查特定點 J 處的部分分?jǐn)?shù) S u,v,我們必須找到部分總和 Sm。點 m 處的 Sm 可以定義如下:
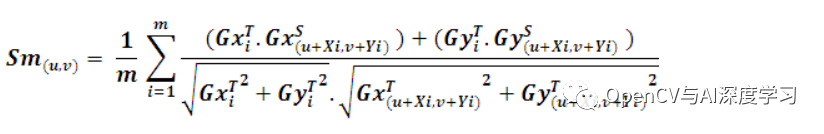
很明顯,和的剩余項小于或等于 1。因此,如果 ,我們可以停止評估

。
另一個標(biāo)準(zhǔn)可以是任何點的部分分?jǐn)?shù)應(yīng)大于最低分?jǐn)?shù)。即,
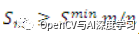
。使用此條件時,匹配將非常快。但問題是,如果先檢查對象的缺失部分,部分和會很低。在這種情況下,對象的該實例不會被視為匹配項。我們可以用另一個標(biāo)準(zhǔn)修改它,我們用安全停止標(biāo)準(zhǔn)檢查模板模型的第一部分,用硬標(biāo)準(zhǔn)檢查其余部分,
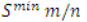
. 用戶可以指定貪婪參數(shù) (g),其中使用硬標(biāo)準(zhǔn)檢查模板模型的部分。所以如果g=1,模板模型中的所有點都用硬標(biāo)準(zhǔn)檢查,如果g=0,所有點將只用安全標(biāo)準(zhǔn)檢查。我們可以將這個過程表述如下。
部分分?jǐn)?shù)的評估可以在以下位置停止:
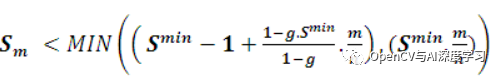
// stoping criterias to search for modeldouble normMinScore = minScore /noOfCordinates; // precompute minumum scoredouble normGreediness = ((1- greediness * minScore)/(1-greediness)) /noOfCordinates;// precompute greedninesssumOfCoords = m + 1;partialScore = partialSum /sumOfCoords ;// check termination criteria// if partial score score is less than the score than// needed to make the required score at that position// break serching at that coordinate.if( partialScore < (MIN((minScore -1) +normGreediness*sumOfCoords,normMinScore* sumOfCoords)))break;
這種相似性度量有幾個優(yōu)點:相似性度量對非線性光照變化是不變的,因為所有梯度向量都是歸一化的。由于邊緣過濾沒有分割,它將顯示對光照任意變化的真實不變性。更重要的是,當(dāng)對象部分可見或與其他對象混合時,這種相似性度量是穩(wěn)健的。
增強(qiáng)功能
該算法有多種可能的增強(qiáng)。為了進(jìn)一步加快搜索過程,可以使用金字塔方法。在這種情況下,搜索以低分辨率和小圖像尺寸開始。這對應(yīng)于金字塔的頂部。如果在此階段搜索成功,則在金字塔的下一層繼續(xù)搜索,該層代表更高分辨率的圖像。以這種方式,繼續(xù)搜索,從而細(xì)化結(jié)果,直到達(dá)到原始圖像大小,即到達(dá)金字塔底部。
通過擴(kuò)展旋轉(zhuǎn)和縮放算法,可以實現(xiàn)另一種增強(qiáng)。這可以通過創(chuàng)建用于旋轉(zhuǎn)和縮放的模板模型并使用所有這些模板模型執(zhí)行搜索來完成。
參考
機(jī)器視覺算法和應(yīng)用 [Carsten Steger、Markus Ulrich、Christian Wiedemann]
數(shù)字圖像處理 [Rafael C. Gonzalez, Richard Eugene Woods]
http://dasl.mem.drexel.edu/alumni/bGreen/www.pages.drexel.edu/_weg22/can_tut.html
源碼與測試Demo
1. 源碼下載鏈接:https://www.codeproject.com/KB/graphics/Edge_Based_template_match/GeoMatch_src.zip
2. 測試Demo下載鏈接:
https://www.codeproject.com/KB/graphics/Edge_Based_template_match/GeoMatch_demo.zip
—版權(quán)聲明—
僅用于學(xué)術(shù)分享,版權(quán)屬于原作者。
若有侵權(quán),請聯(lián)系微信號:yiyang-sy 刪除或修改!