
Python讓Excel飛起來—批量進行數(shù)據(jù)分析
Python讓Excel飛起來—批量進行數(shù)據(jù)分析
案例01 批量升序排序一個工作簿中的所有工作表
-
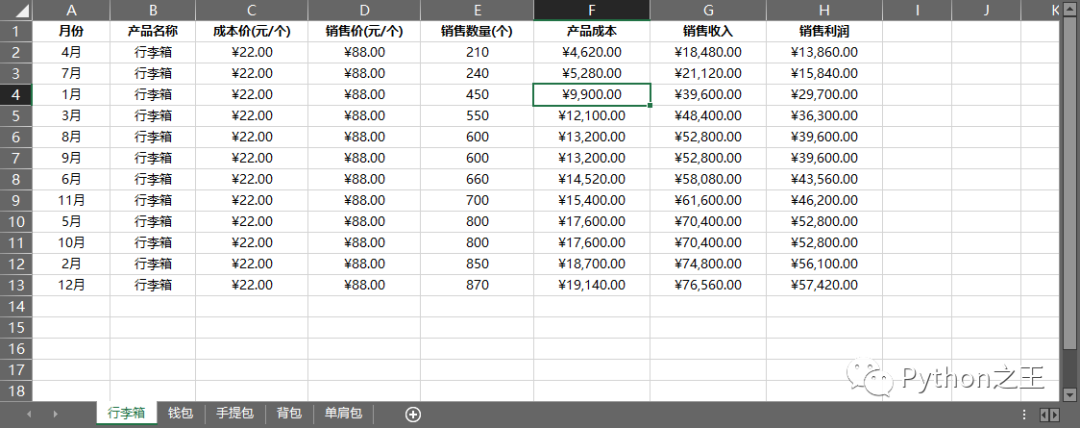
代碼文件:批量升序排序一個工作簿中的所有工作表.py - 數(shù)據(jù)文件:產(chǎn)品銷售統(tǒng)計表.xlsx 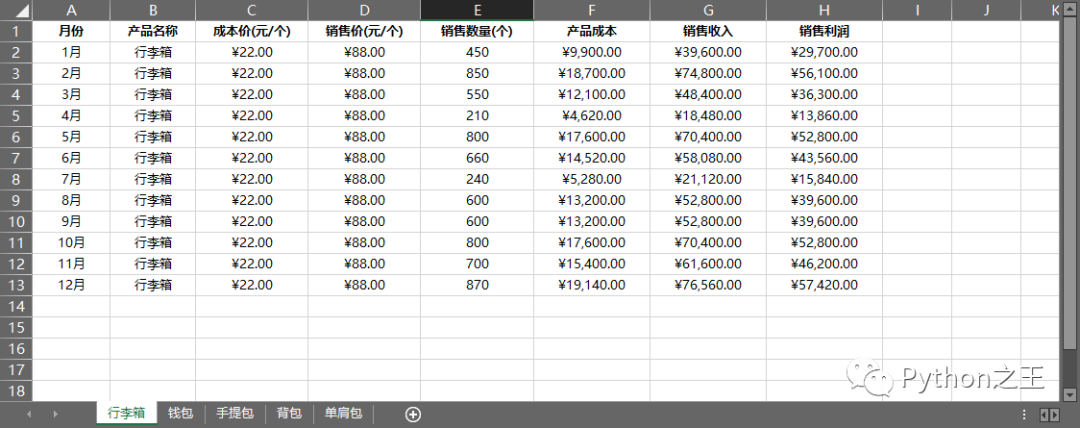 每個表批量對銷售利潤進行升序排列:
每個表批量對銷售利潤進行升序排列:
import xlwings as xw
import pandas as pd
app=xw.App(visible=True,add_book=False)
workbook=app.books.open(r'C:\Users\MLoong\Desktop\22\產(chǎn)品銷售統(tǒng)計表.xlsx')
for i in workbook.sheets:
values=i.range('A1').expand().options(pd.DataFrame).value #讀取當(dāng)前工作表的數(shù)據(jù)并裝換成DataFrame類型
result=values.sort_values(by='銷售利潤') #對銷售利潤進行排序
i.range('A1').value=result
workbook.save()
workbook.close()
app.quit()
知識延伸
舉一反三 批量排序多個工作簿中的數(shù)據(jù)
-
代碼文件:批量排序多個工作簿中的數(shù)據(jù).py - 數(shù)據(jù)文件:產(chǎn)品銷售統(tǒng)計表(文件夾)
import os
import xlwings as xw
import pandas as pd
app=xw.App(visible=True,add_book=False)
file_path=r'C:\Users\MLoong\Desktop\22\產(chǎn)品銷售統(tǒng)計表'
file_list=os.listdir(file_path)
for i in file_list:
if os.path.splitext(i)[1]=='.xlsx':
file_paths=os.path.join(file_path,i)
workbook=app.books.open(file_paths)
for j in workbook.sheets:
values= j.range('A1').expand().options(pd.DataFrame).value
result=values.sort_values(by='銷售利潤')
j.range('A1').value=result
workbook.save()
workbook.close()
app.quit()
案例02 篩選一個工作簿中的所有工作表數(shù)據(jù)
-
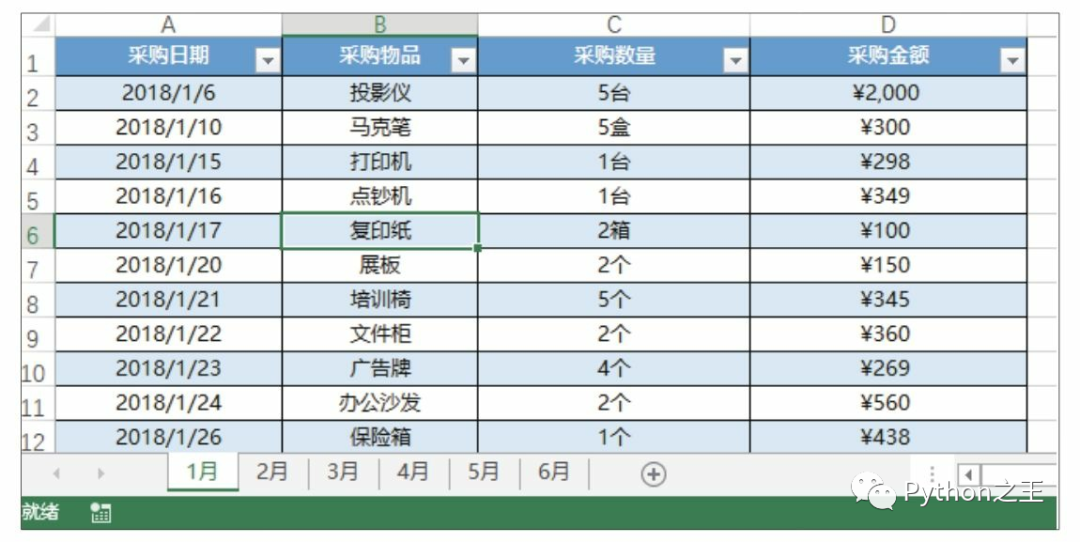
代碼文件:篩選一個工作簿中的所有工作表數(shù)據(jù).py - 數(shù)據(jù)文件:采購表.xlsx 下圖所示是按月份存放在不同工作表中的物品采購明細數(shù)據(jù),如果要更改為按物品名稱存放在不同工作表中,你會怎么做呢?
 思路:先合并所有表,再按采購物品名稱進行分表:
思路:先合并所有表,再按采購物品名稱進行分表:
import xlwings as xw
import pandas as pd
app=xw.App(visible=True,add_book=False)
workbook=app.books.open(r'C:\Users\MLoong\Desktop\22\采購表.xlsx')
#合并原工作簿中各工作表的數(shù)據(jù)
table=pd.DataFrame() #創(chuàng)建一個空的DataFrame
for i,j in enumerate(workbook.sheets) :
values=j.range('A1').options(pd.DataFrame,header=1,index=False,expand='table').value
data=values.reindex(columns=['采購物品','采購日期','采購數(shù)量','采購金額']) #調(diào)整列的順序
table=table.append(data,ignore_index=True)
#新建表,并寫入數(shù)據(jù)
table=table.groupby('采購物品')
new_workbook=app.books.add()
for idx,group in table: #遍歷篩選好的數(shù)據(jù),其中idx對應(yīng)物品名稱,group對應(yīng)物品的明細數(shù)據(jù)
new_worksheet=new_workbook.sheets.add(idx)
new_worksheet['A1'].options(index=False).value=group
#對分表進行求和,放在右下角最后一個位置
last_cell= new_worksheet['A1'].expand().last_cell #獲取當(dāng)前工作表數(shù)據(jù)區(qū)域右下角單元格
last_row=last_cell.row #獲取當(dāng)前工作表數(shù)據(jù)區(qū)域最后一行
last_column=last_cell.column #獲取當(dāng)前工作表數(shù)據(jù)區(qū)域最后一列
last_column_letter=chr(64+last_column) #根據(jù)最后一列,裝換成字母列標(biāo)
sum_cell_name='{}{}'.format(last_column_letter,last_row+1)
sum_last_row_name='{}{}'.format(last_column_letter,last_row)
formula='=sum({}2:{})'.format(last_column_letter,sum_last_row_name)
new_worksheet[sum_cell_name]. formula= formula
new_worksheet.autofit()
new_workbook.save(r'C:\Users\MLoong\Desktop\22\采購分類表.xlsx')
new_workbook.close()
workbook.close()
app.quit()
舉一反三 在一個工作簿中篩選單一類別數(shù)據(jù)
-
代碼文件:在一個工作簿中篩選單一類別數(shù)據(jù).py - 數(shù)據(jù)文件:采購表.xlsx
import xlwings as xw
import pandas as pd
app=xw.App(visible=True,add_book=False)
workbook=app.books.open(r'C:\Users\Administrator\Desktop\22\采購表.xlsx')
table=pd.DataFrame() #創(chuàng)建一個新的DataFrame
for i,j in enumerate(workbook.sheets):
values=j.range('A1').options(pd.DataFrame,header=1,index=False,expand='table').value
data=values.reindex(columns=['采購物品','采購日期','采購數(shù)量','采購金額'])
table=table.append(data,ignore_index=True) #ignore_index=True是序號進行累加的意思
product=table[table['采購物品']=='保險箱'] #篩選"采購物品"是"保險箱"的數(shù)據(jù)
new_workbook=xw.books.add()
new_worksheet=new_workbook.sheets.add('保險箱')
new_worksheet['A1'].options(index=False).value=product
new_worksheet.autofit()
new_workbook.save(r'C:\Users\Administrator\Desktop\22\保險箱.xlsx')
new_workbook.close()
workbook.close()
app.quit()
案例03 對多個工作簿中的工作表分別進行分類匯總
-
代碼文件:對多個工作簿中的工作表分別進行分類匯總.py - 數(shù)據(jù)文件:銷售表(文件夾) 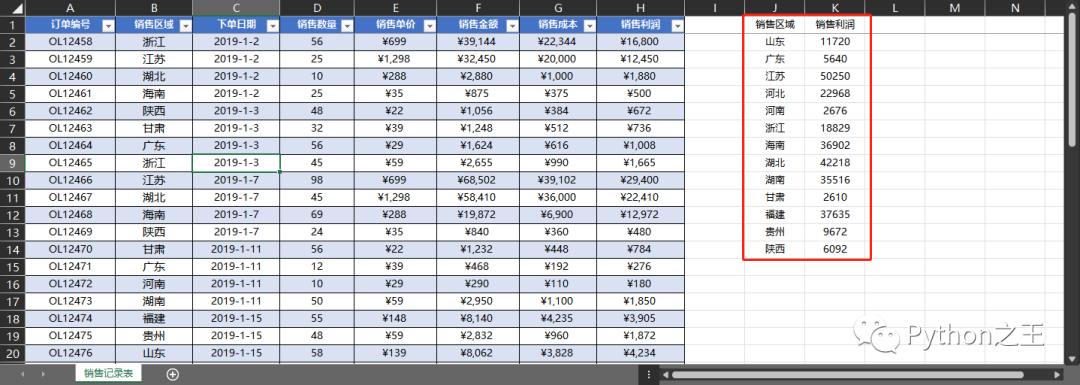
import os
import xlwings as xw
import pandas as pd
app=xw.App(visible=True,add_book=False)
file_path=r'C:\Users\Administrator\Desktop\22\03\銷售表'
file_list=os.listdir(file_path)
for i in file_list:
if os.path.splitext(i)[1]=='.xlsx':
workbook=app.books.open(file_path+'//'+i)
for j in workbook.sheets:
values=j.range('A1').expand().options(pd.DataFrame).value
values['銷售利潤']=values['銷售利潤'].astype('float') #轉(zhuǎn)換‘銷售利潤’列的數(shù)據(jù)類型
result=values.groupby('銷售區(qū)域').sum()
j.range('J1').value=result['銷售利潤']
workbook.save()
workbook.close()
app.quit()
-
第13行代碼中的astype()是pandas模塊中DataFrame對象的函數(shù),用于轉(zhuǎn)換指定列的數(shù)據(jù)類型。該函數(shù)的語法格式和常用參數(shù)含義如下。
-
第14行代碼中g(shù)roupby()函數(shù)后接的sum()函數(shù)用于進行求和匯總,還可以使用其他函數(shù)完成其他類型的匯總運算。常用的有:用mean()函數(shù)求平均值,用count()函數(shù)統(tǒng)計個數(shù),用max()函數(shù)求最大值,用min()函數(shù)求最小值。
舉一反三 批量分類匯總多個工作簿中的指定工作表
-
代碼文件:批量分類匯總多個工作簿中的指定工作表.py - 數(shù)據(jù)文件:銷售表1(文件夾)
import os
import xlwings as xw
import pandas as pd
app=xw.App(visible=True,add_book=False)
file_path=r'C:\Users\Administrator\Desktop\22\03\銷售表1'
file_list=os.listdir(file_path)
for i in file_list:
if os.path.splitext(i)[1]=='.xlsx':
workbook=app.books.open(file_path+'//'+i)
worksheet=workbook.sheets['銷售記錄表']
values=worksheet.range('A1').expand().options(pd.DataFrame).value
values['銷售利潤']=values['銷售利潤'].astype('float') #轉(zhuǎn)換‘銷售利潤’列的數(shù)據(jù)類型
result=values.groupby('銷售區(qū)域').sum()
worksheet.range('J1').value=result['銷售利潤']
workbook.save()
workbook.close()
app.quit()
舉一反三 將多個工作簿數(shù)據(jù)分類匯總到一個工作簿
-
代碼文件:將多個工作簿數(shù)據(jù)分類匯總到一個工作簿.py - 數(shù)據(jù)文件:銷售表(文件夾)
import os
import xlwings as xw
import pandas as pd
app=xw.App(visible=True,add_book=False)
file_path=r'C:\Users\Administrator\Desktop\22\03\銷售表'
file_list=os.listdir(file_path)
collection=[]
for i in file_list:
if os.path.splitext(i)[1]=='.xlsx':
workbook=app.books.open(file_path+'//'+i)
worksheet=workbook.sheets['銷售記錄表']
values=worksheet.range('A1').expand().options(pd.DataFrame).value
filtered=values[['銷售區(qū)域','銷售利潤']]
collection.append(filtered)
workbook.close()
new_values=pd.concat(collection,ignore_index=False).set_index('銷售區(qū)域')
values['銷售利潤']=values['銷售利潤'].astype('float') #轉(zhuǎn)換‘銷售利潤’列的數(shù)據(jù)類型
result=new_values.groupby('銷售區(qū)域').sum()
new_workbook=app.books.add()
new_worksheet=new_workbook.sheets.add('匯總表')
new_worksheet.range('A1').value=result
new_worksheet.autofit()
new_workbook.save(r'C:\Users\Administrator\Desktop\22\03\銷售匯總表.xlsx')
new_workbook.close()
app.quit()
案例04 對一個工作簿中的所有工作表分別求和
-
代碼文件:對一個工作簿中的所有工作表分別求和.py - 數(shù)據(jù)文件:采購表.xlsx
import os
import xlwings as xw
import pandas as pd
app=xw.App(visible=True,add_book=False)
workbook=app.books.open(r'C:\Users\Administrator\Desktop\22\采購表.xlsx')
for i in workbook.sheets:
values=i.range('A1').expand()
data=values.options(pd.DataFrame).value
sums=data['采購金額'].sum()
column=values.value[0].index('采購金額')+1
row=values.shape[0]
i.range(row+1,column).value=sums
workbook.save()
workbook.close()
app.quit()
-
第10行代碼中的index()是Python中列表對象的函數(shù),常用于在列表中查找某個元素的索引位置。該函數(shù)的語法格式和常用參數(shù)含義如下。- 第11行代碼中的shape是pandas模塊中DataFrame對象的一個屬性,它返回的是一個元組,其中有兩個元素,分別代表DataFrame的行數(shù)和列數(shù)。
舉一反三 對一個工作簿中的所有工作表分別求和并將求和結(jié)果寫入固定單元格
-
代碼文件:對一個工作簿中的所有工作表分別求和并將求和結(jié)果寫入固定單元格.py - 數(shù)據(jù)文件:采購表.xlsx
import os
import xlwings as xw
import pandas as pd
app=xw.App(visible=True,add_book=False)
workbook=app.books.open(r'C:\Users\Administrator\Desktop\22\采購表.xlsx')
for i in workbook.sheets:
values=i.range('A1').expand().options(pd.DataFrame).value
sums=values['采購金額'].sum()
i.range('F1').value=sums #將求和后的內(nèi)容寫到F1單元格中
workbook.save()
workbook.close()
app.quit()
案例05 批量統(tǒng)計工作簿的最大值和最小值
-
代碼文件:批量統(tǒng)計工作簿的最大值和最小值.py - 數(shù)據(jù)文件:產(chǎn)品銷售統(tǒng)計表(文件夾) 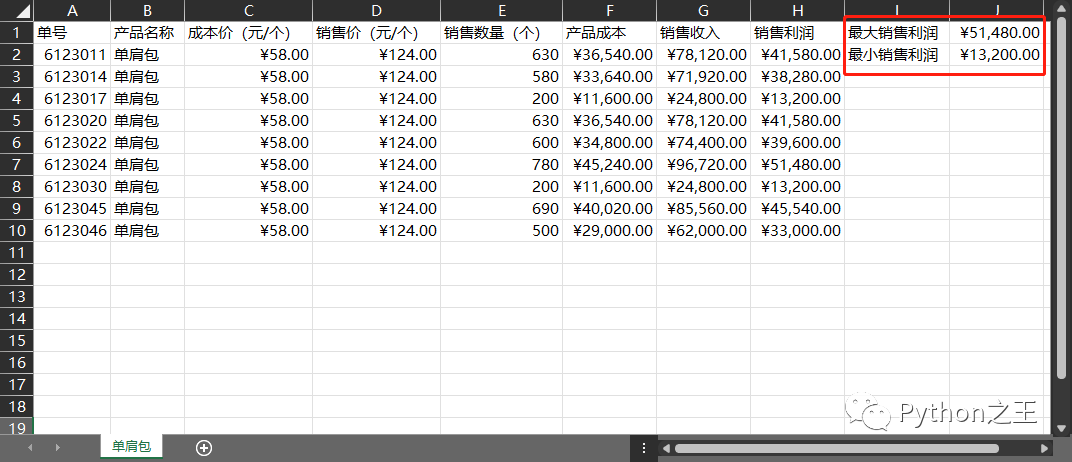
import os
import xlwings as xw
import pandas as pd
app=xw.App(visible=True,add_book=False)
file_path=r'C:\Users\Administrator\Desktop\22\產(chǎn)品銷售統(tǒng)計表'
file_list=os.listdir(file_path)
for j in file_list:
if os.path.splitext(j)[1]=='.xlsx':
file_paths=os.path.join(file_path,j)
workbook=app.books.open(file_paths)
for i in workbook.sheets:
values=i.range('A1').expand().options(pd.DataFrame).value
max0=values['銷售利潤'].max()
min0=values['銷售利潤'].min()
i.range('I1').value='最大銷售利潤'
i.range('J1').value=max0
i.range('I2').value='最小銷售利潤'
i.range('J2').value=min0
i.autofit()
workbook.save()
workbook.close()
app.quit()
舉一反三 批量統(tǒng)計一個工作簿中所有工作表的最大值和最小值
-
代碼文件:批量統(tǒng)計一個工作簿中所有工作表的最大值和最小值.py- 數(shù)據(jù)文件:產(chǎn)品銷售統(tǒng)計表.xlsx
import xlwings as xw
import pandas as pd
app=xw.App(visible=True,add_book=False)
workbook=app.books.open(r'C:\Users\Administrator\Desktop\22\產(chǎn)品銷售統(tǒng)計表.xlsx')
for i in workbook.sheets:
values=i.range('A1').expand().options(pd.DataFrame).value
max0=values['銷售利潤'].max()
min0=values['銷售利潤'].min()
i.range('I3').value='最大銷售利潤'
i.range('J3').value=max0
i.range('I4').value='最小銷售利潤'
i.range('J4').value=min0
i.autofit()
workbook.save()
workbook.close()
app.quit()
案例06 批量制作數(shù)據(jù)透視表
-
代碼文件:批量制作數(shù)據(jù)透視表.py - 數(shù)據(jù)文件:商品銷售表(文件夾) 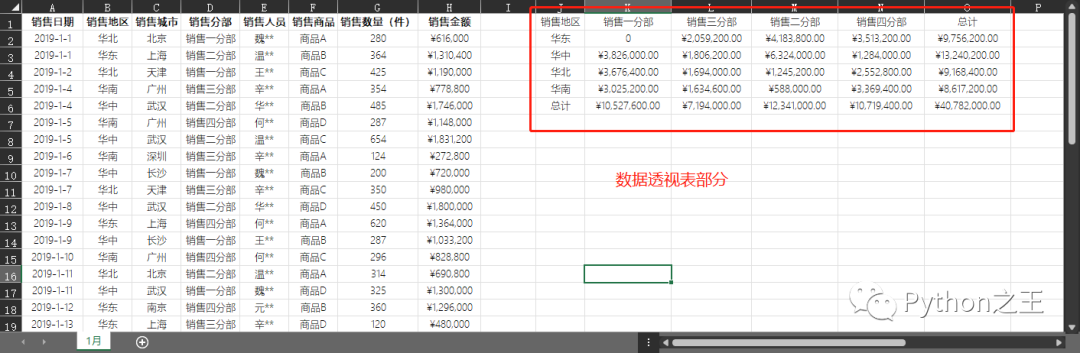
import os
import xlwings as xw
import pandas as pd
app=xw.App(visible=True,add_book=False)
file_path=r'C:\Users\Administrator\Desktop\22\商品銷售表'
file_list=os.listdir(file_path)
for i in file_list:
if os.path.splitext(i)[1]=='.xlsx':
workbook=app.books.open(file_path+'\\'+i)
for j in workbook.sheets:
values=j.range('A1').expand().options(pd.DataFrame).value
pivottable=pd.pivot_table(values,values='銷售金額' #匯總字段為銷售金額
,index='銷售地區(qū)' #指定行字段為銷售地區(qū)
,columns='銷售分部' #列字段為銷售分部
,aggfunc='sum' #匯總計算方式為求和
,fill_value=0 #缺失值填充0
,margins=True #顯示匯總行列
,margins_name='總計' #數(shù)據(jù)行的名稱
)
j.range('J1').value=pivottable
j.autofit()
workbook.save()
workbook.close()
app.quit()
舉一反三 為一個工作簿的所有工作表制作數(shù)據(jù)透視表
-
代碼文件:為一個工作簿的所有工作表制作數(shù)據(jù)透視表.py - 數(shù)據(jù)文件:商品銷售表.xlsx
import os
import xlwings as xw
import pandas as pd
app=xw.App(visible=True,add_book=False)
workbook=app.books.open(r'C:\Users\Administrator\Desktop\22\商品銷售表.xlsx')
for i in workbook.sheets:
values=i.range('A1').expand().options(pd.DataFrame).value
pivottable=pd.pivot_table(values,values='銷售金額' #匯總字段為銷售金額
,index='銷售地區(qū)' #指定行字段為銷售地區(qū)
,columns='銷售分部' #列字段為銷售分部
,aggfunc='sum' #匯總計算方式為求和
,fill_value=0 #缺失值填充0
,margins=True #顯示匯總行列
,margins_name='總計' #數(shù)據(jù)行的名稱
)
i.range('J1').value=pivottable
i.autofit()
workbook.save()
workbook.close()
app.quit()
案例07 使用相關(guān)系數(shù)判斷數(shù)據(jù)的相關(guān)性
-
代碼文件:使用相關(guān)系數(shù)判斷數(shù)據(jù)的相關(guān)性.py - 數(shù)據(jù)文件:相關(guān)性分析.xlsx 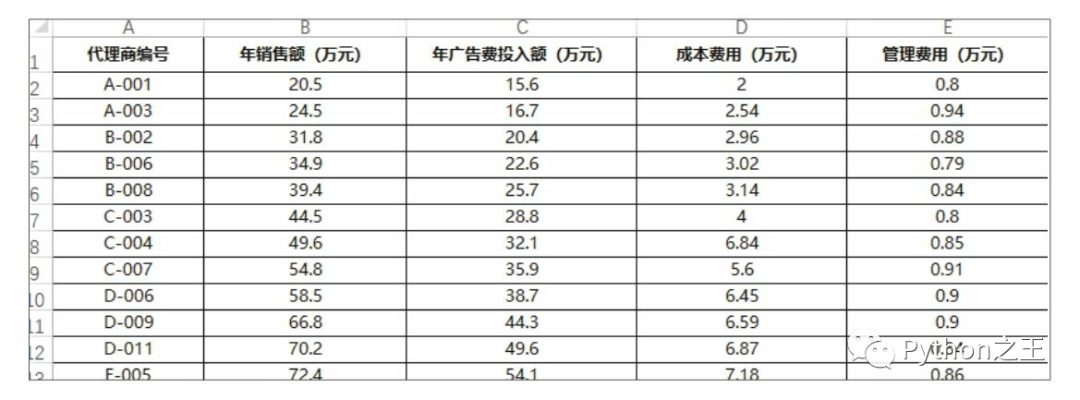
import pandas as pd
df=pd.read_excel(r'C:\Users\Administrator\Desktop\22\相關(guān)性分析.xlsx',index_col='代理商編號')
result=df.corr()
print(result)
運行結(jié)果
-
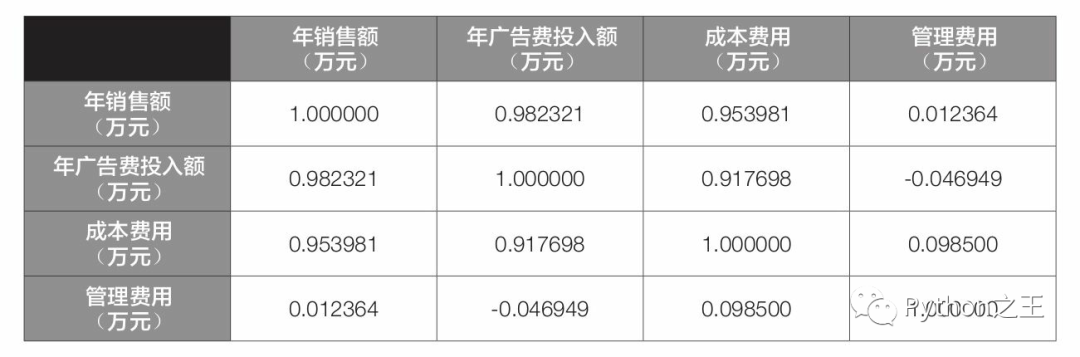 corr()函數(shù)默認計算的是兩個變量之間的皮爾遜相關(guān)系數(shù)。該系數(shù)用于描述兩個變量間線性相關(guān)性的強弱,取值范圍為[-1,1]。系數(shù)為正值表示存在正相關(guān)性,為負值表示存在負相關(guān)性,為0表示不存在線性相關(guān)性。系數(shù)的絕對值越大,說明相關(guān)性越強。- 上表中第1行第2列的數(shù)值0.982321,表示的就是年銷售額與年廣告費投入額的皮爾遜相關(guān)系數(shù),其余單元格中數(shù)值的含義依此類推。需要說明的是,上表中從左上角至右下角的對角線上的數(shù)值都為1,這個1其實沒有什么實際意義,因為它表示的是變量自身與自身的皮爾遜相關(guān)系數(shù),自然是1。- 從上表可以看到,年銷售額與年廣告費投入額、成本費用之間的皮爾遜相關(guān)系數(shù)均接近1,而與管理費用之間的皮爾遜相關(guān)系數(shù)接近0,說明年銷售額與年廣告費投入額、成本費用之間均存在較強的線性正相關(guān)性,而與管理費用之間基本不存在線性相關(guān)性。前面通過直接觀察法得出的結(jié)論是比較準確的。- 第2行代碼中的read_excel()是pandas模塊中的函數(shù),用于讀取工作簿數(shù)據(jù)。3.5.2節(jié)曾簡單介紹過這個函數(shù),這里再詳細介紹一下它的語法格式和常用參數(shù)的含義。- read_excel(io,sheet_name=0,header=0,names=None,index_col=None,usecols=None,squeeze=False,dtype=None)
corr()函數(shù)默認計算的是兩個變量之間的皮爾遜相關(guān)系數(shù)。該系數(shù)用于描述兩個變量間線性相關(guān)性的強弱,取值范圍為[-1,1]。系數(shù)為正值表示存在正相關(guān)性,為負值表示存在負相關(guān)性,為0表示不存在線性相關(guān)性。系數(shù)的絕對值越大,說明相關(guān)性越強。- 上表中第1行第2列的數(shù)值0.982321,表示的就是年銷售額與年廣告費投入額的皮爾遜相關(guān)系數(shù),其余單元格中數(shù)值的含義依此類推。需要說明的是,上表中從左上角至右下角的對角線上的數(shù)值都為1,這個1其實沒有什么實際意義,因為它表示的是變量自身與自身的皮爾遜相關(guān)系數(shù),自然是1。- 從上表可以看到,年銷售額與年廣告費投入額、成本費用之間的皮爾遜相關(guān)系數(shù)均接近1,而與管理費用之間的皮爾遜相關(guān)系數(shù)接近0,說明年銷售額與年廣告費投入額、成本費用之間均存在較強的線性正相關(guān)性,而與管理費用之間基本不存在線性相關(guān)性。前面通過直接觀察法得出的結(jié)論是比較準確的。- 第2行代碼中的read_excel()是pandas模塊中的函數(shù),用于讀取工作簿數(shù)據(jù)。3.5.2節(jié)曾簡單介紹過這個函數(shù),這里再詳細介紹一下它的語法格式和常用參數(shù)的含義。- read_excel(io,sheet_name=0,header=0,names=None,index_col=None,usecols=None,squeeze=False,dtype=None)

-
第3行代碼中的corr()是pandas模塊中DataFrame對象自帶的一個函數(shù),用于計算列與列之間的相關(guān)系數(shù)。該函數(shù)的語法格式和常用參數(shù)含義如下。 
舉一反三 求單個變量和其他變量間的相關(guān)性
-
代碼文件:求單個變量和其他變量間的相關(guān)性.py - 數(shù)據(jù)文件:相關(guān)性分析.xlsx
import pandas as pd
df=pd.read_excel(r'C:\Users\Administrator\Desktop\22\相關(guān)性分析.xlsx',index_col='代理商編號')
result=df.corr()['年銷售額(萬元)']
print(result)
得出以下結(jié)果:
年銷售額(萬元) 1.000000
年廣告費投入額(萬元) 0.982321
成本費用(萬元) 0.953981
管理費用(萬元) 0.012364
Name: 年銷售額(萬元), dtype: float64
案例08 使用方差分析對比數(shù)據(jù)的差異
-
代碼文件:使用方差分析對比數(shù)據(jù)的差異.py - 數(shù)據(jù)文件:方差分析.xlsx 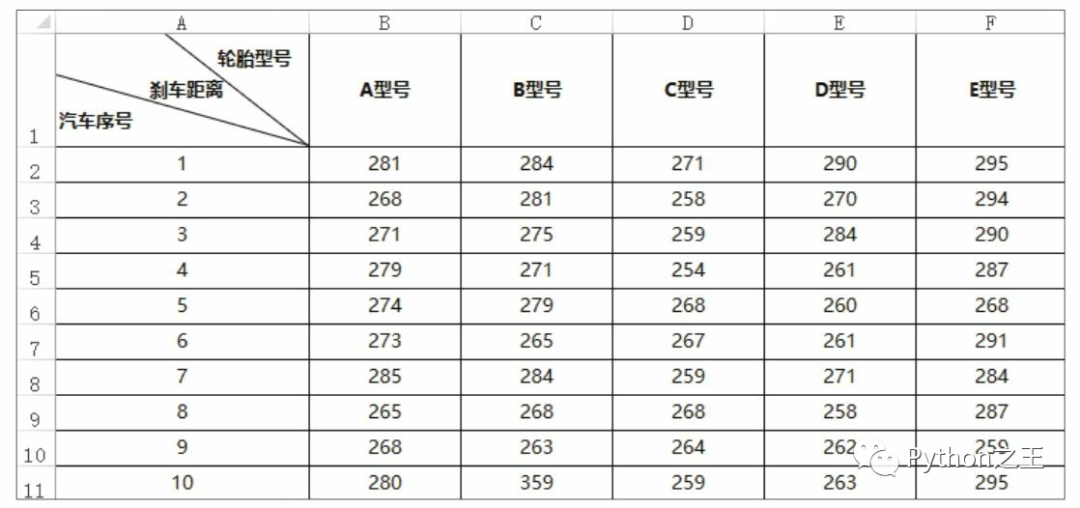 在Python中做方差分析,要用到與方差分析相關(guān)的statsmodels.formula.api模塊和statsmodels.stats.anova模塊,以及ols()函數(shù)和anova_lm()函數(shù)。下面一起來看看具體的代碼。
在Python中做方差分析,要用到與方差分析相關(guān)的statsmodels.formula.api模塊和statsmodels.stats.anova模塊,以及ols()函數(shù)和anova_lm()函數(shù)。下面一起來看看具體的代碼。
import pandas as pd
from statsmodels.formula.api import ols #導(dǎo)入方差分析的模塊
from statsmodels.stats.anova import anova_lm
import xlwings as xw
df=pd.read_excel(r'C:\Users\Administrator\Desktop\22\方差分析.xlsx')
df=df[['A型號','B型號','C型號','D型號','E型號']] #選取ABCDE的型號的列作為分析
df_melt=df.melt() #將列名轉(zhuǎn)換成列數(shù)據(jù)
df_melt.columns=['Treat','Value'] #重命名列名
df_describe=pd.DataFrame()
df_describe['A型號']=df['A型號'].describe() #計算A型號的平均值、最大值、最小值
df_describe['B型號']=df['B型號'].describe() #計算A型號的平均值、最大值、最小值
df_describe['C型號']=df['C型號'].describe() #計算A型號的平均值、最大值、最小值
df_describe['D型號']=df['D型號'].describe() #計算A型號的平均值、最大值、最小值
df_describe['E型號']=df['E型號'].describe() #計算A型號的平均值、最大值、最小值
print(df_describe)
model=ols('Value~C(Treat)',data=df_melt).fit() #對樣本數(shù)據(jù)進行最小二乘現(xiàn)行擬合計算
anova_table=anova_lm(model,typ=3) #對樣本進行方差分析
print(model)
print(anova_table)
app=xw.App(visible=True,add_book=False)
workbook=app.books.open(r'C:\Users\Administrator\Desktop\22\方差分析.xlsx')
worksheet=workbook.sheets['單因素方差分析'] #選中工作表‘單因素方差分析’
worksheet.range('H2').value=df_describe.T #將計算出的平均值、最小值、最大值等數(shù)據(jù)xieru
worksheet.range('H14').value='方差分析'
worksheet.range('H15').value=anova_table #將方差分析的結(jié)果寫入工作表
workbook.save()
workbook.close()
app.quit()
知識延伸
-
第7行代碼中的melt()是pandas模塊中DataFrame對象的函數(shù),用于將列名轉(zhuǎn)換為列數(shù)據(jù),效果如下圖所示,以滿足后續(xù)使用的ols()函數(shù)對數(shù)據(jù)結(jié)構(gòu)的要求。- 第10~14行代碼中的describe()是pandas模塊中DataFrame對象的函數(shù),用于總結(jié)數(shù)據(jù)集分布的集中趨勢,生成描述性統(tǒng)計數(shù)據(jù)。該函數(shù)的語法格式和常用參數(shù)含義如下。- 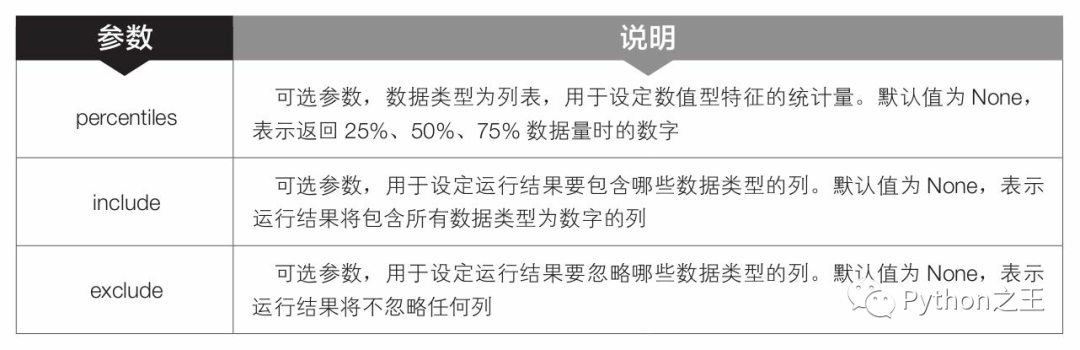 第15行代碼中的ols()是statsmodels.formula.api模塊中的函數(shù),用于對數(shù)據(jù)進行最小二乘線性擬合計算。該函數(shù)的語法格式和常用參數(shù)含義如下。
第15行代碼中的ols()是statsmodels.formula.api模塊中的函數(shù),用于對數(shù)據(jù)進行最小二乘線性擬合計算。該函數(shù)的語法格式和常用參數(shù)含義如下。

-
第16行代碼中的anova_lm()是statsmodels.stats.anova模塊中的函數(shù),用于對數(shù)據(jù)進行方差分析并輸出結(jié)果。該函數(shù)的語法格式和常用參數(shù)含義如下。 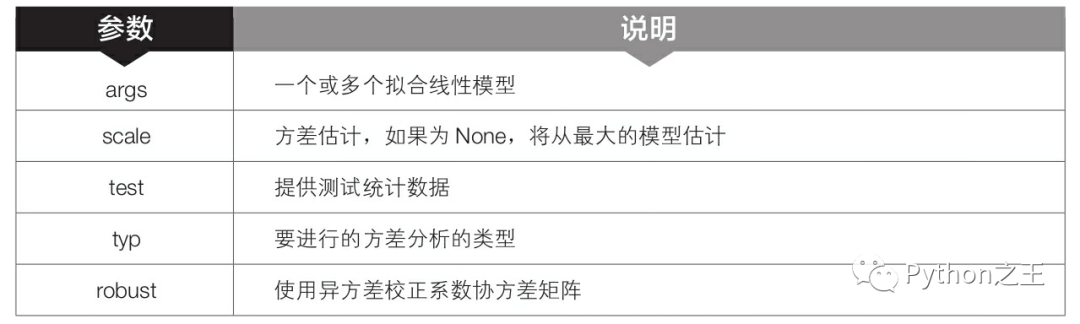
舉一反三 繪制箱形圖識別異常值
-
代碼文件:繪制箱形圖識別異常值.py - 數(shù)據(jù)文件:方差分析.xlsx
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.formula.api import ols #導(dǎo)入方差分析的模塊
from statsmodels.stats.anova import anova_lm
import xlwings as xw
df=pd.read_excel(r'C:\Users\Administrator\Desktop\22\方差分析.xlsx')
df=df[['A型號','B型號','C型號','D型號','E型號']] #選取ABCDE的型號的列作為分析
figure=plt.figure()
plt.rcParams['font.sans-serif']=['SimHei']
df.boxplot(grid=False)
app=xw.App(visible=True,add_book=False)
workbook=app.books.open(r'C:\Users\Administrator\Desktop\22\方差分析.xlsx')
worksheet=workbook.sheets['單因素方差分析'] #選中工作表‘單因素方差分析’
worksheet.pictures.add(figure,name='圖片1',update=True,left=500,top=10)
workbook.save('箱型圖.xlsx')
workbook.close()
app.quit()

案例09 使用描述統(tǒng)計和直方圖制定目標(biāo)
-
代碼文件:使用描述統(tǒng)計和直方圖制定目標(biāo).py - 數(shù)據(jù)文件:描述統(tǒng)計.xlsx 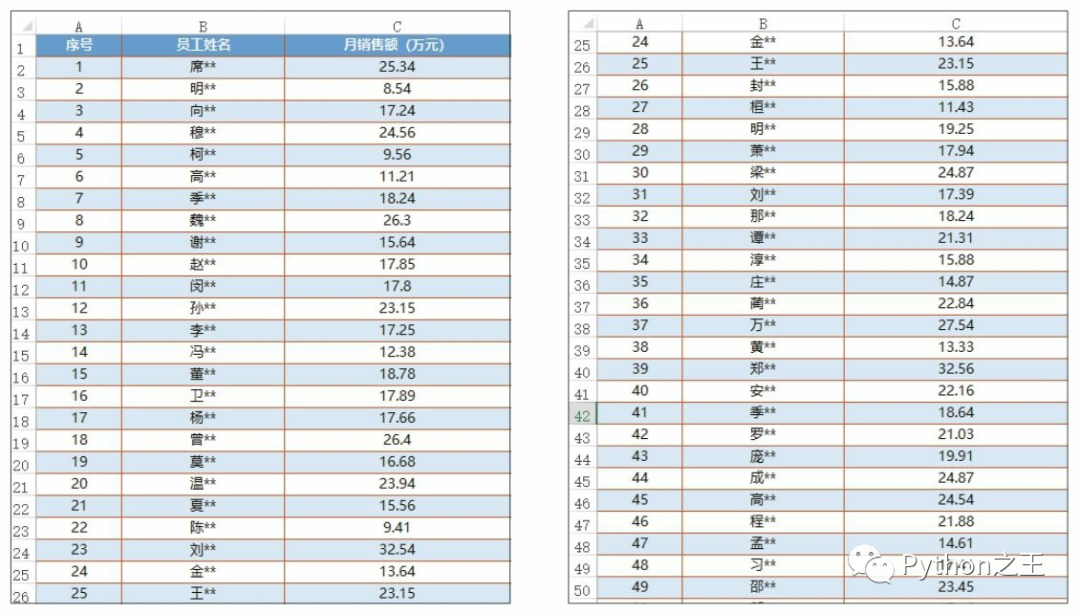
import pandas as pd
import matplotlib.pyplot as plt
import xlwings as xw
#構(gòu)造月銷售額數(shù)據(jù)列
df=pd.read_excel(r'C:\Users\Administrator\Desktop\22\描述統(tǒng)計.xlsx')
df.columns=['序號','員工姓名','月銷售額'] #重命名數(shù)據(jù)列
df=df.drop(columns=['序號','員工姓名']) #刪除序號和員工姓名列
df_describe=df.astype('float').describe() #對月銷售額數(shù)據(jù)進行描述性統(tǒng)計
df_cut=pd.cut(df['月銷售額'],bins=7,precision=2) #將月銷售額分成7個區(qū)間
cut_count=df['月銷售額'].groupby(df_cut).count() #統(tǒng)計各區(qū)間的個數(shù)
df_all=pd.DataFrame() #創(chuàng)建一個空的DateFrame用于匯總數(shù)據(jù)
df_all['計數(shù)']=cut_count
df_all_new=df_all.reset_index() #將索引重置
df_all_new['月銷售額']=df_all_new['月銷售額'].apply(lambda x:str(x)) #將月銷售額轉(zhuǎn)換成字符串類型
#繪圖
fig=plt.figure() #創(chuàng)建繪圖窗口
plt.rcParams['font.sans-serif']=['SimHei'] #解決中文亂碼問題
n,bins,patches=plt.hist(df['月銷售額'],bins=7,edgecolor='black',linewidth=0.5)
plt.xticks(bins) #將直方圖x軸的刻度標(biāo)簽設(shè)置為各區(qū)間的端點值
plt.title('月度銷售額頻率分析') #標(biāo)題
plt.xlabel('月銷售額') #x軸標(biāo)題
plt.ylabel('頻數(shù)') #y軸標(biāo)題
#將圖放進表里
app=xw.App(visible=True,add_book=False)
workbook=app.books.open(r'C:\Users\Administrator\Desktop\22\描述統(tǒng)計.xlsx')
worksheet=workbook.sheets['業(yè)務(wù)員銷售額統(tǒng)計表'] #選中工作表‘單因素方差分析’
worksheet.range('E2').value=df_describe #將描述性統(tǒng)計數(shù)據(jù)寫入表中
worksheet.range('H2').value=df_all_new #將分類后的表寫入表中
worksheet.pictures.add(fig,name='圖片1',update=True,left=400,top=200)
worksheet.autofit()
workbook.save(r'C:\Users\Administrator\Desktop\22\描述統(tǒng)計-直方圖.xlsx')
workbook.close()
app.quit()
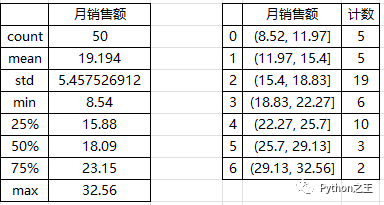
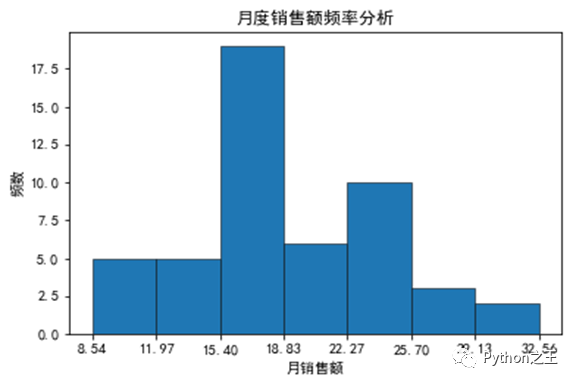
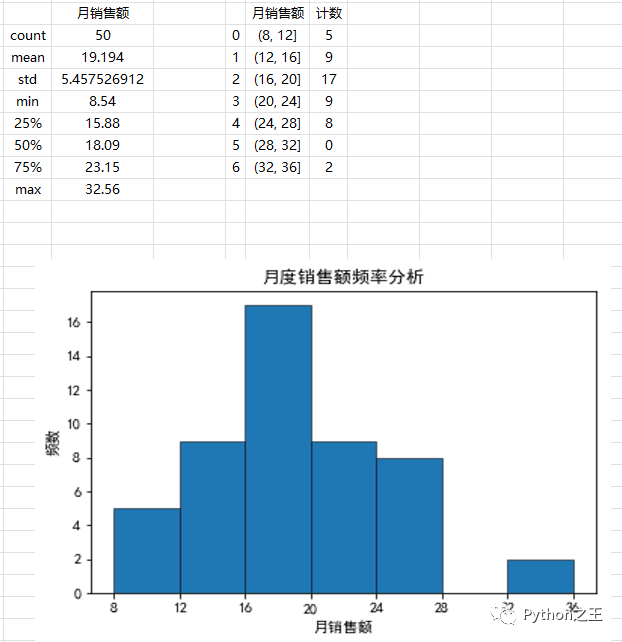
描述統(tǒng)計數(shù)據(jù)中幾個比較重要的值分別為平均值(mean)19.194、標(biāo)準差(std)5.46、中位數(shù)(50%)18.09、最小值8.54、最大值32.56。在工作簿中還可以看到如下圖所示的直方圖,根據(jù)直方圖可以看出,月銷售額基本上以18為基數(shù)向兩邊遞減,即18最普遍。
知識延伸
-
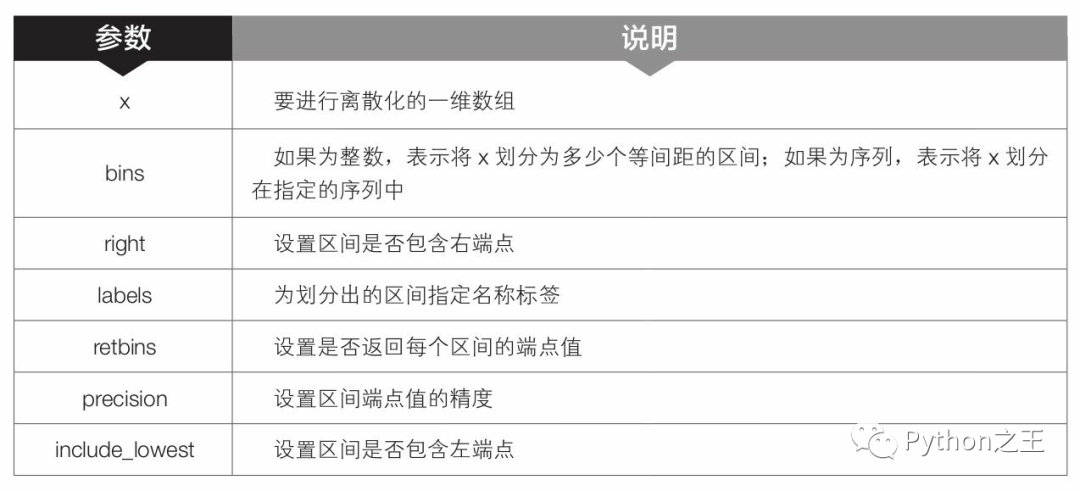
第8行代碼中的cut()是pandas模塊中的函數(shù),用于對數(shù)據(jù)進行離散化處理,也就是將數(shù)據(jù)從最大值到最小值進行等距劃分。該函數(shù)的語法格式和常用參數(shù)含義如下。
df_cut=pd.cut(df['月銷售額'],bins=7,precision=2)
-
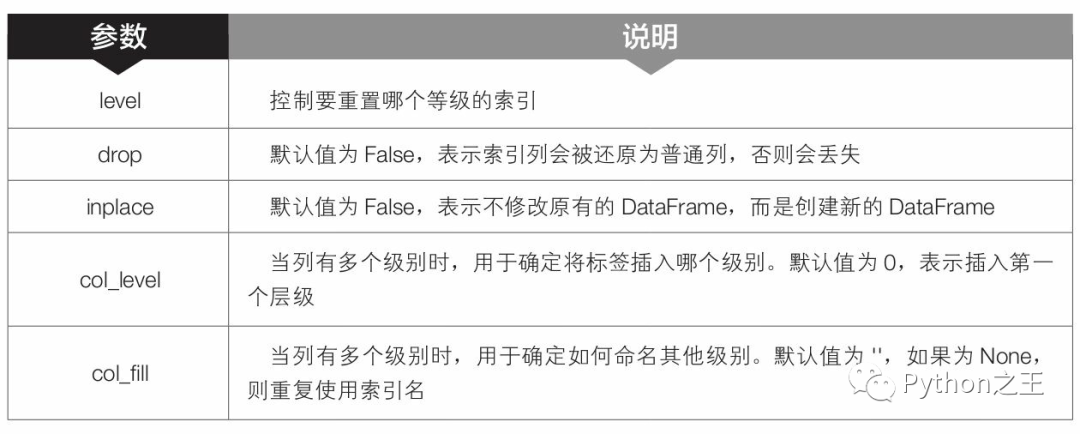
第12行代碼中的reset_index()是pandas模塊中DataFrame對象的函數(shù),用于重置DataFrame對象的索引。在3.5.1節(jié)中曾簡單介紹過reset_index()函數(shù)的用法,這里再詳細介紹一下該函數(shù)的語法格式和常用參數(shù)含義。
df_all_new=df_all.reset_index() #將索引重置
-
第14行代碼中的figure()是matplotlib.pyplot模塊中的函數(shù),用于創(chuàng)建一個繪圖窗口。在3.7.2節(jié)中曾使用過figure()函數(shù),這里再詳細介紹一下該函數(shù)的語法格式和常用參數(shù)含義。- 第16行代碼中的hist()是Matplotlib模塊中的函數(shù),用于繪制直方圖。該函數(shù)的語法格式和常用參數(shù)含義如下。
n,bins,patches=plt.hist(df['月銷售額'],bins=7,edgecolor='black',linewidth=0.5)

舉一反三 使用自定義區(qū)間繪制直方圖
-
代碼文件:使用自定義區(qū)間繪制直方圖.py - 數(shù)據(jù)文件:描述統(tǒng)計.xlsx
import pandas as pd
import matplotlib.pyplot as plt
import xlwings as xw
#構(gòu)造月銷售額數(shù)據(jù)列
df=pd.read_excel(r'C:\Users\Administrator\Desktop\22\描述統(tǒng)計.xlsx')
df.columns=['序號','員工姓名','月銷售額'] #重命名數(shù)據(jù)列
df=df.drop(columns=['序號','員工姓名']) #刪除序號和員工姓名列
df_describe=df.astype('float').describe() #對月銷售額數(shù)據(jù)進行描述性統(tǒng)計
df_cut=pd.cut(df['月銷售額'],bins=range(8,37,4)) #將月銷售額分成7個區(qū)間
cut_count=df['月銷售額'].groupby(df_cut).count() #統(tǒng)計各區(qū)間的個數(shù)
df_all=pd.DataFrame() #創(chuàng)建一個空的DateFrame用于匯總數(shù)據(jù)
df_all['計數(shù)']=cut_count
df_all_new=df_all.reset_index() #將索引重置
df_all_new['月銷售額']=df_all_new['月銷售額'].apply(lambda x:str(x)) #將月銷售額轉(zhuǎn)換成字符串類型
#繪圖
fig=plt.figure() #創(chuàng)建繪圖窗口
plt.rcParams['font.sans-serif']=['SimHei'] #解決中文亂碼問題
n,bins,patches=plt.hist(df['月銷售額'],bins=range(8,37,4),edgecolor='black',linewidth=0.5)
plt.xticks(bins) #將直方圖x軸的刻度標(biāo)簽設(shè)置為各區(qū)間的端點值
plt.title('月度銷售額頻率分析') #標(biāo)題
plt.xlabel('月銷售額') #x軸標(biāo)題
plt.ylabel('頻數(shù)') #y軸標(biāo)題
#將圖放進表里
app=xw.App(visible=True,add_book=False)
workbook=app.books.open(r'C:\Users\Administrator\Desktop\22\描述統(tǒng)計.xlsx')
worksheet=workbook.sheets['業(yè)務(wù)員銷售額統(tǒng)計表'] #選中工作表‘單因素方差分析’
worksheet.range('E2').value=df_describe #將描述性統(tǒng)計數(shù)據(jù)寫入表中
worksheet.range('H2').value=df_all_new #將分類后的表寫入表中
worksheet.pictures.add(fig,name='圖片1',update=True,left=400,top=200)
worksheet.autofit()
workbook.save(r'C:\Users\Administrator\Desktop\22\描述統(tǒng)計-直方圖2.xlsx')
workbook.close()
app.quit()
案例10 使用回歸分析預(yù)測未來值
-
代碼文件:使用回歸分析預(yù)測未來值.py - 數(shù)據(jù)文件:回歸分析.xlsx 
import pandas as pd
from sklearn import linear_model
df=pd.read_excel(r'C:\Users\Administrator\Desktop\22\回歸分析.xlsx')
df=df[1:] #刪除第一行
df.columns=['月份','電視臺廣告費','視頻門戶廣告費','汽車當(dāng)月銷售額'] #重命名
#獲取'電視臺廣告費','視頻門戶廣告費'最為自變量
x=df[['電視臺廣告費','視頻門戶廣告費']]
y=df['汽車當(dāng)月銷售額']
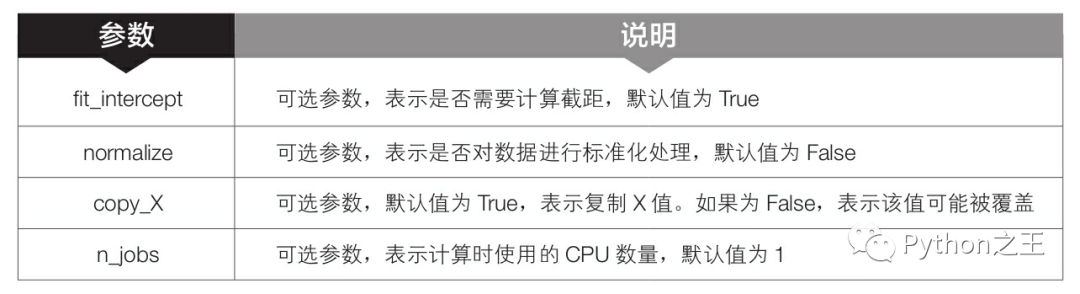
model=linear_model.LinearRegression()
model.fit(x,y)
R2=model.score(x,y)
R2
舉一反三 使用回歸方程計算預(yù)測值
-
代碼文件:使用回歸方程計算預(yù)測值.py - 數(shù)據(jù)文件:回歸分析.xlsx
import pandas as pd
from sklearn import linear_model
df=pd.read_excel(r'C:\Users\Administrator\Desktop\22\回歸分析.xlsx')
df=df[1:] #刪除第一行
df.columns=['月份','電視臺廣告費','視頻門戶廣告費','汽車當(dāng)月銷售額'] #重命名
#獲取'電視臺廣告費','視頻門戶廣告費'最為自變量
x=df[['電視臺廣告費','視頻門戶廣告費']]
y=df['汽車當(dāng)月銷售額']
model=linear_model.LinearRegression()
model.fit(x,y)
coef=model.coef_ #獲取自變量系數(shù)
model_intercept=model.intercept_ #獲取截距
result='y={}+({})x1+({})x2'.format(coef[0],coef[1],model_intercept)
print('線性回歸的方程為:','\n',result)
a=20 #設(shè)置電視廣告費用
b=30 #設(shè)置視頻廣告費
y=model_intercept+a*coef[0]+b*coef[1]
print('電視廣告投放20萬,視頻門戶投放30萬,預(yù)測汽車的銷售額為:','\n',y)
預(yù)測結(jié)果為:
線性回歸的方程為:
y=9.133786669280706+(51.06148377665357)x1+(-316.28885036504175)x2
電視廣告投放20萬,視頻門戶投放30萬,預(yù)測汽車的銷售額為:
1398.2313963201796
參考文獻 《超簡單:用Python讓Excel飛起來》
數(shù)據(jù)下載06:
鏈接:https://pan.baidu.com/s/1KdI7u72sZIcG_C5Y9AtCJw 提取碼:8888

感分割線")
Python“寶藏級”公眾號【Python之王】專注于Python領(lǐng)域,會爬蟲,數(shù)分,C++,tensorflow和Pytorch等等。
近 2年共原創(chuàng) 100+ 篇技術(shù)文章。創(chuàng)作的精品文章系列有:
日常收集整理了一批不錯的 Python 學(xué)習(xí)資料,有需要的小伙可以自行免費領(lǐng)取。
獲取方式如下:公眾號回復(fù)資料。領(lǐng)取Python等系列筆記,項目,書籍,直接套上模板就可以用了。資料包含算法、python、算法小抄、力扣刷題手冊和 C++ 等學(xué)習(xí)資料!