
解惑圖數(shù)據(jù)庫!你知道什么是圖數(shù)據(jù)庫嗎?
作者丨老C
來源丨匠心Java
簡介
為什么需要圖數(shù)據(jù)庫?
設想一個場景:在金融的反欺詐場景下,當一個用戶小李 請求訂單,我們可以設定一個規(guī)則:
獲取該用戶的身份證號、注冊手機號、銀行預留手機號、銀行卡號、緊急聯(lián)系人等信息 通過這些信息去關(guān)聯(lián)包含這些信息的用戶集合 小王、小張、小天通過對關(guān)聯(lián)出的 小王、小張、小天判斷黑名單用戶、逾期用戶、授信拒絕等信息綜合判定一個分數(shù)然后根據(jù)這個分數(shù)對 小李判定是否授信通過;
為了更加有效果我們可以小王、小張、小天作為源用戶列表再獲取這些用戶的2度關(guān)聯(lián)用戶小小、小大,獲取一個綜合評分,和一度關(guān)聯(lián)的用戶綜合評分共同參考,來判定這個userA到底該不該授信通過,借錢給他,如下圖:
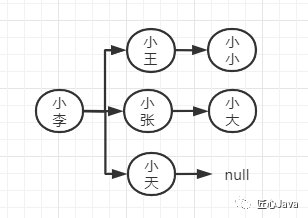
基于上述場景,我們首先先考慮使用關(guān)系型數(shù)據(jù)庫:一個用戶表存儲用戶詳情,上述過程我們需要
從接口入?yún)@取小李的各種信息 通過小李的各種信息去表中查詢出對應數(shù)據(jù) 再根據(jù)查出的一度用戶去表中查詢二度用戶,那如果要查多度呢,如果想要獲取用戶的其他信息呢,就要join,多表join、多次join想想就刺激~
那么,基于圖論的圖數(shù)據(jù)庫就誕生了,詳細的我們下面再介紹,先基于將數(shù)據(jù)存儲到圖庫中,用戶做為節(jié)點、用戶與用戶之間的關(guān)系作為邊、用戶的其他屬性作為節(jié)點的屬性,類似于下圖;
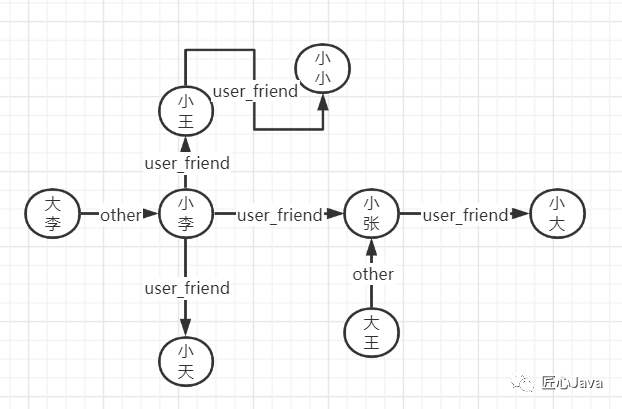
那么用圖庫該怎么查呢?我們就以一種圖庫查詢語言gremlin來實現(xiàn):
g.V().has('user_name',"小李").both("user_friend").both("user_friend").both("user_friend").bothV().has('sex','男')
一句話搞定,不用多次查詢、圖庫幫你搞定~ 多度查詢輕松拈來
ps :具體圖庫底層數(shù)如何存儲、查詢邏輯、圖庫架構(gòu)等 歡迎關(guān)注我~ 后續(xù)系列文章會出~
總結(jié)一下,圖庫在特定場景下的優(yōu)點:
高性能:隨著數(shù)據(jù)量的增多和關(guān)聯(lián)深度的增加,傳統(tǒng)關(guān)系型數(shù)據(jù)庫受制于檢索時需要多個表之間連接操作,數(shù)據(jù)寫入時也需考慮外鍵約束,從而導致較大的額外開銷,產(chǎn)生嚴重的性能問題。而圖模型固有的數(shù)據(jù)索引結(jié)構(gòu),使得它的數(shù)據(jù)查詢與分析速度更快。靈活:圖數(shù)據(jù)庫有非常靈活的數(shù)據(jù)模型,使用者可以根據(jù)業(yè)務變化隨時調(diào)整數(shù)據(jù)模型,比如任意添加或刪除頂點、邊,擴充或者縮小圖模型這些都可以輕松實現(xiàn),這種頻繁的 Schema 更改在關(guān)系型數(shù)據(jù)庫上不能到很好的支持。敏捷:圖數(shù)據(jù)庫的圖模型非常直觀,支持測試驅(qū)動開發(fā)模式,每次構(gòu)建時可進行功能測試和性能測試,符合當今最流行的敏捷開發(fā)需求,對于提高生產(chǎn)和交付效率也有一定幫助。
圖數(shù)據(jù)庫
圖形數(shù)據(jù)庫是NoSQL數(shù)據(jù)庫的一種類型,起源于歐拉理論和圖理論,也可稱為面向/基于圖的數(shù)據(jù)庫,對應的英文是Graph Database。
它應用圖形理論存儲實體之間的關(guān)系信息;圖數(shù)據(jù)庫的基本含義是以“圖”這種數(shù)據(jù)結(jié)構(gòu)做為邏輯結(jié)構(gòu)存儲和查詢數(shù)據(jù)。
我們知道一個圖包含節(jié)點和邊,如下圖:

在圖數(shù)據(jù)庫中圖將實體表現(xiàn)為節(jié)點,實體與其他實體連接的方式表現(xiàn)為聯(lián)系(邊)。我們可以用這個通用的、富有表現(xiàn)力的結(jié)構(gòu)來建模各種場景,從宇宙火箭的建造到道路系統(tǒng),從食物的供應鏈及原產(chǎn)地追蹤到人們的病歷,甚至更多其他的場景。
例如,實體:類似于用戶、用戶的親屬等作為一個節(jié)點存在于圖中,邊:用戶和用戶親屬之間關(guān)聯(lián)的關(guān)系,小李--->小李的父親,這兩個節(jié)點之間的邊可以設定為“用戶父母”的邊;
主流圖數(shù)據(jù)庫
目前主流的圖數(shù)據(jù)庫有:Neo4j,Janusgraph,Dgraph,Giraph,TigerGraph等。
ps : 這里我們只看 database model專用支持graph類型的圖庫
受歡迎程度如下,時間是:2020-5月
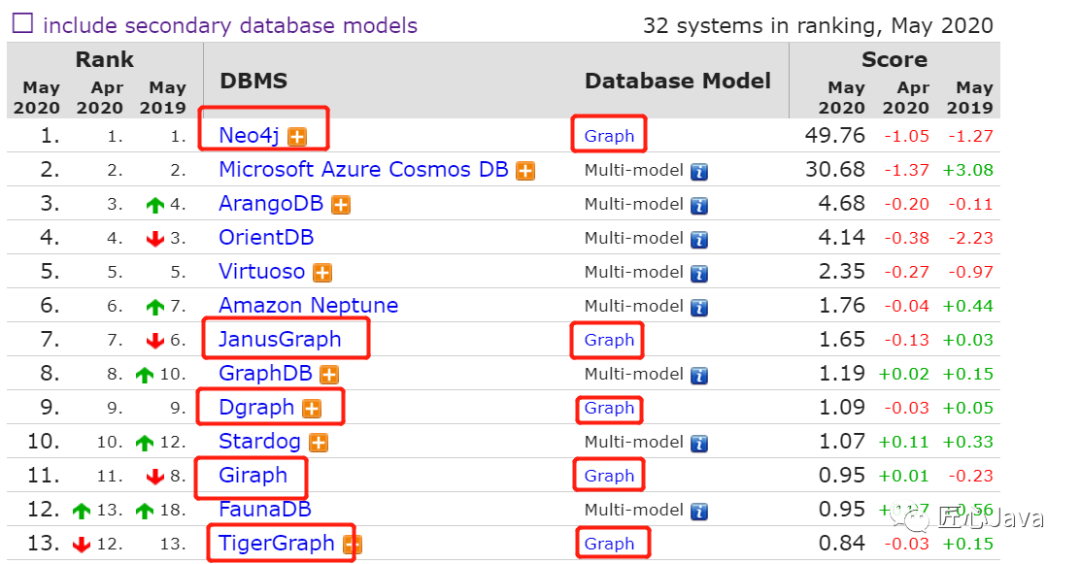
簡單介紹一下Neo4j 和 Janusgraph區(qū)別:
Neo4j:
Neo4J使用原生的圖存儲,以高度自由且規(guī)范的方式管理和存儲數(shù)據(jù)。對比非原生圖解決方案中,隨著信息量的增加,使用面向?qū)ο蟮臄?shù)據(jù)庫存儲數(shù)據(jù)庫使數(shù)據(jù)操作變得越來越慢。 Neo4J可以以每秒一百萬條的驚人速度提供結(jié)果,因為數(shù)據(jù)中的鏈接部分或?qū)嶓w在物理上是已經(jīng)相互連接的。 Neo4J的另一個特點是ACID事務,它確保實時顯示數(shù)據(jù)的合法性和準確性,這是企業(yè)級應用的重要特性。 單擊不收費,集群收費,所以對于不想要花大價錢買的話,這個不推薦;如果不差錢,強烈推薦使用,社群活躍,服務穩(wěn)定,功能強大
Janusgraph:
開源的分布式圖數(shù)據(jù)庫,采用第三方存儲作為底層存儲,如:HBase、Cassandra等 使用第三方框架支持全文匹配、范圍匹配等,如Es等 集群節(jié)點可以線性擴展,以支持更大的圖和更多的并發(fā)訪問用戶。 數(shù)據(jù)分布式存儲,并且每一份數(shù)據(jù)都有多個副本,因此,有更好的計算性能和容錯性。 原生集成Apache TinkerPop圖技術(shù)棧,包括Gremlin graph query language、Gremlin graph server、Gremin applications。 免費開源,我們現(xiàn)在正在使用的就是這個
下面就以JanusGraph為例來初探圖數(shù)據(jù)庫的設計
JanusGraph
可以看下官網(wǎng)上的解釋:
JanusGraph is a scalable graph database optimized for storing and querying graphs containing hundreds of billions of vertices and edges distributed across a multi-machine cluster. JanusGraph is a transactional database that can support thousands of concurrent users executing complex graph traversals in real time.
JanusGraph是一個可擴展的圖形數(shù)據(jù)庫,專門用于存儲和查詢分析分布在多機集群中的數(shù)千億個頂點和關(guān)系邊的圖形。
JanusGraph是一個事務數(shù)據(jù)庫,可以支持數(shù)千個并發(fā)用戶實時執(zhí)行復雜的圖遍歷。
歷史
JanusGraph是2016年12月27日從Titan fork出來的一個分支,之后TiTan的開發(fā)團隊在2017年陸續(xù)發(fā)了0.1.0rc1、0.1.0rc2、0.1.1、0.2.0等四個版本,最新的版本是2017年10月12日。 titan是從2012年開始開發(fā),到2016年停止維護的一個分布式圖數(shù)據(jù)庫。最初在2012年啟動titan項目的公司是Aurelius,2015年此公司被 DataStax(DataStax是開發(fā)apache Cassandra 的公司)收購,DataStax公司吸收了TiTan的圖存儲能力,形成了自己的商業(yè)產(chǎn)品DataStax Enterprise Graph。 TiTan開發(fā)者們希望把TitTan放到Apache Software Foundation下,不過,DataStax不愿意這樣做,而且自從2015年9月DataStax收購了Titan的母公司后,TiTan一直處于停滯狀態(tài),鑒于此,2016年6月,TiTan的開發(fā)者們fork了一個TiTan的分支,重命名為JanusGraph,并將其置于Linux Software Foundation下。 2017年4月6日發(fā)布了第一個版本0.1.0-rc1,目前最新版本是 2020年05月27日發(fā)布的0.6版
JanusGraph項目啟動的初衷是“通過為其增加新功能、改善性能和擴展性、增加后端存儲系統(tǒng)來增強分布式圖系統(tǒng)的功能,從而振興分布式圖系統(tǒng)的開發(fā)”
JanusGraph從Apahce TinkerPop中吸收了對屬性圖模型(Property Graph Model)的支持和對屬性圖模型進行遍歷的Gremlin遍歷語言。
基本概念
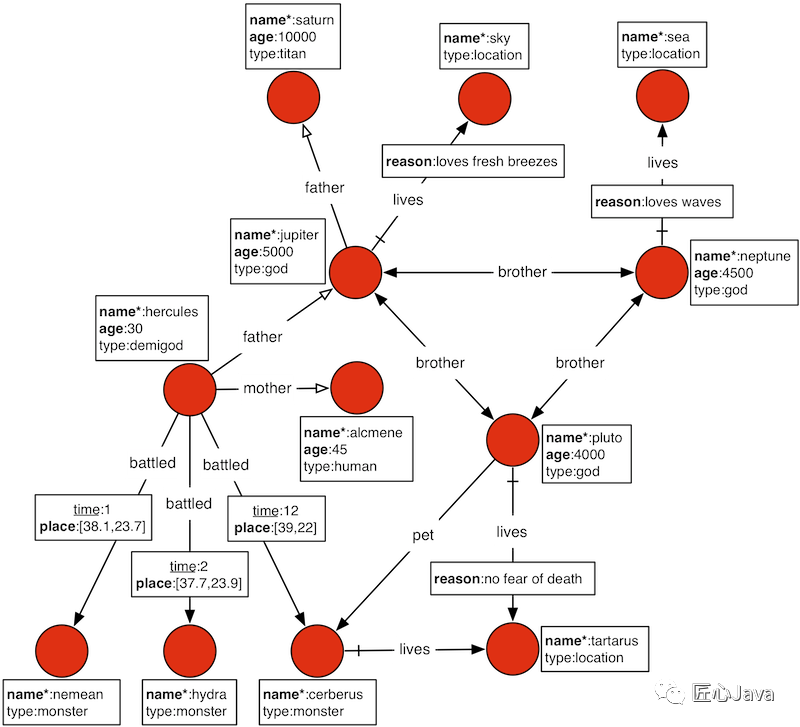
同大多數(shù)圖數(shù)據(jù)庫一樣,JanusGraph采用 屬性圖 進行建模。基于屬性圖的模型,JanusGraph有如下基本概念:
Vertex Label:節(jié)點的類型,用于表示現(xiàn)實世界中的實體類型,比如"人”,“車”。在JanusGraph中,每一個節(jié)點有且只有一個Vertex Label。當不顯式指定Vertex Label時,采用默認的Vertex Label。Vertex:節(jié)點/頂點,用于表示現(xiàn)實世界中的實體對象。Edge Label:邊的類型,用于表示現(xiàn)實世界中的關(guān)系類型,比如“通話關(guān)系”,“轉(zhuǎn)賬關(guān)系”,“微博關(guān)注關(guān)系”等;Edge: 邊,用于表示一個個具體的聯(lián)系。JanusGraph的邊都是單向邊。如果需要雙向邊,則通過兩條相反方向的單向邊組成。JanusGraph不存在無向邊。Property Key:屬性的類型,比如“姓名”,“年齡”,“時間”等。Property Key有Cardinality的概念。Cardinality有SINGLE、LIST和SET三種選項。這三種選項分別用于表示一個Property中,對于同一個Property Key是只允許有一個值、允許多個可重復的值,還是多個不可重復的值。Property:屬性,用于表示一個個具體的附加信息,采用Key-Value結(jié)構(gòu)。Key就是Property Key,Value就是具體的值。
類似于下面這種圖,包含節(jié)點和邊,節(jié)點包含多個屬性:
關(guān)鍵點
彈性和線性可擴展性,適用于不斷增長的數(shù)據(jù)和用戶群。 用于性能和容錯的數(shù)據(jù)分發(fā)和復制。 多數(shù)據(jù)中心高可用性和熱備份。 支持ACID和 最終的一致性。 支持各種存儲后端:Apache Cassandra\Apache HBase \ Google Cloud Bigtable \ Oracle BerkeleyDB 通過與大數(shù)據(jù)平臺集成,支持全局圖形數(shù)據(jù)分析,報告和ETL:Apache Spark\Apache Giraph\ApacheHadoop 支持以下方式進行g(shù)eo、數(shù)據(jù)范圍搜索和全文搜索:ElasticSearch \ Apache Solr \Apache Lucene 與Apache TinkerPop圖形堆棧本機集成:Gremlin圖查詢語言 \ Gremlin圖服務器 \ Gremlin應用程序 Apache 2許可下的開源 工具可視化存儲在JanusGraph中的圖形:Cytoscape \Apache TinkerPop 的 Gephi插件\ Graphexp \ Cambridge Intelligence 的 KeyLines\Linkurious
整體架構(gòu)
JanusGraph是一個圖形數(shù)據(jù)庫引擎,本身專注于緊湊圖形序列化,豐富的圖形數(shù)據(jù)建模和高效的查詢。利用Hadoop進行圖形分析和批處理圖處理。
JanusGraph為數(shù)據(jù)持久性、數(shù)據(jù)索引和客戶端訪問實現(xiàn)了強大的模塊化接口。其模塊化架構(gòu)使其能夠與各種存儲、索引和客戶端技術(shù)進行互操作;模塊化架構(gòu)還簡化了支持新的一個 模塊的流程。
架構(gòu)圖如下:
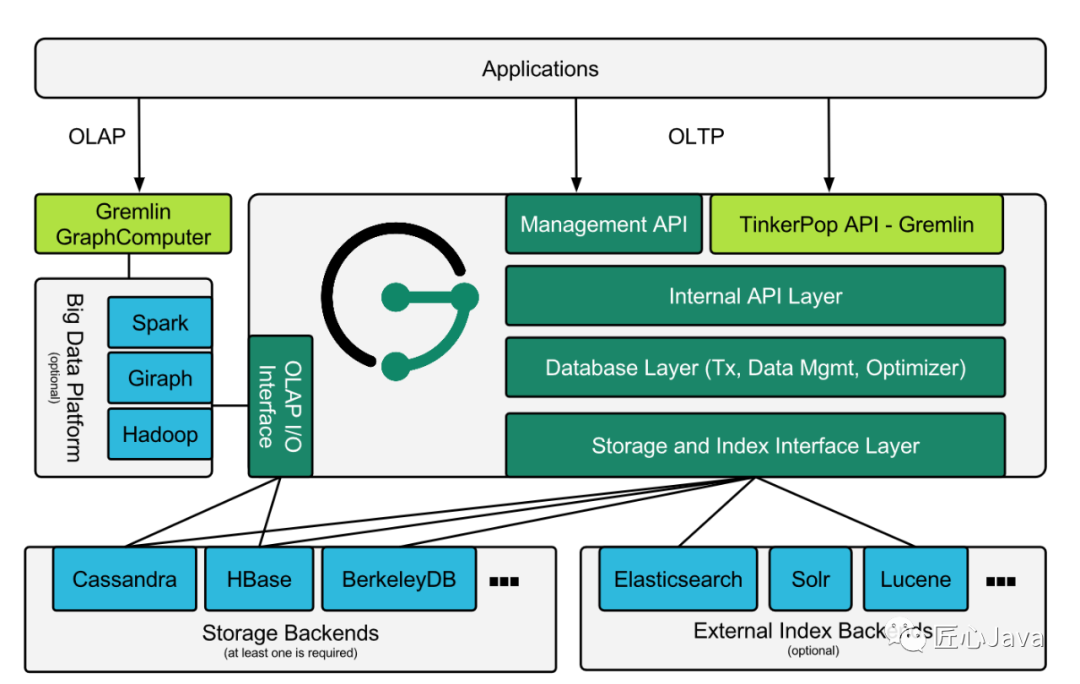
ps:避免篇幅過大,架構(gòu)相關(guān)的信息會在后續(xù)的博文詳細說明
如何使用
作為一個數(shù)據(jù)庫系統(tǒng),它是要用來為應用程序存儲數(shù)據(jù)用的,那么應用程序應該如何使用JanusGraph來為自己存儲數(shù)據(jù)呢?
一般來說,應用程序可以通過兩種不同的方式來使用JanusGraph:
第一種方式:可以把JanusGraph嵌入到應用程序中去,JanusGraph和應用程序處在 同一個JVM中。應用程序中的客戶代碼(相對JanusGraph來說是客戶)直接調(diào)用Gremlin去查詢JanusGraph中存儲的圖,這種情況下外部存儲系統(tǒng)可以是本地的,也可以處在遠程第二種方式:應用程序和Janus Graph處在兩個不同JVM中,應用通過給JanusGraph提交Gremlin查詢給GremlinServer,來使用JanusGraph,因為JanusGraph原生是支持Gremlin Server的。
Gremlin Server是Apache Tinkerpop中的一個組件
JanusGraph集群包含一個、或者多個JanusGraph實例。每次啟動一個JanusGraph實例的時候,都必須指定JanusGraph的配置。
在配置中,可以指定JanusGraph要用的組件,可以控制JanusGraph運行的各個方面,還可以指定一些JanusGraph集群的調(diào)優(yōu)選項:
最小的JanusGraph配置只需要指定一下JanusGraph的后端存儲系統(tǒng),也就是它的持久化引擎。 如果要JanusGraph支持高級的圖查詢,就需要為JanusGraph指定一個索引后端。 若果要提升JanusGraph的查詢性能,就必須為JanusGraph指定緩存,指定性能調(diào)優(yōu)的選項。
以上提到的后端存儲系統(tǒng)、索引后端、緩存、調(diào)優(yōu)選項等都可以在JanusGraph的配置文件中進行指定。默認情況下它的配置文件存放在JanusGraph_home/conf目錄下。
storage.backend=cassandra
storage.hostname=localhost
index.search.backend=elasticsearch
index.search.hostname=
index.search.elasticsearch.client-only=true
也可以在寫測試用例時代碼控制:
/**
* 創(chuàng)建一個JanusGraph實例
* @return JanusGraph的一個實例
*/
private static JanusGraph create() {
try {
return JanusGraphFactory.build()
.set("storage.backend", "hbase")
.set("storage.hostname", "")
.set("storage.port", "")
.set("storage.hbase.table", "")
.set("cache.db-cache", "true")
.set("cache.db-cache-clean-wait", "20")
.set("cache.db-cache-time", "180000")
.set("cache.db-cache-size", "0.5")
.set("index.relationalNetwork.backend", "elasticsearch")
.set("index.relationalNetwork.hostname", "")
.set("index.relationalNetwork.port", 9000)
.open();
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
通過上述代碼,就可以生成一個janusgraph圖實例,通過操作該圖實例來對圖數(shù)據(jù)庫進行操作
總結(jié)
本文介紹了,為什么需要圖數(shù)據(jù)庫,圖數(shù)據(jù)庫的基礎理論,市場上存在的流行的圖數(shù)據(jù)庫并依照janusgraph圖數(shù)據(jù)庫來展開講解一下圖數(shù)據(jù)庫相關(guān)知識等。
-End-
最近有一些小伙伴,讓我?guī)兔φ乙恍?nbsp;面試題 資料,于是我翻遍了收藏的 5T 資料后,匯總整理出來,可以說是程序員面試必備!所有資料都整理到網(wǎng)盤了,歡迎下載!
面試題】即可獲取