
智算中心網(wǎng)絡(luò)架構(gòu)選型及對比
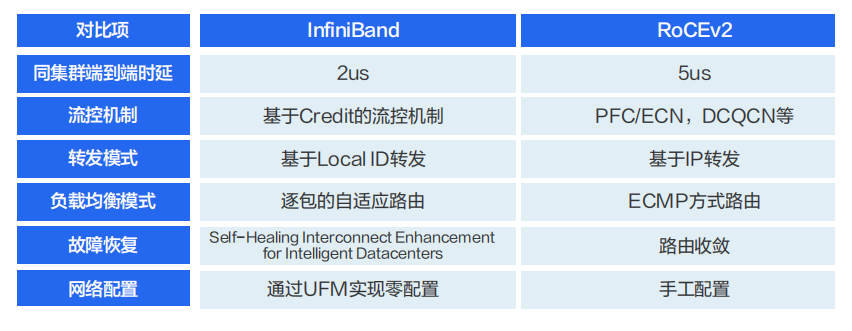

通常,在在AI智算系統(tǒng)中,一個模型從生產(chǎn)到應(yīng)用,一般包括離線訓(xùn)練和推理部署兩大階段;本文選自“智算中心網(wǎng)絡(luò)架構(gòu)白皮書(2023)”“智能計算中心規(guī)劃建設(shè)指南”,常用的對IB和ROCE V2高性能網(wǎng)絡(luò)進行全面的分析對比。
1. 智算網(wǎng)絡(luò)是復(fù)用當前的TCP/IP通用網(wǎng)絡(luò)的基礎(chǔ)設(shè)施,還是新建一張專用的高性能網(wǎng)絡(luò)?
2. 智算網(wǎng)絡(luò)技術(shù)方案采用 InfiniBand 還是 RoCE ?
3. 智算網(wǎng)絡(luò)如何進行運維和管理?
-
4. 智算網(wǎng)絡(luò)是否具備多租戶隔離能力以實現(xiàn)對內(nèi)和對外的運營?
離線訓(xùn)練,就是產(chǎn)生模型的過程。用戶需要根據(jù)自己的任務(wù)場景,準備好訓(xùn)練模型所需要的數(shù)據(jù)集以及神經(jīng)網(wǎng)絡(luò)算法。模型訓(xùn)練開始后,先讀取數(shù)據(jù),然后送入模型進行前向計算,并計算與真實值的誤差。然后執(zhí)行反向計算得到參數(shù)梯度,最后更新參數(shù)。訓(xùn)練過程會進行多輪的數(shù)據(jù)迭代。訓(xùn)練完成之后,保存訓(xùn)練好的模型,然后將模型做上線部署,接受用戶的真實輸入,通過前向計算,完成推理。因此,無論是訓(xùn)練還是推理,核心都是數(shù)據(jù)計算。為了加速計算效率,一般都是通過 GPU 等異構(gòu)加速芯片來進行訓(xùn)練和推理。
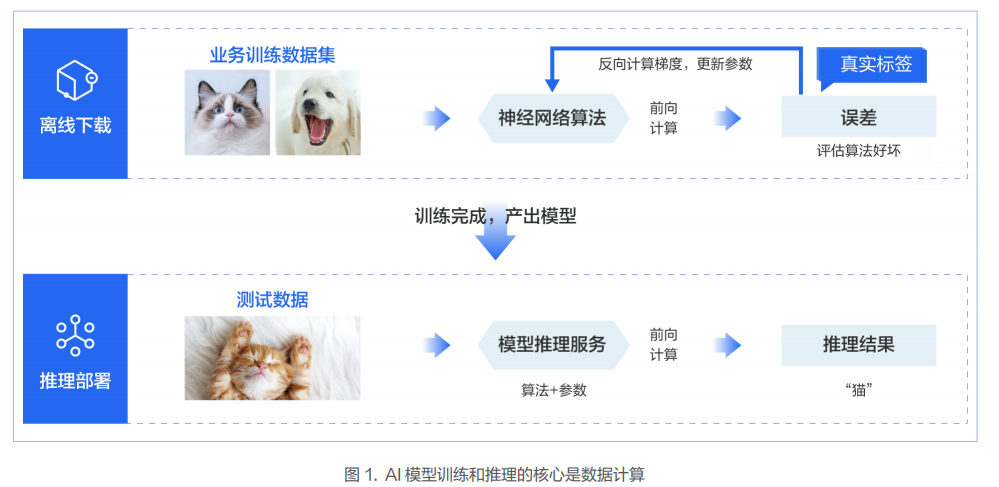
隨著以 GPT3.0 為代表的大模型展現(xiàn)出令人驚艷的能力后,智算業(yè)務(wù)往海量參數(shù)的大模型方向發(fā)展已經(jīng)成為一個主流技術(shù)演進路徑。以自然語言處理(NLP)為例,模型參數(shù)已經(jīng)達到了千億級別。計算機視覺(CV) 、廣告推薦、智能風(fēng)控等領(lǐng)域的模型參數(shù)規(guī)模也在不斷的擴大,正在往百億和千億規(guī)模參數(shù)的方向發(fā)展。
在自動駕駛場景中,每車每日會產(chǎn)生 T 級別數(shù)據(jù),每次訓(xùn)練的數(shù)據(jù)達到 PB 級別。大規(guī)模數(shù)據(jù)處理和大規(guī)模仿真任務(wù)的特點十分顯著,需要使用智算集群來提升數(shù)據(jù)處理與模型訓(xùn)練的效率。
大模型訓(xùn)練中大規(guī)模的參數(shù)對算力和顯存都提出了更高的要求。以GPT3為例,千億參數(shù)需要2TB顯存,當前的單卡顯存容量不夠。即便出現(xiàn)了大容量的顯存,如果用單卡訓(xùn)練的話也需要32年。為了縮短訓(xùn)練時間,通常采用分布式訓(xùn)練技術(shù),對模型和數(shù)據(jù)進行切分,采用多機多卡的方式將訓(xùn)練時長縮短到周或天的級別。

分布式訓(xùn)練就是通過多臺節(jié)點構(gòu)建出一個計算能力和顯存能力超大的集群,來應(yīng)對大模型訓(xùn)練中算力墻和存儲墻這兩個主要挑戰(zhàn)。而聯(lián)接這個超級集群的高性能網(wǎng)絡(luò)直接決定了智算節(jié)點間的通信效率,進而影響整個智算集群的吞吐量和性能。要讓整個智算集群獲得高的吞吐量,高性能網(wǎng)絡(luò)需要具備低時延、大帶寬、長期穩(wěn)定性、大規(guī)模擴展性和可運維幾個關(guān)鍵能力。
分布式訓(xùn)練系統(tǒng)的整體算力并不是簡單的隨著智算節(jié)點的增加而線性增長,而是存在加速比,且加速比小于 1。存在加速比的主要原因是:在分布式場景下,單次的計算時間包含了單卡的計算時間疊加卡間通信時間。因此,降低卡間通信時間,是分布式訓(xùn)練中提升加速比的關(guān)鍵,需要重點考慮和設(shè)計。
降低多機多卡間端到端通信時延的關(guān)鍵技術(shù)是 RDMA 技術(shù)。RDMA 可以繞過操作系統(tǒng)內(nèi)核,讓一臺主機可以直接訪問另外一臺主機的內(nèi)存。
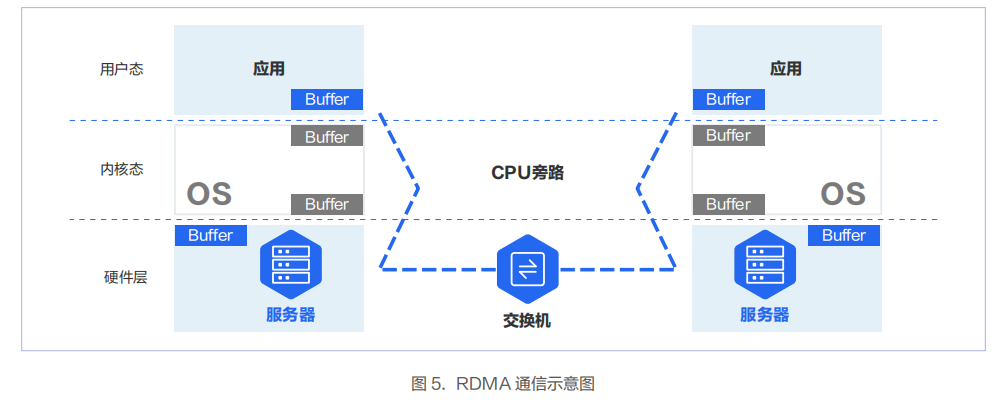
實 現(xiàn) RDMA 的 方 式 有 InfiniBand、RoCEv1、RoCEv2、i WARP 四 種。其 中 RoCEv1 技 術(shù) 當 前 已 經(jīng) 被 淘 汰,iWARP 使用較少。當前 RDMA 技術(shù)主要采用的方案為 InfiniBand 和 RoCEv2 兩種。

在 InfiniBand 和 RoCEv2 方案中,因為繞過了內(nèi)核協(xié)議棧,相較于傳統(tǒng) TCP/IP 網(wǎng)絡(luò),時延性能會有數(shù)十倍的改善。在同集群內(nèi)部一跳可達的場景下,InfiniBand 和 RoCEv2 與傳統(tǒng) IP 網(wǎng)絡(luò)的端到端時延在實驗室的測試數(shù)據(jù)顯示,繞過內(nèi)核協(xié)議棧后,應(yīng)用層的端到端時延可以從 50us(TCP/IP),降低到 5us(RoCE)或 2us(InfiniBand)。

在完成計算任務(wù)后,智算集群內(nèi)部的計算節(jié)點需要將計算結(jié)果快速地同步給其他節(jié)點,以便進行下一輪計算。在結(jié)果同步完成前,計算任務(wù)處于等待狀態(tài),不會進入下一輪計算。如果帶寬不夠大,梯度傳輸就會變慢,造成卡間通信時長變長,進而影響加速比。
要滿足智算網(wǎng)絡(luò)的低時延、大帶寬、穩(wěn)定運行、大規(guī)模以及可運維的需求,目前業(yè)界比較常用的網(wǎng)絡(luò)方案是 InfiniBand方案和 RoCEv2 方案。
一、InfiniBand網(wǎng)絡(luò)介紹
InfiniBand網(wǎng)絡(luò)的關(guān)鍵組成包括Subnet Manager(SM)、InfiniBand 網(wǎng)卡、InfiniBand交換機和InfiniBand連接線纜。
支持 InfiniBand 網(wǎng)卡的廠家以 NVIDIA 為主。下圖是當前常見的 InfiniBand 網(wǎng)卡。InfiniBand 網(wǎng)卡在速率方面保持著快速的發(fā)展。200Gbps 的 HDR 已經(jīng)實現(xiàn)了規(guī)模化的商用部署,400Gbps 的 NDR的網(wǎng)卡也已經(jīng)開始商用部署。

在InfiniBand交換機中,SB7800 為 100Gbps 端口交換機(36*100G),屬于 NVIDIA 比較早的一代產(chǎn)品。Quantum-1 系列為 200Gbps 端口交換機(40*200G),是當前市場采用較多的產(chǎn)品。
在 2021 年,NVIDIA 推出了 400Gbps 的 Quantum-2 系列交換機(64*400G)。交換機上有 32 個 800G OSFP(Octal Small Form Factor Pluggable)口,需要通過線纜轉(zhuǎn)接出 64 個 400G QSFP。
InfiniBand 交換機上不運行任何路由協(xié)議。整個網(wǎng)絡(luò)的轉(zhuǎn)發(fā)表是由集中式的子網(wǎng)管理器(Subnet Manager,簡稱 SM)進行計算并統(tǒng)一下發(fā)的。除了轉(zhuǎn)發(fā)表以外,SM 還負責(zé)管理 InfiniBand 子網(wǎng)的 Partition、QoS 等配置。InfiniBand 網(wǎng)絡(luò)需要專用的線纜和光模塊做交換機間的互聯(lián)以及交換機和網(wǎng)卡的互聯(lián)。
InfiniBand 網(wǎng)絡(luò)方案特點
(1)原生無損網(wǎng)絡(luò)
InfiniBand 網(wǎng)絡(luò)采用基于 credit 信令機制來從根本上避免緩沖區(qū)溢出丟包。只有在確認對方有額度能接收對應(yīng)數(shù)量的報文后,發(fā)送端才會啟動報文發(fā)送。InfiniBand 網(wǎng)絡(luò)中的每一條鏈路都有一個預(yù)置緩沖區(qū)。發(fā)送端一次性發(fā)送數(shù)據(jù)不會超過接收端可用的預(yù)置緩沖區(qū)大小,而接收端完成轉(zhuǎn)發(fā)后會騰空緩沖區(qū),并且持續(xù)向發(fā)送端返回當前可用的預(yù)置緩沖區(qū)大小。依靠這一鏈路級的流控機制,可以確保發(fā)送端絕不會發(fā)送過量,網(wǎng)絡(luò)中不會產(chǎn)生緩沖區(qū)溢出丟包。
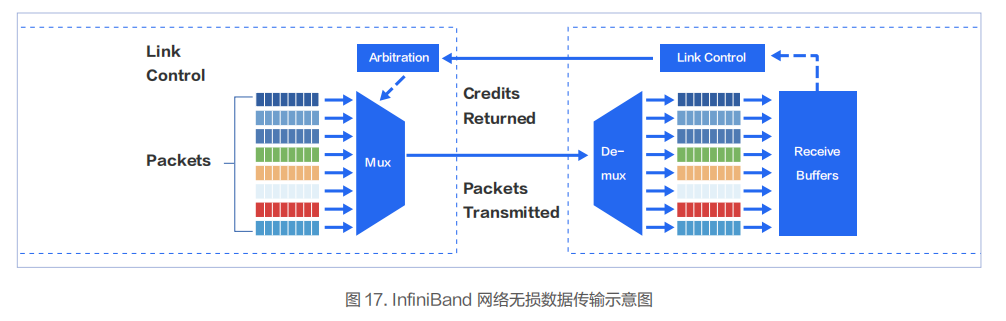
(2)萬卡擴展能力
InfiniBand 的 Adaptive Routing 基于逐包的動態(tài)路由,在超大規(guī)模組網(wǎng)的情況下保證網(wǎng)絡(luò)最優(yōu)利用。InfiniBand 網(wǎng)絡(luò)在業(yè)界有較多的萬卡規(guī)模超大 GPU 集群的案例,包括百度智能云,微軟云等。
目前市場上主要的 InfiniBand 網(wǎng)絡(luò)方案及配套設(shè)備供應(yīng)商有以下幾家。其中,市場占有率最高的是 NVIDIA,其市場份額大于 7 成。
NVIDIA:NVIDIA是InfiniBand技術(shù)的主要供應(yīng)商之一,提供各種InfiniBand適配器、交換機和其他相關(guān)產(chǎn)品。
Intel Corporation:Intel是另一個重要的InfiniBand供應(yīng)商,提供各種InfiniBand網(wǎng)絡(luò)產(chǎn)品和解決方案。
Cisco Systems:Cisco是一家知名的網(wǎng)絡(luò)設(shè)備制造商,也提供InfiniBand交換機和其他相關(guān)產(chǎn)品。
Hewlett Packard Enterprise:HPE是一家大型IT公司,提供各種InfiniBand網(wǎng)絡(luò)解決方案和產(chǎn)品,包括適配器、交換機和服務(wù)器等。
2、RoCEv2 網(wǎng)絡(luò)介紹
InfiniBand 網(wǎng)絡(luò)在一定程度上是一個由 SM(Subnet Manager,子網(wǎng)管理器)進行集中管理的網(wǎng)絡(luò)。而 RoCEv2 網(wǎng)絡(luò)則是一個純分布式的網(wǎng)絡(luò),由支持 RoCEv2 的網(wǎng)卡和交換機組成,一般情況下是兩層架構(gòu)。
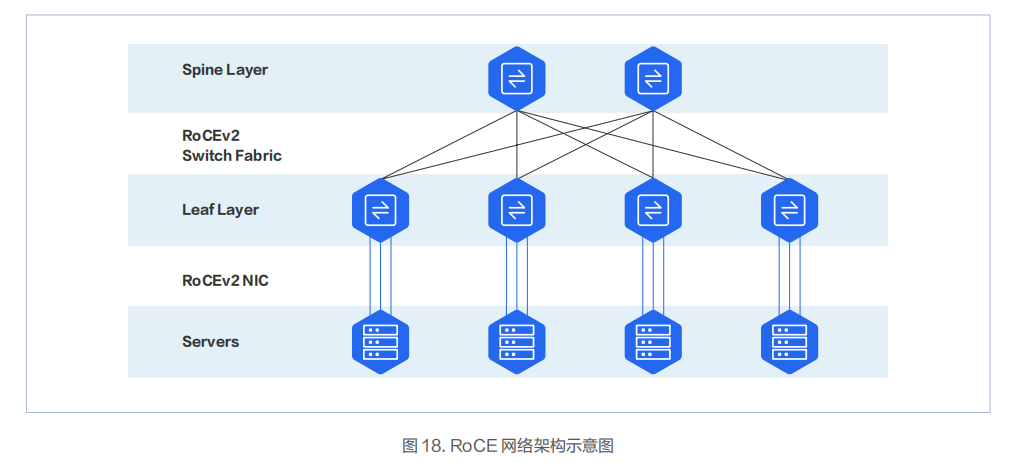
支持 RoCE 網(wǎng)卡的廠家比較多,主流廠商為 NVIDIA、Intel、Broadcom。數(shù)據(jù)中心服務(wù)器網(wǎng)卡主要以 PCIe 卡為主。RDMA 網(wǎng)卡的端口 PHY 速率一般是 50Gbps 起,當前商用的網(wǎng)卡單端口速率已達 400Gbps。

當前大部分數(shù)據(jù)中心交換機都支持 RDMA 流控技術(shù),和 RoCE 網(wǎng)卡配合,實現(xiàn)端到端的 RDMA 通信。國內(nèi)的主流數(shù)據(jù)中心交換機廠商包括華為、新華三等。
高性 能 交 換 機的核心 是 轉(zhuǎn)發(fā) 芯片。當前 市場上的商用轉(zhuǎn)發(fā) 芯片用的比 較 多的是博通的 Tomahawk 系列芯片。其中Tomahawk3 系列的芯片在當前交換機上使用的比較多,市場上支持 Tomahawk4 系列的芯片的交換機也逐漸增多。
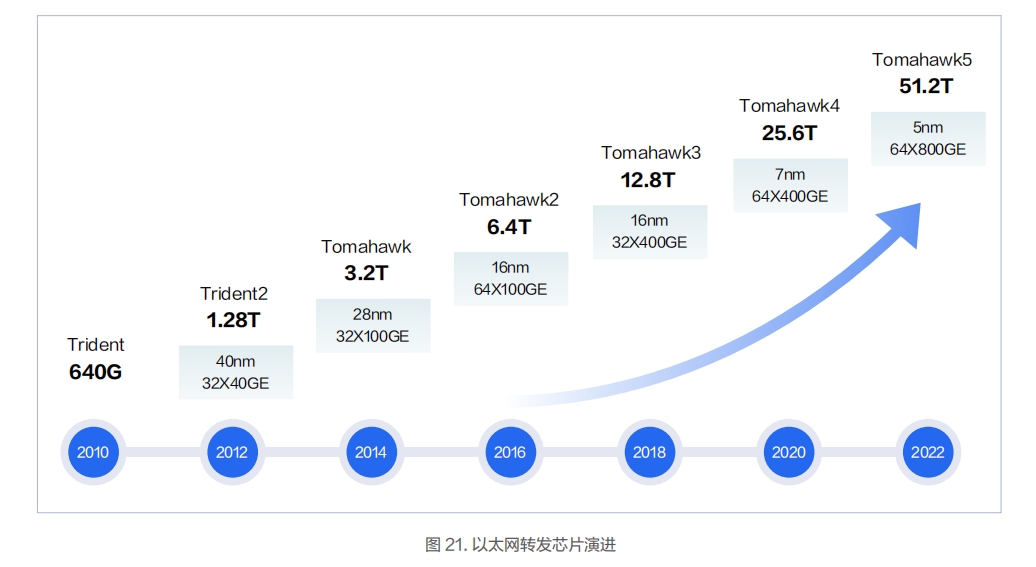
RoCEv2 承載在以太網(wǎng)上,所以傳統(tǒng)以太網(wǎng)的光纖和光模塊都可以用。
RoCEv2 網(wǎng)絡(luò)方案特點
RoCE 方案相對于 InfiniBand 方案的特點是通用性較強和價格相對較低。除用于構(gòu)建高性能 RDMA 網(wǎng)絡(luò)外,還可以在傳統(tǒng)的以太網(wǎng)絡(luò)中使用。但在交換機上的 Headroom、PFC、ECN 相關(guān)參數(shù)的配置是比較復(fù)雜的。在萬卡這種超大規(guī)模場景下,整個網(wǎng)絡(luò)的吞吐性能較 InfiniBand 網(wǎng)絡(luò)要弱一些。
支持 RoCE 的交換機廠商較多,市場占有率排名靠前的包括新華三、華為等。支持 RoCE 的網(wǎng)卡當前市場占有率比較高的是 NVIDIA 的 ConnectX 系列的網(wǎng)卡。
3、InfiniBand 和 RoCEv2網(wǎng)絡(luò)方案對比
從技術(shù)角度看,InfiniBand 使用了較多的技術(shù)來提升網(wǎng)絡(luò)轉(zhuǎn)發(fā)性能,降低故障恢復(fù)時間,提升擴展能力,降低運維復(fù)雜度。
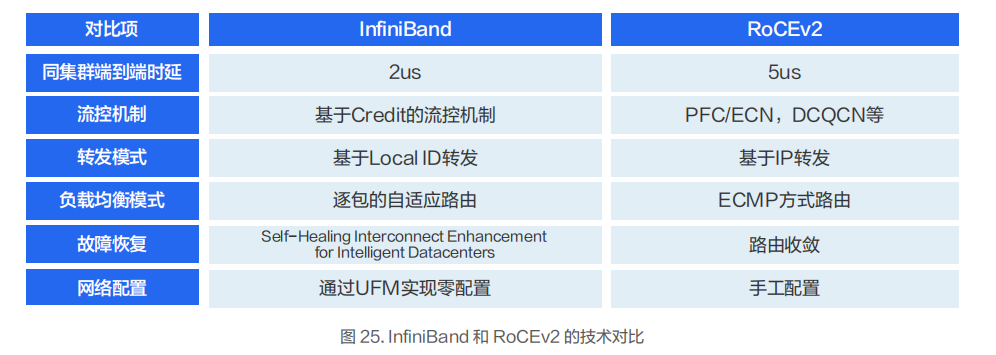
具體到實際業(yè)務(wù)場景上看,RoCEv2 是足夠好的方案,而 InfiniBand 是特別好的方案。
業(yè)務(wù)性能方面:由于 InfiniBand 的端到端時延小于 RoCEv2,所以基于 InfiniBand 構(gòu)建的網(wǎng)絡(luò)在應(yīng)用層業(yè)務(wù)性能方面占優(yōu)。但 RoCEv2 的性能也能滿足絕大部分智算場景的業(yè)務(wù)性能要求。
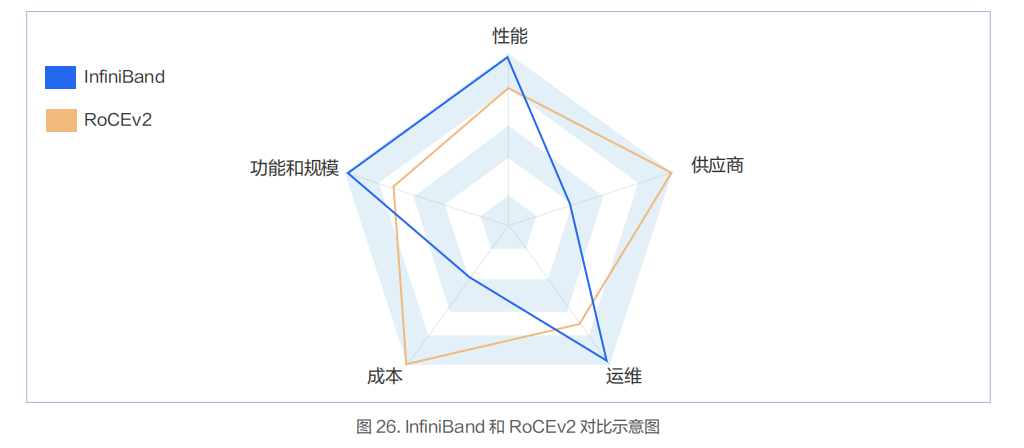
業(yè)務(wù)規(guī)模方面: InfiniBand 能支持單集群萬卡 GPU 規(guī)模,且保證整體性能不下降,并且在業(yè)界有比較多的商用實踐案例。RoCEv2 網(wǎng)絡(luò)能在單集群支持千卡規(guī)模且整體網(wǎng)絡(luò)性能也無太大的降低。
業(yè)務(wù)運維方面: InfiniBand 較 RoCEv2 更成熟,包括多租戶隔離能力,運維診斷能力等。
業(yè)務(wù)成本方面: InfiniBand 的成本要高于 RoCEv2,主要是 InfiniBand 交換機的成本要比以太交換機高一些。
業(yè)務(wù)供應(yīng)商方面: InfiniBand 的供應(yīng)商主要以 NVIDIA 為主,RoCEv2 的供應(yīng)商較多。
本文選自“智算中心網(wǎng)絡(luò)架構(gòu)白皮書(2023)”“智能計算中心規(guī)劃建設(shè)指南”,更多智算中心技術(shù)請參考“算力鑄就大模型:超算、智算及數(shù)據(jù)中心行業(yè)報告(2023)、2023年高性能計算研討合集(上)、2023年高性能計算研討合集(下)、AI基礎(chǔ)知識深度專題詳解合集等”。
下載鏈接:
1、人工智能專題研究(1):大模型推動各行業(yè)AI應(yīng)用滲透 2、人工智能專題研究(2):AI大模型打開AI芯片、光模塊和光芯片需求
1、AI系列專題研究報告:臺股AI服務(wù)器啟示錄(2023) 2、AI專題研究報告:AI算力研究框架(2023)
智算中心網(wǎng)絡(luò)架構(gòu)白皮書(2023)
本號資料全部上傳至知識星球,更多內(nèi)容請登錄智能計算芯知識(知識星球)星球下載全部資料。

免責(zé)申明:本號聚焦相關(guān)技術(shù)分享,內(nèi)容觀點不代表本號立場,可追溯內(nèi)容均注明來源,發(fā)布文章若存在版權(quán)等問題,請留言聯(lián)系刪除,謝謝。
溫馨提示:
請搜索“AI_Architect”或“掃碼”關(guān)注公眾號實時掌握深度技術(shù)分享,點擊“閱讀原文”獲取更多原創(chuàng)技術(shù)干貨。
