
手把手教你使用Python網(wǎng)絡(luò)爬蟲(chóng)下載一本小說(shuō)(附源碼)
回復(fù)“書(shū)籍”即可獲贈(zèng)Python從入門(mén)到進(jìn)階共10本電子書(shū)
????大家好,我是Python進(jìn)階者。
前言
? 前幾天【磐奚鳥(niǎo)】大佬在群里分享了一個(gè)抓取小說(shuō)的代碼,感覺(jué)還是蠻不錯(cuò)的,這里分享給大家學(xué)習(xí)。

一、小說(shuō)下載
????如果你想下載該網(wǎng)站上的任意一本小說(shuō)的話,直接點(diǎn)擊鏈接進(jìn)去,如下圖所示。

????只要將URL中的這個(gè)數(shù)字拿到就可以了,比方說(shuō)這里是951,那么這個(gè)數(shù)字代表的就是這本書(shū)的書(shū)號(hào),在后面的代碼中可以用得到的。
二、具體實(shí)現(xiàn)
????這里直接丟大佬的代碼了,如下所示:
#?coding: utf-8'''筆趣網(wǎng)小說(shuō)下載僅限用于研究代碼勿用于商業(yè)用途請(qǐng)于24小時(shí)內(nèi)刪除'''import requestsimport osfrom bs4 import BeautifulSoupimport timedef book_page_list(book_id):'''通過(guò)傳入的書(shū)號(hào)bookid,獲取此書(shū)的所有章節(jié)目錄:param book_id::return: 章節(jié)目錄及章節(jié)地址'''url = 'http://www.biquw.com/book/{}/'.format(book_id)headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36'}response = requests.get(url, headers)response.encoding = response.apparent_encodingresponse = BeautifulSoup(response.text, 'lxml')booklist = response.find('div', class_='book_list').find_all('a')return booklistdef book_page_text(bookid, booklist):'''通過(guò)書(shū)號(hào)、章節(jié)目錄,抓取每一章的內(nèi)容并存檔:param bookid:str:param booklist::return:None'''try:for book_page in booklist:page_name = book_page.text.replace('*', '')page_id = book_page['href']time.sleep(3)url = 'http://www.biquw.com/book/{}/{}'.format(bookid,page_id)headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36'}response_book = requests.get(url, headers)response_book.encoding = response_book.apparent_encodingresponse_book = BeautifulSoup(response_book.text, 'lxml')book_content = response_book.find('div', id="htmlContent")with open("./{}/{}.txt".format(bookid,page_name), 'a') as f:f.write(book_content.text.replace('\xa0', ''))print("當(dāng)前下載章節(jié):{}".format(page_name))except Exception as e:print(e)print("章節(jié)內(nèi)容獲取失敗,請(qǐng)確保書(shū)號(hào)正確,及書(shū)本有正常內(nèi)容。")if __name__ == '__main__':bookid = input("請(qǐng)輸入書(shū)號(hào)(數(shù)字):")# 如果書(shū)號(hào)對(duì)應(yīng)的目錄不存在,則新建目錄,用于存放章節(jié)內(nèi)容if not os.path.isdir('./{}'.format(bookid)):os.mkdir('./{}'.format(bookid))try:booklist = book_page_list(bookid)print("獲取目錄成功!")time.sleep(5)book_page_text(bookid, booklist)except Exception as e:print(e)????????print("獲取目錄失敗,請(qǐng)確保書(shū)號(hào)輸入正確!")
程序運(yùn)行之后,在控制臺(tái)輸入書(shū)號(hào),即可開(kāi)始進(jìn)行抓取了。
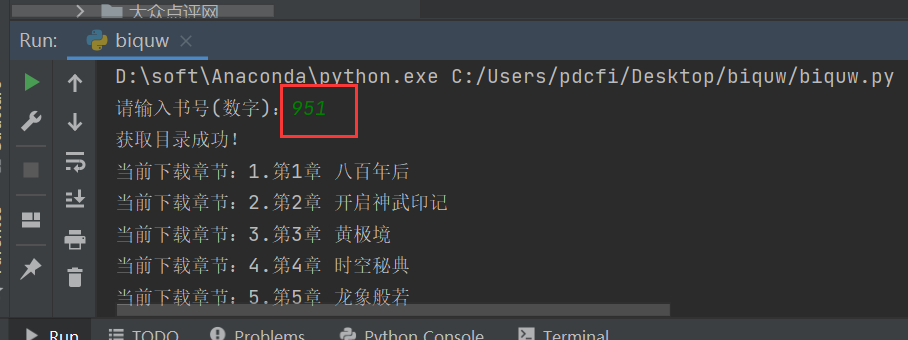
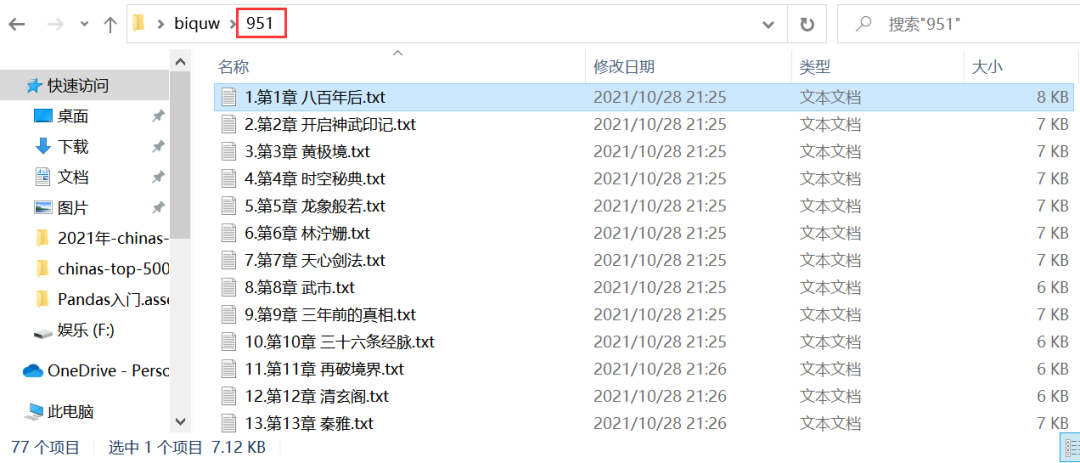
在本地也會(huì)自動(dòng)新建一個(gè)書(shū)號(hào)命名的文件夾,在該文件夾下,會(huì)存放小說(shuō)的章節(jié),如下圖所示。
三、常見(jiàn)問(wèn)題
????在運(yùn)行過(guò)程中小伙伴們應(yīng)該會(huì)經(jīng)常遇到這個(gè)問(wèn)題,如下圖所示。
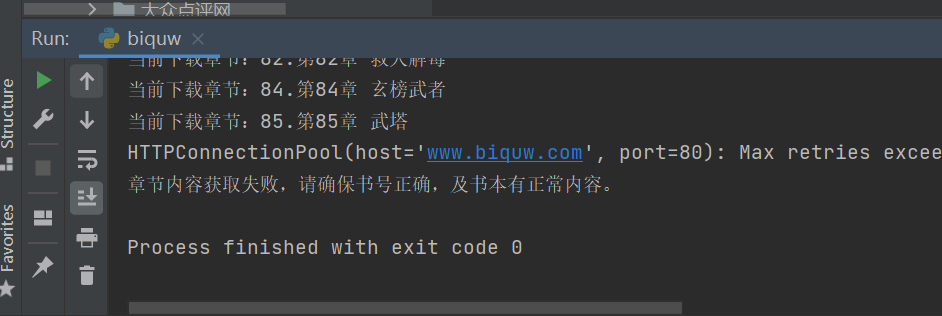
????這個(gè)是因?yàn)樵L問(wèn)太快,網(wǎng)站給你反爬了。可以設(shè)置隨機(jī)的user-agent或者上代理等方法解決。

四、總結(jié)
??? 我是Python進(jìn)階者。這篇文章主要給大家介紹了小說(shuō)內(nèi)容的獲取方法,基于網(wǎng)絡(luò)爬蟲(chóng),通過(guò)requests爬蟲(chóng)庫(kù)和bs4選擇器進(jìn)行實(shí)現(xiàn),并且給大家例舉了常見(jiàn)問(wèn)題的處理方法。
????小伙伴們,快快用實(shí)踐一下吧!如果在學(xué)習(xí)過(guò)程中,有遇到任何問(wèn)題,歡迎加我好友,我拉你進(jìn)Python學(xué)習(xí)交流群共同探討學(xué)習(xí)。
????本文僅僅做代碼學(xué)習(xí)交流分享,大家切勿爬蟲(chóng)成疾,在爬蟲(chóng)的時(shí)候,也盡可能的選擇晚上進(jìn)行,設(shè)置多的睡眠,爬蟲(chóng)適可而止,千萬(wàn)別對(duì)對(duì)方服務(wù)器造成過(guò)壓,謹(jǐn)記!謹(jǐn)記!謹(jǐn)記!
-------------------?End?-------------------
往期精彩文章推薦:

歡迎大家點(diǎn)贊,留言,轉(zhuǎn)發(fā),轉(zhuǎn)載,感謝大家的相伴與支持
想加入Python學(xué)習(xí)群請(qǐng)?jiān)诤笈_(tái)回復(fù)【入群】
萬(wàn)水千山總是情,點(diǎn)個(gè)【在看】行不行
/今日留言主題/
隨便說(shuō)一兩句吧~~