
手把手教你用Python網(wǎng)絡(luò)爬蟲(chóng)實(shí)現(xiàn)起點(diǎn)小說(shuō)下載
回復(fù)“書(shū)籍”即可獲贈(zèng)Python從入門(mén)到進(jìn)階共10本電子書(shū)
今天要跟大家分享一個(gè)小說(shuō)爬取案例--------起點(diǎn)小說(shuō)的小說(shuō)下載。
在做這個(gè)案例之前,我們需要對(duì)其進(jìn)行分析,
1.界面分析,如圖:
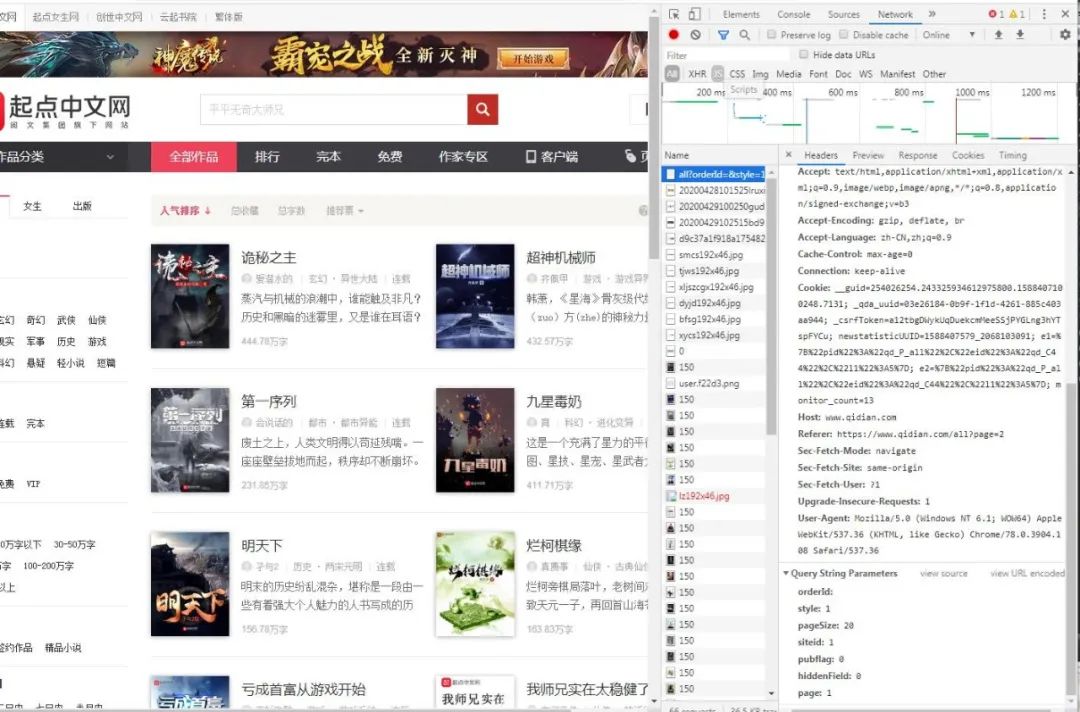
通過(guò)分析很容易就找到了我們的get請(qǐng)求參數(shù),然后獲取相應(yīng)頁(yè)面的小說(shuō)名和鏈接:
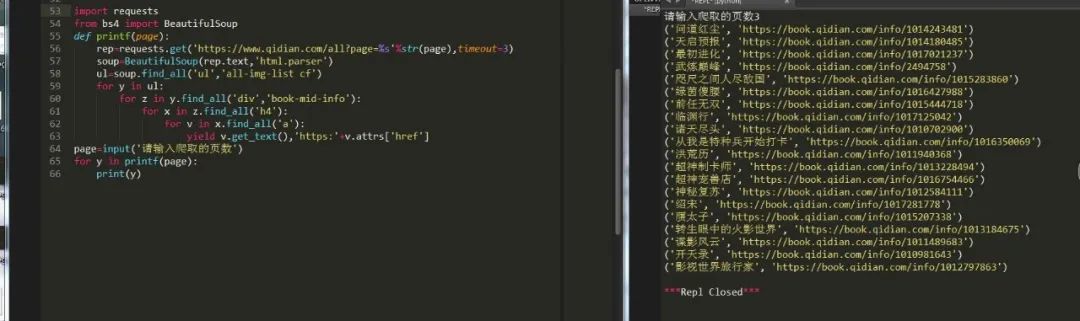
獲取到數(shù)據(jù)之后,我們就隨機(jī)挑選一篇小說(shuō)來(lái)進(jìn)行下載,我們選第一篇,

然后打開(kāi)它的文章目錄,可以看到是這樣的,如圖:
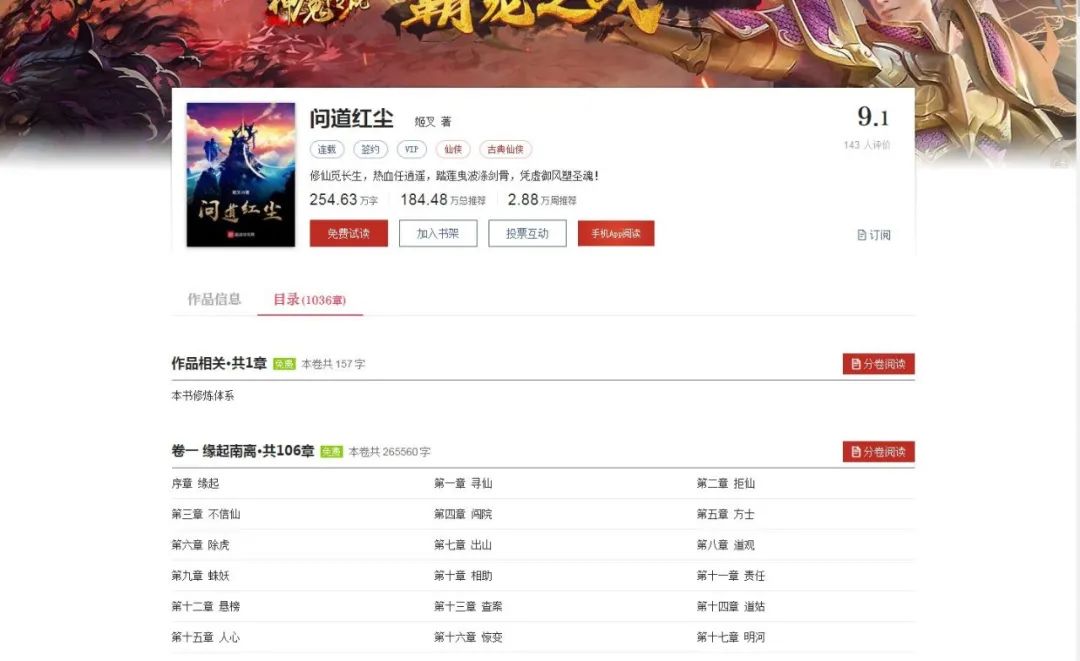
基本上這篇小說(shuō)很長(zhǎng),可以看到它卷一和卷二是免費(fèi)的,后面的收費(fèi),那么今天我們就只爬免費(fèi)的章節(jié)。
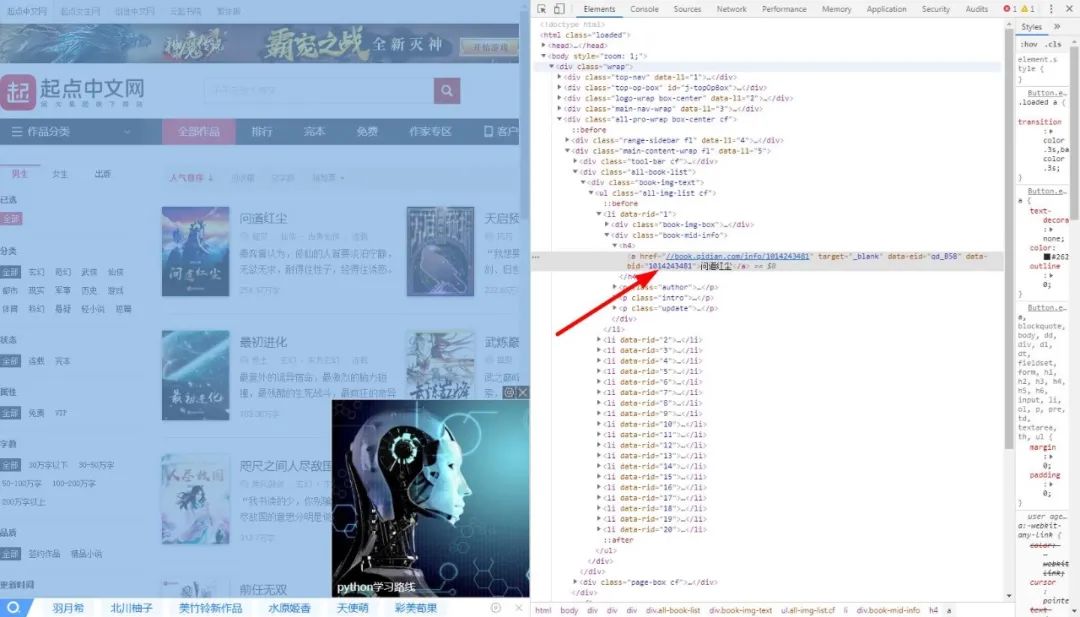
那么我們現(xiàn)在開(kāi)始分析網(wǎng)頁(yè)結(jié)構(gòu),如圖:
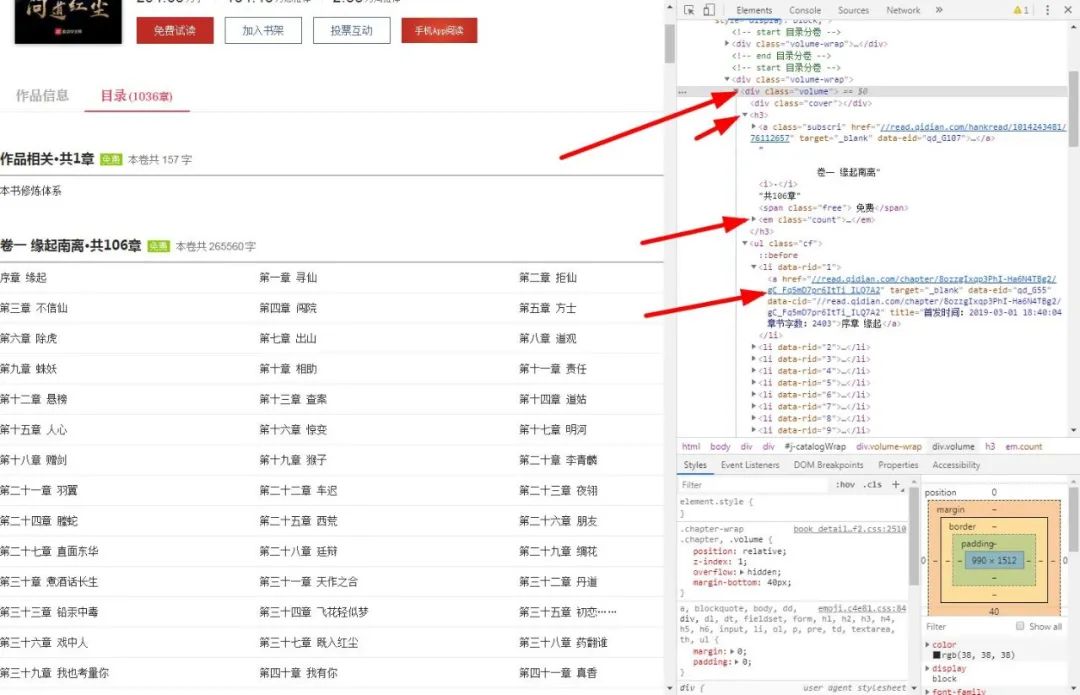
那么,我們可以先把卷一的名字和章節(jié)數(shù)以及章節(jié)下的每個(gè)章節(jié)的名字都打印出來(lái)。
首先我們可以分析下這個(gè)網(wǎng)頁(yè)地址,如圖:
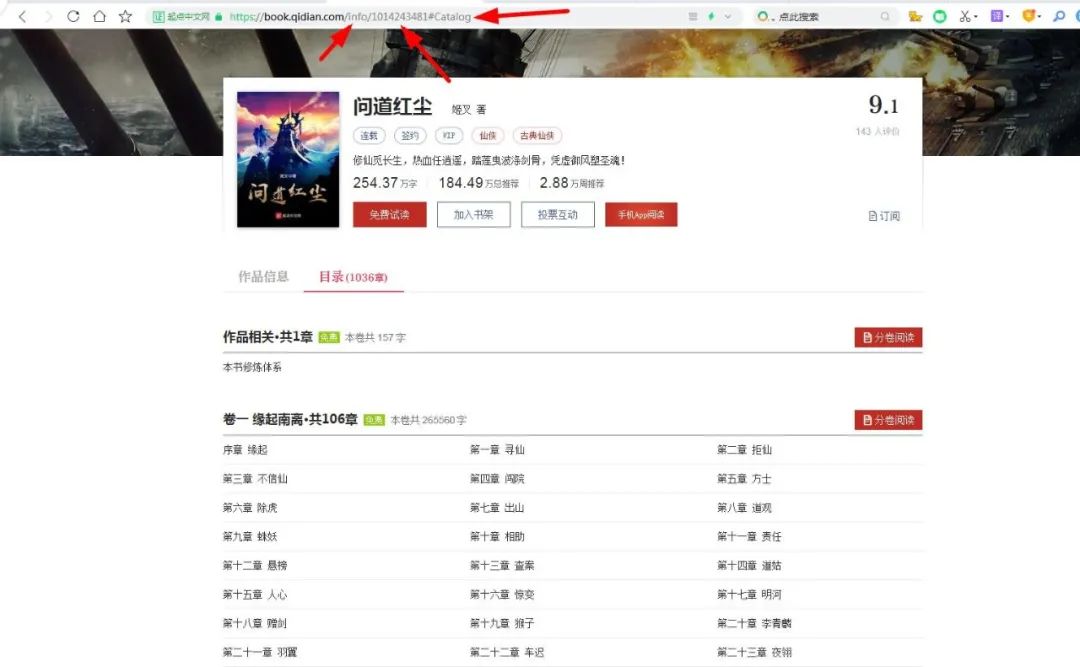
https://book.qidian.com/info/1014243481#Catalog發(fā)覺(jué)前面的沒(méi)變,基本就是后面的變了,增加了一個(gè)info/1014243481#Catalog,下面開(kāi)始分析:
info:信息的意思,
1014243481:小說(shuō)對(duì)應(yīng)的ID,
#Catalog:數(shù)據(jù)補(bǔ)全,無(wú)太大意義
因?yàn)閯倓傄呀?jīng)將文章鏈接的內(nèi)容爬取出來(lái),所以現(xiàn)在只需要拼接一個(gè)#Catalog 即可:
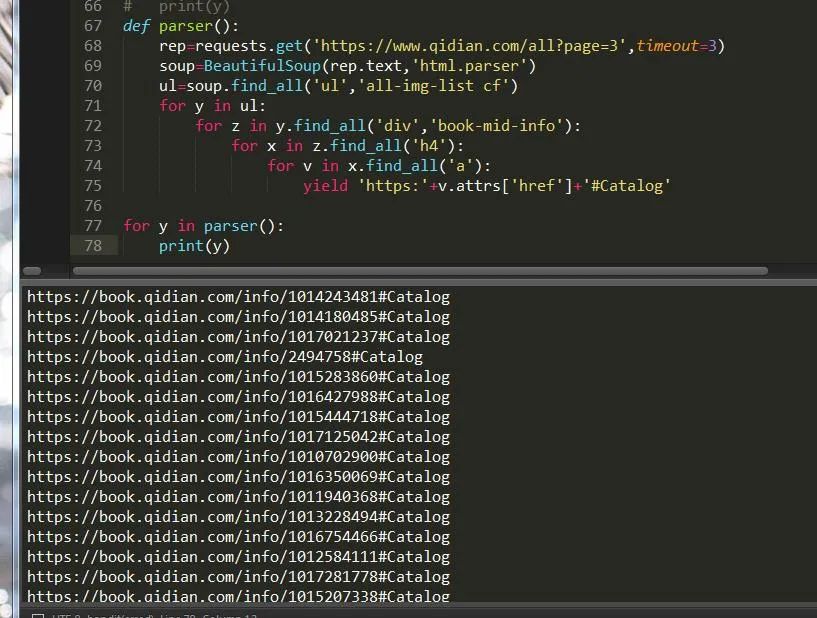
下面我們就可以對(duì)它發(fā)起請(qǐng)求然后在分析它的頁(yè)面了,首先發(fā)起get請(qǐng)求,按照前面的網(wǎng)頁(yè)分析結(jié)構(gòu)來(lái)看,我們應(yīng)該這樣寫(xiě):
可以看出,因?yàn)檫@里有異步加載,所以我們的請(qǐng)求不會(huì)一下子全部顯示出來(lái),需要不斷的請(qǐng)求,當(dāng)然最好加個(gè)延遲。
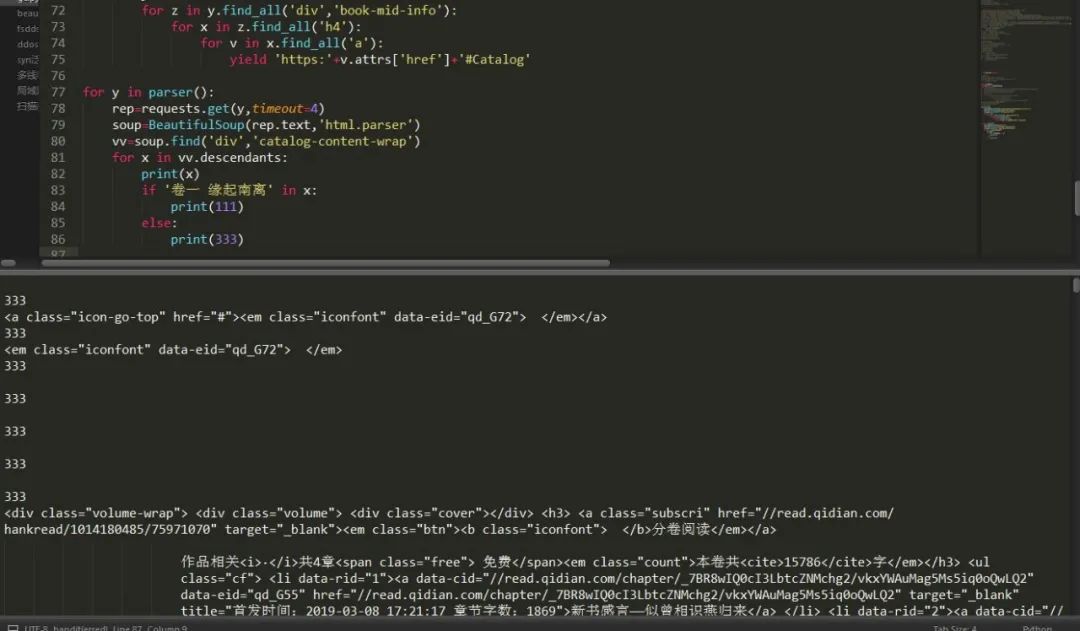
這樣我們就獲取到了這個(gè)頁(yè)面所有的小說(shuō),也可以這樣,因?yàn)槲覀儧](méi)找接口,所以強(qiáng)行解析只能解析部分內(nèi)容,但是也很全面了。如圖:
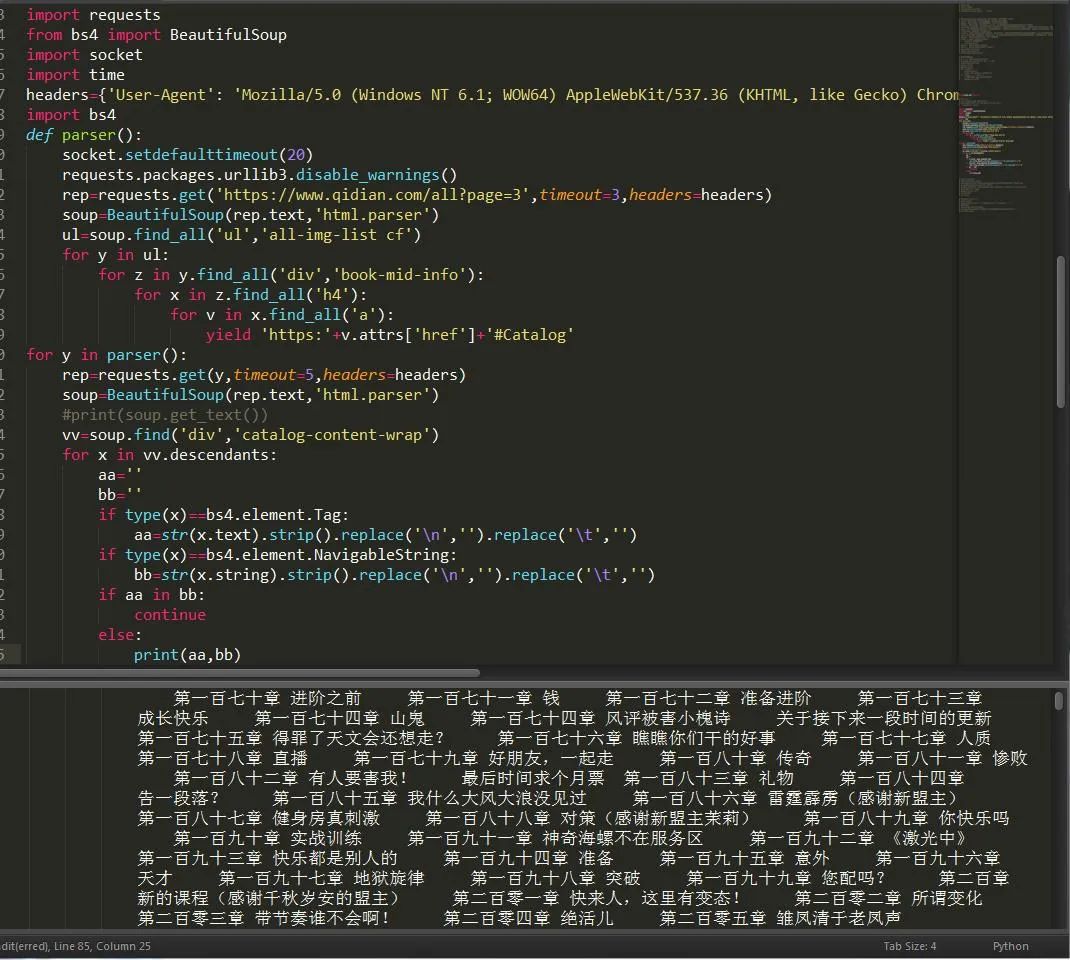
找的還算挺詳細(xì),只不過(guò)沒(méi)有找接口時(shí)所拿到的數(shù)據(jù)那么規(guī)范好看了。
------------------- End -------------------
往期精彩文章推薦:
手把手教你利用Python輕松拆分Excel為多個(gè)CSV文件
手把手教你4種方法用Python批量實(shí)現(xiàn)多Excel多Sheet合并
手把手教你用Python爬取百度搜索結(jié)果并保存

歡迎大家點(diǎn)贊,留言,轉(zhuǎn)發(fā),轉(zhuǎn)載,感謝大家的相伴與支持
想加入Python學(xué)習(xí)群請(qǐng)?jiān)诤笈_(tái)回復(fù)【入群】
萬(wàn)水千山總是情,點(diǎn)個(gè)【在看】行不行
/今日留言主題/
隨便說(shuō)一兩句吧~