
如何設(shè)計一個億級消息量的 IM 系統(tǒng)

來源:https://xie.infoq.cn/article/19e95a78e2f5389588debfb1c
IM核心概念
用戶 :系統(tǒng)的使用者
消息 :是指用戶之間的溝通內(nèi)容。通常在IM系統(tǒng)中,消息會有以下幾類:文本消息、表情消息、圖片消息、視頻消息、文件消息等等
會話 :通常指兩個用戶之間因聊天而建立起的關(guān)聯(lián)
群 :通常指多個用戶之間因聊天而建立起的關(guān)聯(lián)
終端 :指用戶使用IM系統(tǒng)的機器。通常有Android端、iOS端、Web端等等
未讀數(shù) :指用戶還沒讀的消息數(shù)量
用戶狀態(tài) :指用戶當(dāng)前是在線、離線還是掛起等狀態(tài)
關(guān)系鏈 :是指用戶與用戶之間的關(guān)系,通常有單向的好友關(guān)系、雙向的好友關(guān)系、關(guān)注關(guān)系等等。這里需要注意與會話的區(qū)別,用戶只有在發(fā)起聊天時才產(chǎn)生會話,但關(guān)系并不需要聊天才能建立。對于關(guān)系鏈的存儲,可以使用圖數(shù)據(jù)庫(Neo4j等等),可以很自然地表達現(xiàn)實世界中的關(guān)系,易于建模
單聊 :一對一聊天
群聊 :多人聊天
客服 :在電商領(lǐng)域,通常需要對用戶提供售前咨詢、售后咨詢等服務(wù)。這時,就需要引入客服來處理用戶的咨詢
消息分流 :在電商領(lǐng)域,一個店鋪通常會有多個客服,此時決定用戶的咨詢由哪個客服來處理就是消息分流。通常消息分流會根據(jù)一系列規(guī)則來確定消息會分流給哪個客服,例如客服是否在線(客服不在線的話需要重新分流給另一個客服)、該消息是售前咨詢還是售后咨詢、當(dāng)前客服的繁忙程度等等
信箱 :本文的信箱我們指一個Timeline、一個收發(fā)消息的隊列
讀擴散 vs 寫擴散
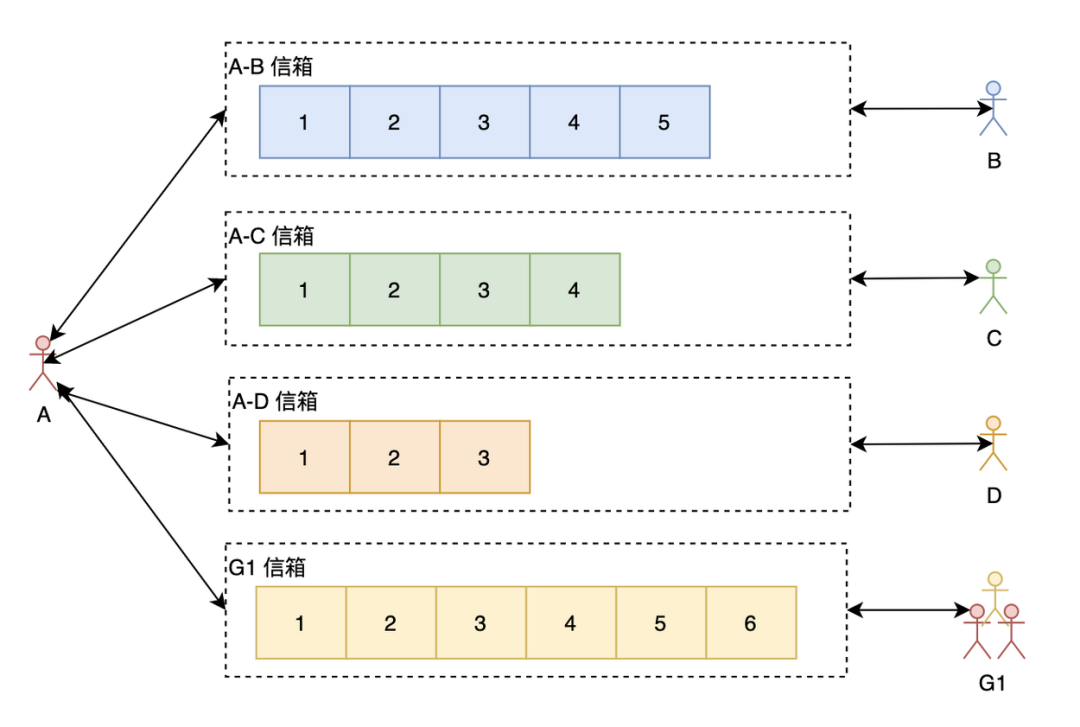
讀擴散
我們先來看看讀擴散。如上圖所示,A與每個聊天的人跟群都有一個信箱(有些博文會叫Timeline),A在查看聊天信息的時候需要讀取所有有新消息的信箱。這里的讀擴散需要注意與Feeds系統(tǒng)的區(qū)別,在Feeds系統(tǒng)中,每個人都有一個寫信箱,寫只需要往自己的寫信箱里寫一次就好了,讀需要從所有關(guān)注的人的寫信箱里讀。但IM系統(tǒng)里的讀擴散通常是每兩個相關(guān)聯(lián)的人就有一個信箱,或者每個群一個信箱。
讀擴散的優(yōu)點:
寫操作(發(fā)消息)很輕量,不管是單聊還是群聊,只需要往相應(yīng)的信箱寫一次就好了 每一個信箱天然就是兩個人的聊天記錄,可以方便查看聊天記錄跟進行聊天記錄的搜索
讀擴散的缺點:
讀操作(讀消息)很重
寫擴散
接下來看看寫擴散。
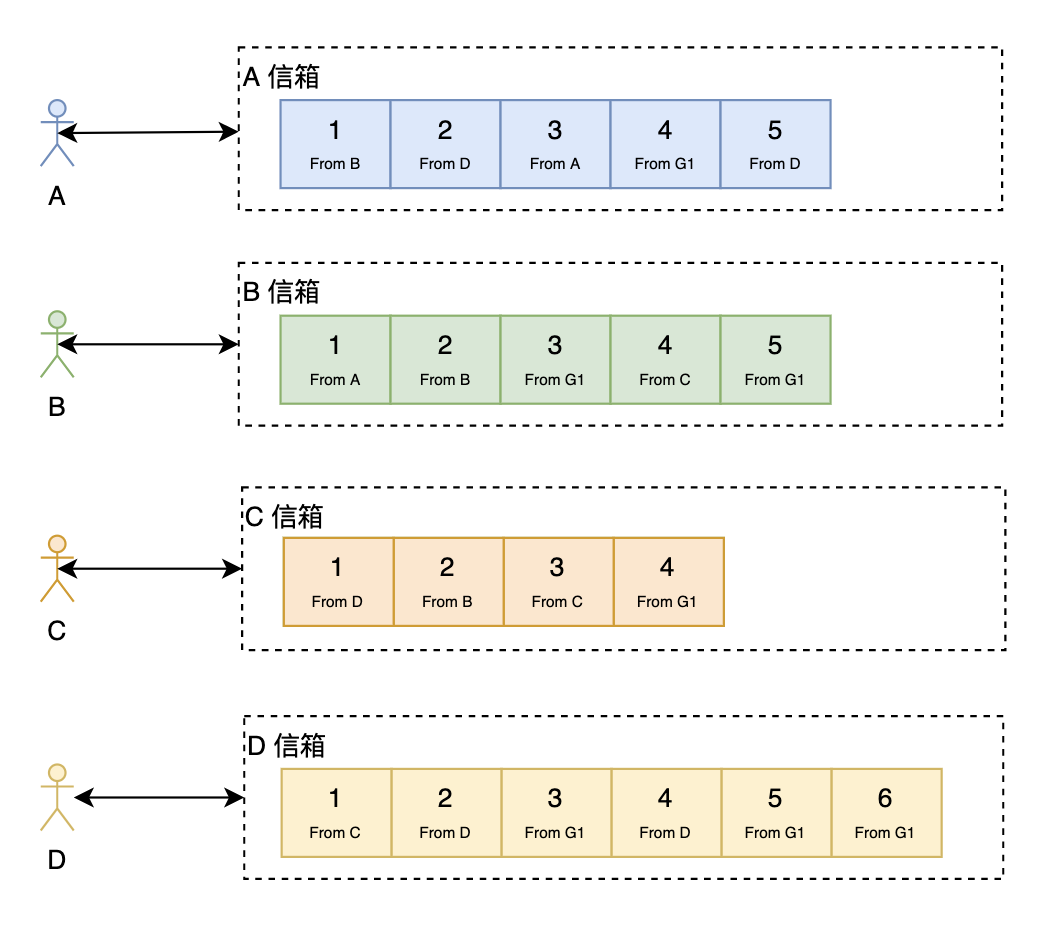
在寫擴散中,每個人都只從自己的信箱里讀取消息,但寫(發(fā)消息)的時候,對于單聊跟群聊處理如下:
單聊:往自己的信箱跟對方的信箱都寫一份消息,同時,如果需要查看兩個人的聊天歷史記錄的話還需要再寫一份(當(dāng)然,如果從個人信箱也能回溯出兩個人的所有聊天記錄,但這樣效率會很低)。 群聊:需要往所有的群成員的信箱都寫一份消息,同時,如果需要查看群的聊天歷史記錄的話還需要再寫一份。可以看出,寫擴散對于群聊來說大大地放大了寫操作。
寫擴散優(yōu)點:
讀操作很輕量 可以很方便地做消息的多終端同步
寫擴散缺點:
寫操作很重,尤其是對于群聊來說
注意,在Feeds系統(tǒng)中:
寫擴散也叫:Push、Fan-out或者Write-fanout 讀擴散也叫:Pull、Fan-in或者Read-fanout
唯一ID設(shè)計
通常情況下,ID的設(shè)計主要有以下幾大類:
UUID 基于Snowflake的ID生成方式 基于申請DB步長的生成方式 基于Redis或者DB的自增ID生成方式 特殊的規(guī)則生成唯一ID
具體的實現(xiàn)方法跟優(yōu)缺點可以參考之前的一篇博文:分布式唯一 ID 解析
在IM系統(tǒng)中需要唯一Id的地方主要是:
會話ID 消息ID
消息ID
我們來看看在設(shè)計消息ID時需要考慮的三個問題。
消息ID不遞增可以嗎
我們先看看不遞增的話會怎樣:
使用字符串,浪費存儲空間,而且不能利用存儲引擎的特性讓相鄰的消息存儲在一起,降低消息的寫入跟讀取性能 使用數(shù)字,但數(shù)字隨機,也不能利用存儲引擎的特性讓相鄰的消息存儲在一起,會加大隨機IO,降低性能;而且隨機的ID不好保證ID的唯一性
因此,消息ID最好是遞增的。
全局遞增 vs 用戶級別遞增 vs 會話級別遞增
全局遞增:指消息ID在整個IM系統(tǒng)隨著時間的推移是遞增的。全局遞增的話一般可以使用Snowflake(當(dāng)然,Snowflake也只是worker級別的遞增)。此時,如果你的系統(tǒng)是讀擴散的話為了防止消息丟失,那每一條消息就只能帶上上一條消息的ID,前端根據(jù)上一條消息判斷是否有丟失消息,有消息丟失的話需要重新拉一次。
用戶級別遞增:指消息ID只保證在單個用戶中是遞增的,不同用戶之間不影響并且可能重復(fù)。典型代表:微信。如果是寫擴散系統(tǒng)的話信箱時間線ID跟消息ID需要分開設(shè)計,信箱時間線ID用戶級別遞增,消息ID全局遞增。如果是讀擴散系統(tǒng)的話感覺使用用戶級別遞增必要性不是很大。
會話級別遞增:指消息ID只保證在單個會話中是遞增的,不同會話之間不影響并且可能重復(fù)。典型代表:QQ。
連續(xù)遞增 vs 單調(diào)遞增
連續(xù)遞增是指ID按 1,2,3...n 的方式生成;而單調(diào)遞增是指只要保證后面生成的ID比前面生成的ID大就可以了,不需要連續(xù)。
據(jù)我所知,QQ的消息ID就是在會話級別使用的連續(xù)遞增,這樣的好處是,如果丟失了消息,當(dāng)下一條消息來的時候發(fā)現(xiàn)ID不連續(xù)就會去請求服務(wù)器,避免丟失消息。此時,可能有人會想,我不能用定時拉的方式看有沒有消息丟失嗎?當(dāng)然不能,因為消息ID只在會話級別連續(xù)遞增的話那如果一個人有上千個會話,那得拉多少次啊,服務(wù)器肯定是抗不住的。
對于讀擴散來說,消息ID使用連續(xù)遞增就是一種不錯的方式了。如果使用單調(diào)遞增的話當(dāng)前消息需要帶上前一條消息的ID(即聊天消息組成一個鏈表),這樣,才能判斷消息是否丟失。
總結(jié)一下就是:
寫擴散:信箱時間線ID使用用戶級別遞增,消息ID全局遞增,此時只要保證單調(diào)遞增就可以了 讀擴散:消息ID可以使用會話級別遞增并且最好是連續(xù)遞增
會話ID
我們來看看設(shè)計會話ID需要注意的問題:
其中,會話ID有種比較簡單的生成方式(特殊的規(guī)則生成唯一ID):拼接 from_user_id 跟 to_user_id:
如果 from_user_id跟to_user_id都是32位整形數(shù)據(jù)的話可以很方便地用位運算拼接成一個64位的會話ID,即:conversation_id = ${from_user_id} << 32 | ${to_user_id}(在拼接前需要確保值比較小的用戶ID是from_user_id,這樣任意兩個用戶發(fā)起會話可以很方便地知道會話ID)如果 from_user_id跟to_user_id都是64位整形數(shù)據(jù)的話那就只能拼接成一個字符串了,拼接成字符串的話就比較傷了,浪費存儲空間性能又不好。
前東家就是使用的上面第1種方式,第1種方式有個硬傷:隨著業(yè)務(wù)在全球的擴展,32位的用戶ID如果不夠用需要擴展到64位的話那就需要大刀闊斧地改了。32位整形ID看起來能夠容納21億個用戶,但通常我們?yōu)榱朔乐箘e人知道真實的用戶數(shù)據(jù),使用的ID通常不是連續(xù)的,這時,32位的用戶ID就完全不夠用了。因此,該設(shè)計完全依賴于用戶ID,不是一種可取的設(shè)計方式。
因此,會話ID的設(shè)計可以使用全局遞增的方式,加一個映射表,保存from_user_id、to_user_id跟conversation_id的關(guān)系。
推模式 vs 拉模式 vs 推拉結(jié)合模式
在IM系統(tǒng)中,新消息的獲取通常會有三種可能的做法:
推模式:有新消息時服務(wù)器主動推給所有端(iOS、Android、PC等) 拉模式:由前端主動發(fā)起拉取消息的請求,為了保證消息的實時性,一般采用推模式,拉模式一般用于獲取歷史消息 推拉結(jié)合模式:有新消息時服務(wù)器會先推一個有新消息的通知給前端,前端接收到通知后就向服務(wù)器拉取消息
推模式簡化圖如下:
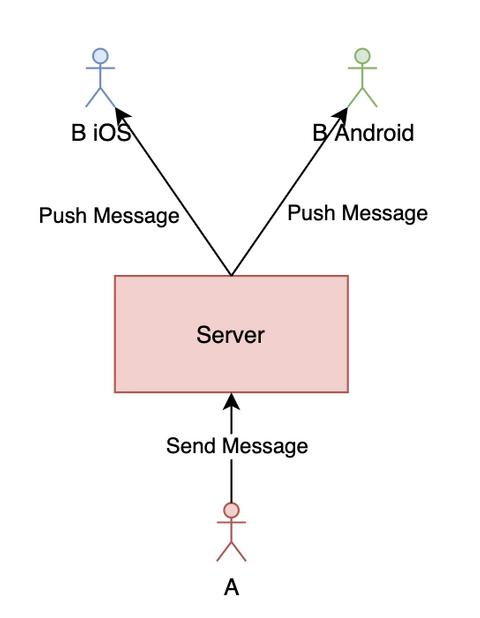
如上圖所示,正常情況下,用戶發(fā)的消息經(jīng)過服務(wù)器存儲等操作后會推給接收方的所有端。但推是有可能會丟失的,最常見的情況就是用戶可能會偽在線(是指如果推送服務(wù)基于長連接,而長連接可能已經(jīng)斷開,即用戶已經(jīng)掉線,但一般需要經(jīng)過一個心跳周期后服務(wù)器才能感知到,這時服務(wù)器會錯誤地以為用戶還在線;偽在線是本人自己想的一個概念,沒想到合適的詞來解釋)。因此如果單純使用推模式的話,是有可能會丟失消息的。
推拉結(jié)合模式簡化圖如下:
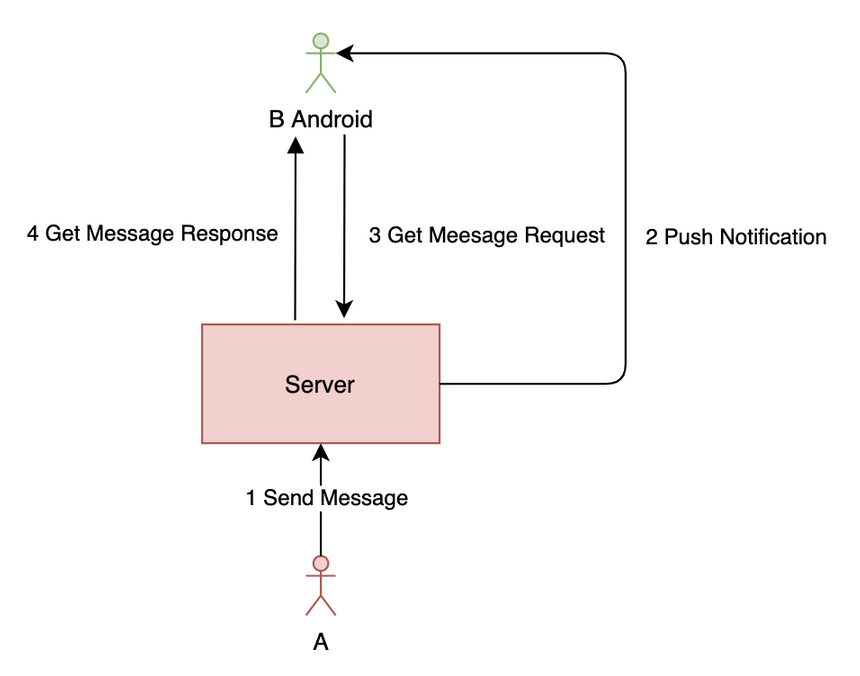
可以使用推拉結(jié)合模式解決推模式可能會丟消息的問題。在用戶發(fā)新消息時服務(wù)器推送一個通知,然后前端請求最新消息列表,為了防止有消息丟失,可以再每隔一段時間主動請求一次。可以看出,使用推拉結(jié)合模式最好是用寫擴散,因為寫擴散只需要拉一條時間線的個人信箱就好了,而讀擴散有N條時間線(每個信箱一條),如果也定時拉取的話性能會很差。
業(yè)界解決方案
前面了解了IM系統(tǒng)的常見設(shè)計問題,接下來我們再看看業(yè)界是怎么設(shè)計IM系統(tǒng)的。研究業(yè)界的主流方案有助于我們深入理解IM系統(tǒng)的設(shè)計。以下研究都是基于網(wǎng)上已經(jīng)公開的資料,不一定正確,大家僅作參考就好了。
微信
雖然微信很多基礎(chǔ)框架都是自研,但這并不妨礙我們理解微信的架構(gòu)設(shè)計。從微信公開的《[從0到1:微信后臺系統(tǒng)的演進之路](#》這篇文章可以看出,微信采用的主要是:寫擴散 + 推拉結(jié)合。由于群聊使用的也是寫擴散,而寫擴散很消耗資源,因此微信群有人數(shù)上限(目前是500)。所以這也是寫擴散的一個明顯缺點,如果需要萬人群就比較難了。
從文中還可以看出,微信采用了多數(shù)據(jù)中心架構(gòu):
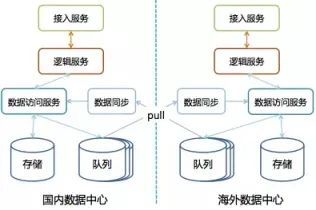
微信每個數(shù)據(jù)中心都是自治的,每個數(shù)據(jù)中心都有全量的數(shù)據(jù),數(shù)據(jù)中心間通過自研的消息隊列來同步數(shù)據(jù)。為了保證數(shù)據(jù)的一致性,每個用戶都只屬于一個數(shù)據(jù)中心,只能在自己所屬的數(shù)據(jù)中心進行數(shù)據(jù)讀寫,如果用戶連了其它數(shù)據(jù)中心則會自動引導(dǎo)用戶接入所屬的數(shù)據(jù)中心。而如果需要訪問其它用戶的數(shù)據(jù)那只需要訪問自己所屬的數(shù)據(jù)中心就可以了。同時,微信使用了三園區(qū)容災(zāi)的架構(gòu),使用Paxos來保證數(shù)據(jù)的一致性。
從微信公開的《萬億級調(diào)用系統(tǒng):微信序列號生成器架構(gòu)設(shè)計及演變》這篇文章可以看出,微信的ID設(shè)計采用的是:基于申請DB步長的生成方式 + 用戶級別遞增。如下圖所示:
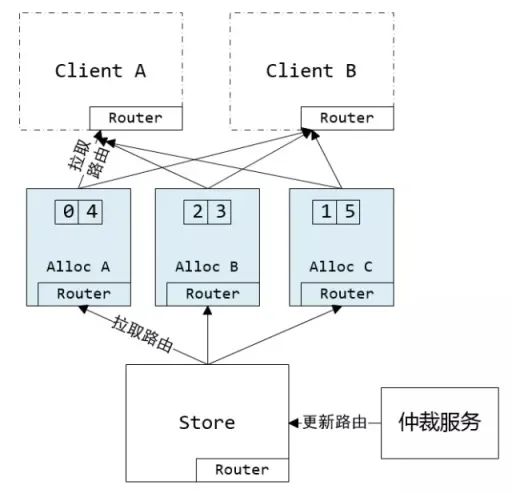
微信的序列號生成器由仲裁服務(wù)生成路由表(路由表保存了uid號段到AllocSvr的全映射),路由表會同步到AllocSvr跟Client。如果AllocSvr宕機的話會由仲裁服務(wù)重新調(diào)度uid號段到其它AllocSvr。
釘釘
釘釘公開的資料不多,從《阿里釘釘技術(shù)分享:企業(yè)級IM王者——釘釘在后端架構(gòu)上的過人之處》這篇文章我們只能知道,釘釘最開始使用的是寫擴散模型,為了支持萬人群,后來貌似優(yōu)化成了讀擴散。
但聊到阿里的IM系統(tǒng),不得不提的是阿里自研的Tablestore。一般情況下,IM系統(tǒng)都會有一個自增ID生成系統(tǒng),但Tablestore創(chuàng)造性地引入了主鍵列自增,即把ID的生成整合到了DB層,支持了用戶級別遞增(傳統(tǒng)MySQL等DB只能支持表級自增,即全局自增)。具體可以參考:《如何優(yōu)化高并發(fā)IM系統(tǒng)架構(gòu)》
什么?Twitter不是Feeds系統(tǒng)嗎?這篇文章不是討論IM的嗎?是的,Twitter是Feeds系統(tǒng),但Feeds系統(tǒng)跟IM系統(tǒng)其實有很多設(shè)計上的共性,研究下Feeds系統(tǒng)有助于我們在設(shè)計IM系統(tǒng)時進行參考。再說了,研究下Feeds系統(tǒng)也沒有壞處,擴展下技術(shù)視野嘛。
Twitter的自增ID設(shè)計估計大家都耳熟能詳了,即大名鼎鼎的Snowflake,因此ID是全局遞增的。
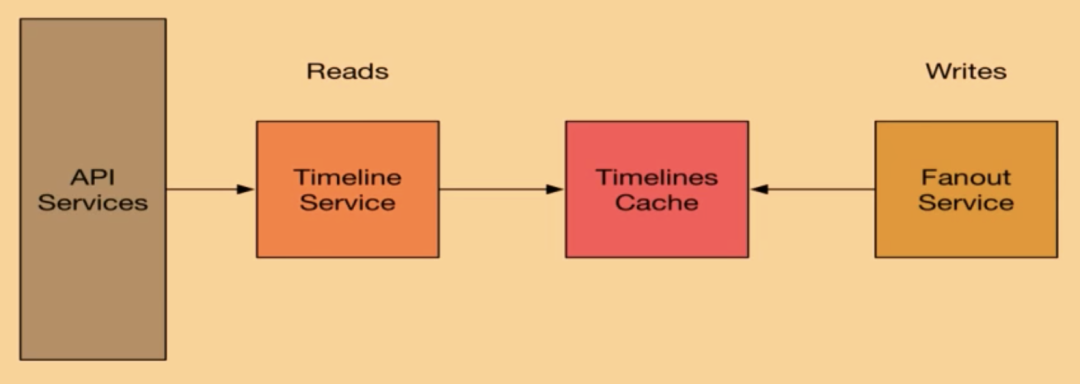
從這個視頻分享《How We Learned to Stop Worrying and Love Fan-In at Twitter》可以看出,Twitter一開始使用的是寫擴散模型,F(xiàn)anout Service負(fù)責(zé)擴散寫到Timelines Cache(使用了Redis),Timeline Service負(fù)責(zé)讀取Timeline數(shù)據(jù),然后由API Services返回給用戶。
但由于寫擴散對于大V來說寫的消耗太大,因此后面Twitter又使用了寫擴散跟讀擴散結(jié)合的方式。如下圖所示:
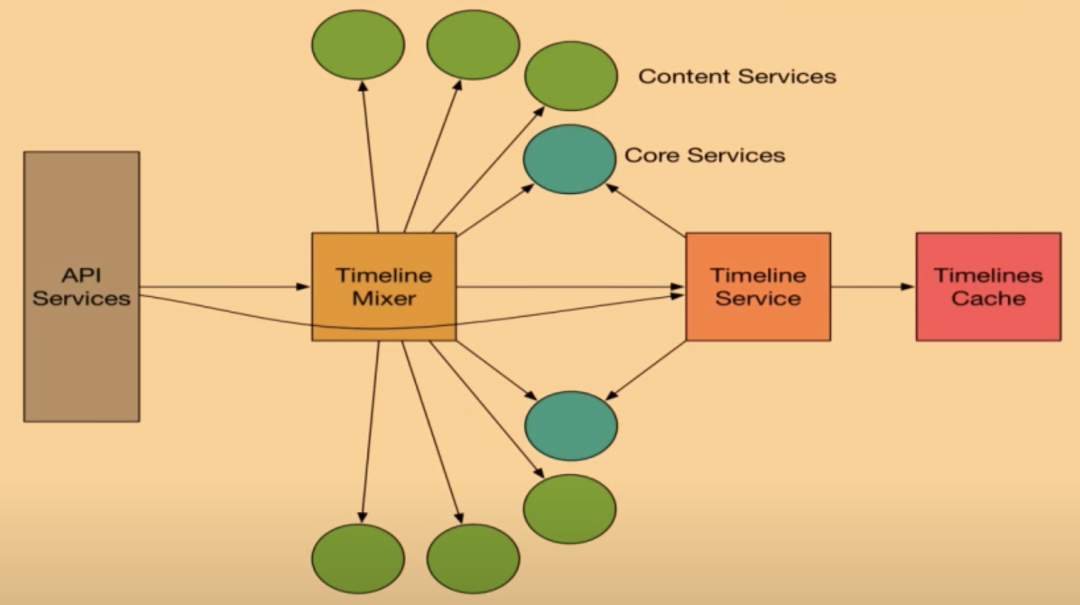
對于粉絲數(shù)不多的用戶如果發(fā)Twitter使用的還是寫擴散模型,由Timeline Mixer服務(wù)將用戶的Timeline、大V的寫Timeline跟系統(tǒng)推薦等內(nèi)容整合起來,最后再由API Services返回給用戶
IM需要解決的問題
如何保證消息的實時性
在通信協(xié)議的選擇上,我們主要有以下幾個選擇:
使用TCP Socket通信,自己設(shè)計協(xié)議:58到家等等 使用UDP Socket通信:QQ等等 使用HTTP長輪循:微信網(wǎng)頁版等等
不管使用哪種方式,我們都能夠做到消息的實時通知。但影響我們消息實時性的可能會在我們處理消息的方式上。例如:假如我們推送的時候使用MQ去處理并推送一個萬人群的消息,推送一個人需要2ms,那么推完一萬人需要20s,那么后面的消息就阻塞了20s。如果我們需要在10ms內(nèi)推完,那么我們推送的并發(fā)度應(yīng)該是:人數(shù):10000 / (推送總時長:10 / 單個人推送時長:2) = 2000
因此,我們在選擇具體的實現(xiàn)方案的時候一定要評估好我們系統(tǒng)的吞吐量,系統(tǒng)的每一個環(huán)節(jié)都要進行評估壓測。只有把每一個環(huán)節(jié)的吞吐量評估好了,才能保證消息推送的實時性。
如何保證消息時序
以下情況下消息可能會亂序:
發(fā)送消息如果使用的不是長連接,而是使用HTTP的話可能會出現(xiàn)亂序。因為后端一般是集群部署,使用HTTP的話請求可能會打到不同的服務(wù)器,由于網(wǎng)絡(luò)延遲或者服務(wù)器處理速度的不同,后發(fā)的消息可能會先完成,此時就產(chǎn)生了消息亂序。解決方案: 前端依次對消息進行處理,發(fā)送完一個消息再發(fā)送下一個消息。這種方式會降低用戶體驗,一般情況下不建議使用。 帶上一個前端生成的順序ID,讓接收方根據(jù)該ID進行排序。這種方式前端處理會比較麻煩一點,而且聊天的過程中接收方的歷史消息列表中可能會在中間插入一條消息,這樣會很奇怪,而且用戶可能會漏讀消息。但這種情況可以通過在用戶切換窗口的時候再進行重排來解決,接收方每次收到消息都先往最后面追加。 通常為了優(yōu)化體驗,有的IM系統(tǒng)可能會采取異步發(fā)送確認(rèn)機制(例如:QQ)。即消息只要到達服務(wù)器,然后服務(wù)器發(fā)送到MQ就算發(fā)送成功。如果由于權(quán)限等問題發(fā)送失敗的話后端再推一個通知下去。這種情況下MQ就要選擇合適的Sharding策略了: 按 to_user_id進行Sharding:使用該策略如果需要做多端同步的話發(fā)送方多個端進行同步可能會亂序,因為不同隊列的處理速度可能會不一樣。例如發(fā)送方先發(fā)送m1然后發(fā)送m2,但服務(wù)器可能會先處理完m2再處理m1,這里其它端會先收到m2然后是m1,此時其它端的會話列表就亂了。按 conversation_id進行Sharding:使用該策略同樣會導(dǎo)致多端同步會亂序。按 from_user_id進行Sharding:這種情況下使用該策略是比較好的選擇通常為了優(yōu)化性能,推送前可能會先往MQ推,這種情況下使用 to_user_id才是比較好的選擇。
用戶在線狀態(tài)如何做
很多IM系統(tǒng)都需要展示用戶的狀態(tài):是否在線,是否忙碌等。主要可以使用Redis或者分布式一致性哈希來實現(xiàn)用戶在線狀態(tài)的存儲。
Redis存儲用戶在線狀態(tài)
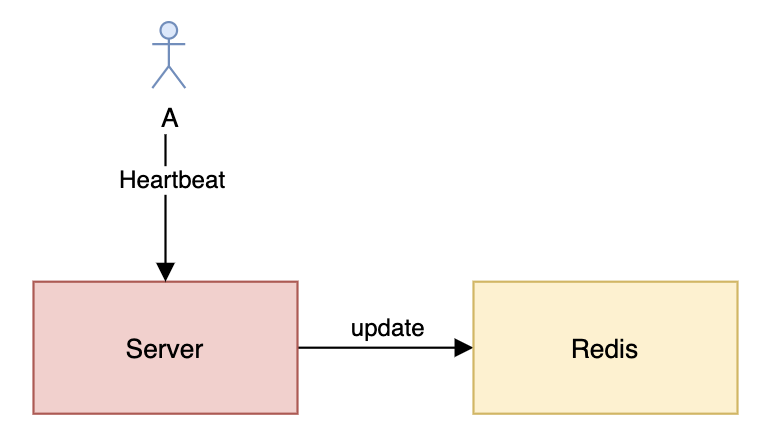
看上面的圖可能會有人疑惑,為什么每次心跳都需要更新Redis?如果我使用的是TCP長連接那是不是就不用每次心跳都更新了?確實,正常情況下服務(wù)器只需要在新建連接或者斷開連接的時候更新一下Redis就好了。但由于服務(wù)器可能會出現(xiàn)異常,或者服務(wù)器跟Redis之間的網(wǎng)絡(luò)會出現(xiàn)問題,此時基于事件的更新就會出現(xiàn)問題,導(dǎo)致用戶狀態(tài)不正確。因此,如果需要用戶在線狀態(tài)準(zhǔn)確的話最好通過心跳來更新在線狀態(tài)。
由于Redis是單機存儲的,因此,為了提高可靠性跟性能,我們可以使用Redis Cluster或者Codis。
分布式一致性哈希存儲用戶在線狀態(tài)

使用分布式一致性哈希需要注意在對Status Server Cluster進行擴容或者縮容的時候要先對用戶狀態(tài)進行遷移,不然在剛操作時會出現(xiàn)用戶狀態(tài)不一致的情況。同時還需要使用虛擬節(jié)點避免數(shù)據(jù)傾斜的問題。
多端同步怎么做
讀擴散
前面也提到過,對于讀擴散,消息的同步主要是以推模式為主,單個會話的消息ID順序遞增,前端收到推的消息如果發(fā)現(xiàn)消息ID不連續(xù)就請求后端重新獲取消息。但這樣仍然可能丟失會話的最后一條消息,為了加大消息的可靠性,可以在歷史會話列表的會話里再帶上最后一條消息的ID,前端在收到新消息的時候會先拉取最新的會話列表,然后判斷會話的最后一條消息是否存在,如果不存在,消息就可能丟失了,前端需要再拉一次會話的消息列表;如果會話的最后一條消息ID跟消息列表里的最后一條消息ID一樣,前端就不再處理。這種做法的性能瓶頸會在拉取歷史會話列表那里,因為每次新消息都需要拉取后端一次,如果按微信的量級來看,單是消息就可能會有20萬的QPS,如果歷史會話列表放到MySQL等傳統(tǒng)DB的話肯定抗不住。因此,最好將歷史會話列表存到開了AOF(用RDB的話可能會丟數(shù)據(jù))的Redis集群。這里只能感慨性能跟簡單性不能兼得。
寫擴散
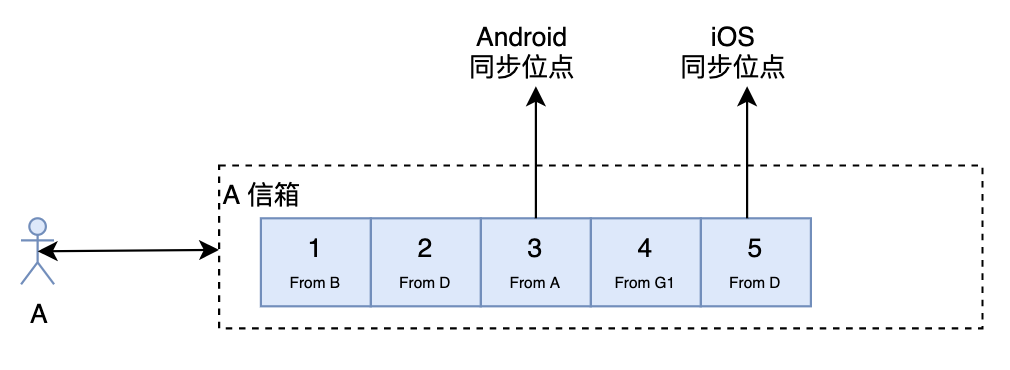
對于寫擴散來說,多端同步就簡單些了。前端只需要記錄最后同步的位點,同步的時候帶上同步位點,然后服務(wù)器就將該位點后面的數(shù)據(jù)全部返回給前端,前端更新同步位點就可以了。
如何處理未讀數(shù)
在IM系統(tǒng)中,未讀數(shù)的處理非常重要。未讀數(shù)一般分為會話未讀數(shù)跟總未讀數(shù),如果處理不當(dāng),會話未讀數(shù)跟總未讀數(shù)可能會不一致,嚴(yán)重降低用戶體驗。
讀擴散
對于讀擴散來說,我們可以將會話未讀數(shù)跟總未讀數(shù)都存在后端,但后端需要保證兩個未讀數(shù)更新的原子性跟一致性,一般可以通過以下兩種方法來實現(xiàn):
使用Redis的multi事務(wù)功能,事務(wù)更新失敗可以重試。但要注意如果你使用Codis集群的話并不支持事務(wù)功能。 使用Lua嵌入腳本的方式。使用這種方式需要保證會話未讀數(shù)跟總未讀數(shù)都在同一個Redis節(jié)點(Codis的話可以使用Hashtag)。這種方式會導(dǎo)致實現(xiàn)邏輯分散,加大維護成本。
寫擴散
對于寫擴散來說,服務(wù)端通常會弱化會話的概念,即服務(wù)端不存儲歷史會話列表。未讀數(shù)的計算可由前端來負(fù)責(zé),標(biāo)記已讀跟標(biāo)記未讀可以只記錄一個事件到信箱里,各個端通過重放該事件的形式來處理會話未讀數(shù)。使用這種方式可能會造成各個端的未讀數(shù)不一致,至少微信就會有這個問題。
如果寫擴散也通過歷史會話列表來存儲未讀數(shù)的話那用戶時間線服務(wù)跟會話服務(wù)緊耦合,這個時候需要保證原子性跟一致性的話那就只能使用分布式事務(wù)了,會大大降低系統(tǒng)的性能。
如何存儲歷史消息
讀擴散
對于讀擴散,只需要按會話ID進行Sharding存儲一份就可以了。
寫擴散
對于寫擴散,需要存儲兩份:一份是以用戶為Timeline的消息列表,一份是以會話為Timeline的消息列表。以用戶為Timeline的消息列表可以用用戶ID來做Sharding,以會話為Timeline的消息列表可以用會話ID來做Sharding。
數(shù)據(jù)冷熱分離
對于IM來說,歷史消息的存儲有很強的時間序列特性,時間越久,消息被訪問的概率也越低,價值也越低。
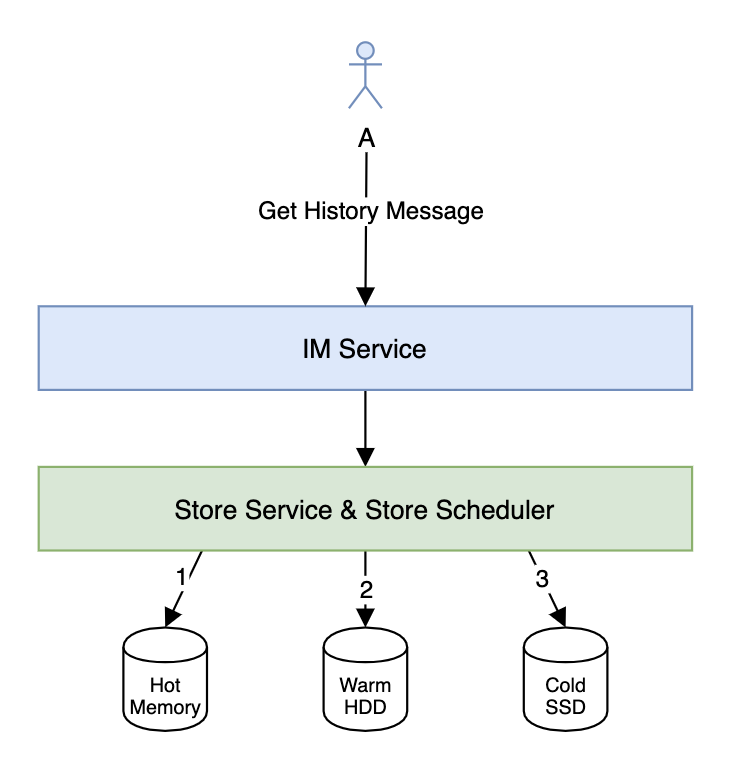
如果我們需要存儲幾年甚至是永久的歷史消息的話(電商IM中比較常見),那么做歷史消息的冷熱分離就非常有必要了。數(shù)據(jù)的冷熱分離一般是HWC(Hot-Warm-Cold)架構(gòu)。對于剛發(fā)送的消息可以放到Hot存儲系統(tǒng)(可以用Redis)跟Warm存儲系統(tǒng),然后由Store Scheduler根據(jù)一定的規(guī)則定時將冷數(shù)據(jù)遷移到Cold存儲系統(tǒng)。獲取消息的時候需要依次訪問Hot、Warm跟Cold存儲系統(tǒng),由Store Service整合數(shù)據(jù)返回給IM Service。
接入層怎么做
實現(xiàn)接入層的負(fù)載均衡主要有以下幾個方法:
硬件負(fù)載均衡:例如F5、A10等等。硬件負(fù)載均衡性能強大,穩(wěn)定性高,但價格非常貴,不是土豪公司不建議使用。 使用DNS實現(xiàn)負(fù)載均衡:使用DNS實現(xiàn)負(fù)載均衡比較簡單,但使用DNS實現(xiàn)負(fù)載均衡如果需要切換或者擴容那生效會很慢,而且使用DNS實現(xiàn)負(fù)載均衡支持的IP個數(shù)有限制、支持的負(fù)載均衡策略也比較簡單。 DNS + 4層負(fù)載均衡 + 7層負(fù)載均衡架構(gòu):例如 DNS + DPVS + Nginx 或者 DNS + LVS + Nginx。有人可能會疑惑為什么要加入4層負(fù)載均衡呢?這是因為7層負(fù)載均衡很耗CPU,并且經(jīng)常需要擴容或者縮容,對于大型網(wǎng)站來說可能需要很多7層負(fù)載均衡服務(wù)器,但只需要少量的4層負(fù)載均衡服務(wù)器即可。因此,該架構(gòu)對于HTTP等短連接大型應(yīng)用很有用。當(dāng)然,如果流量不大的話只使用DNS + 7層負(fù)載均衡即可。但對于長連接來說,加入7層負(fù)載均衡Nginx就不大好了。因為Nginx經(jīng)常需要改配置并且reload配置,reload的時候TCP連接會斷開,造成大量掉線。 DNS + 4層負(fù)載均衡:4層負(fù)載均衡一般比較穩(wěn)定,很少改動,比較適合于長連接。
對于長連接的接入層,如果我們需要更加靈活的負(fù)載均衡策略或者需要做灰度的話,那我們可以引入一個調(diào)度服務(wù),如下圖所示:
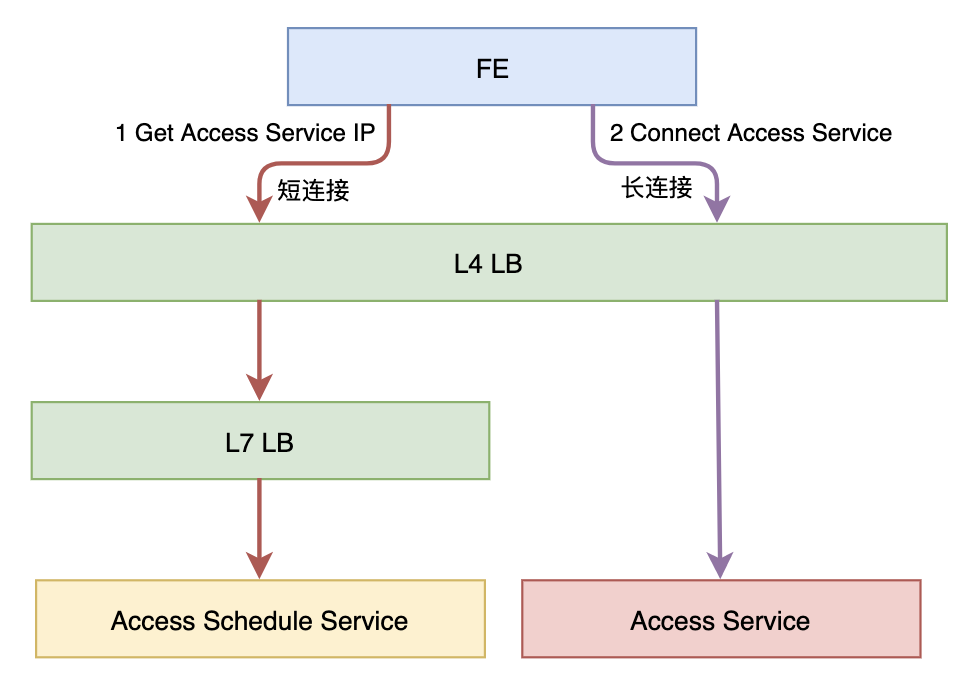
Access Schedule Service可以實現(xiàn)根據(jù)各種策略來分配Access Service,例如:
根據(jù)灰度策略來分配 根據(jù)就近原則來分配 根據(jù)最少連接數(shù)來分配
架構(gòu)心得
最后,分享一下做大型應(yīng)用的架構(gòu)心得:
灰度!灰度!灰度! 監(jiān)控!監(jiān)控!監(jiān)控! 告警!告警!告警! 緩存!緩存!緩存! 限流!熔斷!降級! 低耦合,高內(nèi)聚! 避免單點,擁抱無狀態(tài)! 評估!評估!評估! 壓測!壓測!壓測!
推薦閱讀:
企業(yè)IT技術(shù)架構(gòu)規(guī)劃方案
論數(shù)字化轉(zhuǎn)型——轉(zhuǎn)什么,如何轉(zhuǎn)?
企業(yè)10大管理流程圖,數(shù)字化轉(zhuǎn)型從業(yè)者必備!
【中臺實踐】華為大數(shù)據(jù)中臺架構(gòu)分享.pdf