
【遷移學(xué)習(xí)】隱私保護(hù)下的遷移算法

作者:李新春
————————
計算機(jī)軟件新技術(shù)國家重點(diǎn)實驗室
偽文藝程序員
既可提刀立碼,行遍天下
又可調(diào)參煉丹,臥于隆中
本文概要
本文介紹一種特殊場景下的遷移算法:隱私保護(hù)下的遷移算法。首先,本文稍微回顧一下傳統(tǒng)遷移算法的流程、特性和局限之處,然后文章介紹幾種解決當(dāng)源域數(shù)據(jù)有某些訪問限制的場景下實現(xiàn)遷移的算法。具體包括:ADDA-CVPR2017,F(xiàn)ADA-ICLR2020,SHOT-ICML2020。
1
傳統(tǒng)遷移算法UDDA
首先說明這里說的傳統(tǒng)遷移算法,主要指深度域適應(yīng)(Deep Domain Adaptation),更具體的是無監(jiān)督深度域適應(yīng)(Unsupervised Deep Domain Adaptation, UDDA)。因為UDDA是最為常見,也是大家廣泛關(guān)注的設(shè)定,因此這方面的工作遠(yuǎn)遠(yuǎn)多于其余遷移算法的設(shè)定。
先介紹一下UDDA具體是做什么的:給定一個目標(biāo)域(Target Domain),該域只有無標(biāo)記數(shù)據(jù),因此不能有監(jiān)督地訓(xùn)練模型,目標(biāo)域通常是一個新的局點(diǎn)、場景或者數(shù)據(jù)集;為了在目標(biāo)域無標(biāo)記數(shù)據(jù)的情況下建立模型,可以借助源域(Source Domain)的知識,源域通常是已有局點(diǎn)、場景或者數(shù)據(jù)集,知識可以是源域訓(xùn)練好的模型、源域的原始數(shù)據(jù)、源域的特征等。
借助有標(biāo)記信息的源域,目標(biāo)域上即便沒有標(biāo)記數(shù)據(jù),也可以建立一個模型。使得該模型對目標(biāo)域數(shù)據(jù)有效的關(guān)鍵難點(diǎn)在于源域和目標(biāo)域存在數(shù)據(jù)分布的差異,稱之為域漂移(Domain Shift),如何去對齊源域和目標(biāo)域的數(shù)據(jù)是UDDA解決的主要問題。
UDDA通常包含下面的三種框架:
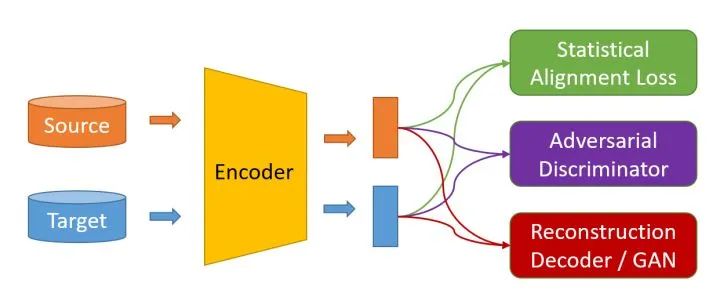
首先,源域和目標(biāo)域的數(shù)據(jù)(圓柱)會經(jīng)過特征提取器(Encoder)提取特征(矩形),然后各種辦法會對源域和目標(biāo)域的特征進(jìn)行操作,使得源域和目標(biāo)域上數(shù)據(jù)的特征對齊。這里值得一提的是,UDDA通常假設(shè)源域和目標(biāo)域的類別是一樣的,比如源域和目標(biāo)域都是去分類0-9十個手寫數(shù)字,只不過源域和目標(biāo)域的手寫風(fēng)格不一樣。
?對源域和目標(biāo)域特征進(jìn)行操作的辦法包括三種類別:
基于統(tǒng)計對齊:使用各種統(tǒng)計量對齊源域和目標(biāo)域特征的分布,比如對齊核空間均值(MMD Loss)、對齊協(xié)方差矩陣(CORAL Loss)等;
基于對抗對齊:建立一個域分類器(Domain Classifier)作為判別器(Discriminator),目的要盡可能將源域和目標(biāo)域的特征區(qū)分開來,使用梯度反轉(zhuǎn)(Gradient Reversal Gradient,GRL)可以促使特征提取器提取和領(lǐng)域無關(guān)(Domain Invariant)的特征;
基于重構(gòu)對齊:將源域和目標(biāo)域的特征通過同一個生成網(wǎng)絡(luò)進(jìn)行生成相應(yīng)的數(shù)據(jù),通過假設(shè)只有分布接近的樣本才可以使用同一個網(wǎng)絡(luò)生成數(shù)據(jù)對齊源域和目標(biāo)域特征。
關(guān)于以上幾種UDDA的具體算法可以參加以前的文章:https://zhuanlan.zhihu.com/p/205433863
這里本文只給出UDDA的幾個特性:
源域數(shù)據(jù)可獲得:UDDA假設(shè)源域數(shù)據(jù)存在并且可以獲得;
源域目標(biāo)域數(shù)據(jù)可混合:UDDA通常假設(shè)源域和目標(biāo)域數(shù)據(jù)可以在一起處理,即可以放在同一個設(shè)備上進(jìn)行運(yùn)算;
訓(xùn)練預(yù)測過程是Transductive的:目標(biāo)域數(shù)據(jù)必須和源域數(shù)據(jù)一同訓(xùn)練才可以使得特征提取器提取領(lǐng)域無關(guān)的特征,才可以將源域的模型遷移到目標(biāo)域,因此當(dāng)一批新的目標(biāo)域的數(shù)據(jù)到來的話,并不能直接使用源域模型進(jìn)行預(yù)測。
總的來說,傳統(tǒng)的UDDA方法假設(shè)源域數(shù)據(jù)可獲得、源域目標(biāo)域數(shù)據(jù)可混合、訓(xùn)練過程Transductive。然而,有一些場景下,源域數(shù)據(jù)不可獲得,或者源域數(shù)據(jù)不可以外傳,這種情況下如何進(jìn)行遷移呢?
首先,這里需要注意的是,源域數(shù)據(jù)不能外傳和源域數(shù)據(jù)不可獲得是兩種情況,前者假設(shè)源域數(shù)據(jù)存在,但是不可以和目標(biāo)域數(shù)據(jù)放在一起,后者是源域數(shù)據(jù)根本就不存在了。
2
ADDA
ADDA是CVPR2017的一篇工作,來自論文《Adversarial Discriminative Domain Adaptation》,作者信息截圖如下:
一作Eric Tzeng來自于加利福尼亞大學(xué)伯克利分校,代表作有DDC和ADDA;二作Judy Hoffman來自斯坦福大學(xué),代表作CyCADA,以及多篇在多領(lǐng)域遷移方面的理論文章,比如NeurIPS 2018的《Algorithms and Theory for Multiple-Source Adaptation》;三作Kate Saenko是波斯頓大學(xué)計算機(jī)科學(xué)計算機(jī)視覺組(Computer Vision and Learning Group,CVL)的Leader,是一名女性學(xué)者,Baochen Sun,Xingchao Peng,Kuniaki Saito等人都在該組深造或者深造過。
CVL代表作有(個人評定,以下文章個人在學(xué)習(xí)DA的過程中或多或少閱讀或者研究過):
Xingchao Peng, Zijun Huang, Yizhe Zhu, Kate Saenko: Federated Adversarial Domain Adaptation. ICLR 2020
Xingchao Peng, Yichen Li, Kate Saenko: Domain2Vec: Domain Embedding for Unsupervised Domain Adaptation. ECCV (6) 2020: 756-774
Shuhan Tan, Xingchao Peng, Kate Saenko: Generalized Domain Adaptation with Covariate and Label Shift CO-ALignment. CoRR abs/1910.10320 (2019)
Xingchao Peng, Zijun Huang, Ximeng Sun, Kate Saenko: Domain Agnostic Learning with Disentangled Representations. ICML 2019: 5102-5112
Xingchao Peng, Qinxun Bai, Xide Xia, Zijun Huang, Kate Saenko, Bo Wang: Moment Matching for Multi-Source Domain Adaptation. ICCV 2019: 1406-1415
Kuniaki Saito, Donghyun Kim, Stan Sclaroff, Trevor Darrell, Kate Saenko: Semi-Supervised Domain Adaptation via Minimax Entropy. ICCV 2019: 8049-8057
Kuniaki Saito, Yoshitaka Ushiku, Tatsuya Harada, Kate Saenko: Adversarial Dropout Regularization. ICLR (Poster) 2018
Xingchao Peng, Ben Usman, Neela Kaushik, Dequan Wang, Judy Hoffman, Kate Saenko: VisDA: A Synthetic-to-Real Benchmark for Visual Domain Adaptation. CVPR Workshops 2018: 2021-2026
Eric Tzeng, Judy Hoffman, Kate Saenko, Trevor Darrell: Adversarial Discriminative Domain Adaptation. CVPR 2017: 2962-2971
Baochen Sun, Kate Saenko: Deep CORAL: Correlation Alignment for Deep Domain Adaptation. ECCV Workshops (3) 2016: 443-450
Baochen Sun, Jiashi Feng, Kate Saenko: Return of Frustratingly Easy Domain Adaptation. AAAI 2016: 2058-2065
Eric Tzeng, Judy Hoffman, Trevor Darrell, Kate Saenko: Simultaneous Deep Transfer Across Domains and Tasks. ICCV 2015: 4068-4076
回歸正題,ADDA的訓(xùn)練流程圖如下:
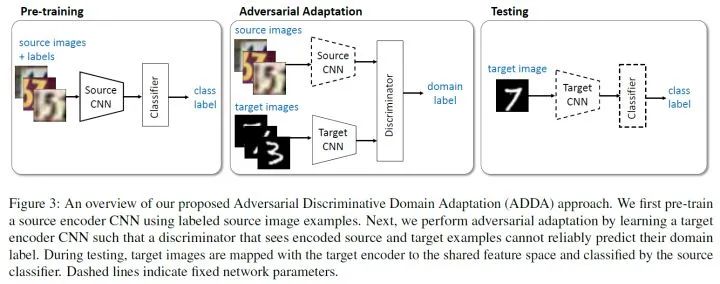
首先是預(yù)訓(xùn)練階段(Pre-training Stage),源域上利用有標(biāo)記數(shù)據(jù)訓(xùn)練,采用交叉熵?fù)p失:

其中? ?為源域的特征提取器,?
?為源域的特征提取器,? ?為源域的分類器。
?為源域的分類器。
然后是對抗對齊階段(Adversarial Adaptation Stage),將源域的特征提取器拷貝給目標(biāo)域? ?,并且將分類器??固定住遷移到目標(biāo)域。然后就是對?
?,并且將分類器??固定住遷移到目標(biāo)域。然后就是對? ?根據(jù)目標(biāo)域數(shù)據(jù)進(jìn)行微調(diào),當(dāng)且僅當(dāng)目標(biāo)域特征提取器??在目標(biāo)域提取的特征和源域特征提取器??在源域數(shù)據(jù)提取的特征相似時,源域的分類器才可以很好地適應(yīng)目標(biāo)域,即下面幾個公式的目的主要是使得?
?根據(jù)目標(biāo)域數(shù)據(jù)進(jìn)行微調(diào),當(dāng)且僅當(dāng)目標(biāo)域特征提取器??在目標(biāo)域提取的特征和源域特征提取器??在源域數(shù)據(jù)提取的特征相似時,源域的分類器才可以很好地適應(yīng)目標(biāo)域,即下面幾個公式的目的主要是使得? ?。
?。
簡單的方法仍然是使用對抗進(jìn)行訓(xùn)練。第一步訓(xùn)練域判別器(Discriminator)將源域的特征和目標(biāo)域的特征進(jìn)行區(qū)分開,? ?代表域判別器:
?代表域判別器:

第二步,訓(xùn)練??,使得? ?讓判別器盡可能分不開:
?讓判別器盡可能分不開:

重復(fù)以上兩步,直到收斂。
可以看出以上過程中, 源域特征提取器?只在源域預(yù)訓(xùn)練階段使用到,然后拷貝給目標(biāo)域,目標(biāo)域微調(diào)特征提取器。換句話說,源域訓(xùn)練好的模型,包括特征提取器和分類器,傳輸?shù)侥繕?biāo)域之后,目標(biāo)域只微調(diào)特征提取器,使得特征提取器提取的特征單向向源域的特征對齊,分類時使用的仍然是源域的分類器。
為什么說這個方法可以推廣到隱私保護(hù)呢?因為可以看到,源域的數(shù)據(jù)只在預(yù)訓(xùn)練階段利用到,且后面對齊的過程中只用到了源域的特征? ?,而不是?
?,而不是? ?,后者需要訪問到源域原始數(shù)據(jù)。
?,后者需要訪問到源域原始數(shù)據(jù)。
總的來說,ADDA容許源域和目標(biāo)域的特征提取器不一致,將? ?參數(shù)解耦開來,并且訓(xùn)練過程中其實只用到了源域的特征。如果,源域數(shù)據(jù)和目標(biāo)域數(shù)據(jù)不在同一設(shè)備上,假設(shè)源域數(shù)據(jù)的特征可以發(fā)送出去的話,該方案可以做到隱私保護(hù)。
?參數(shù)解耦開來,并且訓(xùn)練過程中其實只用到了源域的特征。如果,源域數(shù)據(jù)和目標(biāo)域數(shù)據(jù)不在同一設(shè)備上,假設(shè)源域數(shù)據(jù)的特征可以發(fā)送出去的話,該方案可以做到隱私保護(hù)。
3
FADA
正如上述介紹的CVL組,Xingchao Peng將ADDA擴(kuò)充到多域版本,并且提出了FADA。FADA來自ICLR2020的《Federated Adversarial Domain Adaptation》,論文首頁截圖如下:

該文提出了一個新的場景FADA,即聯(lián)邦學(xué)習(xí)下的多域遷移。假設(shè)有很多個源域,每個源域的數(shù)據(jù)分布在單獨(dú)的設(shè)備上,原始數(shù)據(jù)不能外傳,如何在這種情況下將其模型復(fù)用到目標(biāo)域呢?簡而言之,如何在數(shù)據(jù)不能被發(fā)送出去的約束下進(jìn)行特征對齊呢?
該文假設(shè)各個領(lǐng)域的特征可以被發(fā)送出去,和ADDA假設(shè)一致。假設(shè)有? ?個源域,每個源域上都訓(xùn)練了一個特征提取器?
?個源域,每個源域上都訓(xùn)練了一個特征提取器? ?和分類器?
?和分類器? ?,首先對于目標(biāo)域的特征提取器?
?,首先對于目標(biāo)域的特征提取器? ?和分類器?
?和分類器? ?,使用聯(lián)邦學(xué)習(xí)(Federated Learning)里面的加權(quán)平均方法:
?,使用聯(lián)邦學(xué)習(xí)(Federated Learning)里面的加權(quán)平均方法:

其中? ?衡量了每個源域?qū)δ繕?biāo)域的貢獻(xiàn),一般需要滿足?
?衡量了每個源域?qū)δ繕?biāo)域的貢獻(xiàn),一般需要滿足? ?。FADA中提到了一種動態(tài)加權(quán)(Dynamic Attention)的方式,這里不過多介紹,主要是通過源域當(dāng)前模型融合到目標(biāo)域之后對目標(biāo)域特征區(qū)分度的提升幅度作為衡量的標(biāo)準(zhǔn)。簡單的情況下,可以取?
?。FADA中提到了一種動態(tài)加權(quán)(Dynamic Attention)的方式,這里不過多介紹,主要是通過源域當(dāng)前模型融合到目標(biāo)域之后對目標(biāo)域特征區(qū)分度的提升幅度作為衡量的標(biāo)準(zhǔn)。簡單的情況下,可以取? ?。總之,目標(biāo)域上由于沒有標(biāo)記,不可能訓(xùn)練出?
?。總之,目標(biāo)域上由于沒有標(biāo)記,不可能訓(xùn)練出? ?,需要通過源域的模型進(jìn)行加權(quán)平均得到。
?,需要通過源域的模型進(jìn)行加權(quán)平均得到。
接下來,F(xiàn)ADA使用特征提取器在各個域上提取特征,即? ?,然后假設(shè)這些特征可以傳輸?shù)酵粋€設(shè)備上,就可以在該設(shè)備上訓(xùn)練一個域判別器(Domain Identifier, DI),注意這里的判別器和ADDA中不一樣,因為涉及到多個域,此處的域判別器是多分類器,具體而言是?
?,然后假設(shè)這些特征可以傳輸?shù)酵粋€設(shè)備上,就可以在該設(shè)備上訓(xùn)練一個域判別器(Domain Identifier, DI),注意這里的判別器和ADDA中不一樣,因為涉及到多個域,此處的域判別器是多分類器,具體而言是? ?分類。
?分類。
訓(xùn)練域判別器的損失函數(shù)如下:

其中? ?是向量的第?
?是向量的第? ?項,即上述目標(biāo)會訓(xùn)練域判別器使得第?
?項,即上述目標(biāo)會訓(xùn)練域判別器使得第? ?源域的數(shù)據(jù)會被預(yù)測為第??類別,且目標(biāo)域樣本被預(yù)測為第??類。
?源域的數(shù)據(jù)會被預(yù)測為第??類別,且目標(biāo)域樣本被預(yù)測為第??類。
訓(xùn)練好域判別器之后,將??發(fā)送到各個源域所在的設(shè)備,然后訓(xùn)練各自的特征提取器??去混淆??:

FADA總的框架圖如下,該框架融合了很多方法,還包括特征解耦(Feature Disentangle)等等,這里不過多介紹。
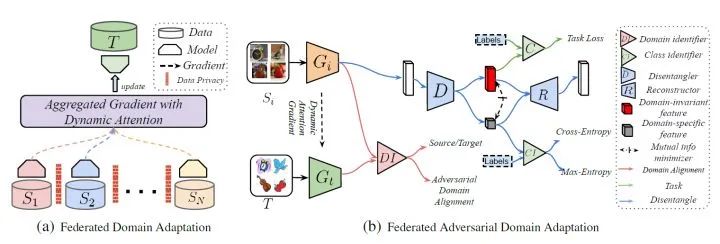
總的來說,F(xiàn)ADA將多個源域和目標(biāo)域的特征發(fā)送到一個指定的設(shè)備,在該設(shè)備上訓(xùn)練一個域判別器,然后將域判別器下發(fā)到各個源域作為對抗項促使相應(yīng)的特征提取器提取領(lǐng)域無關(guān)的特征。可以說,F(xiàn)ADA是ADDA的多領(lǐng)域擴(kuò)展版本。
4
SHOT
SHOT是比較有意思的一篇工作,名稱是《Do We Really Need to Access the Source Data? Source Hypothesis Transfer for Unsupervised Domain Adaptation》,來自ICML2020,作者信息截圖如下:

如果說ADDA和FADA都是假設(shè)源域數(shù)據(jù)不可以被發(fā)送出設(shè)備的話,SHOT假設(shè)源域數(shù)據(jù)獲取不到,即源域數(shù)據(jù)丟失或者不存在。
那么在只有源域模型和目標(biāo)域眾多無標(biāo)記數(shù)據(jù)的情況下,如何遷移呢?SHOT解決了這個問題。首先SHOT指的是Source Hypothesis Transfer,Source Hypothesis指的是源域模型的分類器。SHOT和ADDA有一個一致的地方就是,都固定住了源域模型的分類器,微調(diào)源域的特征提取器。ADDA通過對抗損失(假設(shè)可以訪問到源域數(shù)據(jù)的特征)進(jìn)行微調(diào)目標(biāo)域特征提取器,而SHOT則是通過偽標(biāo)簽(Pseudo Label)自監(jiān)督地訓(xùn)練。
首先,SHOT對源域模型進(jìn)行有監(jiān)督地訓(xùn)練,源域模型可以記為? ?,其中?
?,其中? ?分別是源域的特征提取器和分類器,訓(xùn)練時采用標(biāo)記平滑(Label Smoothing),促使訓(xùn)練的模型具有更好的可遷移性、泛化性。
?分別是源域的特征提取器和分類器,訓(xùn)練時采用標(biāo)記平滑(Label Smoothing),促使訓(xùn)練的模型具有更好的可遷移性、泛化性。
然后,將源域模型拷貝到目標(biāo)域,? ?,固定住?
?,固定住? ?,微調(diào)?
?,微調(diào)? ?。
?。
SHOT首先采用一個常見的信息最大化(Information Maximization, IM)損失,促使目標(biāo)域上每個樣本的分類概率的熵盡可能小,所有樣本預(yù)測的概率平均值盡可能均勻。假設(shè)目標(biāo)域樣本? ?預(yù)測的結(jié)果為?
?預(yù)測的結(jié)果為? ?,其中?
?,其中? ?是一個Softmax的函數(shù)。那么記?
?是一個Softmax的函數(shù)。那么記? ?為目標(biāo)域樣本預(yù)測概率的平均值(可以計算一個Batch的樣本預(yù)測概率的平均值)。那么IM損失為:
?為目標(biāo)域樣本預(yù)測概率的平均值(可以計算一個Batch的樣本預(yù)測概率的平均值)。那么IM損失為:

這一項損失并不能完全讓目標(biāo)域的特征提取器完全訓(xùn)練得當(dāng),因此需要使用下面的偽標(biāo)簽技術(shù)進(jìn)行訓(xùn)練。
偽標(biāo)簽技術(shù)很直觀,就是利用當(dāng)下的模型對無標(biāo)記樣本打標(biāo)簽,然后取預(yù)測結(jié)果置信度最高的部分樣本來打標(biāo)簽,然后用這些偽標(biāo)簽的數(shù)據(jù)來繼續(xù)訓(xùn)練這個模型。
比如,對于目標(biāo)域樣本??,根據(jù)模型預(yù)測概率的最大值? ?進(jìn)行排序,選擇最大的一部分對其打標(biāo)簽為?
?進(jìn)行排序,選擇最大的一部分對其打標(biāo)簽為? ?。直接使用偽標(biāo)簽訓(xùn)練很容易帶來誤差累計問題,因此需要盡可能使得偽標(biāo)簽打得準(zhǔn)確,可以使用一個標(biāo)簽精煉(Label Refinery)的過程。具體而言包括:
?。直接使用偽標(biāo)簽訓(xùn)練很容易帶來誤差累計問題,因此需要盡可能使得偽標(biāo)簽打得準(zhǔn)確,可以使用一個標(biāo)簽精煉(Label Refinery)的過程。具體而言包括:

其中? ?是第?
?是第? ?類樣本的類中心,?
?類樣本的類中心,? ?是距離函數(shù)。以上幾個公式可以看作是幾步K-Means操作,第一個公式根據(jù)模型輸出的概率值和每個樣本的特征向量進(jìn)行Soft加權(quán)得到類別中心,第二個公式根據(jù)每個樣本和各個類中心的距離打標(biāo)簽,第三個公式是Hard加權(quán)更新類中心,第四個公式是根據(jù)距離打標(biāo)簽。該迭代可以重復(fù)很多次,但是一般來說使用這兩步迭代之后的偽標(biāo)簽就會比較準(zhǔn)確了。
?是距離函數(shù)。以上幾個公式可以看作是幾步K-Means操作,第一個公式根據(jù)模型輸出的概率值和每個樣本的特征向量進(jìn)行Soft加權(quán)得到類別中心,第二個公式根據(jù)每個樣本和各個類中心的距離打標(biāo)簽,第三個公式是Hard加權(quán)更新類中心,第四個公式是根據(jù)距離打標(biāo)簽。該迭代可以重復(fù)很多次,但是一般來說使用這兩步迭代之后的偽標(biāo)簽就會比較準(zhǔn)確了。
以上就是標(biāo)簽精煉的過程,主要是指使用目標(biāo)域樣本的關(guān)系(聚簇結(jié)果)來對偽標(biāo)簽進(jìn)行進(jìn)一步調(diào)整,而不僅僅是利用模型的預(yù)測結(jié)果。
打了偽標(biāo)簽之后,模型可以根據(jù)交叉熵?fù)p失進(jìn)行訓(xùn)練,綜合IM損失,可以將模型性能提升至很高。
5
總? 結(jié)
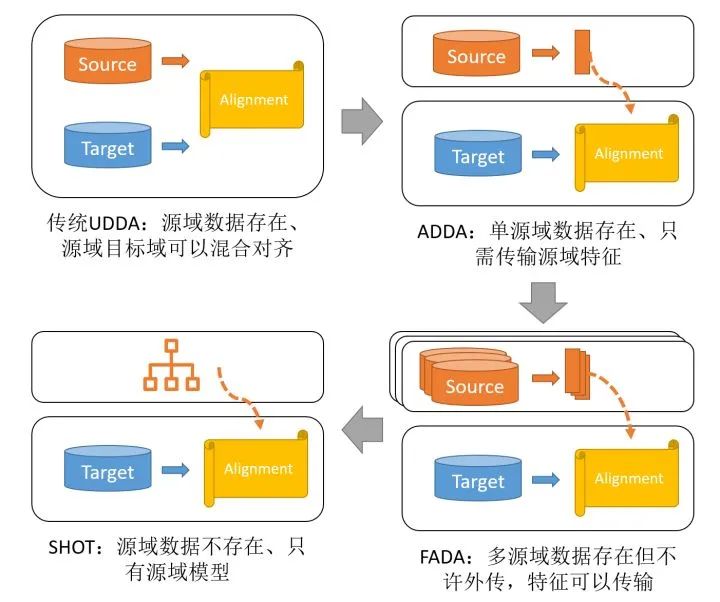
總結(jié)一下,傳統(tǒng)UDDA以及本文主要介紹的ADDA、FADA和SHOT可以使用下圖來區(qū)分:
參考文獻(xiàn)
Eric Tzeng, Judy Hoffman, Kate Saenko, Trevor Darrell: Adversarial Discriminative Domain Adaptation. CVPR 2017: 2962-2971
Xingchao Peng, Zijun Huang, Yizhe Zhu, Kate Saenko: Federated Adversarial Domain Adaptation. ICLR 2020
Jian Liang, Dapeng Hu, Jiashi Feng: Do We Really Need to Access the Source Data? Source Hypothesis Transfer for Unsupervised Domain Adaptation. CoRR abs/2002.08546 (2020)
往期精彩回顧
獲取本站知識星球優(yōu)惠券,復(fù)制鏈接直接打開:
https://t.zsxq.com/qFiUFMV
本站qq群704220115。
加入微信群請掃碼: