
深度學(xué)習(xí),強(qiáng)化學(xué)習(xí) ,遷移學(xué)習(xí)
本文轉(zhuǎn)自csdn,原文鏈接:https://blog.csdn.net/jiandanjinxin/article/details/54133521
深度學(xué)習(xí)的局限
表達(dá)能力的限制。因?yàn)橐粋€(gè)模型畢竟是一種現(xiàn)實(shí)的反映,等于是現(xiàn)實(shí)的鏡像,它能夠描述現(xiàn)實(shí)的能力越強(qiáng)就越準(zhǔn)確,而機(jī)器學(xué)習(xí)都是用變量來描述世界的,它的變量數(shù)是有限的,深度學(xué)習(xí)的深度也是有限的。另外它對數(shù)據(jù)的需求量隨著模型的增大而增大,但現(xiàn)實(shí)中有那么多高質(zhì)量數(shù)據(jù)的情況還不多。所以一方面是數(shù)據(jù)量,一方面是數(shù)據(jù)里面的變量、數(shù)據(jù)的復(fù)雜度,深度學(xué)習(xí)來描述數(shù)據(jù)的復(fù)雜度還不夠復(fù)雜。
缺乏反饋機(jī)制。目前深度學(xué)習(xí)對圖像識(shí)別、語音識(shí)別等問題來說是最好的,但是對其他的問題并不是最好的,特別是有延遲反饋的問題,例如機(jī)器人的行動(dòng),AlphaGo下圍棋也不是深度學(xué)習(xí)包打所有的,它還有強(qiáng)化學(xué)習(xí)的一部分,反饋是直到最后那一步才知道你的輸贏。還有很多其他的學(xué)習(xí)任務(wù)都不一定是深度學(xué)習(xí)才能來完成的。
針對深度學(xué)習(xí)的局限性,或許強(qiáng)化學(xué)習(xí)和遷移學(xué)習(xí)能夠解決相應(yīng)的問題。

強(qiáng)化學(xué)習(xí)是什么?
強(qiáng)化學(xué)習(xí)(Reinforcement Learning),就是智能系統(tǒng)從環(huán)境到行為映射的學(xué)習(xí),以使獎(jiǎng)勵(lì)信號(hào)(強(qiáng)化信號(hào))函數(shù)值最大。
強(qiáng)化學(xué)習(xí)不同于連接主義學(xué)習(xí)中的監(jiān)督學(xué)習(xí),主要表現(xiàn)在教師信號(hào)上,強(qiáng)化學(xué)習(xí)中由環(huán)境提供的強(qiáng)化信號(hào)是對產(chǎn)生動(dòng)作的好壞作一種評價(jià)(通常為標(biāo)量信號(hào)),而不是告訴強(qiáng)化學(xué)習(xí)系統(tǒng)RLS(reinforcement learning system)如何去產(chǎn)生正確的動(dòng)作。由于外部環(huán)境提供的信息很少,RLS必須靠自身的經(jīng)歷進(jìn)行學(xué)習(xí)。
通過這種方式,RLS在行動(dòng)-評價(jià)的環(huán)境中獲得知識(shí),改進(jìn)行動(dòng)方案以適應(yīng)環(huán)境。
之前ALPHGO 大戰(zhàn) 李世石 4:1
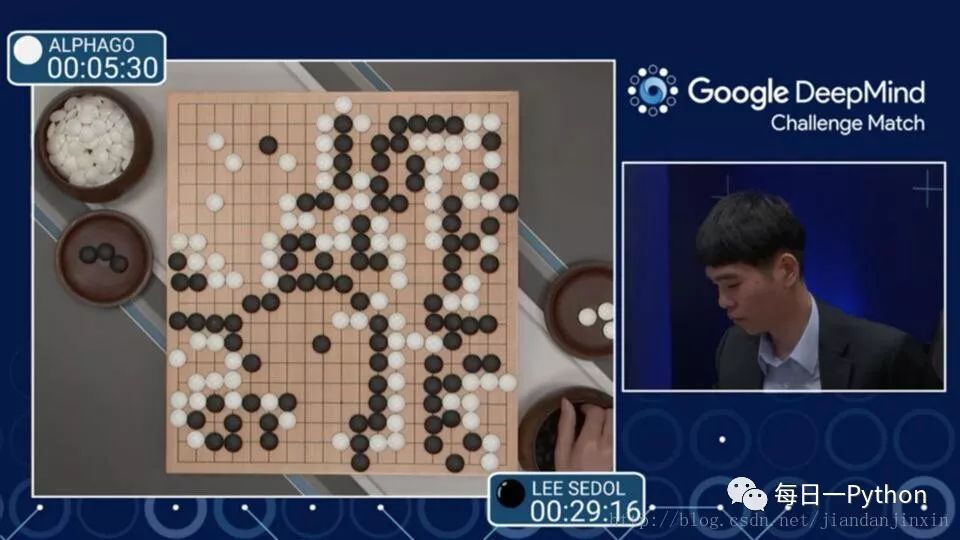
目前的 Master 大戰(zhàn)中日韓圍棋世界冠軍 60:0
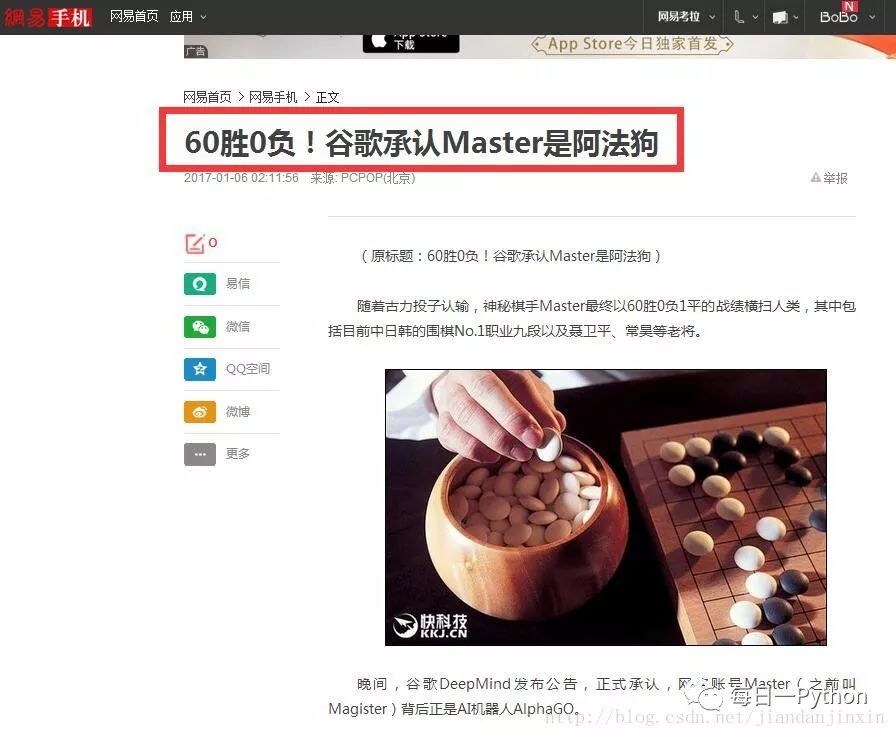
背后的 DeepMind 就是將深度學(xué)習(xí)應(yīng)用到強(qiáng)化學(xué)習(xí)中去的范例。
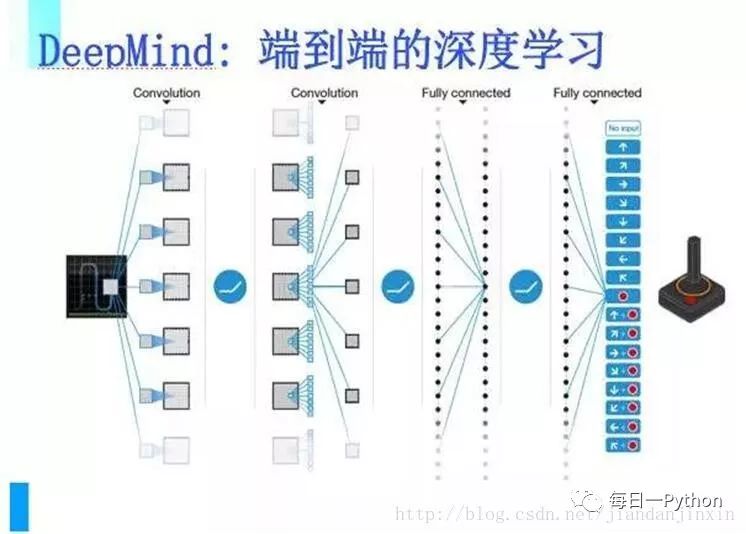
DeepMind把端到端的深度學(xué)習(xí)應(yīng)用在強(qiáng)化學(xué)習(xí)上,使得強(qiáng)化學(xué)習(xí)能夠應(yīng)付大數(shù)據(jù),因此能在圍棋上把人類完全擊倒,它做到這樣是通過完全的自學(xué)習(xí)、自我修煉、自我改正,然后一個(gè)一個(gè)迭代。
深度學(xué)習(xí)是一種端到端的學(xué)習(xí)方式,整個(gè)學(xué)習(xí)過程中不需要中間的和顯著的人類參與。直接把海量數(shù)據(jù)投放到算法中,讓數(shù)據(jù)自己說話,系統(tǒng)會(huì)自動(dòng)從數(shù)據(jù)中學(xué)習(xí)。從輸入到輸出是一個(gè)完全自動(dòng)的過程。
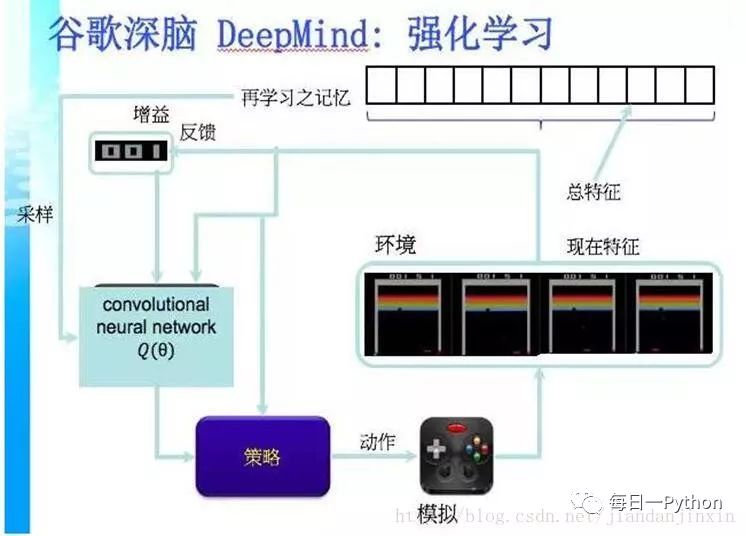
永動(dòng)機(jī)器學(xué)習(xí)
CMU大學(xué)的例子,用中文來說是永動(dòng)機(jī)器學(xué)習(xí),這個(gè)機(jī)器不斷在網(wǎng)上扒一些網(wǎng)頁,在每個(gè)網(wǎng)頁里面都學(xué)到一些知識(shí),把這些知識(shí)綜合起來,變成幾千萬條知識(shí),這些知識(shí)又會(huì)衍生新的知識(shí)。那么我們看到從下到上是隨著時(shí)間,知識(shí)量在增長。但是它到了某一個(gè)程度實(shí)際上是不能再往上走了,因?yàn)橹R(shí)會(huì)自我矛盾。這個(gè)時(shí)候就需要人來進(jìn)行一部分的調(diào)節(jié),把一部分不正確的知識(shí)去掉,讓它繼續(xù)能成長。這個(gè)過程為什么會(huì)發(fā)生呢?
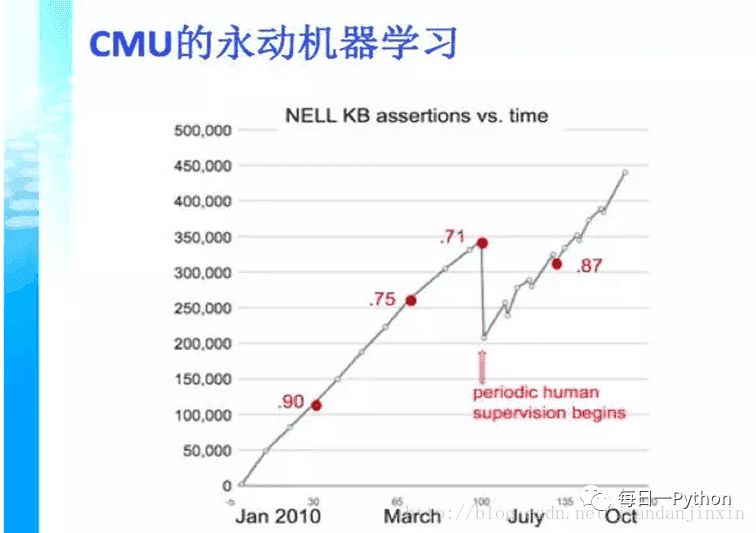
是因?yàn)闄C(jī)器學(xué)習(xí)有一個(gè)很嚴(yán)重的現(xiàn)象,就是自我偏差,這種偏差可以體現(xiàn)在統(tǒng)計(jì)學(xué)的一個(gè)重要概念中,就是我們獲得的數(shù)據(jù)也許是一個(gè)有偏數(shù)據(jù),我們可能建了一個(gè)模型,對大部分的數(shù)據(jù)都有用,但其中有一些特例。我們?nèi)绾蝸硖幚磉@些特例,如何來處理我們訓(xùn)練數(shù)據(jù)和應(yīng)用數(shù)據(jù)之間的偏差,這是我們下一步要研究的內(nèi)容。
兩個(gè)問題:數(shù)據(jù)量大,有偏數(shù)據(jù);數(shù)據(jù)量少。

為了解決以上問題,下面我們來看幾個(gè)示例




以上示例都是人類的遷移學(xué)習(xí)的能力。
遷移學(xué)習(xí)是什么?
所謂遷移學(xué)習(xí),或者領(lǐng)域適應(yīng)Domain Adaptation,一般就是要將從源領(lǐng)域(Source Domain)學(xué)習(xí)到的東西應(yīng)用到目標(biāo)領(lǐng)域(Target Domain)上去。源領(lǐng)域和目標(biāo)領(lǐng)域之間往往有g(shù)ap/domain discrepancy(源領(lǐng)域的數(shù)據(jù)和目標(biāo)領(lǐng)域的數(shù)據(jù)遵循不同的分布)。
遷移學(xué)習(xí)能夠?qū)⑦m用于大數(shù)據(jù)的模型遷移到小數(shù)據(jù)上,實(shí)現(xiàn)個(gè)性化遷移。
遷移什么,怎么遷移,什么時(shí)候能遷移,這是遷移學(xué)習(xí)要解決的主要問題。
遷移學(xué)習(xí)能解決那些問題?
小數(shù)據(jù)的問題。比方說新開一個(gè)網(wǎng)店,賣一種新的糕點(diǎn),沒有任何的數(shù)據(jù),就無法建立模型對用戶進(jìn)行推薦。但用戶買一個(gè)東西會(huì)反映到用戶可能還會(huì)買另外一個(gè)東西,所以如果知道用戶在另外一個(gè)領(lǐng)域,比方說賣飲料,已經(jīng)有了很多很多的數(shù)據(jù),利用這些數(shù)據(jù)建一個(gè)模型,結(jié)合用戶買飲料的習(xí)慣和買糕點(diǎn)的習(xí)慣的關(guān)聯(lián),就可以把飲料的推薦模型給成功地遷移到糕點(diǎn)的領(lǐng)域,這樣,在數(shù)據(jù)不多的情況下可以成功推薦一些用戶可能喜歡的糕點(diǎn)。這個(gè)例子就說明,有兩個(gè)領(lǐng)域,一個(gè)領(lǐng)域已經(jīng)有很多的數(shù)據(jù),能成功地建一個(gè)模型,有一個(gè)領(lǐng)域數(shù)據(jù)不多,但是和前面那個(gè)領(lǐng)域是關(guān)聯(lián)的,就可以把那個(gè)模型給遷移過來。
個(gè)性化的問題。比如每個(gè)人都希望自己的手機(jī)能夠記住一些習(xí)慣,這樣不用每次都去設(shè)定它,怎么才能讓手機(jī)記住這一點(diǎn)呢?其實(shí)可以通過遷移學(xué)習(xí)把一個(gè)通用的用戶使用手機(jī)的模型遷移到個(gè)性化的數(shù)據(jù)上面。
遷移學(xué)習(xí)四種實(shí)現(xiàn)方法
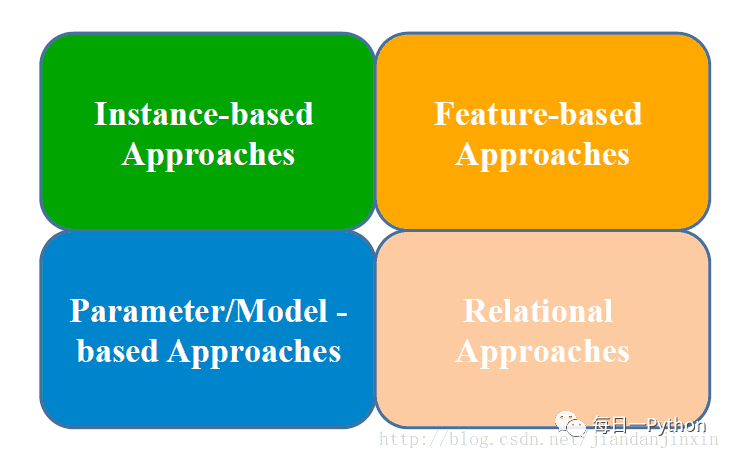
1. 樣本遷移 Instance-based Transfer Learning

一般是對樣本進(jìn)行加權(quán),給比較重要的樣本較大的權(quán)重。
樣本遷移即在數(shù)據(jù)集(源領(lǐng)域)中找到與目標(biāo)領(lǐng)域相似的數(shù)據(jù),把這個(gè)數(shù)據(jù)放大多倍,與目標(biāo)領(lǐng)域的數(shù)據(jù)進(jìn)行匹配。其特點(diǎn)是:需要對不同例子加權(quán);需要用數(shù)據(jù)進(jìn)行訓(xùn)練。
2. 特征遷移 Feature-based Transfer Learning

在特征空間進(jìn)行遷移,一般需要把源領(lǐng)域和目標(biāo)領(lǐng)域的特征投影到同一個(gè)特征空間里進(jìn)行。
特征遷移是通過觀察源領(lǐng)域圖像與目標(biāo)域圖像之間的共同特征,然后利用觀察所得的共同特征在不同層級(jí)的特征間進(jìn)行自動(dòng)遷移。
3. 模型遷移 Model-based Transfer Learning

整個(gè)模型應(yīng)用到目標(biāo)領(lǐng)域去,比如目前常用的對預(yù)訓(xùn)練好的深度網(wǎng)絡(luò)做微調(diào),也可以叫做參數(shù)遷移。
模型遷移利用上千萬的圖象訓(xùn)練一個(gè)圖象識(shí)別的系統(tǒng),當(dāng)我們遇到一個(gè)新的圖象領(lǐng)域,就不用再去找?guī)浊f個(gè)圖象來訓(xùn)練了,可以原來的圖像識(shí)別系統(tǒng)遷移到新的領(lǐng)域,所以在新的領(lǐng)域只用幾萬張圖片同樣能夠獲取相同的效果。模型遷移的一個(gè)好處是可以和深度學(xué)習(xí)結(jié)合起來,我們可以區(qū)分不同層次可遷移的度,相似度比較高的那些層次他們被遷移的可能性就大一些
4. 關(guān)系遷移 Relational Transfer Learning
社會(huì)網(wǎng)絡(luò),社交網(wǎng)絡(luò)之間的遷移。

前沿的遷移學(xué)習(xí)方向
Reinforcement Transfer Learning
怎么遷移智能體學(xué)習(xí)到的知識(shí):比如我學(xué)會(huì)了一個(gè)游戲,那么我在另一個(gè)相似的游戲里面也是可以應(yīng)用一些類似的策略的
Transitive Transfer Learning
傳遞性遷移學(xué)習(xí),兩個(gè)domain之間如果相隔得太遠(yuǎn),那么我們就插入一些intermediate domains,一步步做遷移
Source-Free Transfer Learning
不知道是哪個(gè)源領(lǐng)域
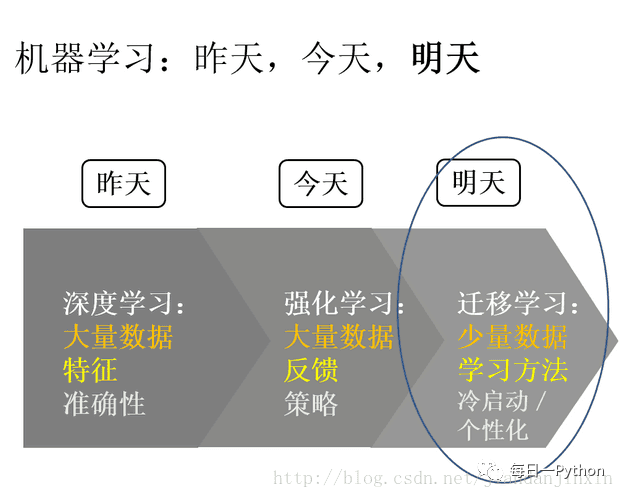
最后用一張圖總結(jié)一下深度學(xué)習(xí)、強(qiáng)化學(xué)習(xí)、遷移學(xué)習(xí)的趨勢
參考資料:
https://mp.weixin.qq.com/s?__biz=MzAwMjM2Njg2Nw==&mid=2653144126&idx=1&sn=d9633d71ed89590100422c85f6bdb845
http://mp.weixin.qq.com/s?__biz=MzI3MTA0MTk1MA==&mid=2651982064&idx=1&sn=92e65d423db5aa79d8c8c782afc19111&scene=1&srcid=0426Sj6blqQWPuyUb8qCswf3&from=singlemessage&isappinstalled=0#wechat_redirect
http://geek.csdn.net/news/detail/92051
http://www.leiphone.com/news/201612/hF1AX5yNwcxtf005.html
https://zhuanlan.zhihu.com/p/22023097
版權(quán)聲明:本文為CSDN博主「帥氣的弟八哥」的原創(chuàng)文章,遵循 CC 4.0 BY-SA 版權(quán)協(xié)議,轉(zhuǎn)載請附上原文出處鏈接及本聲明。
原文鏈接:https://blog.csdn.net/jiandanjinxin/article/details/54133521
《數(shù)據(jù)科學(xué)與人工智能》公眾號(hào)推薦朋友們學(xué)習(xí)和使用Python語言,需要加入Python語言群的,請掃碼加我個(gè)人微信,備注【姓名-Python群】,我誠邀你入群,大家學(xué)習(xí)和分享。