
Service Mesh架構(gòu)新技能之eBPF入門與實踐
在分享這篇文章之前,先簡單和大家說下背景。在之前的文章中作者分享了一些關(guān)于Service Mesh微服務架構(gòu)的文章,在Service Mesh架構(gòu)中需要通過SideCar代理的方式對應用容器流量進行劫持,并以此實現(xiàn)微服務治理相關(guān)的各種能力。但這種SideCar方式在微服務數(shù)量過多時會造成系統(tǒng)性能的降低,因為SideCar本質(zhì)上來說,也是通過用戶代碼實現(xiàn)的網(wǎng)絡代理來進行流量管控的。而eBPF則是一種替代SideCar的新式解決方案,它存在于操作系統(tǒng)的內(nèi)核層級,在性能上表現(xiàn)更優(yōu)。
因此目前關(guān)于Service Mesh微服務架構(gòu)的技術(shù)方案開始逐步趨向于使用eBPF來替代原先的像Envoy這樣的SideCar代理。本文的內(nèi)容將詳細介紹eBPF的前世今生,具體如下:
技術(shù)背景
eBPF 源于 BPF,本質(zhì)上是處于內(nèi)核中的一個高效與靈活的虛類虛擬機組件,以一種安全的方式在許多內(nèi)核 hook 點執(zhí)行字節(jié)碼。BPF 最初的目的是用于高效網(wǎng)絡報文過濾,經(jīng)過重新設計,eBPF 不再局限于網(wǎng)絡協(xié)議棧,已經(jīng)成為內(nèi)核頂級的子系統(tǒng),演進為一個通用執(zhí)行引擎。
開發(fā)者可基于 eBPF 開發(fā)性能分析工具、軟件定義網(wǎng)絡、安全等諸多場景。本文將介紹 eBPF 的前世今生,并構(gòu)建一個 eBPF 環(huán)境進行開發(fā)實踐,文中所有的代碼可以在我的 GitHub[1]?中找到。
發(fā)展歷史
BPF,是類 Unix 系統(tǒng)上數(shù)據(jù)鏈路層的一種原始接口,提供原始鏈路層封包的收發(fā)。1992 年,Steven McCanne 和 Van Jacobson 寫了一篇名為《The BSD Packet Filter: A New Architecture for User-level Packet Capture[2]》的論文。在文中,作者描述了他們?nèi)绾卧?Unix 內(nèi)核實現(xiàn)網(wǎng)絡數(shù)據(jù)包過濾,這種新的技術(shù)比當時最先進的數(shù)據(jù)包過濾技術(shù)快 20 倍。
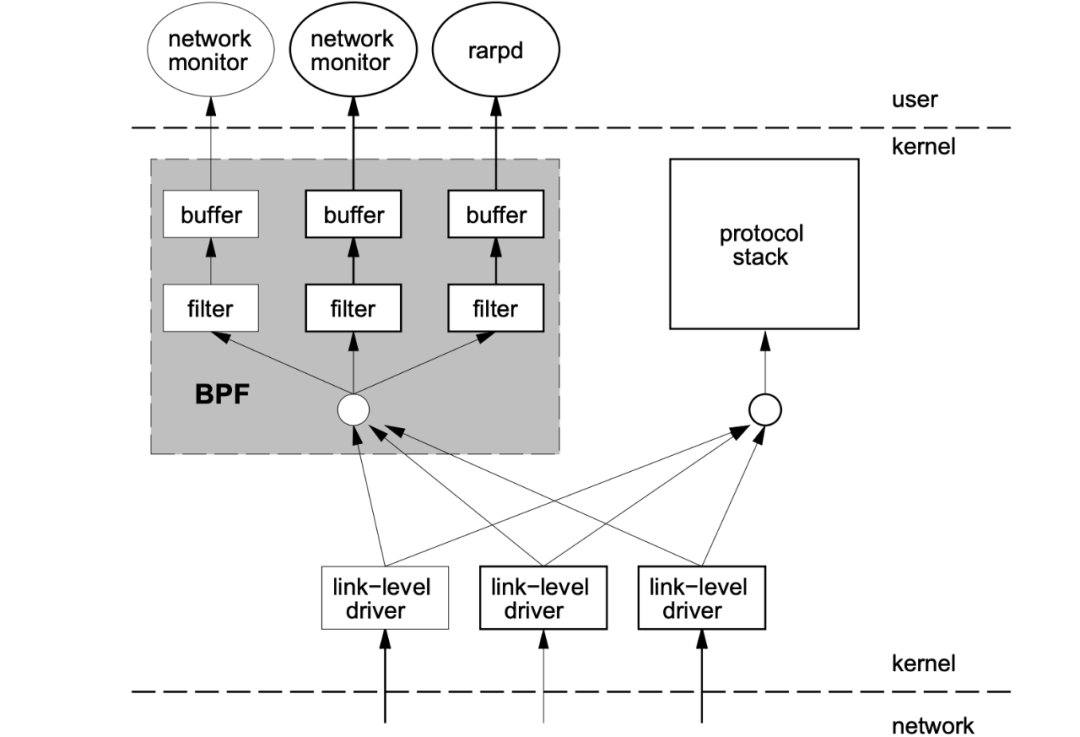
BPF 在數(shù)據(jù)包過濾上引入了兩大革新:
一個新的虛擬機 (VM) 設計,可以有效地工作在基于寄存器結(jié)構(gòu)的 CPU 之上
應用程序使用緩存只復制與過濾數(shù)據(jù)包相關(guān)的數(shù)據(jù),不會復制數(shù)據(jù)包的所有信息,這樣可以最大程度地減少BPF 處理的數(shù)據(jù)
由于這些巨大的改進,所有的 Unix 系統(tǒng)都選擇采用 BPF 作為網(wǎng)絡數(shù)據(jù)包過濾技術(shù),直到今天,許多 Unix 內(nèi)核的派生系統(tǒng)中(包括 Linux 內(nèi)核)仍使用該實現(xiàn)。tcpdump 的底層采用 BPF 作為底層包過濾技術(shù),我們可以在命令后面增加?-d 來查看 tcpdump 過濾條件的底層匯編指令。
$?tcpdump?-d?'ip?and?tcp?port?8080'
(000)?ldh??????[12]
(001)?jeq??????#0x800???????????jt?2?jf?12
(002)?ldb??????[23]
(003)?jeq??????#0x6?????????????jt?4?jf?12
(004)?ldh??????[20]
(005)?jset?????#0x1fff??????????jt?12?jf?6
(006)?ldxb?????4*([14]&0xf)
(007)?ldh??????[x?+?14]
(008)?jeq??????#0x1f90??????????jt?11?jf?9
(009)?ldh??????[x?+?16]
(010)?jeq??????#0x1f90??????????jt?11?jf?12
(011)?ret??????#262144
(012)?ret??????#0
2014 年初,Alexei Starovoitov 實現(xiàn)了 eBPF(extended Berkeley Packet Filter)。經(jīng)過重新設計,eBPF 演進為一個通用執(zhí)行引擎,可基于此開發(fā)性能分析工具、軟件定義網(wǎng)絡等諸多場景。
eBPF 最早出現(xiàn)在 3.18 內(nèi)核中,此后原來的 BPF 就被稱為經(jīng)典 BPF,縮寫 cBPF(classic BPF),cBPF 現(xiàn)在已經(jīng)基本廢棄。現(xiàn)在,Linux 內(nèi)核只運行 eBPF,內(nèi)核會將加載的 cBPF 字節(jié)碼透明地轉(zhuǎn)換成 eBPF 再執(zhí)行。
eBPF 與 cBPF
eBPF 新的設計針對現(xiàn)代硬件進行了優(yōu)化,所以 eBPF 生成的指令集比舊的 BPF 解釋器生成的機器碼執(zhí)行得更快。擴展版本也增加了虛擬機中的寄存器數(shù)量,將原有的 2 個 32 位寄存器增加到 10 個 64 位寄存器。
由于寄存器數(shù)量和寬度的增加,開發(fā)人員可以使用函數(shù)參數(shù)自由交換更多的信息,編寫更復雜的程序。總之,這些改進使 eBPF 版本的速度比原來的 BPF 提高了 4 倍。
| 維度 | cBPF | eBPF |
|---|---|---|
| 內(nèi)核版本 | Linux 2.1.75(1997 年) | Linux 3.18(2014 年)[4.x for kprobe/uprobe/tracepoint/perf-event] |
| 寄存器數(shù)目 | 2 個:A,X | 10個:R0–R9,另外 R10 是一個只讀的幀指針
|
| 寄存器寬度 | 32 位 | 64 位 |
| 存儲 | 16 個內(nèi)存位: M[0–15] | 512 字節(jié)堆棧,無限制大小的?map?存儲 |
| 限制的內(nèi)核調(diào)用 | 非常有限,僅限于 JIT 特定 | 有限,通過 bpf_call 指令調(diào)用 |
| 目標事件 | 數(shù)據(jù)包、?seccomp-BPF | 數(shù)據(jù)包、內(nèi)核函數(shù)、用戶函數(shù)、跟蹤點 PMCs 等 |
2014 年 6 月,eBPF 擴展到用戶空間,這也成為了 BPF 技術(shù)的轉(zhuǎn)折點。正如 Alexei 在提交補丁的注釋中寫到:「這個補丁展示了 eBPF 的潛力」。當前,eBPF 不再局限于網(wǎng)絡棧,已經(jīng)成為內(nèi)核頂級的子系統(tǒng)。
eBPF 與內(nèi)核模塊
對比 Web 的發(fā)展,eBPF 與內(nèi)核的關(guān)系有點類似于 JavaScript 與瀏覽器內(nèi)核的關(guān)系,eBPF 相比于直接修改內(nèi)核和編寫內(nèi)核模塊提供了一種新的內(nèi)核可編程的選項。eBPF 程序架構(gòu)強調(diào)安全性和穩(wěn)定性,看上去更像內(nèi)核模塊,但與內(nèi)核模塊不同,eBPF 程序不需要重新編譯內(nèi)核,并且可以確保 eBPF 程序運行完成,而不會造成系統(tǒng)的崩潰。
| 維度 | Linux?內(nèi)核模塊 | eBPF |
|---|---|---|
| kprobes/tracepoints | 支持 | 支持 |
| 安全性 | 可能引入安全漏洞或?qū)е聝?nèi)核 Panic | 通過驗證器進行檢查,可以保障內(nèi)核安全 |
| 內(nèi)核函數(shù) | 可以調(diào)用內(nèi)核函數(shù) | 只能通過 BPF Helper 函數(shù)調(diào)用 |
| 編譯性 | 需要編譯內(nèi)核 | 不需要編譯內(nèi)核,引入頭文件即可 |
| 運行 | 基于相同內(nèi)核運行 | 基于穩(wěn)定 ABI 的 BPF 程序可以編譯一次,各處運行 |
| 與應用程序交互 | 打印日志或文件 | 通過 perf_event 或 map 結(jié)構(gòu) |
| 數(shù)據(jù)結(jié)構(gòu) | 豐富性 | 一般豐富 |
| 入門門檻 | 高 | 低 |
| 升級 | 需要卸載和加載,可能導致處理流程中斷 | 原子替換升級,不會造成處理流程中斷 |
| 內(nèi)核內(nèi)置 | 視情況而定 | 內(nèi)核內(nèi)置支持 |
eBPF 架構(gòu)
eBPF 分為用戶空間程序和內(nèi)核程序兩部分:
用戶空間程序負責加載 BPF 字節(jié)碼至內(nèi)核,如需要也會負責讀取內(nèi)核回傳的統(tǒng)計信息或者事件詳情
內(nèi)核中的 BPF 字節(jié)碼負責在內(nèi)核中執(zhí)行特定事件,如需要也會將執(zhí)行的結(jié)果通過 maps 或者 perf-event 事件發(fā)送至用戶空間
其中用戶空間程序與內(nèi)核 BPF 字節(jié)碼程序可以使用 map 結(jié)構(gòu)實現(xiàn)雙向通信,這為內(nèi)核中運行的 BPF 字節(jié)碼程序提供了更加靈活的控制
eBPF 整體結(jié)構(gòu)圖如下:
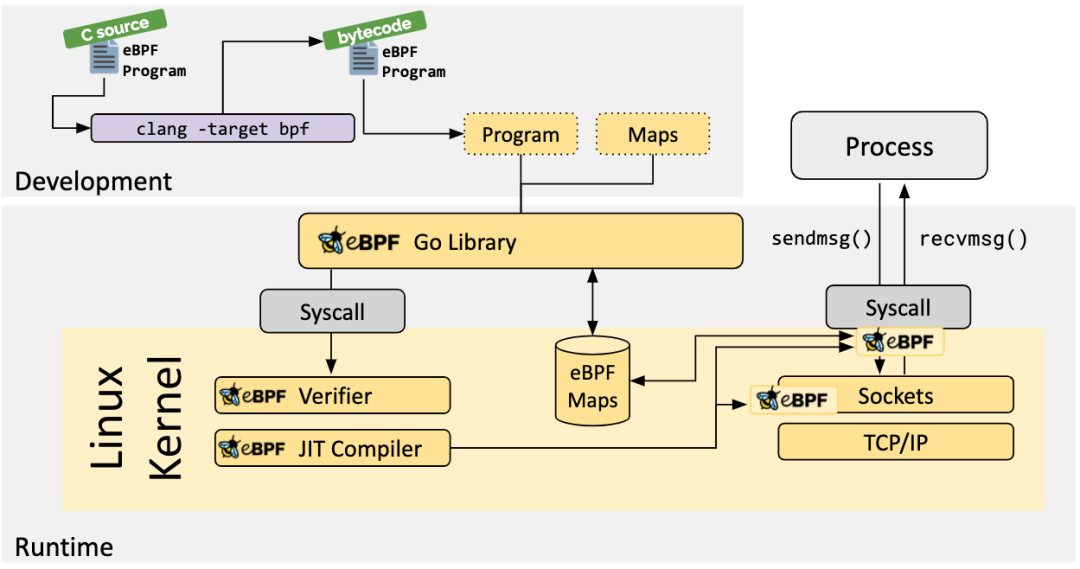
用戶空間程序與內(nèi)核中的 BPF 字節(jié)碼交互的流程主要如下:
1、使用 LLVM 或者 GCC 工具將編寫的 BPF 代碼程序編譯成 BPF 字節(jié)碼
2、使用加載程序 Loader 將字節(jié)碼加載至內(nèi)核
3、內(nèi)核使用驗證器(Verfier) 組件保證執(zhí)行字節(jié)碼的安全性,以避免對內(nèi)核造成災難,在確認字節(jié)碼安全后將其加載對應的內(nèi)核模塊執(zhí)行
4、內(nèi)核中運行的 BPF 字節(jié)碼程序可以使用兩種方式將數(shù)據(jù)回傳至用戶空間:
maps 方式可用于將內(nèi)核中實現(xiàn)的統(tǒng)計摘要信息(比如測量延遲、堆棧信息)等回傳至用戶空間;
perf-event 用于將內(nèi)核采集的事件實時發(fā)送至用戶空間,用戶空間程序?qū)崟r讀取分析。
eBPF 限制
eBPF 技術(shù)雖然強大,但是為了保證內(nèi)核的處理安全和及時響應,內(nèi)核中的 eBPF 技術(shù)也給予了諸多限制,當然隨著技術(shù)的發(fā)展和演進,限制也在逐步放寬或者提供了對應的解決方案。
eBPF 程序不能調(diào)用任意的內(nèi)核參數(shù),只限于內(nèi)核模塊中列出的 BPF Helper 函數(shù),函數(shù)支持列表也隨著內(nèi)核的演進在不斷增加。
eBPF 程序不允許包含無法到達的指令,防止加載無效代碼,延遲程序的終止。
eBPF 程序中循環(huán)次數(shù)限制且必須在有限時間內(nèi)結(jié)束,這主要是用來防止在 kprobes 中插入任意的循環(huán),導致鎖住整個系統(tǒng);解決辦法包括展開循環(huán),并為需要循環(huán)的常見用途添加輔助函數(shù)。Linux 5.3 在 BPF 中包含了對有界循環(huán)的支持,它有一個可驗證的運行時間上限。
eBPF 堆棧大小被限制在 MAX_BPF_STACK,截止到內(nèi)核 Linux 5.8 版本,被設置為 512;參見 include/linux/filter.h[3],這個限制特別是在棧上存儲多個字符串緩沖區(qū)時:一個char[256]緩沖區(qū)會消耗這個棧的一半。目前沒有計劃增加這個限制,解決方法是改用 bpf 映射存儲,它實際上是無限的。
/*?BPF?program?can?access?up?to?512?bytes?of?stack?space.?*/
#define?MAX_BPF_STACK?512
eBPF 字節(jié)碼大小最初被限制為 4096 條指令,截止到內(nèi)核 Linux 5.8 版本, 當前已將放寬至 100 萬指令( BPF_COMPLEXITY_LIMIT_INSNS),參見:include/linux/bpf.h[4],對于無權(quán)限的BPF程序,仍然保留4096條限制 ( BPF_MAXINSNS );新版本的 eBPF 也支持了多個 eBPF 程序級聯(lián)調(diào)用,雖然傳遞信息存在某些限制,但是可以通過組合實現(xiàn)更加強大的功能。
#define?BPF_COMPLEXITY_LIMIT_INSNS??????1000000?/*?yes.?1M?insns?*/
—?2?—
eBPF 實戰(zhàn)
在深入介紹 eBPF 特性之前,讓我們 Get Hands Dirty,切切實實的感受 eBPF 程序到底是什么,我們該如何開發(fā) eBPF 程序。隨著 eBPF 生態(tài)的演進,現(xiàn)在已經(jīng)有越來越多的工具鏈用于開發(fā) eBPF 程序,在后文也會詳細介紹:
基于 bcc 開發(fā):bcc 提供了對 eBPF 開發(fā),前段提供 Python API,后端 eBPF 程序通過 C 實現(xiàn)。特點是簡單易用,但是性能較差。
基于 libebpf-bootstrap 開發(fā):libebpf-bootstrap 提供了一個方便的腳手架。
基于內(nèi)核源碼開發(fā):內(nèi)核源碼開發(fā)門檻較高,但是也更加切合 eBPF 底層原理,所以這里以這個方法作為示例。
內(nèi)核源碼編譯
系統(tǒng)環(huán)境如下,采用騰訊云 CVM,Ubuntu 20.04,內(nèi)核版本 5.4.0。
$?uname?-a
Linux?VM-1-3-ubuntu?5.4.0-42-generic?#46-Ubuntu?SMP?Fri?Jul?10?00:24:02?UTC?2020?x86_64?x86_64?x86_64?GNU/Linux
首先安裝必要依賴:
sudo?apt?install?-y?bison?build-essential?cmake?flex?git?libedit-dev?pkg-config?libmnl-dev?\
???python?zlib1g-dev?libssl-dev?libelf-dev?libcap-dev?libfl-dev?llvm?clang?pkg-config?\
???gcc-multilib?luajit?libluajit-5.1-dev?libncurses5-dev?libclang-dev?clang-tools
一般情況下推薦采用 apt 方式的安裝源碼,安裝簡單而且只安裝當前內(nèi)核的源碼,源碼的大小在 200M 左右。
#?apt-cache?search?linux-source
#?apt?install?linux-source-5.4.0
源碼安裝至?/usr/src/?目錄下。
$?ls?-hl
total?4.0K
drwxr-xr-x?4?root?root?4.0K?Nov??9?13:22?linux-source-5.4.0
lrwxrwxrwx?1?root?root???45?Oct?15?10:28?linux-source-5.4.0.tar.bz2?->?linux-source-5.4.0/linux-source-5.4.0.tar.bz2
$?tar?-jxvf?linux-source-5.4.0.tar.bz2
$?cd?linux-source-5.4.0
$?cp?-v?/boot/config-$(uname?-r)?.config?#?make?defconfig?或者?make?menuconfig
$?make?headers_install
$?make?modules_prepare
$?make?scripts?????#?可選
$?make?M=samples/bpf??#?如果配置出錯,可以使用?make?oldconfig?&&?make?prepare?修復
Hello World
前面說到 eBPF 通常由內(nèi)核空間程序和用戶空間程序兩部分組成,現(xiàn)在 samples/bpf 目錄下有很多這種程序,內(nèi)核空間程序以?_kern.c 結(jié)尾,用戶空間程序以?_user.c 結(jié)尾。先不看這些復雜的程序,我們手動寫一個 eBPF 程序的 Hello World。
內(nèi)核中的程序 hello_kern.c:
#include?
#include?"bpf_helpers.h"
#define?SEC(NAME)?__attribute__((section(NAME),?used))
SEC("tracepoint/syscalls/sys_enter_execve")
int?bpf_prog(void?*ctx)
{
????char?msg[]?=?"Hello?BPF?from?houmin!\n";
????bpf_trace_printk(msg,?sizeof(msg));
????return?0;
}
char?_license[]?SEC("license")?=?"GPL";
函數(shù)入口:
上述代碼和普通的C語言編程有一些區(qū)別。
程序的入口通過編譯器的 pragama __section("tracepoint/syscalls/sys_enter_execve")?指定的。
入口的參數(shù)不再是 argc, argv, 它根據(jù)不同的 prog type 而有所差別。我們的例子中,prog type 是 BPF_PROG_TYPE_TRACEPOINT, 它的入口參數(shù)就是 void *ctx。
頭文件:
#include?
這個頭文件的來源是kernel source header file 。它安裝在?/usr/include/linux/bpf.h中。
它提供了bpf 編程需要的很多symbol。例如:
enum bpf_func_id 定義了所有的kerne helper function 的id
enum bpf_prog_type 定義了內(nèi)核支持的所有的prog 的類型。
struct __sk_buff 是bpf 代碼中訪問內(nèi)核struct sk_buff的接口。
等等
#include?“bpf_helpers.h”
來自libbpf ,需要自行安裝。我們引用這個頭文件是因為調(diào)用了bpf_printk()。這是一個kernel helper function。
程序解釋:
這里我們簡單解讀下內(nèi)核態(tài)的 ebpf 程序,非常簡單:
bpf_trace_printk?是一個 eBPF helper 函數(shù),用于打印信息到?trace_pipe?(/sys/kernel/debug/tracing/trace_pipe),詳見這里[5]
代碼聲明了?SEC?宏,并且定義了 GPL 的 License,這是因為加載進內(nèi)核的 eBPF 程序需要有 License 檢查,類似于內(nèi)核模塊
加載 BPF 代碼:
用戶態(tài)程序 hello_user.c:
#include?
#include?"bpf_load.h"
int?main(int?argc,?char?**argv)
{
????if(load_bpf_file("hello_kern.o")?!=?0)
????{
????????printf("The?kernel?didn't?load?BPF?program\n");
????????return?-1;
????}
????read_trace_pipe();
????return?0;
}
在用戶態(tài) ebpf 程序中,解讀如下:
通過?load_bpf_file?將編譯出的內(nèi)核態(tài) ebpf 目標文件加載到內(nèi)核
通過?read_trace_pipe?從?trace_pipe?讀取 trace 信息,打印到控制臺中
修改 samples/bpf 目錄下的 Makefile 文件,在對應的位置添加以下三行:
hostprogs-y?+=?hello
hello-objs?:=?bpf_load.o?hello_user.o
always?+=?hello_kern.o
重新編譯,可以看到編譯成功的文件:
$?make?M=samples/bpf
$?ls?-hl?samples/bpf/hello*
-rwxrwxr-x?1?ubuntu?ubuntu?404K?Mar?30?17:48?samples/bpf/hello
-rw-rw-r--?1?ubuntu?ubuntu??317?Mar?30?17:47?samples/bpf/hello_kern.c
-rw-rw-r--?1?ubuntu?ubuntu?3.8K?Mar?30?17:48?samples/bpf/hello_kern.o
-rw-rw-r--?1?ubuntu?ubuntu??246?Mar?30?17:47?samples/bpf/hello_user.c
-rw-rw-r--?1?ubuntu?ubuntu?2.2K?Mar?30?17:48?samples/bpf/hello_user.o
進入到對應的目錄運行 hello 程序,可以看到輸出結(jié)果如下:
$?sudo?./hello
???????????<...>-102735?[001]?....??6733.481740:?0:?Hello?BPF?from?houmin!
???????????<...>-102736?[000]?....??6733.482884:?0:?Hello?BPF?from?houmin!
???????????<...>-102737?[002]?....??6733.483074:?0:?Hello?BPF?from?houmin!
代碼解讀
前面提到 load_bpf_file 函數(shù)將 LLVM 編譯出來的 eBPF 字節(jié)碼加載進內(nèi)核,這到底是如何實現(xiàn)的呢?
經(jīng)過搜查,可以看到 load_bpf_file 也是在 samples/bpf 目錄下實現(xiàn)的,具體的參見 bpf_load.c[6]。
閱讀 load_bpf_file 代碼可以看到,它主要是解析 ELF 格式的 eBPF 字節(jié)碼,然后調(diào)用 load_and_attach[7]?函數(shù)。
在 load_and_attach 函數(shù)中,我們可以看到其調(diào)用了 bpf_load_program 函數(shù),這是 libbpf 提供的函數(shù)。
調(diào)用的 bpf_load_program 中的 license、kern_version 等參數(shù)來自于解析 eBPF ELF 文件,prog_type 來自于 bpf 代碼里面 SEC 字段指定的類型。
static?int?load_and_attach(const?char?*event,?struct?bpf_insn?*prog,?int?size)
{
??bool?is_socket?=?strncmp(event,?"socket",?6)?==?0;
?bool?is_kprobe?=?strncmp(event,?"kprobe/",?7)?==?0;
?bool?is_kretprobe?=?strncmp(event,?"kretprobe/",?10)?==?0;
?bool?is_tracepoint?=?strncmp(event,?"tracepoint/",?11)?==?0;
?bool?is_raw_tracepoint?=?strncmp(event,?"raw_tracepoint/",?15)?==?0;
?bool?is_xdp?=?strncmp(event,?"xdp",?3)?==?0;
?bool?is_perf_event?=?strncmp(event,?"perf_event",?10)?==?0;
?bool?is_cgroup_skb?=?strncmp(event,?"cgroup/skb",?10)?==?0;
?bool?is_cgroup_sk?=?strncmp(event,?"cgroup/sock",?11)?==?0;
?bool?is_sockops?=?strncmp(event,?"sockops",?7)?==?0;
?bool?is_sk_skb?=?strncmp(event,?"sk_skb",?6)?==?0;
?bool?is_sk_msg?=?strncmp(event,?"sk_msg",?6)?==?0;
??
??//...
??
?fd?=?bpf_load_program(prog_type,?prog,?insns_cnt,?license,?kern_version,
?????????bpf_log_buf,?BPF_LOG_BUF_SIZE);
?if?(fd???printf("bpf_load_program()?err=%d\n%s",?errno,?bpf_log_buf);
??return?-1;
?}
??//...
}
—?3?—
eBPF 特性
Hook Overview
eBPF 程序都是事件驅(qū)動的,它們會在內(nèi)核或者應用程序經(jīng)過某個確定的 Hook 點的時候運行,這些 Hook 點都是提前定義的,包括系統(tǒng)調(diào)用、函數(shù)進入/退出、內(nèi)核 tracepoints、網(wǎng)絡事件等。
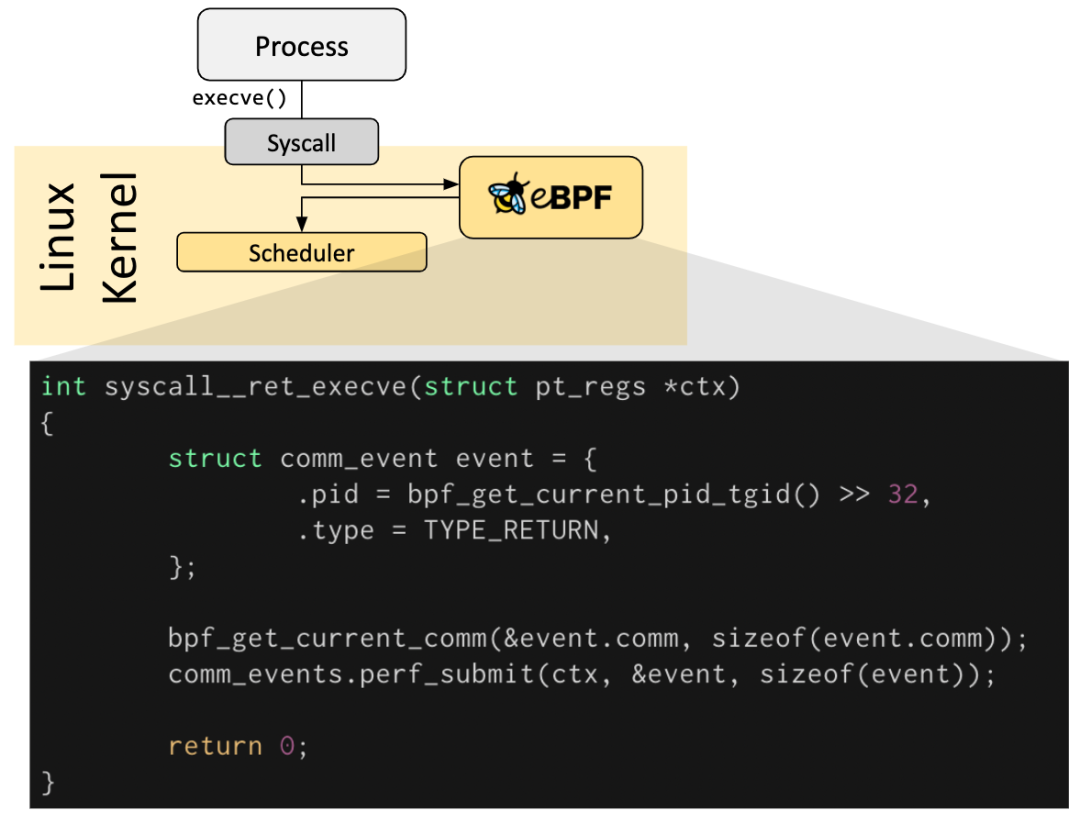
如果針對某個特定需求的 Hook 點不存在,可以通過 kprobe 或者 uprobe 來在內(nèi)核或者用戶程序的幾乎所有地方掛載 eBPF 程序。
Verification
With great power there must also come great responsibility.
每一個 eBPF 程序加載到內(nèi)核都要經(jīng)過 Verification,用來保證 eBPF 程序的安全性,主要包括:
要保證加載 eBPF 程序的進程有必要的特權(quán)級,除非節(jié)點開啟了 unpriviledged 特性,只有特權(quán)級的程序才能夠加載 eBPF 程序。
1、內(nèi)核提供了一個配置項?/proc/sys/kernel/unprivileged_bpf_disabled?來禁止非特權(quán)用戶使用?bpf(2)?系統(tǒng)調(diào)用,可以通過?sysctl?命令修改
2、比較特殊的一點是,這個配置項特意設計為一次性開關(guān)(one-time kill switch), 這意味著一旦將它設為?1,就沒有辦法再改為?0?了,除非重啟內(nèi)核
3、一旦設置為 1 之后,只有初始命名空間中有 CAP_SYS_ADMIN 特權(quán)的進程才可以調(diào)用 bpf(2)?系統(tǒng)調(diào)用 。Cilium 啟動后也會將這個配置項設為 1:
$?echo?1?>?/proc/sys/kernel/unprivileged_bpf_disabled
要保證 eBPF 程序不會崩潰或者使得系統(tǒng)出故障。
要保證 eBPF 程序不能陷入死循環(huán),能夠 runs to completion。
要保證 eBPF 程序必須滿足系統(tǒng)要求的大小,過大的 eBPF 程序不允許被加載進內(nèi)核。
要保證 eBPF 程序的復雜度有限,Verifier 將會評估 eBPF 程序所有可能的執(zhí)行路徑,必須能夠在有限時間內(nèi)完成 eBPF 程序復雜度分析。
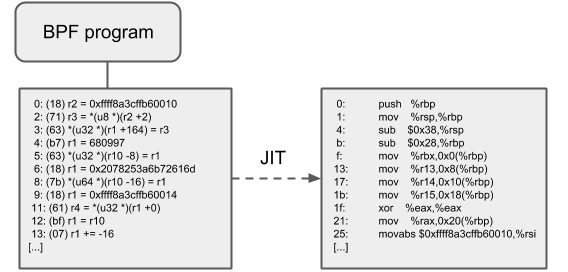
JIT Compilation
Just-In-Time(JIT)編譯用來將通用的 eBPF 字節(jié)碼翻譯成與機器相關(guān)的指令集,從而極大加速 BPF 程序的執(zhí)行:
與解釋器相比,它們可以降低每個指令的開銷。通常,指令可以 1:1 映射到底層架構(gòu)的原生指令
這也會減少生成的可執(zhí)行鏡像的大小,因此對 CPU 的指令緩存更友好
特別地,對于 CISC 指令集(例如?x86),JIT 做了很多特殊優(yōu)化,目的是為給定的指令產(chǎn)生可能的最短操作碼,以降低程序翻譯過程所需的空間
64 位的 x86_64、arm64、ppc64、s390x、mips64、sparc64 和 32 位的 arm 、x86_32 架構(gòu)都內(nèi)置了 in-kernel eBPF JIT 編譯器,它們的功能都是一樣的,可以用如下方式打開:
$?echo?1?>?/proc/sys/net/core/bpf_jit_enable
32 位的 mips、ppc 和 sparc 架構(gòu)目前內(nèi)置的是一個 cBPF JIT 編譯器。這些只有 cBPF JIT 編譯器的架構(gòu),以及那些甚至完全沒有 BPF JIT 編譯器的架構(gòu),需要通過內(nèi)核中的解釋器(in-kernel interpreter)執(zhí)行 eBPF 程序。
要判斷哪些平臺支持 eBPF JIT,可以在內(nèi)核源文件中 grep HAVE_EBPF_JIT:
$?git?grep?HAVE_EBPF_JIT?arch/
arch/arm/Kconfig:???????select?HAVE_EBPF_JIT???if?!CPU_ENDIAN_BE32
arch/arm64/Kconfig:?????select?HAVE_EBPF_JIT
arch/powerpc/Kconfig:???select?HAVE_EBPF_JIT???if?PPC64
arch/mips/Kconfig:??????select?HAVE_EBPF_JIT???if?(64BIT?&&?!CPU_MICROMIPS)
arch/s390/Kconfig:??????select?HAVE_EBPF_JIT???if?PACK_STACK?&&?HAVE_MARCH_Z196_FEATURES
arch/sparc/Kconfig:?????select?HAVE_EBPF_JIT???if?SPARC64
arch/x86/Kconfig:???????select?HAVE_EBPF_JIT???if?X86_64
Maps
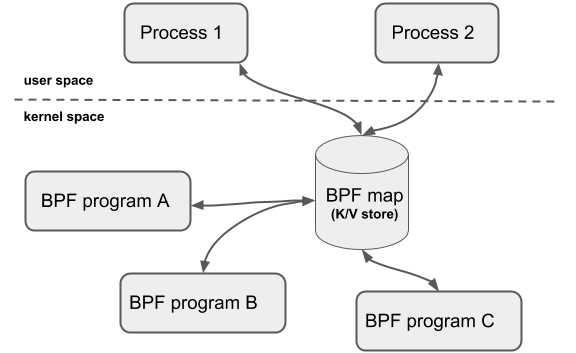
BPF Map 是駐留在內(nèi)核空間中的高效 Key/Value store,包含多種類型的 Map,由內(nèi)核實現(xiàn)其功能,具體實現(xiàn)可以參考我的這篇博文[8]。
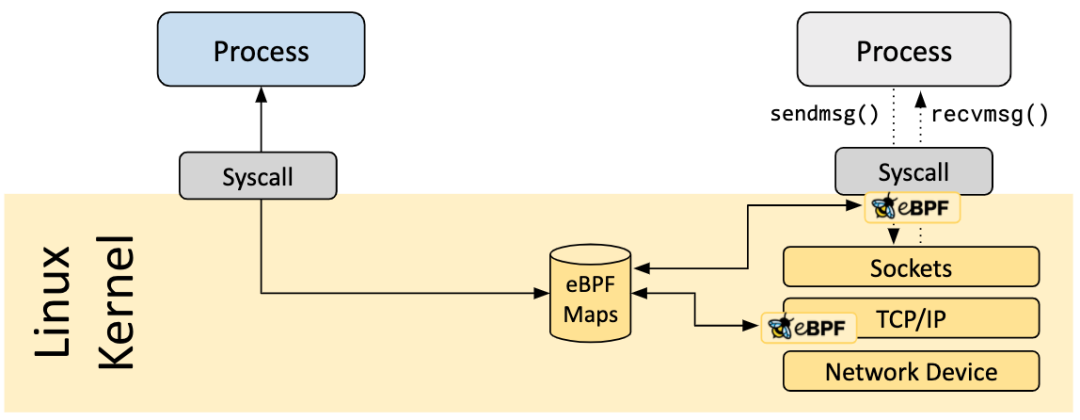
BPF Map 的交互場景有以下幾種:
BPF 程序和用戶態(tài)程序的交互:BPF 程序運行完,得到的結(jié)果存儲到 map 中,供用戶態(tài)程序通過文件描述符訪問
BPF 程序和內(nèi)核態(tài)程序的交互:和 BPF 程序以外的內(nèi)核程序交互,也可以使用 map 作為中介
BPF 程序間交互:如果 BPF 程序內(nèi)部需要用全局變量來交互,但是由于安全原因 BPF 程序不允許訪問全局變量,可以使用 map 來充當全局變量
BPF Tail call:Tail call 是一個BPF程序跳轉(zhuǎn)到另一BPF程序,BPF程序首先通過 BPF_MAP_TYPE_PROG_ARRAY 類型的 map 來知道另一個BPF程序的指針,然后調(diào)用 tail_call()?的 helper function 來執(zhí)行Tail call
共享 map 的 BPF 程序不要求是相同的程序類型,例如 tracing 程序可以和網(wǎng)絡程序共享 map,單個 BPF 程序目前最多可直接訪問 64 個不同 map。
當前可用的通用 map 有:
BPF_MAP_TYPE_HASH
BPF_MAP_TYPE_ARRAY
BPF_MAP_TYPE_PERCPU_HASH
BPF_MAP_TYPE_PERCPU_ARRAY
BPF_MAP_TYPE_LRU_HASH
BPF_MAP_TYPE_LRU_PERCPU_HASH
BPF_MAP_TYPE_LPM_TRIE
以上 map 都使用相同的一組 BPF 輔助函數(shù)來執(zhí)行查找、更新或刪除操作,但各自實現(xiàn)了不同的后端,這些后端各有不同的語義和性能特點。隨著多CPU架構(gòu)的成熟發(fā)展,BPF Map也引入了 per-cpu 類型,如BPF_MAP_TYPE_PERCPU_HASH、BPF_MAP_TYPE_PERCPU_ARRAY等。
當你使用這種類型的BPF Map時,每個 CPU 都會存儲并看到它自己的 Map 數(shù)據(jù),從屬于不同 CPU 之間的數(shù)據(jù)是互相隔離的,這樣做的好處是,在進行查找和聚合操作時更加高效,性能更好,尤其是你的 BPF 程序主要是在做收集時間序列型數(shù)據(jù),如流量數(shù)據(jù)或指標等。
當前內(nèi)核中的非通用 map 有:
BPF_MAP_TYPE_PROG_ARRAY:一個數(shù)組 map,用于 hold 其他的 BPF 程序
BPF_MAP_TYPE_PERF_EVENT_ARRAY
BPF_MAP_TYPE_CGROUP_ARRAY:用于檢查 skb 中的 cgroup2 成員信息
BPF_MAP_TYPE_STACK_TRACE:用于存儲棧跟蹤的 MAP
BPF_MAP_TYPE_ARRAY_OF_MAPS:持有(hold) 其他 map 的指針,這樣整個 map 就可以在運行時實現(xiàn)原子替換
BPF_MAP_TYPE_HASH_OF_MAPS:持有(hold) 其他 map 的指針,這樣整個 map 就可以在運行時實現(xiàn)原子替換
Helper Calls
eBPF 程序不能夠隨意調(diào)用內(nèi)核函數(shù),如果這么做的話會導致 eBPF 程序與特定的內(nèi)核版本綁定,相反它內(nèi)核定義的一系列 Helper functions。Helper functions 使得 BPF 能夠通過一組內(nèi)核定義的穩(wěn)定的函數(shù)調(diào)用來從內(nèi)核中查詢數(shù)據(jù),或者將數(shù)據(jù)推送到內(nèi)核。
所有的 BPF 輔助函數(shù)都是核心內(nèi)核的一部分,無法通過內(nèi)核模塊來擴展或添加。當前可用的 BPF 輔助函數(shù)已經(jīng)有幾十個,并且數(shù)量還在不斷增加,你可以在《Linux Manual Page: bpf-helpers[9]》看到當前 Linux 支持的 Helper functions。
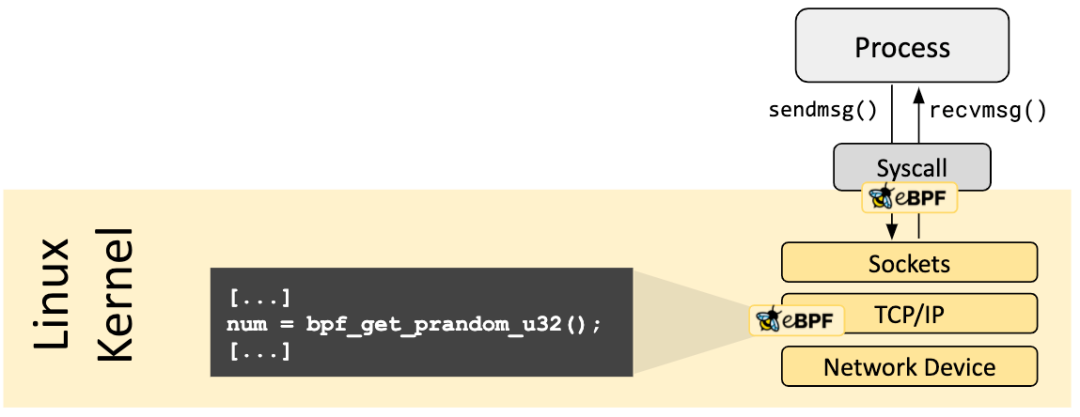
不同類型的 BPF 程序能夠使用的輔助函數(shù)可能是不同的,例如:
與 attach 到 tc 層的 BPF 程序相比,attach 到 socket 的 BPF程序只能夠調(diào)用前者可以調(diào)用的輔助函數(shù)的一個子集
lightweight tunneling 使用的封裝和解封裝輔助函數(shù),只能被更低的 tc 層使用;而推送通知到用戶態(tài)所使用的事件輸出輔助函數(shù),既可以被 tc 程序使用也可以被 XDP 程序使用
所有的輔助函數(shù)都共享同一個通用的、和系統(tǒng)調(diào)用類似的函數(shù)方法,其定義如下:
u64?fn(u64?r1,?u64?r2,?u64?r3,?u64?r4,?u64?r5)
內(nèi)核將輔助函數(shù)抽象成 BPF_CALL_0()?到 BPF_CALL_5()?幾個宏,形式和相應類型的系統(tǒng)調(diào)用類似,這里宏的定義可以參見 include/linux/filter.h 。以 bpf_map_update_elem 為例,可以看到它通過調(diào)用相應 map 的回調(diào)函數(shù)完成更新 map 元素的操作:
/kernel/bpf/helpers.c
BPF_CALL_4(bpf_map_update_elem,?struct?bpf_map?*,?map,?void?*,?key,
???????????void?*,?value,?u64,?flags)
{
????WARN_ON_ONCE(!rcu_read_lock_held());
????return?map->ops->map_update_elem(map,?key,?value,?flags);
}
const?struct?bpf_func_proto?bpf_map_update_elem_proto?=?{
????.func???????????=?bpf_map_update_elem,
????.gpl_only???????=?false,
????.ret_type???????=?RET_INTEGER,
????.arg1_type??????=?ARG_CONST_MAP_PTR,
????.arg2_type??????=?ARG_PTR_TO_MAP_KEY,
????.arg3_type??????=?ARG_PTR_TO_MAP_VALUE,
????.arg4_type??????=?ARG_ANYTHING,
};
這種方式有很多優(yōu)點:
雖然 cBPF 允許其加載指令(load instructions)進行超出范圍的訪問(overload),以便從一個看似不可能的包偏移量(packet offset)獲取數(shù)據(jù)以喚醒多功能輔助函數(shù),但每個 cBPF JIT 仍然需要為這個 cBPF 擴展實現(xiàn)對應的支持。
而在 eBPF 中,JIT 編譯器會以一種透明和高效的方式編譯新加入的輔助函數(shù),這意味著 JIT 編 譯器只需要發(fā)射(emit)一條調(diào)用指令(call instruction),因為寄存器映射的方式使得 BPF 排列參數(shù)的方式(assignments)已經(jīng)和底層架構(gòu)的調(diào)用約定相匹配了。
這使得基于輔助函數(shù)擴展核心內(nèi)核(core kernel)非常方便。所有的 BPF 輔助函數(shù)都是核心內(nèi)核的一部分,無法通過內(nèi)核模塊(kernel module)來擴展或添加。
前面提到的函數(shù)簽名還允許校驗器執(zhí)行類型檢測(type check)。上面的 struct bpf_func_proto 用于存放校驗器必需知道的所有關(guān)于該輔助函數(shù)的信息,這樣校驗器可以確保輔助函數(shù)期望的類型和 BPF 程序寄存器中的當前內(nèi)容是匹配的。
參數(shù)類型范圍很廣,從任意類型的值,到限制只能為特定類型,例如 BPF 棧緩沖區(qū)(stack buffer)的 pointer/size 參數(shù)對,輔助函數(shù)可以從這個位置讀取數(shù)據(jù)或向其寫入數(shù)據(jù)。對于這種情況,校驗器還可以執(zhí)行額外的檢查,例如,緩沖區(qū)是否已經(jīng)初始化過了。
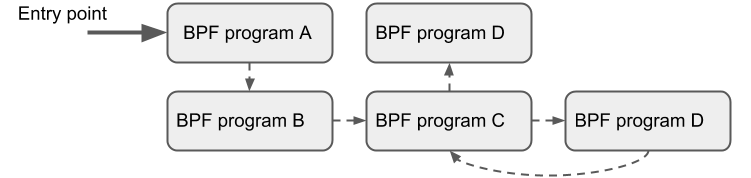
Tail Calls
尾調(diào)用的機制是指:一個 BPF 程序可以調(diào)用另一個 BPF 程序,并且調(diào)用完成后不用返回到原來的程序。
和普通函數(shù)調(diào)用相比,這種調(diào)用方式開銷最小,因為它是用長跳轉(zhuǎn)(long jump)實現(xiàn)的,復用了原來的棧幀?(stack frame)
BPF 程序都是獨立驗證的,因此要傳遞狀態(tài),要么使用 per-CPU map 作為 scratch 緩沖區(qū) ,要么如果是 tc 程序的話,還可以使用?skb?的某些字段(例如?cb[])
相同類型的程序才可以尾調(diào)用,而且它們還要與 JIT 編譯器相匹配,因此要么是 JIT 編譯執(zhí)行,要么是解釋器執(zhí)行(invoke interpreted programs),但不能同時使用兩種方式
BPF to BPF Calls
除了 BPF 輔助函數(shù)和 BPF 尾調(diào)用之外,BPF 核心基礎設施最近剛加入了一個新特性:BPF to BPF calls。在這個特性引入內(nèi)核之前,典型的 BPF C 程序必須將所有需要復用的代碼進行特殊處理,例如,在頭文件中聲明為 always_inline。當 LLVM 編譯和生成 BPF 對象文件時,所有這些函數(shù)將被內(nèi)聯(lián),因此會在生成的對象文件中重 復多次,導致代碼尺寸膨脹:
#include?
#ifndef?__section
#?define?__section(NAME)??????????????????\
???__attribute__((section(NAME),?used))
#endif
#ifndef?__inline
#?define?__inline?????????????????????????\
???inline?__attribute__((always_inline))
#endif
static?__inline?int?foo(void)
{
????return?XDP_DROP;
}
__section("prog")
int?xdp_drop(struct?xdp_md?*ctx)
{
????return?foo();
}
char?__license[]?__section("license")?=?"GPL";
之所以要這樣做是因為 BPF 程序的加載器、校驗器、解釋器和 JIT 中都缺少對函數(shù)調(diào)用的支持。從 Linux 4.16 和 LLVM 6.0?開始,這個限制得到了解決,BPF 程序不再需要到處使用 always_inline 聲明了。因此,上面的代碼可以更自然地重寫為:
#include?
#ifndef?__section
#?define?__section(NAME)??????????????????\
???__attribute__((section(NAME),?used))
#endif
static?int?foo(void)
{
????return?XDP_DROP;
}
__section("prog")
int?xdp_drop(struct?xdp_md?*ctx)
{
????return?foo();
}
char?__license[]?__section("license")?=?"GPL";
BPF 到 BPF 調(diào)用是一個重要的性能優(yōu)化,極大減小了生成的 BPF 代碼大小,因此?對 CPU 指令緩存(instruction cache,i-cache)更友好。
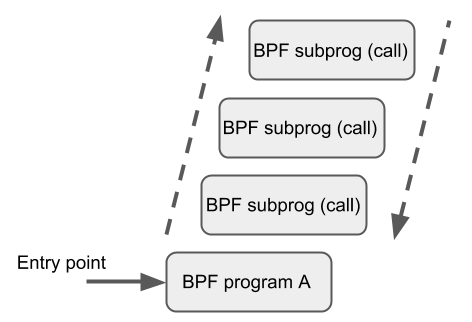
BPF 輔助函數(shù)的調(diào)用約定也適用于 BPF 函數(shù)間調(diào)用:
r1?-?r5?用于傳遞參數(shù),返回結(jié)果放到?r0
r1?-?r5?是 scratch registers,r6?-?r9?像往常一樣是保留寄存器
最大嵌套調(diào)用深度是?8
調(diào)用方可以傳遞指針(例如,指向調(diào)用方的棧幀的指針) 給被調(diào)用方,但反過來不行
當前,BPF 函數(shù)間調(diào)用和 BPF 尾調(diào)用是不兼容的,因為后者需要復用當前的棧設置( stack setup),而前者會增加一個額外的棧幀,因此不符合尾調(diào)用期望的布局。
BPF JIT 編譯器為每個函數(shù)體發(fā)射獨立的鏡像(emit separate images for each function body),稍后在最后一通 JIT 處理(final JIT pass)中再修改鏡像中函數(shù)調(diào)用的地址 。已經(jīng)證明,這種方式需要對各種 JIT 做最少的修改,因為在實現(xiàn)中它們可以將 BPF 函數(shù)間調(diào)用當做常規(guī)的 BPF 輔助函數(shù)調(diào)用。
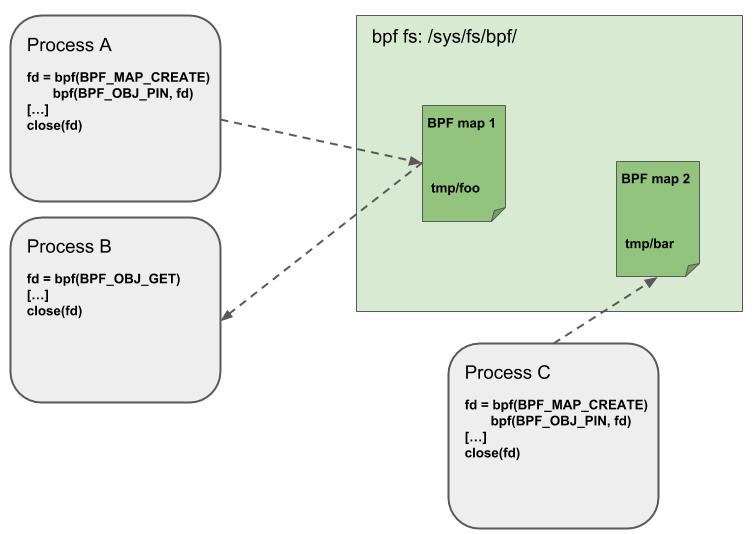
Object Pinning
BPF map 和程序作為內(nèi)核資源只能通過文件描述符訪問,其背后是內(nèi)核中的匿名 inode。這帶來了很多優(yōu)點:
用戶空間應用程序能夠使用大部分文件描述符相關(guān)的 API
傳遞給 Unix socket 的文件描述符是透明工作等等
但同時,文件描述符受限于進程的生命周期,使得 map 共享之類的操作非常笨重,這給某些特定的場景帶來了很多復雜性。
例如 iproute2,其中的 tc 或 XDP 在準備環(huán)境、加載程序到內(nèi)核之后最終會退出。在這種情況下,從用戶空間也無法訪問這些 map 了,而本來這些 map 其實是很有用的。例如,在 data path 的 ingress 和 egress 位置共享的 map(可以統(tǒng)計包數(shù)、字節(jié)數(shù)、PPS 等信息)。另外,第三方應用可能希望在 BPF 程序運行時監(jiān)控或更新 map。
為了解決這個問題,內(nèi)核實現(xiàn)了一個最小內(nèi)核空間 BPF 文件系統(tǒng),BPF map 和 BPF 程序都可以 pin 到這個文件系統(tǒng)內(nèi),這個過程稱為 object pinning。BPF 相關(guān)的文件系統(tǒng)不是單例模式(singleton),它支持多掛載實例、硬鏈接、軟連接等等。
相應的,BPF 系統(tǒng)調(diào)用擴展了兩個新命令,如下圖所示:
BPF_OBJ_PIN:釘住一個對象
BPF_OBJ_GET:獲取一個被釘住的對象
Hardening
1、Protection Execution Protection
為了避免代碼被損壞,BPF 會在程序的生命周期內(nèi),在內(nèi)核中將 BPF 解釋器解釋后的整個鏡像(struct bpf_prog)和 JIT 編譯之后的鏡像(struct bpf_binary_header)鎖定為只讀的。在這些位置發(fā)生的任何數(shù)據(jù)損壞(例如由于某些內(nèi)核 bug 導致的)會觸發(fā)通用的保護機制,因此會造成內(nèi)核崩潰而不是允許損壞靜默地發(fā)生。
查看哪些平臺支持將鏡像內(nèi)存(image memory)設置為只讀的,可以通過下面的搜索:
$?git?grep?ARCH_HAS_SET_MEMORY?|?grep?select
arch/arm/Kconfig:????select?ARCH_HAS_SET_MEMORY
arch/arm64/Kconfig:??select?ARCH_HAS_SET_MEMORY
arch/s390/Kconfig:???select?ARCH_HAS_SET_MEMORY
arch/x86/Kconfig:????select?ARCH_HAS_SET_MEMORY
CONFIG_ARCH_HAS_SET_MEMORY 選項是不可配置的,因此平臺要么內(nèi)置支持,要么不支持,那些目前還不支持的架構(gòu)未來可能也會支持。
2、Mitigation Against Spectre
為了防御 Spectre v2 攻擊,Linux 內(nèi)核提供了 CONFIG_BPF_JIT_ALWAYS_ON 選項,打開這個開關(guān)后 BPF 解釋器將會從內(nèi)核中完全移除,永遠啟用 JIT 編譯器:
如果應用在一個基于虛擬機的環(huán)境,客戶機內(nèi)核將不會復用內(nèi)核的 BPF 解釋器,因此可以避免某些相關(guān)的攻擊
如果是基于容器的環(huán)境,這個配置是可選的,如果 JIT 功能打開了,解釋器仍然可能會在編譯時被去掉,以降低內(nèi)核的復雜度
對于主流架構(gòu)(例如?x86_64?和?arm64)上的 JIT 通常都建議打開這個開關(guān)
將?/proc/sys/net/core/bpf_jit_harden 設置為 1 會為非特權(quán)用戶的 JIT 編譯做一些額外的加固工作。這些額外加固會稍微降低程序的性能,但在有非受信用戶在系統(tǒng)上進行操作的情況下,能夠有效地減小潛在的受攻擊面。
但與完全切換到解釋器相比,這些性能損失還是比較小的。對于 x86_64 JIT 編譯器,如果設置了 CONFIG_RETPOLINE,尾調(diào)用的間接跳轉(zhuǎn)( indirect jump)就會用 retpoline 實現(xiàn)。寫作本文時,在大部分現(xiàn)代 Linux 發(fā)行版上這個配置都是打開的。
3、Constant Blinding
當前,啟用加固會在 JIT 編譯時盲化(blind)BPF 程序中用戶提供的所有 32 位和 64 位常量,以防御 JIT spraying攻擊,這些攻擊會將原生操作碼作為立即數(shù)注入到內(nèi)核。
這種攻擊有效是因為:立即數(shù)駐留在可執(zhí)行內(nèi)核內(nèi)存(executable kernel memory)中,因此某些內(nèi)核 bug 可能會觸發(fā)一個跳轉(zhuǎn)動作,如果跳轉(zhuǎn)到立即數(shù)的開始位置,就會把它們當做原生指令開始執(zhí)行。
盲化 JIT 常量通過對真實指令進行隨機化(randomizing the actual instruction)實現(xiàn) 。在這種方式中,通過對指令進行重寫,將原來基于立即數(shù)的操作轉(zhuǎn)換成基于寄存器的操作。指令重寫將加載值的過程分解為兩部分:
加載一個盲化后的(blinded)立即數(shù)?rnd ^ imm?到寄存器
將寄存器和?rnd?進行異或操作(xor)
這樣原始的 imm 立即數(shù)就駐留在寄存器中,可以用于真實的操作了。這里介紹的只是加載操作的盲化過程,實際上所有的通用操作都被盲化了。下面是加固關(guān)閉的情況下,某個程序的 JIT 編譯結(jié)果:
$?echo?0?>?/proc/sys/net/core/bpf_jit_harden
??ffffffffa034f5e9?+?
??[...]
??39:???mov????$0xa8909090,%eax
??3e:???mov????$0xa8909090,%eax
??43:???mov????$0xa8ff3148,%eax
??48:???mov????$0xa89081b4,%eax
??4d:???mov????$0xa8900bb0,%eax
??52:???mov????$0xa810e0c1,%eax
??57:???mov????$0xa8908eb4,%eax
??5c:???mov????$0xa89020b0,%eax
??[...]
加固打開之后,以上程序被某個非特權(quán)用戶通過 BPF 加載的結(jié)果(這里已經(jīng)進行了常量盲化):
$?echo?1?>?/proc/sys/net/core/bpf_jit_harden
??ffffffffa034f1e5?+?
??[...]
??39:???mov????$0xe1192563,%r10d
??3f:???xor????$0x4989b5f3,%r10d
??46:???mov????%r10d,%eax
??49:???mov????$0xb8296d93,%r10d
??4f:???xor????$0x10b9fd03,%r10d
??56:???mov????%r10d,%eax
??59:???mov????$0x8c381146,%r10d
??5f:???xor????$0x24c7200e,%r10d
??66:???mov????%r10d,%eax
??69:???mov????$0xeb2a830e,%r10d
??6f:???xor????$0x43ba02ba,%r10d
??76:???mov????%r10d,%eax
??79:???mov????$0xd9730af,%r10d
??7f:???xor????$0xa5073b1f,%r10d
??86:???mov????%r10d,%eax
??89:???mov????$0x9a45662b,%r10d
??8f:???xor????$0x325586ea,%r10d
??96:???mov????%r10d,%eax
??[...]
兩個程序在語義上是一樣的,但在第二種方式中,原來的立即數(shù)在反匯編之后的程序中不再可見。同時,加固還會禁止任何 JIT 內(nèi)核符合(kallsyms)暴露給特權(quán)用戶,JIT 鏡像地址不再出現(xiàn)在?/proc/kallsyms 中。
Offloads
BPF 網(wǎng)絡程序,尤其是 tc 和 XDP BPF 程序在內(nèi)核中都有一個 offload 到硬件的接口,這樣就可以直接在網(wǎng)卡上執(zhí)行 BPF 程序。
當前,Netronome 公司的 nfp 驅(qū)動支持通過 JIT 編譯器 offload BPF,它會將 BPF 指令翻譯成網(wǎng)卡實現(xiàn)的指令集。另外,它還支持將 BPF maps offload 到網(wǎng)卡,因此 offloaded BPF 程序可以執(zhí)行 map 查找、更新和刪除操作。
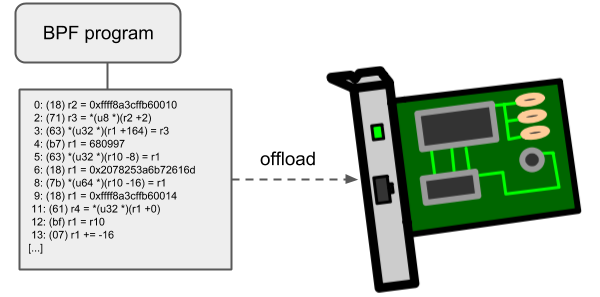
—?4?—
eBPF 接口
BPF 系統(tǒng)調(diào)用
eBPF 提供了 bpf()?系統(tǒng)調(diào)用來對 BPF Map 或 程序進行操作,其函數(shù)原型如下:
#include?
int?bpf(int?cmd,?union?bpf_attr?*attr,?unsigned?int?size);
函數(shù)有三個參數(shù),其中:
cmd?指定了 bpf 系統(tǒng)調(diào)用執(zhí)行的命令類型,每個 cmd 都會附帶一個參數(shù)?attr
bpf_attr union?允許在內(nèi)核和用戶空間之間傳遞數(shù)據(jù),確切的格式取決于?cmd?這個參數(shù)
size?這個參數(shù)表示bpf_attr union?這個對象以字節(jié)為單位的大小
cmd 可以為一下幾種類型,基本上可以分為操作 eBPF Map 和操作 eBPF 程序兩種類型:
BPF_MAP_CREATE:創(chuàng)建一個 eBPF Map 并且返回指向該 Map 的文件描述符
BPF_MAP_LOOKUP_ELEM:在某個 Map 中根據(jù) key 查找元素并返回其 value
BPF_MAP_UPDATE_ELEM:在某個 Map 中創(chuàng)建或者更新一個元素 key/value 對
BPF_MAP_DELETE_ELEM:在某個 Map 中根據(jù) key 刪除一個元素
BPF_MAP_GET_NEXT_KEY:在某個 Map 中根據(jù) key 查找元素然后返回下一個元素的 key
BPF_PROG_LOAD:校驗并加載 eBPF 程序,返回與該程序關(guān)聯(lián)的文件描述符
……
bpf_attr union 的結(jié)構(gòu)如下所示,根據(jù)不同的 cmd 可以填充不同的信息。
union?bpf_attr?{
??struct?{????/*?Used?by?BPF_MAP_CREATE?*/
????__u32?????????map_type;
????__u32?????????key_size;????/*?size?of?key?in?bytes?*/
????__u32?????????value_size;??/*?size?of?value?in?bytes?*/
????__u32?????????max_entries;?/*?maximum?number?of?entries?in?a?map?*/
??};
??struct?{????/*?Used?by?BPF_MAP_*_ELEM?and?BPF_MAP_GET_NEXT_KEY?commands?*/
????__u32?????????map_fd;
????__aligned_u64?key;
????union?{
??????__aligned_u64?value;
??????__aligned_u64?next_key;
????};
????__u64?????????flags;
??};
??struct?{????/*?Used?by?BPF_PROG_LOAD?*/
????__u32?????????prog_type;
????__u32?????????insn_cnt;
????__aligned_u64?insns;??????/*?'const?struct?bpf_insn?*'?*/
????__aligned_u64?license;????/*?'const?char?*'?*/
????__u32?????????log_level;??/*?verbosity?level?of?verifier?*/
????__u32?????????log_size;???/*?size?of?user?buffer?*/
????__aligned_u64?log_buf;????/*?user?supplied?'char?*'?buffer?*/
????__u32?????????kern_version;?/*?checked?when?prog_type=kprobe?(since?Linux?4.1)?*/
??};
}?__attribute__((aligned(8)));
使用 eBPF 程序的命令:
BPF_PROG_LOAD 命令用于校驗和加載 eBPF 程序,其需要填充的參數(shù) bpf_xattr,下面展示了在 libbpf 中 bpf_load_program 的實現(xiàn),可以看到最終是調(diào)用了 bpf 系統(tǒng)調(diào)用。
/tools/lib/bpf/bpf.c
int?bpf_load_program(enum?bpf_prog_type?type,?const?struct?bpf_insn?*insns,
???????size_t?insns_cnt,?const?char?*license,
???????__u32?kern_version,?char?*log_buf,
???????size_t?log_buf_sz)
{
?struct?bpf_load_program_attr?load_attr;
?memset(&load_attr,?0,?sizeof(struct?bpf_load_program_attr));
?load_attr.prog_type?=?type;
?load_attr.expected_attach_type?=?0;
?load_attr.name?=?NULL;
?load_attr.insns?=?insns;
?load_attr.insns_cnt?=?insns_cnt;
?load_attr.license?=?license;
?load_attr.kern_version?=?kern_version;
?return?bpf_load_program_xattr(&load_attr,?log_buf,?log_buf_sz);
}
int?bpf_load_program_xattr(const?struct?bpf_load_program_attr?*load_attr,
??????char?*log_buf,?size_t?log_buf_sz)
{
??//?...
??fd?=?sys_bpf_prog_load(&attr,?sizeof(attr));
?if?(fd?>=?0)
??return?fd;
??//?...
}
static?inline?int?sys_bpf_prog_load(union?bpf_attr?*attr,?unsigned?int?size)
{
?int?fd;
?do?{
??fd?=?sys_bpf(BPF_PROG_LOAD,?attr,?size);
?}?while?(fd?
?return?fd;
}
和前面一樣,查看 libbpf 中 bpf_create_map 的實現(xiàn),可以看到最終也調(diào)用了 bpf 系統(tǒng)調(diào)用:
/tools/lib/bpf/bpf.c
int?bpf_create_map(enum?bpf_map_type?map_type,?int?key_size,
?????int?value_size,?int?max_entries,?__u32?map_flags)
{
?struct?bpf_create_map_attr?map_attr?=?{};
?map_attr.map_type?=?map_type;
?map_attr.map_flags?=?map_flags;
?map_attr.key_size?=?key_size;
?map_attr.value_size?=?value_size;
?map_attr.max_entries?=?max_entries;
?return?bpf_create_map_xattr(&map_attr);
}
int?bpf_create_map_xattr(const?struct?bpf_create_map_attr?*create_attr)
{
?union?bpf_attr?attr;
?memset(&attr,?'\0',?sizeof(attr));
?attr.map_type?=?create_attr->map_type;
?attr.key_size?=?create_attr->key_size;
?attr.value_size?=?create_attr->value_size;
?attr.max_entries?=?create_attr->max_entries;
?attr.map_flags?=?create_attr->map_flags;
?if?(create_attr->name)
??memcpy(attr.map_name,?create_attr->name,
?????????min(strlen(create_attr->name),?BPF_OBJ_NAME_LEN?-?1));
?attr.numa_node?=?create_attr->numa_node;
?attr.btf_fd?=?create_attr->btf_fd;
?attr.btf_key_type_id?=?create_attr->btf_key_type_id;
?attr.btf_value_type_id?=?create_attr->btf_value_type_id;
?attr.map_ifindex?=?create_attr->map_ifindex;
?attr.inner_map_fd?=?create_attr->inner_map_fd;
?return?sys_bpf(BPF_MAP_CREATE,?&attr,?sizeof(attr));
}
libbpf 中 bpf_map_lookup_elem 的實現(xiàn):
/tools/lib/bpf/bpf.c
int?bpf_map_lookup_elem(int?fd,?const?void?*key,?void?*value)
{
?union?bpf_attr?attr;
?memset(&attr,?0,?sizeof(attr));
?attr.map_fd?=?fd;
?attr.key?=?ptr_to_u64(key);
?attr.value?=?ptr_to_u64(value);
?return?sys_bpf(BPF_MAP_LOOKUP_ELEM,?&attr,?sizeof(attr));
}
libbpf 中 bpf_map_update_elem 的實現(xiàn):
/tools/lib/bpf/bpf.c
int?bpf_map_update_elem(int?fd,?const?void?*key,?const?void?*value,
???__u64?flags)
{
?union?bpf_attr?attr;
?memset(&attr,?0,?sizeof(attr));
?attr.map_fd?=?fd;
?attr.key?=?ptr_to_u64(key);
?attr.value?=?ptr_to_u64(value);
?attr.flags?=?flags;
?return?sys_bpf(BPF_MAP_UPDATE_ELEM,?&attr,?sizeof(attr));
}
libbpf 中 bpf_map_delete_elem 的實現(xiàn):
/tools/lib/bpf/bpf.c
int?bpf_map_delete_elem(int?fd,?const?void?*key)
{
?union?bpf_attr?attr;
?memset(&attr,?0,?sizeof(attr));
?attr.map_fd?=?fd;
?attr.key?=?ptr_to_u64(key);
?return?sys_bpf(BPF_MAP_DELETE_ELEM,?&attr,?sizeof(attr));
}
libbpf 中 bpf_map_get_next_key 的實現(xiàn):
/tools/lib/bpf/bpf.c
int?bpf_map_get_next_key(int?fd,?const?void?*key,?void?*next_key)
{
?union?bpf_attr?attr;
?memset(&attr,?0,?sizeof(attr));
?attr.map_fd?=?fd;
?attr.key?=?ptr_to_u64(key);
?attr.next_key?=?ptr_to_u64(next_key);
?return?sys_bpf(BPF_MAP_GET_NEXT_KEY,?&attr,?sizeof(attr));
}
注意,這里的 libbpf 函數(shù)和之前提到的 helper functions 還不太一樣,你可以在 Linux Manual Page: bpf-helpers[9]?看到當前 Linux 支持的 Helper functions。以 bpf_map_update_elem 為例,eBPF 程序通過調(diào)用 helper function,其參數(shù)如下:
struct?msg?{
?__s32?seq;
?__u64?cts;
?__u8?comm[MAX_LENGTH];
};
struct?bpf_map_def?SEC("maps")?map?=?{
?.type?=?BPF_MAP_TYPE_PERF_EVENT_ARRAY,
?.key_size?=?sizeof(int),
?.value_size?=?sizeof(__u32),
?.max_entries?=?0,
};
void?*bpf_map_lookup_elem(struct?bpf_map?*map,?const?void?*key)
這里的第一個參數(shù)來自于 SEC(".maps")?語法糖創(chuàng)建的 bpf_map。
對于用戶態(tài)程序,則其函數(shù)原型如下,其中通過 fd 來訪問 eBPF map。
int?bpf_map_lookup_elem(int?fd,?const?void?*key,?void?*value)
BPF 程序類型
函數(shù)BPF_PROG_LOAD加載的程序類型規(guī)定了四件事:
程序可以附加在哪里
驗證器允許調(diào)用內(nèi)核中的哪些幫助函數(shù)
網(wǎng)絡包的數(shù)據(jù)是否可以直接訪問
作為第一個參數(shù)傳遞給程序的對象類型
實際上,程序類型本質(zhì)上定義了一個 API。甚至還創(chuàng)建了新的程序類型,以區(qū)分允許調(diào)用的不同的函數(shù)列表(比如 BPF_PROG_TYPE_CGROUP_SKB 對比 BPF_PROG_TYPE_SOCKET_FILTER)。
bpf 程序會被 hook 到內(nèi)核不同的 hook 點上。不同的 hook 點的入口參數(shù),能力有所不同。因而定義了不同的 prog type。不同的 prog type 的 bpf 程序能夠調(diào)用的 kernel function 集合也不一樣。當 bpf 程序加載到內(nèi)核時,內(nèi)核的 verifier 程序會根據(jù) bpf prog type,檢查程序的入口參數(shù),調(diào)用了哪些 helper function。
目前內(nèi)核支持的eBPF程序類型列表如下所示:
BPF_PROG_TYPE_SOCKET_FILTER:一種網(wǎng)絡數(shù)據(jù)包過濾器
BPF_PROG_TYPE_KPROBE:確定kprobe是否應該觸發(fā)
BPF_PROG_TYPE_SCHED_CLS:一種網(wǎng)絡流量控制分類器
BPF_PROG_TYPE_SCHED_ACT:一種網(wǎng)絡流量控制動作
BPF_PROG_TYPE_TRACEPOINT:確定 tracepoint是否應該觸發(fā)
BPF_PROG_TYPE_XDP:從設備驅(qū)動程序接收路徑運行的網(wǎng)絡數(shù)據(jù)包過濾器
BPF_PROG_TYPE_PERF_EVENT:確定是否應該觸發(fā)perf事件處理程序
BPF_PROG_TYPE_CGROUP_SKB:一種用于控制組的網(wǎng)絡數(shù)據(jù)包過濾器
BPF_PROG_TYPE_CGROUP_SOCK:一種由于控制組的網(wǎng)絡包篩選器,它被允許修改套接字選項
BPF_PROG_TYPE_LWT_*:用于輕量級隧道的網(wǎng)絡數(shù)據(jù)包過濾器
BPF_PROG_TYPE_SOCK_OPS:一個用于設置套接字參數(shù)的程序
BPF_PROG_TYPE_SK_SKB:一個用于套接字之間轉(zhuǎn)發(fā)數(shù)據(jù)包的網(wǎng)絡包過濾器
BPF_PROG_CGROUP_DEVICE:確定是否允許設備操作
隨著新程序類型的添加,內(nèi)核開發(fā)人員同時發(fā)現(xiàn)也需要添加新的數(shù)據(jù)結(jié)構(gòu)。
舉個例子 BPF_PROG_TYPE_SCHED_CLS bpf prog , 能夠訪問哪些 bpf helper function 呢?讓我們來看看源代碼是如何實現(xiàn)的。
每一種 prog type 會定義一個 struct bpf_verifier_ops 結(jié)構(gòu)體。當 prog load 到內(nèi)核時,內(nèi)核會根據(jù)它的 type,調(diào)用相應結(jié)構(gòu)體的 get_func_proto 函數(shù)。
const?struct?bpf_verifier_ops?tc_cls_act_verifier_ops?=?{
????????.get_func_proto?????????=?tc_cls_act_func_proto,
????.convert_ctx_access?????=?tc_cls_act_convert_ctx_access,
};
對于 BPF_PROG_TYPE_SCHED_CLS 類型的 BPF 代碼,verifier 會調(diào)用 tc_cls_act_func_proto,以檢查程序調(diào)用的 helper function 是否都是合法的。
BPF 代碼調(diào)用時機
每一種 prog type 的調(diào)用時機都不同。
BPF_PROG_TYPE_SCHED_CLS 的調(diào)用過程如下。
1、Egress 方向
Egress 方向上,TCP/IP 協(xié)議棧運行之后,有一個 hook 點。這個 hook 點可以 attach BPF_PROG_TYPE_SCHED_CLS type 的 egress 方向的 bpf prog。在這段 bpf 代碼執(zhí)行之后,才會運行 qos,tcpdump,xmit 到網(wǎng)卡 driver 的代碼。在這段 bpf 代碼中你可以修改報文里面的內(nèi)容,地址等。修改之后,通過 tcpdump 可以看到,因為 tcpdump 代碼在此之后才執(zhí)行。
static?int?__dev_queue_xmit(struct?sk_buff?*skb,?struct?net_device?*sb_dev)
{
???skb?=?sch_handle_egress(skb,?&rc,?dev);
???//?enqueue?tc?qos
???//?dequeue?tc?qos
???//?dev_hard_start_xmit
???//?tcpdump?works?here!?dev_queue_xmit_nit
???//?nic?driver->ndo_start_xmit?
}
Ingress 方向上,在 deliver to tcp/ip 協(xié)議棧之前,在 tcpdump 之后,有一個hook點。這個hook點可以attach BPF_PROG_TYPE_SCHED_CLS type 的 ingress 方向的 bpf prog。在這里你也可以修改報文。但是修改之后的結(jié)果在 tcpdump 中是看不到的。
static?int?__netif_receive_skb_core(struct?sk_buff?**pskb,?bool?pfmemalloc,
????????????????????????????????????struct?packet_type?**ppt_prev)
{
??//?generic?xdp?bpf?hook
??//?tcpdump?
??//?tc?ingress?hook
??skb?=?sch_handle_ingress(skb,?&pt_prev,?&ret,?orig_dev,?&another);
??//?deliver?to?tcp/ip?stack?or?bridge/ipvlan?device
}
無論 egress 還是 ingress 方向,真正執(zhí)行 bpf 指令的入口都是 cls_bpf_classify。它遍歷 tcf_proto 中的 bpf prog link list, 對每一個 bpf prog 執(zhí)行 BPF_PROG_RUN(prog->filter, skb)
static?int?cls_bpf_classify(struct?sk_buff?*skb,?const?struct?tcf_proto?*tp,
????????????????????????????struct?tcf_result?*res)
{
??struct?cls_bpf_head?*head?=?rcu_dereference_bh(tp->root);
??struct?cls_bpf_prog?*prog;
??
??list_for_each_entry_rcu(prog,?&head->plist,?link)?{
????????????????int?filter_res;
????????if?(tc_skip_sw(prog->gen_flags))?{
????????????????????????filter_res?=?prog->exts_integrated???TC_ACT_UNSPEC?:?0;
????????????????}?else?if?(at_ingress)?{
????????????????????????/*?It?is?safe?to?push/pull?even?if?skb_shared()?*/
????????????????????????__skb_push(skb,?skb->mac_len);
????????????????????????bpf_compute_data_pointers(skb);
????????????????????????filter_res?=?BPF_PROG_RUN(prog->filter,?skb);
????????????????????????__skb_pull(skb,?skb->mac_len);
????????????????}?else?{
????????????????????????bpf_compute_data_pointers(skb);
????????????????????????filter_res?=?BPF_PROG_RUN(prog->filter,?skb);
????????????????}
}
BPF_PROG_RUN 會執(zhí)行 JIT compile 的 bpf 指令,如果內(nèi)核不支持 JIT,則會調(diào)用解釋器執(zhí)行 bpf 的 byte code。
BPF_PROG_RUN 傳給 bpf prog 的入口參數(shù)是 skb,其類型是 struct sk_buff,定義在文件 include/linux/skbuff.h 中。
但是在 bpf 代碼中,為了安全,不能直接訪問?sk_buff。bpf 中是通過訪問 struct __sk_buff 來訪問 struct sk_buff 的。__sk_buff 是 sk_buff 的一個子集,是 sk_buff 面向 bpf 程序的接口。bpf 代碼中對?__sk_buff 的訪問會在 verifier 程序中翻譯成對 sk_buff 相應 fileds 的訪問。
在加載 bpf prog 的時候,verifier 會調(diào)用上面 tc_cls_act_verifier_ops 結(jié)構(gòu)體里面的 tc_cls_act_convert_ctx_access 的鉤子。它最終會調(diào)用下面的函數(shù)修改 ebpf 的指令,使得對?__sk_buff 的訪問變成對 struct sk_buff 的訪問。
BPF Attach type
一種 type 的bpf prog 可以掛到內(nèi)核中不同的hook點,這些不同的hook點就是不同的attach type。
其對應關(guān)系在下面函數(shù)中定義了。
attach_type_to_prog_type(enum?bpf_attach_type?attach_type)
{
????????switch?(attach_type)?{
????????case?BPF_CGROUP_INET_INGRESS:
????????case?BPF_CGROUP_INET_EGRESS:
????????????????return?BPF_PROG_TYPE_CGROUP_SKB;
????????case?BPF_CGROUP_INET_SOCK_CREATE:
????????case?BPF_CGROUP_INET_SOCK_RELEASE:
????????case?BPF_CGROUP_INET4_POST_BIND:
????????case?BPF_CGROUP_INET6_POST_BIND:
????????????????return?BPF_PROG_TYPE_CGROUP_SOCK;
?????.....
}
當 bpf prog 通過系統(tǒng)調(diào)用 bpf() attach 到具體的 hook 點時,其入口參數(shù)中就需要指定 attach type。
有趣的是,BPF_PROG_TYPE_SCHED_CLS 類型的 bpf prog 不能通過 bpf 系統(tǒng)調(diào)用來 attach,因為它沒有定義對應的 attach type。故它的 attach 需要通過 netlink interface 額外的實現(xiàn),還是非常復雜的。
常用 prog type 介紹
內(nèi)核中的 prog type 目前有 30 種。每一種 type 能做的事情有所差異,這里只講講我平時工作用過的幾種。
理解一種 prog type 的最好的方法是:
查表 attach_type_to_prog_type,得到它的 attach type
再搜索內(nèi)核代碼,看這些 attach type 在內(nèi)核哪里被調(diào)用了。
最后看看它的入口參數(shù)和 return value 的處理過程,基本就能理解其作用了。
include/uapi/linux/bpf.h
enum?bpf_prog_type?{
}
是第一個被添加到內(nèi)核的程序類型。當你 attach 一個 bpf 程序到 socket 上,你可以獲取到被 socket 處理的所有數(shù)據(jù)包。socket 過濾不允許你修改這些數(shù)據(jù)包以及這些數(shù)據(jù)包的目的地。僅僅是提供給你觀察這些數(shù)據(jù)包。在你的程序中可以獲取到諸如 protocol type 類型等。
以 tcp 為 example,調(diào)用的地點是 tcp_v4_rcv->tcp_filter->sk_filter_trim_cap 作用是過濾報文,或者 trim 報文。udp,icmp 中也有相關(guān)的調(diào)用。
BPF_PROG_TYPE_SOCK_OPS
在 tcp 協(xié)議 event 發(fā)生時調(diào)用的 bpf 鉤子,定義了 15 種 event。這些 event 的 attach type 都是 BPF_CGROUP_SOCK_OPS。不同的調(diào)用點會傳入不同的 enum,比如:
BPF_SOCK_OPS_TCP_CONNECT_CB 是主動 tcp connect call 的;
BPF_SOCK_OPS_ACTIVE_ESTABLISHED_CB 是被動 connect 成功時調(diào)用的。
主要作用:tcp 調(diào)優(yōu),event 統(tǒng)計等。
BPF_PROG_TYPE_SOCK_OPS 這種程序類型,允許你當數(shù)據(jù)包在內(nèi)核網(wǎng)絡協(xié)議棧的各個階段傳輸?shù)臅r候,去修改套接字的鏈接選項。他們 attach 到 cgroups 上,和 BPF_PROG_TYPE_CGROUP_SOCK 以及 BPF_PROG_TYPE_CGROUP_SKB 很像,但是不同的是,他們可以在整個連接的生命周期內(nèi)被調(diào)用好多次。
你的 bpf 程序會接受到一個 op 的參數(shù),該參數(shù)代表內(nèi)核將通過套接字鏈接執(zhí)行的操作。因此,你知道在鏈接的生命周期內(nèi)何時調(diào)用該程序。另一方面,你可以獲取 ip 地址,端口等。你還可以修改鏈接的鏈接的選項以設置超時并更改數(shù)據(jù)包的往返延遲時間。
舉個例子,F(xiàn)acebook 使用它來為同一數(shù)據(jù)中心內(nèi)的連接設置短恢復時間目標(RTO)。RTO 是一種時間,它指的是網(wǎng)絡在出現(xiàn)故障后的恢復時間,這個指標也表示網(wǎng)絡在受到不可接受到情況下的,不能被使用的時間。Facebook 認為,在同一數(shù)據(jù)中心中,應該有一個很短的 RTO,F(xiàn)acebook 修改了這個時間,使用 bpf 程序。
BPF_PROG_TYPE_CGROUP_SOCK_ADDR
它對應很多 attach type,一般在 bind,connect 時調(diào)用,傳入 sock 的地址。
主要作用:例如 cilium 中 clusterip 的實現(xiàn),在主動 connect 時,修改了目的 ip 地址,就是利用這個。
BPF_PROG_TYPE_CGROUP_SOCK_ADDR,這種類型的程序使你可以在由特定 cgroup 控制的用戶空間程序中操縱 IP 地址和端口號。在某些情況下,當您要確保一組特定的用戶空間程序使用相同的 IP 地址和端口時,系統(tǒng)將使用多個 IP 地址。
當你將這些用戶空間程序放在同一 cgroup 中時,這些 BPF 程序使你可以靈活地操作這些綁定。這樣可以確保這些應用程序的所有傳入和傳出連接均使用 BPF 程序提供的 IP 和端口。
BPF_PROG_TYPE_SK_MSG
BPF_PROG_TYPE_SK_MSG, These types of programs let you control whether a message sent to a socket should be delivered.
當內(nèi)核創(chuàng)建了一個 socket,它會被存儲在前面提到的 map 中。當你 attach 一個程序到這個 socket map 的時候,所有的被發(fā)送到那些 socket 的 message 都會被 filter。在 filter message 之前,內(nèi)核拷貝了這些 data,因此你可以讀取這些 message,而且可以給出你的決定:例如,SK_PASS 和 SK_DROP。
BPF_PROG_TYPE_SK_SKB
調(diào)用點:tcp sendmsg 時會調(diào)用。
主要作用:做sock redir 用的。
BPF_PROG_TYPE_SK_SKB,這類程序可以讓你獲取 socket maps 和 socket redirects。socket maps 可以讓你獲得一些 socket 的引用。當你有了這些引用,你可以使用相關(guān)的 helpers,去重定向一個 incoming 的 packet ,從一個 socket 去另外一個 scoket。
這在使用 BPF 來做負載均衡時是非常有用的。你可以在 socket 之間轉(zhuǎn)發(fā)網(wǎng)絡數(shù)據(jù)包,而不需要離開內(nèi)核空間。Cillium 和 Facebook 的 Katran 廣泛的使用這種類型的程序去做流量控制。
BPF_PROG_TYPE_CGROUP_SOCKOPT
調(diào)用點:getsockopt,setsockopt
BPF_PROG_TYPE_KPROBE
類似 ftrace 的 kprobe,在函數(shù)出入口的 hook 點,debug 用的。
BPF_PROG_TYPE_TRACEPOINT
類似 ftrace 的 tracepoint。
BPF_PROG_TYPE_SCHED_CLS
如上面的例子。
BPF_PROG_TYPE_XDP
網(wǎng)卡驅(qū)動收到 packet 時,尚未生成 sk_buff 數(shù)據(jù)結(jié)構(gòu)之前的一個 hook 點。
BPF_PROG_TYPE_XDP 允許你的 bpf 程序,在網(wǎng)絡數(shù)據(jù)包到達 kernel 很早的時候。在這樣的 bpf 程序中,你僅僅可能獲取到一點點的信息,因為 kernel 還沒有足夠的時間去處理。因為時間足夠的早,所以你可以在網(wǎng)絡很高的層面上去處理這些 packet。
XDP定義了很多的處理方式,例如:
XDP_PASS 就意味著,你會把 packet 交給內(nèi)核的另一個子系統(tǒng)去處理
XDP_DROP 就意味著,內(nèi)核應該丟棄這個數(shù)據(jù)包
XDP_TX 意味著,你可以把這個包轉(zhuǎn)發(fā)到 network interface card(NIC)第一次接收到這個包的時候
BPF_PROG_TYPE_CGROUP_SKB
BPF_PROG_TYPE_CGROUP_SKB 允許你過濾整個 cgroup 的網(wǎng)絡流量。在這種程序類型中,你可以在網(wǎng)絡流量到達這個 cgoup 中的程序前做一些控制。內(nèi)核試圖傳遞給同一 cgroup 中任何進程的任何數(shù)據(jù)包都將通過這些過濾器之一。
同時,你可以決定 cgroup 中的進程通過該接口發(fā)送網(wǎng)絡數(shù)據(jù)包時該怎么做。其實,你可以發(fā)現(xiàn)它和 BPF_PROG_TYPE_SOCKET_FILTER 的類型很類似。最大的不同是 cgroup_skb 是 attach 到這個 cgroup 中的所有進程,而不是特殊的進程。在 container 的環(huán)境中,bpf 是非常有用的。
ingress 方向上,tcp 收到報文時(tcp_v4_rcv),會調(diào)用這個 bpf 做過濾。
egress 方向上,ip 在出報文時(ip_finish_output)會調(diào)用它做丟包過濾 輸入?yún)?shù)是skb。
BPF_PROG_TYPE_CGROUP_SOCK
在 sock create,release,post_bind 時調(diào)用的。主要用來做一些權(quán)限檢查的。
BPF_PROG_TYPE_CGROUP_SOCK,這種類型的 bpf 程序允許你,在一個 cgroup 中的任何進程打開一個 socket 的時候,去執(zhí)行你的 Bpf 程序。這個行為和 CGROUP_SKB 的行為類似,但是它是提供給你 cgoup 中的進程打開一個新的 socket 的時候的情況,而不是給你網(wǎng)絡數(shù)據(jù)包通過的權(quán)限控制。
這對于為可以打開套接字的程序組提供安全性和訪問控制很有用,而不必分別限制每個進程的功能。
—?5?—
eBPF 工具鏈
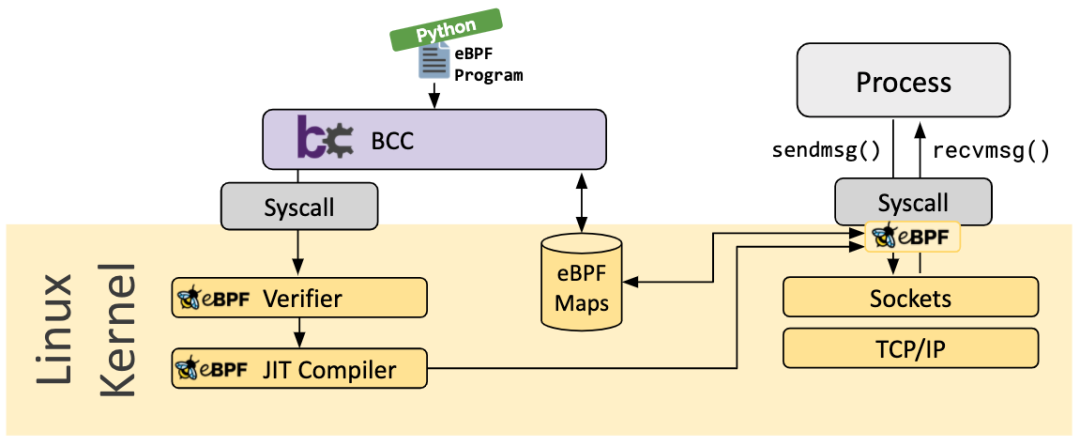
BCC
BCC 是 BPF 的編譯工具集合,前端提供 Python/Lua API,本身通過 C/C++ 語言實現(xiàn),集成 LLVM/Clang 對 BPF 程序進行重寫、編譯和加載等功能, 提供一些更人性化的函數(shù)給用戶使用。
雖然 BCC 竭盡全力地簡化 BPF 程序開發(fā)人員的工作,但其“黑魔法” (使用 Clang 前端修改了用戶編寫的 BPF 程序)使得出現(xiàn)問題時,很難找到問題的所在以及解決方法。必須記住命名約定和自動生成的跟蹤點結(jié)構(gòu) 。且由于 libbcc 庫內(nèi)部集成了龐大的 LLVM/Clang 庫,使其在使用過程中會遇到一些問題:
在每個工具啟動時,都會占用較高的 CPU 和內(nèi)存資源來編譯 BPF 程序,在系統(tǒng)資源已經(jīng)短缺的服務器上運行可能引起問題;
依賴于內(nèi)核頭文件包,必須將其安裝在每個目標主機上。即便如此,如果需要內(nèi)核中未 export 的內(nèi)容,則需要手動將類型定義復制/粘貼到 BPF 代碼中;
由于 BPF 程序是在運行時才編譯,因此很多簡單的編譯錯誤只能在運行時檢測到,影響開發(fā)體驗。
隨著 BPF CO-RE 的落地,我們可以直接使用內(nèi)核開發(fā)人員提供的 libbpf 庫來開發(fā) BPF 程序,開發(fā)方式和編寫普通 C 用戶態(tài)程序一樣:一次編譯生成小型的二進制文件。Libbpf 作為 BPF 程序加載器,接管了重定向、加載、驗證等功能,BPF 程序開發(fā)者只需要關(guān)注 BPF 程序的正確性和性能即可。這種方式將開銷降到了最低,且去除了龐大的依賴關(guān)系,使得整體開發(fā)流程更加順暢。
性能優(yōu)化大師 Brendan Gregg 在用 libbpf + BPF CO-RE 轉(zhuǎn)換一個 BCC 工具后給出了性能對比數(shù)據(jù):
As my colleague Jason pointed out, the memory footprint of opensnoop as CO-RE is much lower than opensnoop.py. 9 Mbytes for CO-RE vs 80 Mbytes for Python.
我們可以看到在運行時相比 BCC 版本,libbpf + BPF CO-RE 版本節(jié)約了近 9 倍的內(nèi)存開銷,這對于物理內(nèi)存資源已經(jīng)緊張的服務器來說會更友好。
關(guān)于 BCC 可以參考我的這篇文章[10]介紹。
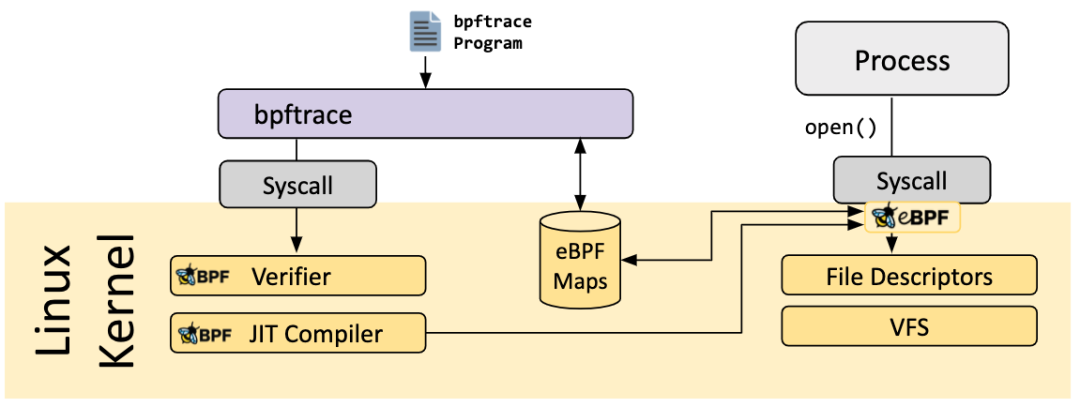
bpftrace
bpftrace is a high-level tracing language for Linux eBPF and available in recent Linux kernels (4.x). bpftrace uses LLVM as a backend to compile scripts to eBPF bytecode and makes use of BCC for interacting with the Linux eBPF subsystem as well as existing Linux tracing capabilities: kernel dynamic tracing (kprobes), user-level dynamic tracing (uprobes), and tracepoints. The bpftrace language is inspired by awk, C and predecessor tracers such as DTrace and SystemTap.
eBPF Go Library
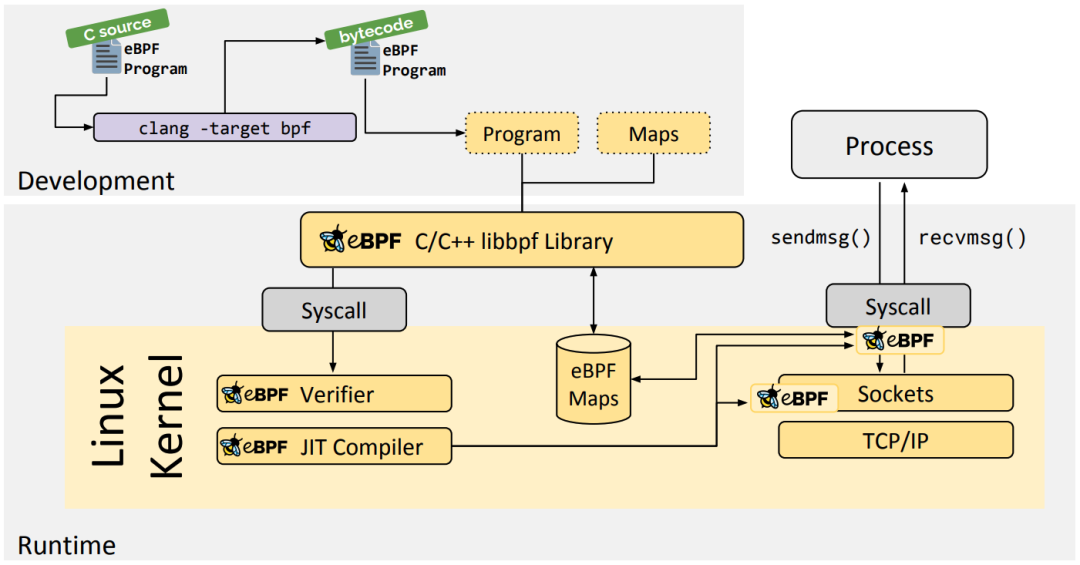
libbpf
本篇文章還在持續(xù)更新中,請點擊閱讀原文關(guān)注原文。
相關(guān)鏈接:
https://github.com/SimpCosm/godemo/tree/master/ebpf
http://www.tcpdump.org/papers/bpf-usenix93.pdf
https://github.com/torvalds/linux/blob/v5.8/include/linux/filter.h
https://github.com/torvalds/linux/blob/v5.8/include/linux/bpf.h
https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md#1-bpf_trace_printk
https://elixir.bootlin.com/linux/v5.4/source/samples/bpf/bpf_load.c#L659
https://elixir.bootlin.com/linux/v5.4/source/samples/bpf/bpf_load.c#L76
https://houmin.cc/posts/98a3c8ff/
https://man7.org/linux/man-pages/man7/bpf-helpers.7.html
https://houmin.cc/posts/6a8748a1/
—————END—————
推薦閱讀
干貨|如何步入Service Mesh微服務架構(gòu)時代
實戰(zhàn)|Service Mesh微服務架構(gòu)實現(xiàn)服務間gRPC通信