
Pandas用的6不6,來試試這道題就能看出來
導讀
近日,在實際工作中遇到了這樣一道數(shù)據(jù)處理的實際問題,憑借自己LeetCode200+算法題和Pandas熟練運用一年的功底,很快就完成了。特此小結,以資后鑒!
題目描述:給定一組用戶的多次行為起止時間表,由于相鄰行為之間可能存在交叉(即后一行為的開始時間可能早于前一行為的結束時間),所以需根據(jù)用戶ID對其相應的起止時間信息進行合并處理。不失一般性,模擬示例數(shù)據(jù)如下:
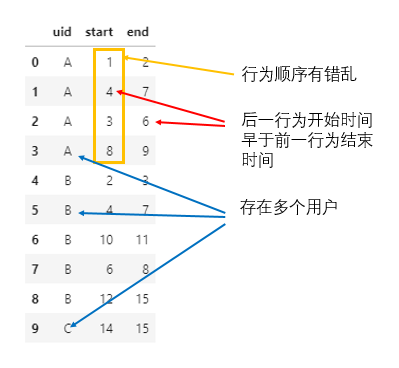
在上述示例數(shù)據(jù)中,用戶A和用戶B的多組行為間,均存在一定的起止時間交叉,例如用戶A的兩個行為起止時間分別為[3, 6]和[4, 7](同時,這里的兩組行為開始時間先后順序還是錯的),存在交叉,所以可合并為[3, 7];類似地,用戶B的兩個行為起止時間分別為[4, 7]和[6, 8],也可合并為[4, 8]。
為完成以上這一小需求,實際上可拆解為兩個小問題:
給定同一用戶的多組行為起始時間,根據(jù)起止時間的大小完成區(qū)間合并問題。實際上,這是LeetCode的一道原題
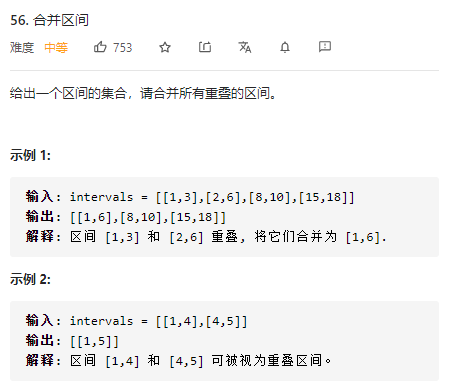
圖片源自LeetCode56題截圖
在完成單個用戶區(qū)間合并的基礎上,如何處理多用戶的區(qū)間合并以及最后結果的拼接問題。用Pandas的思維來講,自然就是groupby的過程:split—aggregate(range combine)—union
1def?range_combine(starts,?ends):
2????#?在starts有序的前提下,完成區(qū)間合并
3????combines?=?[]
4????for?start,?end?in?zip(starts,?ends):
5????????if?not?combines?or?start?>?combines[-1][1]:
6????????????combines.append([start,?end])
7????????else:
8????????????combines[-1][1]?=?max(combines[-1][1],?end)
9????return?combines
10#?測試樣例
11starts?=?[1,?3,?4,?8]
12ends?=?[2,?6,?7,?9]
13range_combine(starts,?ends)
14#?輸出?[[1,?2],?[3,?7],?[8,?9]]

進而,可以完成各用戶多個行為起止區(qū)間分裂成多行的過程,具體實現(xiàn)如下:
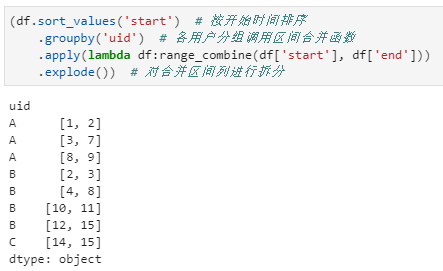

一個現(xiàn)實需求,對應多個數(shù)據(jù)處理小技巧,這真是實踐出真知啊!
相關閱讀:
評論
圖片
表情