
深入了解Mysql索引數(shù)據(jù)結(jié)構(gòu)
目錄
1: 索引結(jié)構(gòu)
** 哈希表
** 有序數(shù)組
** 二叉樹
** 多叉樹
2: 多叉樹索引維護
一:索引結(jié)構(gòu)
提到數(shù)據(jù)庫索引大家肯定不陌生,那到底什么是索引呢,索引是怎么工作的呢,今天就一起來聊聊這個話題
索引的出現(xiàn)就是為了解決數(shù)據(jù)庫查詢的效率問題,就像平時我們看書一樣,想要找某個詳細的內(nèi)容,就先通過目錄去找到大概的地方,再找具體的內(nèi)容,索引就是數(shù)據(jù)庫中的“目錄”
下面我們進入今天的正題,索引數(shù)據(jù)結(jié)構(gòu)的類型
哈希表
哈希表是一種以(Key-value)的形式存儲的數(shù)據(jù)結(jié)構(gòu),這種數(shù)據(jù)結(jié)構(gòu)我們接觸的最多的就是HashMap的數(shù)據(jù)結(jié)構(gòu)了。通過Key找到Value,哈希表的數(shù)據(jù)存儲很簡單,把value存在數(shù)組中,這個value存的的位置就是key通過哈希函數(shù)轉(zhuǎn)換得到的,不同的key通過哈希函數(shù)得到的值可能是一樣的,針對這種情況會拉出一個鏈表,相同位置的value存放在鏈表上,然后遍歷鏈表的值。哈希表的特點就是查詢等值的場景,做范圍查詢性能都是不好的。
有序數(shù)組
有序數(shù)組在等值查詢和范圍查詢的場景下查詢效率都特別好,但是索引有更新的時候有序數(shù)組就遇到大問題了,所以有序數(shù)組適合靜態(tài)數(shù)據(jù)的存儲。
二叉樹
二叉搜索樹的特點是:每個節(jié)點的左兒子小于父節(jié)點,父節(jié)點又小于右兒子。樹可以有二叉,也可以有多叉。多叉樹就是每個節(jié)點有多個兒子,兒子之間的大小保證從左到右遞增。二叉樹是搜索效率最高的,但是實際上大多數(shù)的數(shù)據(jù)庫存儲卻并不使用二叉樹。其原因是,索引不止存在內(nèi)存中,還要寫到磁盤上。為了讓一個查詢盡量少地讀磁盤,就必須讓查詢過程訪問盡量少的數(shù)據(jù)塊。那么,我們就不應(yīng)該使用二叉樹,而是要使用“N 叉”樹。這里,“N 叉”樹中的“N”取決于數(shù)據(jù)塊的大小。
Innodb引擎的索引
Innodb使用的是B+樹的數(shù)據(jù)結(jié)構(gòu)存儲索引數(shù)據(jù),每一個索引在引擎里面都有一顆對應(yīng)的B+樹
假設(shè),有個表主鍵為Id,有個字段X,在X上有索引。往表中插入一些值
(1,10)(2,20)(3,30)(4,40)(7,70)(8,80),下面是索引的組織結(jié)構(gòu)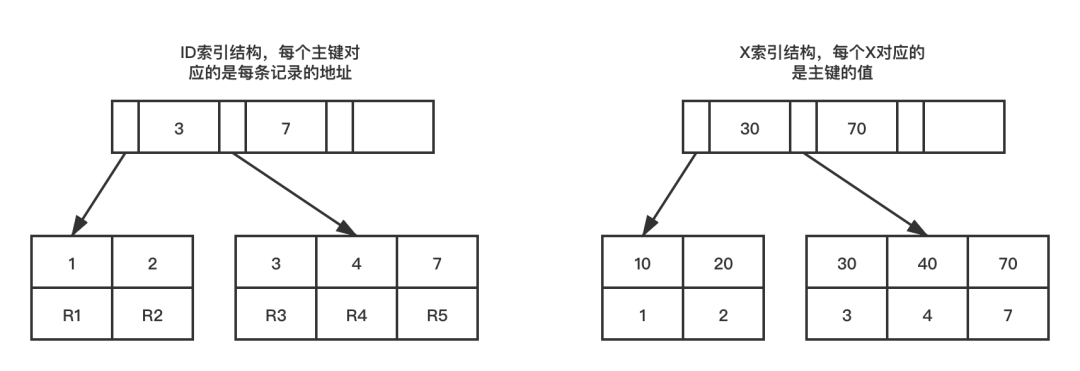 從圖中不難看出,主鍵索引(聚簇索引)存的是對應(yīng)的數(shù)據(jù),非主鍵索引(二級索引)存的是主鍵id
從圖中不難看出,主鍵索引(聚簇索引)存的是對應(yīng)的數(shù)據(jù),非主鍵索引(二級索引)存的是主鍵id
主鍵索引和非主鍵索引的區(qū)別
select id from table_name where id = ? 這種查詢只要訪問主鍵索引就能拿到結(jié)果
select x from table_name where x = ? 這種要先訪問非主鍵索引找到id,再訪問主鍵索引拿到值,這個過程叫做回表。這樣就會多掃碼一顆索引樹。
索引維護
頁分裂和頁合并
如上圖,如果在id=4后面加入id=5的記錄,需要在邏輯上移動后面的數(shù)據(jù),如果在id=7后面加入新數(shù)據(jù),直接在后面插入就好,但是如果R7所在的數(shù)據(jù)頁滿了,根據(jù)B+樹的算法,需要重新申請一個新的數(shù)據(jù)頁,把數(shù)據(jù)移動到新的數(shù)據(jù)頁,這個過程叫頁分裂,性能受到影響,還會降低空間的利用率。合并其實就是一個分裂的逆過程。
自增主鍵和非自增主鍵的區(qū)別
自增主鍵的數(shù)據(jù)插入,是一個遞增插入的場景。每次插入一條新記錄,都是追加操作,都不涉及到挪動其他記錄,也不會觸發(fā)葉子節(jié)點的分裂。而非遞增主鍵都相反。
主鍵的長度越小,非主鍵索引存的是主鍵的值,那么非主鍵索引占用的空間就越小。
END
今天的內(nèi)容就先講到這里,不知道大家有沒有收獲,下篇文章會給繼續(xù)給大家?guī)硭饕嚓P(guān)的知識,比如說覆蓋索引,最左匹配原則等等,下次再見。
掃一掃或者長按二維碼關(guān)注 Java 渣渣菜技術(shù)公眾號
點擊原文獲取最新電商項目。