
索引數(shù)據(jù)結(jié)構(gòu)
數(shù)據(jù)庫索引,是數(shù)據(jù)庫管理系統(tǒng)中一個(gè)排序的數(shù)據(jù)結(jié)構(gòu),主要有
B樹索引、Hash索引兩種
一:B樹索引
先來看下B樹索引結(jié)構(gòu)實(shí)列
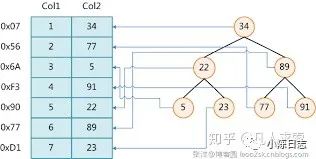
關(guān)于圖的說明如下:
左邊表示的是某個(gè)數(shù)據(jù)庫的數(shù)據(jù)表,一共有兩列七條記錄,最左邊的是數(shù)據(jù)記錄的物理地址(就是在硬盤的存儲(chǔ)位置)。為了加快對Col2這一列的查找,可以創(chuàng)建一個(gè)如右邊所示的二叉查找樹,每個(gè)節(jié)點(diǎn)分別包含索引鍵值和一個(gè)指向?qū)?yīng)數(shù)據(jù)記錄物理地址的指針,這樣就可以運(yùn)用二叉查找在O(log2n)的復(fù)雜度內(nèi)獲取到相應(yīng)數(shù)據(jù)。
舉例子來看下,比如這樣的一個(gè)查詢
select * from tablename where Col2=5
這時(shí)候會(huì)先從Col2=34的根節(jié)點(diǎn)開始找,因?yàn)?span style="font-weight:600;">5小于34,會(huì)進(jìn)入到左邊的編號位22的子節(jié)點(diǎn),依次向下推,就會(huì)找到Col2=5,這樣就比用5和Col2中的每個(gè)數(shù)字來對比下要快的多了。
其實(shí)關(guān)于B樹,大多數(shù)用的是B樹的變種,主要有B-,B+樹,關(guān)于這兩個(gè)介紹,我?guī)痛蠹艺伊藘善月嬓问浇忉屵@兩個(gè)概念的,比較容易理解,保證你看完后不會(huì)有這樣的感覺

兩篇通俗易懂的文章:
漫畫:什么是B-樹?
漫畫:什么是B+樹?
二:理解Hash樹索引
哈希索引就是采用一定的哈希算法,把鍵值換算成新的哈希值,檢索時(shí)不需要類似B+樹那樣從根節(jié)點(diǎn)到葉子節(jié)點(diǎn)逐級查找,只需一次哈希算法即可立刻定位到相應(yīng)的位置,速度非常快。
Hash 索引結(jié)構(gòu)的特殊性,其檢索效率非常高,索引的檢索可以一次定位,這時(shí)疑問就來了,既然 Hash 索引的效率要比 B-Tree 高很多,為什么大家不都用 Hash 索引而還要使用 B-Tree 索引呢?任何事物都是有兩面性的,Hash 索引也一樣,雖然 Hash 索引效率高,但是 Hash 索引本身由于其特殊性也帶來了很多限制和弊端,主要有以下這些。
1.Hash索引只支持等值比較,例如使用=,IN( )和<=>。對于WHERE price>100并不能加速查詢
如果是等值查詢,那么哈希索引明顯有絕對優(yōu)勢,因?yàn)橹恍枰?jīng)過一次算法即可找到相應(yīng)的鍵值;當(dāng)然了,這個(gè)前提是,鍵值都是唯一的。如果鍵值不是唯一的,就需要先找到該鍵所在位置,然后再根據(jù)鏈表往后掃描,直到找到相應(yīng)的數(shù)據(jù);
由于 Hash 索引比較的是進(jìn)行 Hash 運(yùn)算之后的 Hash 值,所以它只能用于等值的過濾,不能用于基于范圍的過濾,因?yàn)榻?jīng)過相應(yīng)的 Hash 算法處理之后的 Hash 值的大小關(guān)系,并不能保證和Hash運(yùn)算前完全一樣。
2.Hash 索引無法被用來避免數(shù)據(jù)的排序操作
由于 Hash 索引中存放的是經(jīng)過 Hash 計(jì)算之后的 Hash 值,而且Hash值的大小關(guān)系并不一定和 Hash 運(yùn)算前的鍵值完全一樣,所以數(shù)據(jù)庫無法利用索引的數(shù)據(jù)來避免任何排序運(yùn)算;
3.Hash 索引不支持多列聯(lián)合索引的最左匹配規(guī)則
對于組合索引,Hash 索引在計(jì)算 Hash 值的時(shí)候是組合索引鍵合并后再一起計(jì)算 Hash 值,而不是單獨(dú)計(jì)算 Hash 值,所以通過組合索引的前面一個(gè)或幾個(gè)索引鍵進(jìn)行查詢的時(shí)候,Hash 索引也無法被利用。
4.Hash索引在任何時(shí)候都不能避免表掃描
前面已經(jīng)知道,Hash 索引是將索引鍵通過 Hash 運(yùn)算之后,將 Hash運(yùn)算結(jié)果的 Hash 值和所對應(yīng)的行指針信息存放于一個(gè) Hash 表中,由于不同索引鍵存在相同 Hash 值,所以即使取滿足某個(gè) Hash 鍵值的數(shù)據(jù)的記錄條數(shù),也無法從 Hash 索引中直接完成查詢,還是要通過訪問表中的實(shí)際數(shù)據(jù)進(jìn)行相應(yīng)的比較,并得到相應(yīng)的結(jié)果。
B+樹索引的關(guān)鍵字檢索效率比較平均,不像B樹那樣波動(dòng)幅度大,在有大量重復(fù)鍵值情況下,哈希索引的效率也是極低的,因?yàn)榇嬖谒^的哈希碰撞問題。
補(bǔ)充:
什么情況下會(huì)使用索引呢?
主鍵自動(dòng)建立唯一索引
頻繁作為查詢條件的字段應(yīng)該創(chuàng)建索引
查詢中于其他表關(guān)聯(lián)的字段,外鍵關(guān)系建立索引
頻繁更新的字段不適合建立索引,因?yàn)槊看胃虏粏螁螘r(shí)更新了記錄還會(huì)更新索引
where 條件里用不到的字段不創(chuàng)建索引
查詢中排序的字段,排序的字段若通過索引去訪問將會(huì)大大提高排序速度
查詢中統(tǒng)計(jì)或者分組的字段
哪些情況不需要?jiǎng)?chuàng)建索引
表記錄太少
經(jīng)常增刪改的表
如果某個(gè)數(shù)據(jù)列包含許多重復(fù)的內(nèi)容,為它建立索引
就沒有太多太大實(shí)際效果
關(guān)于這篇文章,希望大家能夠多理解幾遍,把索引的概念給吃透。