
思考NLP和CV中的Local和Global建模
【寫在前面】
CNN的感受野受卷積核大小的限制,導(dǎo)致了CNN實(shí)際上是一種Local的信息建模;而Self-Attention(SA)是將每個(gè)位置和所有位置計(jì)算attention weight,考慮了每個(gè)點(diǎn)之間的聯(lián)系,因此SA是一種Global的建模。
起初,CNN大多用在CV領(lǐng)域中,而SA大多用在NLP領(lǐng)域中。但是隨著SA和CNN各自優(yōu)缺點(diǎn)的顯現(xiàn)(如下表所示),越來越多的文章對(duì)這兩個(gè)結(jié)構(gòu)進(jìn)行了混合的應(yīng)用,使得模型不僅能夠捕獲全局的信息,還能建模局部信息來建模更加細(xì)粒度的信息。本文將結(jié)合兩篇NLP和CV的文章,對(duì)全局信息建模(SA)和局部信息建模(CNN)進(jìn)行進(jìn)一步的分析。
CNN和SA的優(yōu)缺點(diǎn)分析:

1)Conv的卷積核是靜態(tài)的,是與輸入的特征無關(guān)的;Self-Attention的權(quán)重是根據(jù)QKV動(dòng)態(tài)計(jì)算得到的,所以Self-Attention的動(dòng)態(tài)自適應(yīng)加權(quán)的。
2)對(duì)卷積來說,它只關(guān)心每個(gè)位置周圍的特征,因此卷積具有平移不變性。但是Self-Attention不具備這個(gè)性質(zhì)。
3)Conv的感知范圍受卷積核大小的限制,而大范圍的感知能力有利于模型獲得更多的上下文信息。Self-Attention是對(duì)特征進(jìn)行全局感知。
1.CNN和SA在NLP中的聯(lián)合應(yīng)用
1.1. 論文地址和代碼
MUSE:Parallel Multi-Scale Attention for Sequence to Sequence Learning
論文地址:https://arxiv.org/abs/1911.09483
代碼地址:https://github.com/lancopku/MUSE
核心代碼:https://github.com/xmu-xiaoma666/External-Attention-pytorch/blob/master/attention/MUSEAttention.py
1.2. Motivation
Transformer在NLP領(lǐng)域曾經(jīng)掀起了熱潮,原因是SA對(duì)句子序列的建模能力非常強(qiáng),性能上遠(yuǎn)超RNN等結(jié)構(gòu),對(duì)RNN-based NLP時(shí)代進(jìn)行了革新。
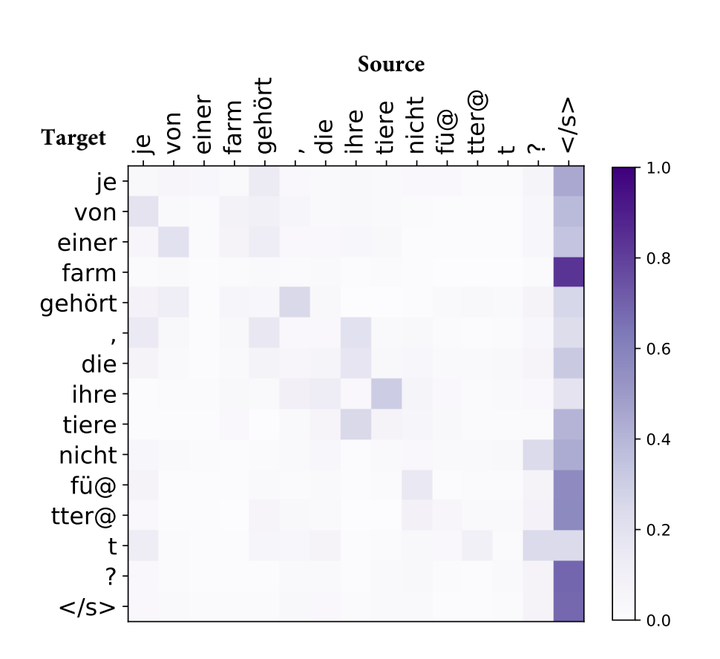
但是一些研究表明,SA對(duì)于短句子的建模非常有效,對(duì)于長句子的建模能力就會(huì)減弱。原因是SA建模時(shí)注意力會(huì)過度集中或過度分散,如下圖所示,有的區(qū)域幾乎沒有attention,有的區(qū)域會(huì)有特別大的attention weight,另外大部分區(qū)域的attention weight都比較小,只有很少一部分的區(qū)域的attention weight比較大。
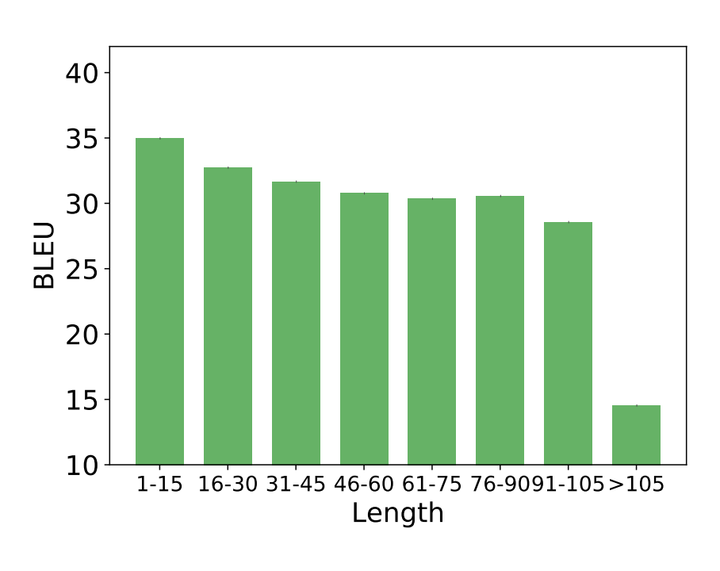
除此之外,如下圖所示,SA在短句子上的效果非常好,在長句子的效果極具下降,也在一定程度上顯示了SA對(duì)于長句子序列建模能力的不足。(這一點(diǎn)我倒是不太贊同,因?yàn)椋赡苁且驗(yàn)楸旧黹L句子包含的信息更加豐富(或者信息更加冗余),所以對(duì)于模型來說,長句子序列的學(xué)習(xí)本身就比短句子要難,所以也會(huì)導(dǎo)致性能的下降。因此,是否是因?yàn)镾A對(duì)長句子序列建模能力的不足導(dǎo)致的性能下降,還需要做進(jìn)一步的實(shí)驗(yàn))
基于以上的發(fā)現(xiàn),作者提出了通過引入多尺度的CNN,在不同尺度上進(jìn)行局部信息的感知,由此來提升SA全局建模能力的不足。
1.3. 方法
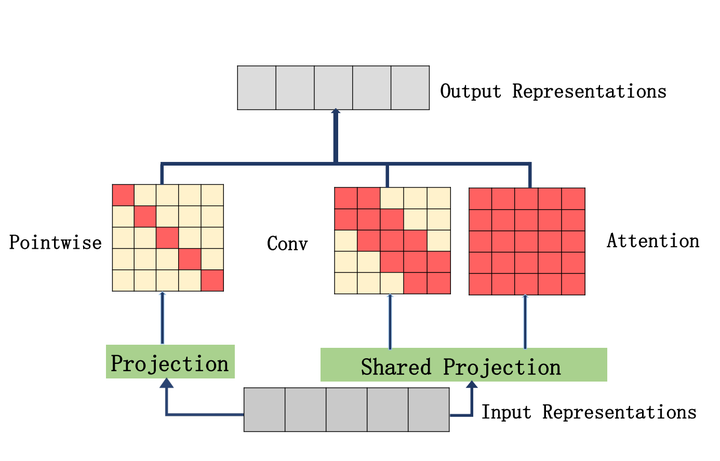
模型結(jié)構(gòu)如上圖所示,作者將原來只能對(duì)特征進(jìn)行全局建模的SA換成能夠進(jìn)行多尺度建模的CNN與SA的結(jié)合(Multi-Scale Attention)。
在卷積方面作者用的是深度可分離卷積:
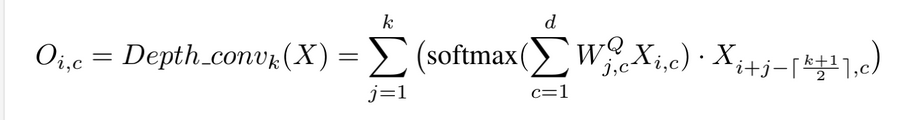
此外,除了感受野為1的特征,其他尺度的Attention在進(jìn)行特征映射的時(shí)候都采用了與SA參數(shù)共享的映射矩陣。
為了能夠動(dòng)態(tài)選擇不同感受野處理之后的特征,作者還對(duì)各個(gè)卷積核處理之后的結(jié)果進(jìn)行了動(dòng)態(tài)加權(quán):
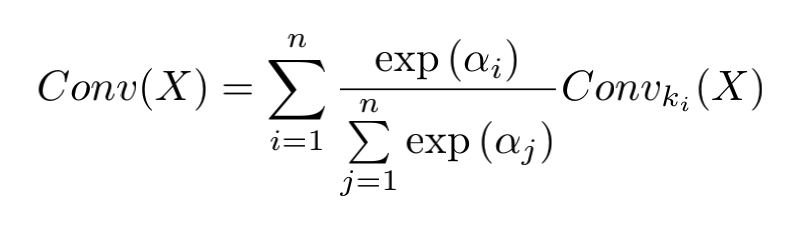
1.4. 實(shí)驗(yàn)
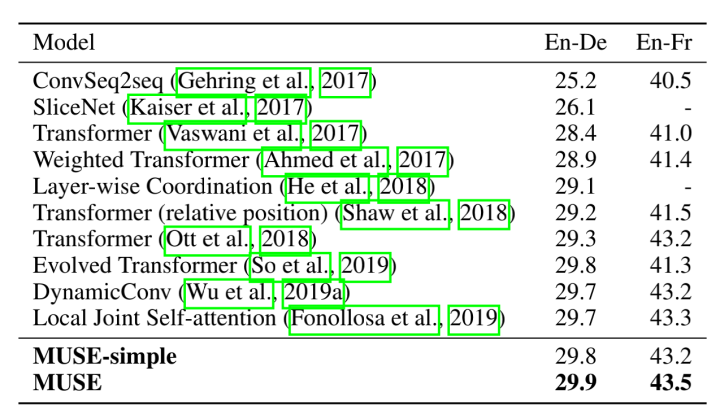
在翻譯任務(wù)上,MUSE模型能夠超過其他的所有模型。
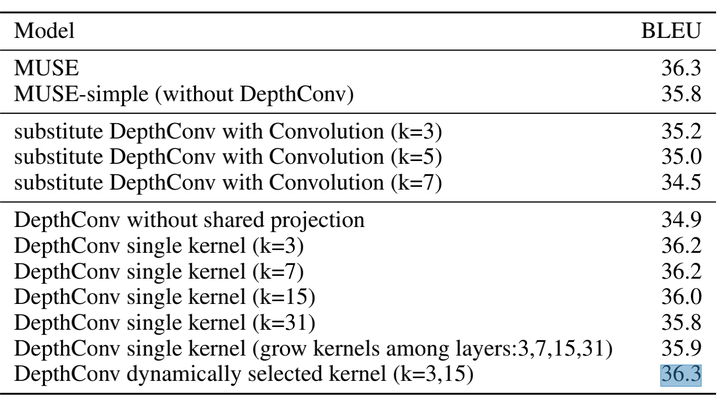
在感受野的選擇方面,如果只采用一個(gè)卷積,那么k=3或7的時(shí)候效果比較好;采用多個(gè)卷積,比采用單個(gè)卷積的效果要更好一些。
2. CV中CNN和SA的聯(lián)合應(yīng)用
2.1. 論文地址代碼
CoAtNet: Marrying Convolution and Attention for All Data Sizes
論文地址:https://arxiv.org/abs/2106.04803
官方代碼:未開源
核心代碼:https://github.com/xmu-xiaoma666/External-Attention-pytorch/blob/master/attention/CoAtNet.py
2.2. Motivation
在本文的【寫在前面】,我們提到了CNN有一個(gè)特點(diǎn),叫做平移不變性。這是CV任務(wù)中的一個(gè)假設(shè)偏置,對(duì)于提高模型在CV任務(wù)上的泛化能力是非常重要的。而SA對(duì)于捕獲圖片的全局信息是非常重要的,能夠極大的提高模型的學(xué)習(xí)能力。因此,作者就想到了,將這兩者都用到了CV任務(wù)中,讓模型不僅擁有很強(qiáng)的泛化能力,也能擁有很強(qiáng)的學(xué)習(xí)能力。
2.3. 方法&實(shí)驗(yàn)
本文倒是沒有提什么特別新穎的方法,不過CNN和SA的串聯(lián)結(jié)構(gòu)做了詳細(xì)的實(shí)驗(yàn)。首先作者提出了四種結(jié)構(gòu),1)C-C-C-C;2)C-C-C-T;3)C-C-T-T ;4)C-T-T-T。其中C代表Convolution,T代表Transformer。
用這幾個(gè)結(jié)構(gòu)分別在ImageNet1K和JFT數(shù)據(jù)集上做了實(shí)驗(yàn),訓(xùn)練的loss和準(zhǔn)確率如下:
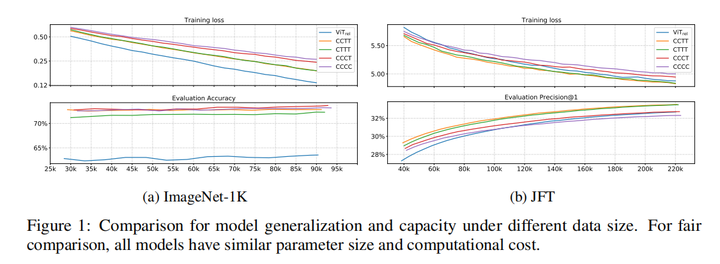
根據(jù)上面的結(jié)果,作者得出來以下的結(jié)論:
不同結(jié)構(gòu)的泛化能力排序如下:
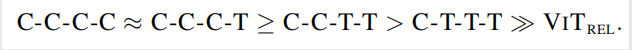
不同結(jié)構(gòu)的學(xué)習(xí)能力排序如下:
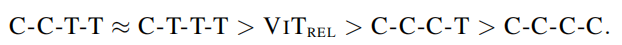
然后,作者為了探究C-C-T-T 和 C-T-T-T,哪一個(gè)比較好。作者在JFT上預(yù)訓(xùn)練后,在ImageNet-1K上再訓(xùn)練了30個(gè)epoch。結(jié)果如下:

可以看出C-C-T-T的效果比較好,因此作者選用了C-C-T-T作為CoAtNet的結(jié)構(gòu)。
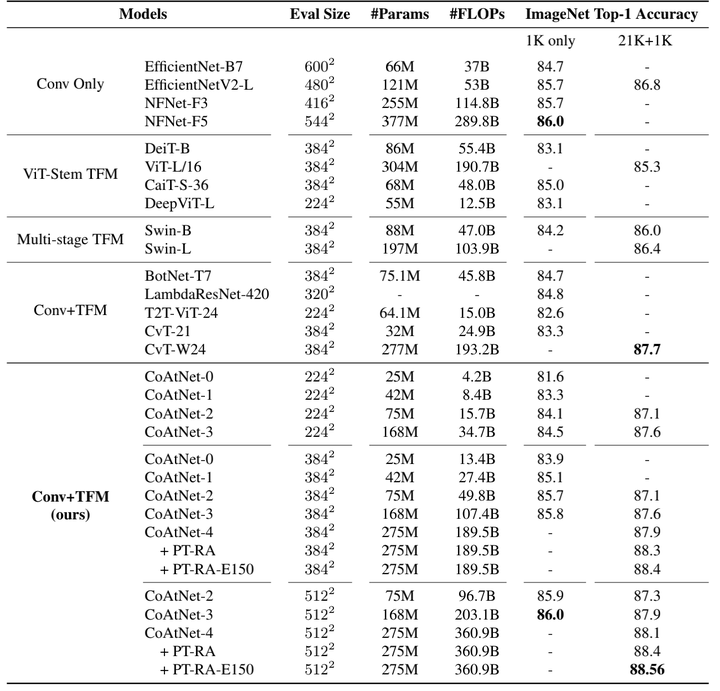
從上圖中可以看出,CNN+SA的結(jié)構(gòu)確實(shí)比單純的CNN或者SA的結(jié)構(gòu)性能要好。
【總結(jié)】
CNN和SA其實(shí)還是有一些相似,又有一些不同的。既然各有優(yōu)缺點(diǎn),將他們進(jìn)行結(jié)合確實(shí)是不個(gè)不錯(cuò)的選擇。但是,個(gè)人覺得,目前的方法將CNN和SA做結(jié)合都比較粗暴,所以會(huì)導(dǎo)致sub-optimal的問題。
個(gè)人覺得,如果能夠?qū)A融入到CNN中,形成一種內(nèi)容自適應(yīng)的卷積;或者將CNN到SA中,形成一種具有平移不變性的SA,這樣的結(jié)構(gòu),或許會(huì)比當(dāng)前這樣直接并列或者串聯(lián)有意思的多。
除此之外,出了簡單粗暴的將CNN和SA融合的到一起,最近還有一系列文章提出了局部的注意力(e.g., VOLO[1], Focal Self-Attention[2])來提高模型的能力。
【參考文獻(xiàn)】
[1]. Yuan, Li, et al. "VOLO: Vision Outlooker for Visual Recognition." arXiv preprint arXiv:2106.13112 (2021).
[2]. Yang, J., Li, C., Zhang, P., Dai, X., Xiao, B., Yuan, L., & Gao, J. (2021). Focal Self-attention for Local-Global Interactions in Vision Transformers. arXiv preprint arXiv:2107.00641.
關(guān)于文章有任何問題,歡迎在評(píng)論區(qū)留言或者添加作者微信: xmu_xiaoma