
ICLR2021 | 顯存不夠?不妨拋棄端到端訓(xùn)練
點(diǎn)擊上方“程序員大白”,選擇“星標(biāo)”公眾號(hào)
重磅干貨,第一時(shí)間送達(dá)


極市導(dǎo)讀
本文研究了一種比目前廣為使用的端到端訓(xùn)練模式顯存開銷更小、更容易并行化的訓(xùn)練方法:將網(wǎng)絡(luò)拆分成若干段、使用局部監(jiān)督信號(hào)進(jìn)行訓(xùn)練。
本文主要介紹我們被ICLR2021接收的一篇文章:Revisiting Locally Supervised Learning: an Alternative to End-to-End Training。
https://openreview.net/forum?id=fAbkE6ant2
代碼已經(jīng)在Github上面開源:https://github.com/blackfeather-wang/InfoPro-Pytorch
本文研究了一種比目前廣為使用的端到端訓(xùn)練模式顯存開銷更小、更容易并行化的訓(xùn)練方法:將網(wǎng)絡(luò)拆分成若干段、使用局部監(jiān)督信號(hào)進(jìn)行訓(xùn)練。我們指出了這一范式的一大缺陷在于損失網(wǎng)絡(luò)整體性能,并從信息的角度闡明了,其癥結(jié)在于局部監(jiān)督傾向于使網(wǎng)絡(luò)在淺層損失對(duì)深層網(wǎng)絡(luò)有很大價(jià)值的任務(wù)相關(guān)信息。為有效解決這一問題,我們提出了一種局部監(jiān)督學(xué)習(xí)算法:InfoPro。在圖像識(shí)別和語義分割任務(wù)上的實(shí)驗(yàn)結(jié)果表明,我們的算法可以在不顯著增大訓(xùn)練時(shí)間的前提下,有效節(jié)省顯存開銷,并提升性能。
1. Introduction (研究動(dòng)機(jī)及簡(jiǎn)介)
一般而言,深度神經(jīng)網(wǎng)絡(luò)以端到端的形式訓(xùn)練。以一個(gè)13層的簡(jiǎn)單卷積神經(jīng)網(wǎng)絡(luò)為例,我們會(huì)將訓(xùn)練數(shù)據(jù)輸入網(wǎng)絡(luò)中,逐層前傳至最后一層,輸出結(jié)果,計(jì)算損失值(End-to-End Loss),再?gòu)膿p失求得梯度,將之逐層反向傳播以更新網(wǎng)絡(luò)參數(shù)。
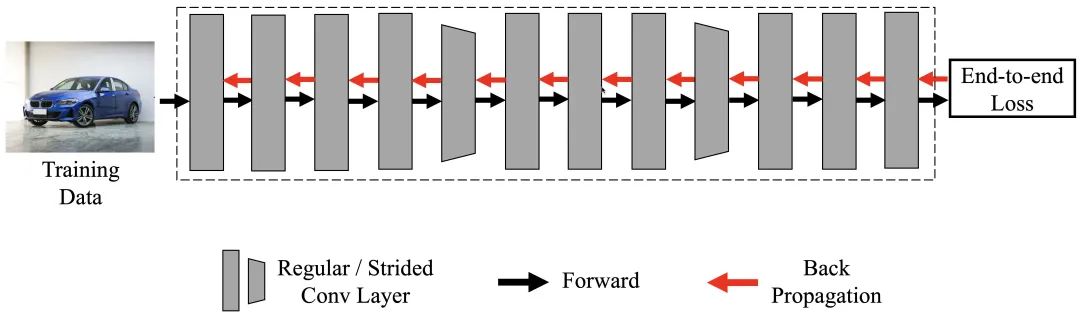
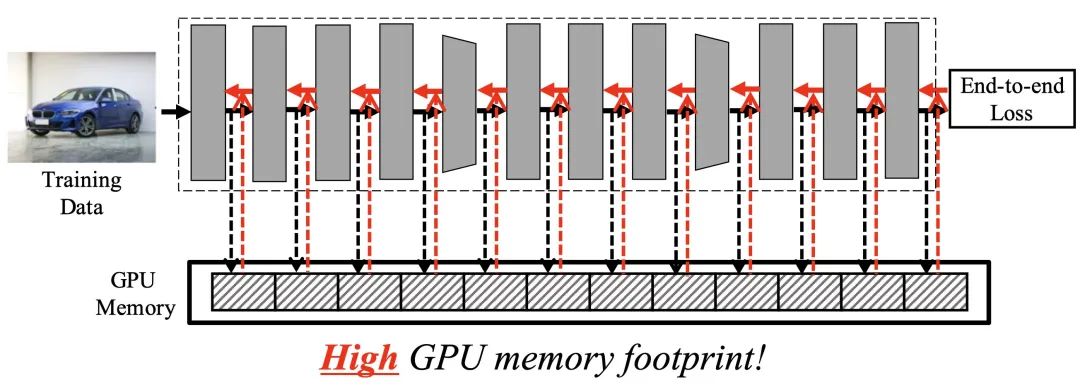
盡管端到端訓(xùn)練在大量任務(wù)中都穩(wěn)定地表現(xiàn)出了良好的效果,但其效率至少在以下兩方面仍然有待提升。其一,端到端訓(xùn)練需要在網(wǎng)絡(luò)前傳時(shí)將每一層的輸出進(jìn)行存儲(chǔ),并在逐層反傳梯度時(shí)使用這些值,這造成了極大的顯存開銷,如下圖所示。
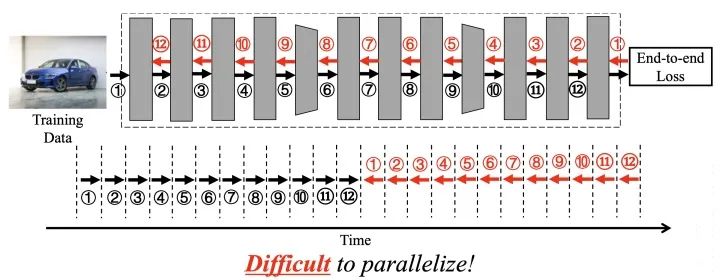
其二,對(duì)整個(gè)網(wǎng)絡(luò)進(jìn)行前傳-->反傳的這一范式是一個(gè)固有的線性過程。前傳時(shí)深層網(wǎng)絡(luò)必須等待淺層網(wǎng)絡(luò)的計(jì)算完成后才能開始自身的前傳過程;同理,反傳時(shí)淺層網(wǎng)絡(luò)需要等待來自深層網(wǎng)絡(luò)的梯度信號(hào)才能進(jìn)行自身的運(yùn)算。這兩點(diǎn)線性的限制使得端到端訓(xùn)練很難進(jìn)行并行化以進(jìn)一步的提升效率。
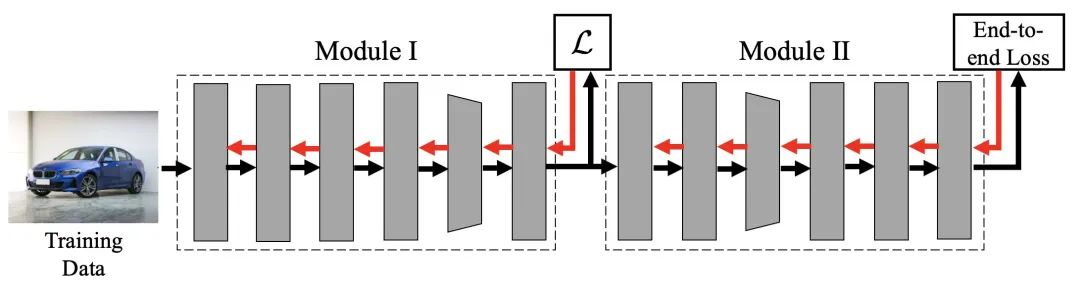
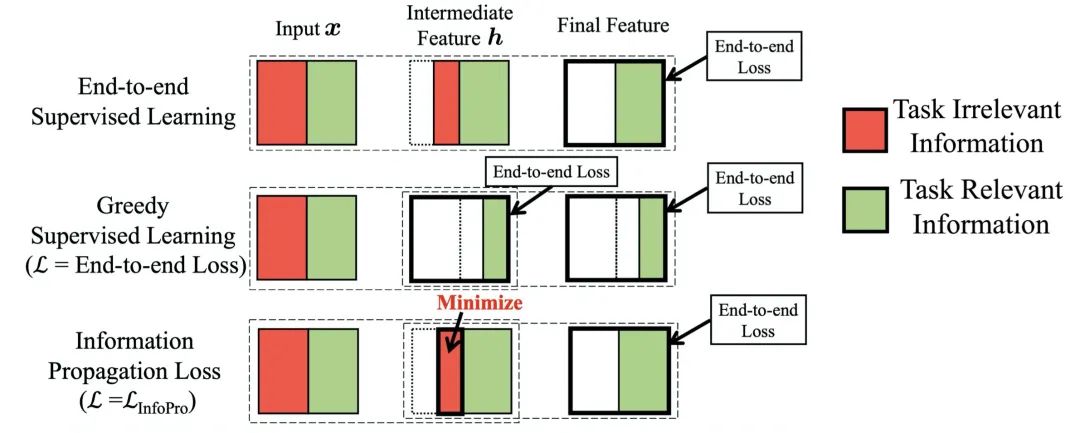
為了解決或緩解上述兩點(diǎn)低效的問題,一個(gè)可能的方案是使用局部監(jiān)督學(xué)習(xí),即將網(wǎng)絡(luò)拆分為若干個(gè)局部模塊(local module),并在每個(gè)模塊的末端添加一個(gè)局部損失,利用這些局部損失產(chǎn)生監(jiān)督信號(hào)分別訓(xùn)練各個(gè)局部模塊,注意不同模塊間沒有梯度上的聯(lián)通。下圖給出了一個(gè)將網(wǎng)絡(luò)拆分為兩段的例子。
相較于端到端訓(xùn)練的兩點(diǎn)不足,局部監(jiān)督學(xué)習(xí)在效率上先天具有顯著優(yōu)勢(shì)。其一,我們一次只需保存一個(gè)局部模塊內(nèi)的中間層輸出值,待此模塊完成反向傳播后,即可釋放存儲(chǔ)空間,進(jìn)而復(fù)用同樣的空間用以存儲(chǔ)下一個(gè)局部模塊的中間層輸出值,如下圖所示。簡(jiǎn)言之,理論上顯存開銷隨局部模塊數(shù)呈指數(shù)級(jí)下降。
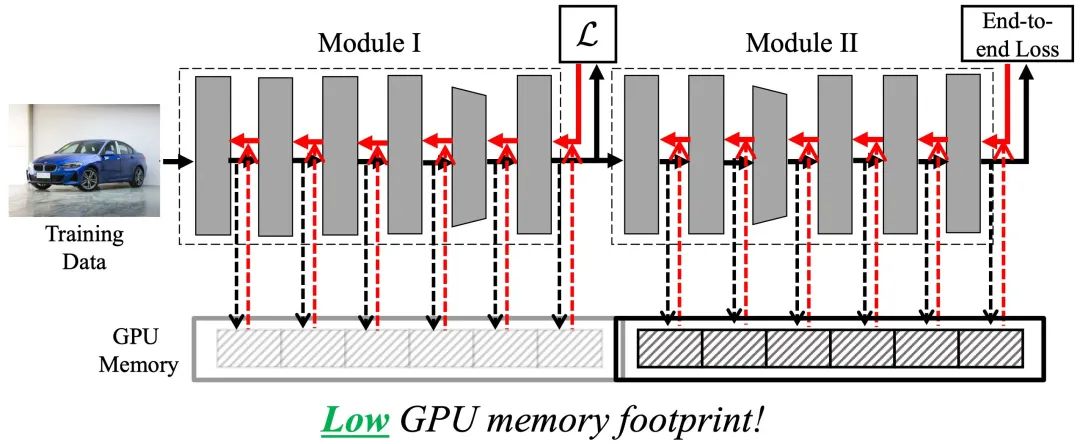
其二,不同局部模塊的反向傳播過程并沒有必然的前后依賴關(guān)系,在工程實(shí)現(xiàn)上,不同模塊的訓(xùn)練可以自然的并行完成,例如分別使用不同的GPU,如下圖所示。
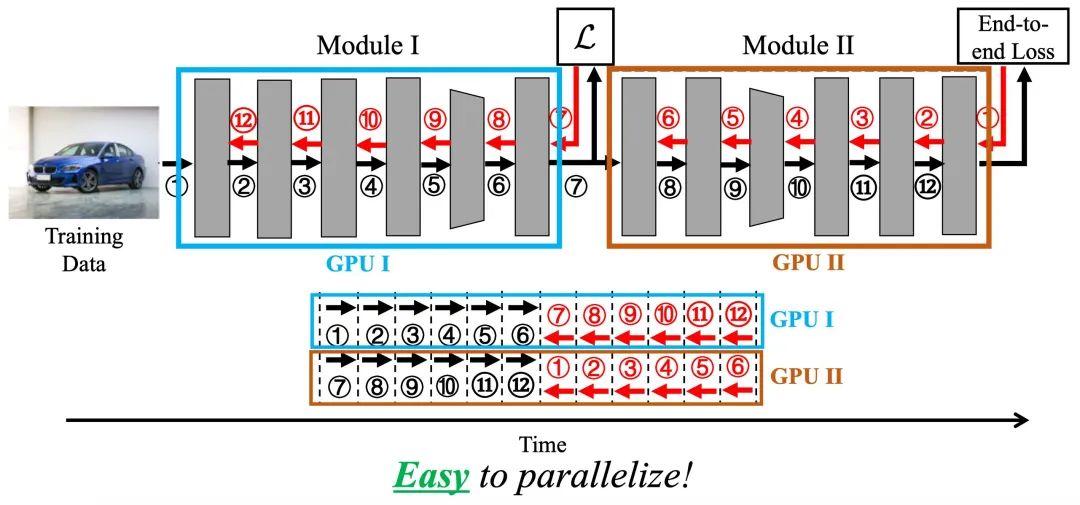
2. Analysis (問題分析與假設(shè))
相信大家看到這里,都會(huì)有一個(gè)問題:既然局部監(jiān)督學(xué)習(xí)的效率自然地高于端到端訓(xùn)練,為什么它現(xiàn)在沒有被大規(guī)模應(yīng)用呢?其問題在于,局部監(jiān)督學(xué)習(xí)往往會(huì)損害網(wǎng)絡(luò)的整體性能。
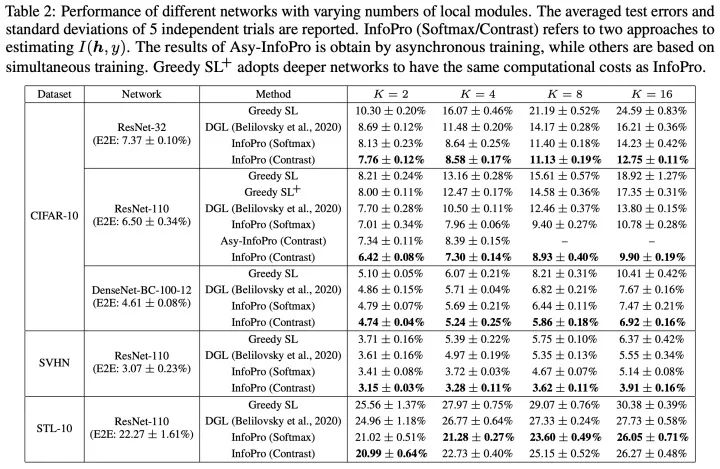
以圖片識(shí)別為例,考慮一種簡(jiǎn)單自然的情況,我們使用標(biāo)準(zhǔn)的線性分類器+SoftMax+交叉熵作為每個(gè)局部模塊的損失函數(shù),在CIFAR-10數(shù)據(jù)集上使用局部監(jiān)督學(xué)習(xí)訓(xùn)練ResNet-32,結(jié)果如下所示,其中 代表局部模塊的數(shù)目。可以看出隨著值的增長(zhǎng),網(wǎng)絡(luò)的測(cè)試誤差急劇上升。
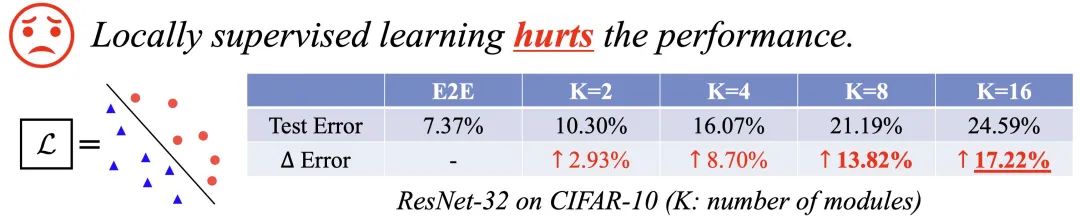
若能解決性能下降的問題,局部監(jiān)督學(xué)習(xí)就有可能作為一種更為高效的訓(xùn)練范式而取代端到端訓(xùn)練。出于這一點(diǎn),我們探究和分析了這一問題的原因。
上述局部監(jiān)督學(xué)習(xí)和端到端訓(xùn)練的一個(gè)顯著的不同點(diǎn)在于,前者對(duì)網(wǎng)絡(luò)的中間層特征直接加入了與任務(wù)直接相關(guān)的監(jiān)督信號(hào),從這一點(diǎn)出發(fā),一個(gè)自然的疑問是,由此引發(fā)的中間層特征在任務(wù)相關(guān)行為上的區(qū)別是怎樣的呢?因此,我們固定了圖7中得到的模型,使用網(wǎng)絡(luò)每層的特征訓(xùn)練了一個(gè)線性分類器,其測(cè)試誤差如下圖右側(cè)所示。其中,橫軸代碼取用特征的網(wǎng)絡(luò)層數(shù),縱軸代表測(cè)試誤差,不同的曲線對(duì)應(yīng)于不同的取值,表示端到端的情形。
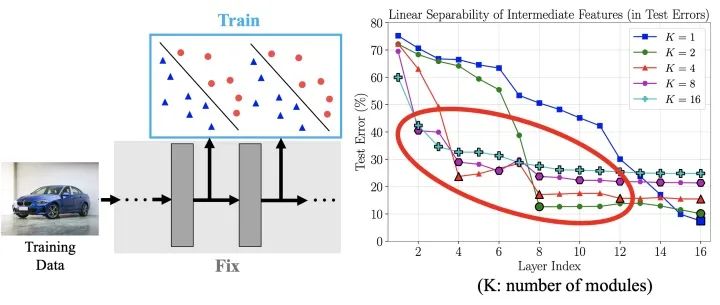
從結(jié)果中可以觀察到一個(gè)明顯的現(xiàn)象:局部監(jiān)督學(xué)習(xí)所得到的中間層特征在淺層時(shí)就體現(xiàn)出了極好的線性可分性,但當(dāng)特征進(jìn)一步經(jīng)過更深的網(wǎng)絡(luò)層時(shí),其線性可分性卻沒有得到進(jìn)一步的增長(zhǎng);相比而言,盡管在淺層時(shí)幾乎線性不可分,端到端訓(xùn)練得到的中間層特征隨著層數(shù)的加深可分性逐漸增強(qiáng),最終取得了更低的測(cè)試誤差。于是便產(chǎn)生了一個(gè)非常有趣的問題:**局部監(jiān)督學(xué)習(xí)中,深層網(wǎng)絡(luò)使用了分辨性遠(yuǎn)遠(yuǎn)強(qiáng)于端到端訓(xùn)練的特征,為何它得到的最終效果卻遜于端到端訓(xùn)練?難道基于可分性已經(jīng)很強(qiáng)的特征,訓(xùn)練網(wǎng)絡(luò)以進(jìn)一步提升其線性可分性,不應(yīng)該得到更好的最終結(jié)果嗎?**這似乎與一些之前的觀察(例如deeply supervised net)矛盾。
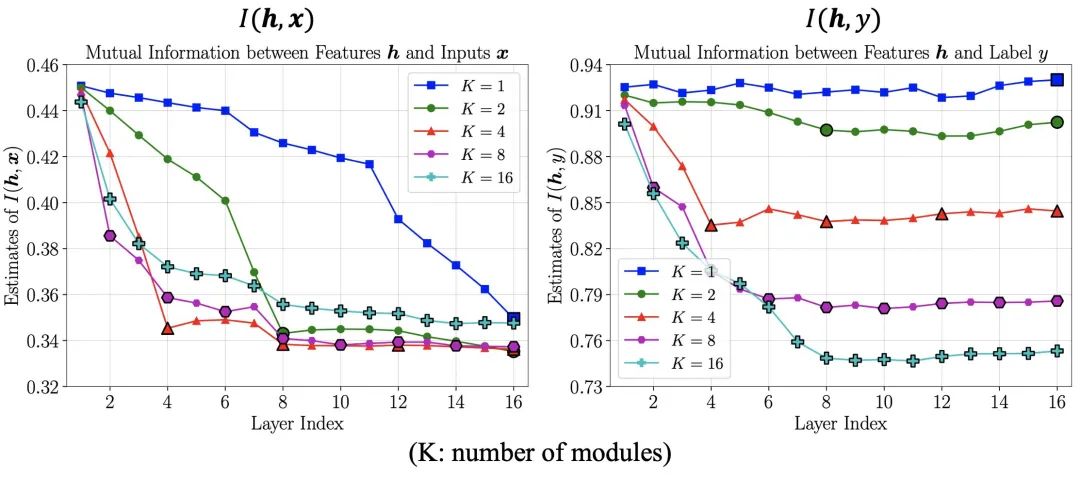
為了解答這個(gè)疑問,我們進(jìn)一步從信息的角度探究網(wǎng)絡(luò)特征在可分性之外的區(qū)別。我們分別估計(jì)了中間層特征 與輸入數(shù)據(jù) 和任務(wù)標(biāo)簽 之間的互信息 和,并以此作為中包含的全部信息和任務(wù)相關(guān)信息的度量指標(biāo)。
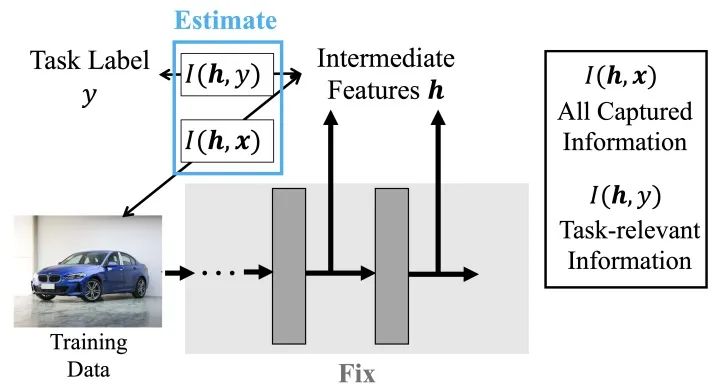
其結(jié)果如下圖所示,其中橫軸為取用信息的層數(shù),縱軸表示估計(jì)值。從中不難看出,端到端訓(xùn)練的網(wǎng)絡(luò)中,特征所包含的總信息量逐層減少,但任務(wù)相關(guān)信息維持不變,說明網(wǎng)絡(luò)逐層剔除了與任務(wù)無關(guān)的信息。與之形成鮮明對(duì)比的是,局部監(jiān)督學(xué)習(xí)得到的網(wǎng)絡(luò)在淺層就丟失了大量的任務(wù)相關(guān)信息,特征所包含的總信息量也急劇下降。我們猜測(cè),這一現(xiàn)象的原因在于,僅憑淺層網(wǎng)絡(luò)難以如全部網(wǎng)絡(luò)一般有效分離和利用所有任務(wù)相關(guān)信息,因此索性去丟棄部分無法利用的信息換取局部訓(xùn)練損失的降低。而在這種情況下,網(wǎng)絡(luò)深層接收到的特征相較網(wǎng)絡(luò)原始輸入本就缺少關(guān)鍵信息,自然難以基于其建立更有效的表征,也就難以取得更好的最終性能。
基于上述觀察,我們可以總結(jié)得到:局部監(jiān)督學(xué)習(xí)之所以會(huì)損害網(wǎng)絡(luò)的整體性能,是因?yàn)槠鋬A向于使網(wǎng)絡(luò)在淺層丟失與任務(wù)相關(guān)的信息,從而使得深層網(wǎng)絡(luò)空有更多的參數(shù)和更大的容量,卻因輸入特征先天不足而無用武之地。
3. Method (方法詳述)
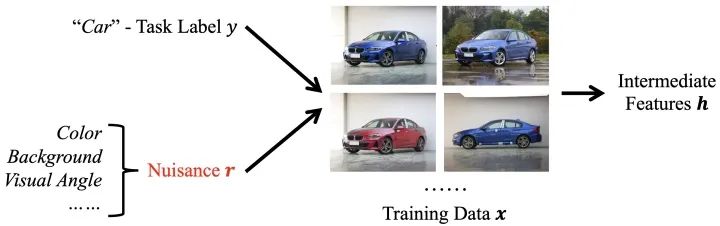
為了解決損失信息的問題,本文提出了一種專為局部監(jiān)督學(xué)習(xí)定制的損失函數(shù):InfoPro。首先,我們引入一個(gè)基本模型。如下圖所示,我們假設(shè)訓(xùn)練數(shù)據(jù)受到兩個(gè)隨機(jī)變量影響,其一是任務(wù)標(biāo)簽 ,決定我們所關(guān)心的主體內(nèi)容;其二是無關(guān)變量,用于決定數(shù)據(jù)中與任務(wù)無關(guān)的部分,例如背景、視角、天氣等。
基于上述變量設(shè)置,我們將InfoPro損失函數(shù)定義為下面的結(jié)合形式。它用于作為局部監(jiān)督信號(hào)訓(xùn)練局部模塊,由兩項(xiàng)組成。第一項(xiàng)用于推動(dòng)局部模塊向前傳遞所有信息;在第二項(xiàng)中,我們使用一個(gè)滿足特殊條件無關(guān)變量來建模中間層特征中的全部任務(wù)無關(guān)信息(無用信息),在此基礎(chǔ)上迫使局部模塊剔除這些與任務(wù)無關(guān)的信息。
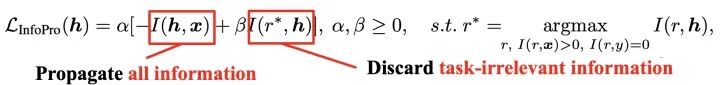
InfoPro與端到端訓(xùn)練和在 2. Analysis 中所述的簡(jiǎn)單局部監(jiān)督學(xué)習(xí)(Greedy Supervised Learning)的對(duì)比如下圖所示。簡(jiǎn)言之,InfoPro的目標(biāo)是使得局部模塊能夠在保證向前傳遞全部有價(jià)值信息的條件下,盡可能丟棄特征中的無用信息,以解決局部監(jiān)督學(xué)習(xí)在淺層丟失任務(wù)相關(guān)信息、影響網(wǎng)絡(luò)最終性能的問題。事實(shí)上,這也是我們前面觀察到的、端到端訓(xùn)練對(duì)網(wǎng)絡(luò)淺層的影響形式。InfoPro與其它局部學(xué)習(xí)方法最大的區(qū)別在于它是非貪婪的,并不直接對(duì)局部的任務(wù)相關(guān)行為(如Greedy Supervised Learning中基于局部特征的分類損失)做出直接約束。
在具體實(shí)現(xiàn)上,由于InfoPro損失的第二項(xiàng)比較難以估算,我們推導(dǎo)出了其的一個(gè)易于計(jì)算的上界,如下圖所示:
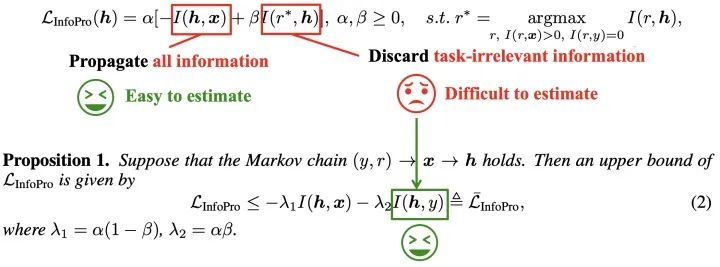
關(guān)于這一上界的具體推導(dǎo)過程、一些數(shù)學(xué)性質(zhì)和其實(shí)際上的計(jì)算方式,由于流程比較復(fù)雜且不關(guān)鍵,不在此贅述,歡迎感興趣的讀者參閱我們的文章~
4. Experiments (實(shí)驗(yàn)結(jié)果)
在不同局部模塊數(shù)目的條件下,穩(wěn)定勝過baseline
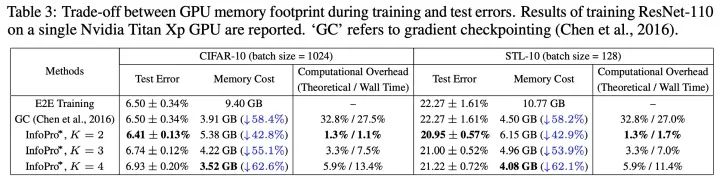
大量節(jié)省顯存,且不引入顯著的額外計(jì)算/時(shí)間開銷,效果相較端到端訓(xùn)練略有提升
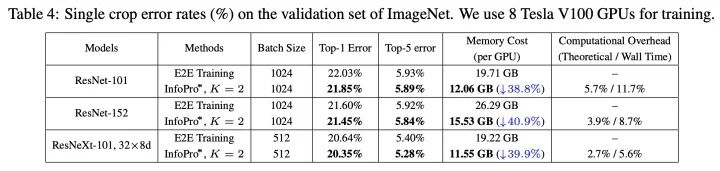
ImageNet大規(guī)模圖像識(shí)別任務(wù)上的結(jié)果,節(jié)省顯存的效果同樣顯著,效果略有提升
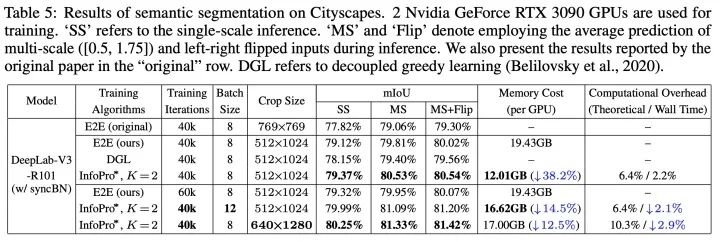
Cityscapes語義分割實(shí)驗(yàn)結(jié)果,除節(jié)省顯存方面的作用外,我們還證明了,在相同的顯存限制下,InfoPro可以使用更大的batch size或更大分辨率的輸入圖片
5. Conclusion (結(jié)語)
總結(jié)來說,這項(xiàng)工作的要點(diǎn)在于:(1)從效率的角度反思端到端訓(xùn)練范式;(2)指出了局部監(jiān)督學(xué)習(xí)相較于端到端的缺陷在于損失網(wǎng)絡(luò)性能,并從信息的角度分析了其原因;(3)在理論上提出了初步解決方案,并探討了具體實(shí)現(xiàn)方法。
歡迎大家follow我們的工作~
@inproceedings{wang2021revisiting,title = {Revisiting Locally Supervised Learning: an Alternative to End-to-end Training},author = {Yulin Wang and Zanlin Ni and Shiji Song and Le Yang and Gao Huang},booktitle = {International Conference on Learning Representations (ICLR)},year = {2021},url = {https://openreview.net/forum?id=fAbkE6ant2}}
如有任何問題,歡迎留言或者給我發(fā)郵件,附上我的主頁鏈接
https://www.rainforest-wang.cool/
推薦閱讀
國(guó)產(chǎn)小眾瀏覽器因屏蔽視頻廣告,被索賠100萬(后續(xù))
年輕人“不講武德”:因看黃片上癮,把網(wǎng)站和786名女主播起訴了
關(guān)于程序員大白
程序員大白是一群哈工大,東北大學(xué),西湖大學(xué)和上海交通大學(xué)的碩士博士運(yùn)營(yíng)維護(hù)的號(hào),大家樂于分享高質(zhì)量文章,喜歡總結(jié)知識(shí),歡迎關(guān)注[程序員大白],大家一起學(xué)習(xí)進(jìn)步!