
30分鐘 Keras 創(chuàng)建一個圖像分類器
深度學(xué)習(xí)是使用人工神經(jīng)網(wǎng)絡(luò)進行機器學(xué)習(xí)的一個子集,目前已經(jīng)被證明在圖像分類方面非常強大。盡管這些算法的內(nèi)部工作在數(shù)學(xué)上是嚴格的,但 Python 庫(比如 keras)使這些問題對我們所有人都可以接近。在本文中,我將介紹一個簡單的圖像分類器的設(shè)計,它使用人工神經(jīng)網(wǎng)絡(luò)將食物圖像分為兩類:披薩或意大利面。
下載圖片
為了訓(xùn)練我們的模型,我們將需要下載大量比薩餅和意大利面的圖像,這是一個可能非常繁瑣的任務(wù),通過 bing-image-downloader Python 庫可以非常容易地完成。
# Install Bing image downloaderpip install bing-image-downloader
現(xiàn)在,我們已經(jīng)安裝了 bing-image-downloader,我們可以很容易地抓取500張比薩餅和意大利面的照片用于訓(xùn)練和測試我們的模型!
# Import bing-image-downloaderfrom bing_image_downloader import downloader# Download imagesdownloader.download("pizza", limit=500, output_dir="photos")downloader.download("pasta", limit=500, output_dir="photos")
這應(yīng)該需要幾分鐘,之后你將有兩個子目錄下的照片稱為比薩餅和面食,每個包含500張照片。這很簡單!
數(shù)據(jù)整理
為了將我們的數(shù)據(jù)轉(zhuǎn)換成對我們的模型有利的格式,我們需要使用 glob、 pandas、 numpy 和 PIL 庫。
# Import packagesimport globimport numpy as npimport pandas as pdfrom PIL import Image
我們將使用 glob 來收集我們下載的所有圖像的文件路徑。為此,我們使用 * 通配符分配變量,以對應(yīng)目錄中的所有文件。
# Filepaths for the pizza and pasta imagesfilepath_pizza = "./photos/pizza/*"filepath_pasta = "./photos/pasta/*"
現(xiàn)在,我們可以使用 glob 創(chuàng)建列表,其中每個元素都包含文件夾中單個圖像的文件路徑:
# Collect all the image filepaths into listspizza_files = [file for file in glob.iglob(filepath_pizza)]pasta_files = [file for file in glob.iglob(filepath_pasta)]
使用所有的文件路徑,我們現(xiàn)在可以構(gòu)建一個 pandas 數(shù)據(jù)框架,我們可以在其中跟蹤文件路徑及其相關(guān)標簽(比薩或意大利面)。在這種情況下,我們將給披薩圖像一個0的標簽,給意大利面圖像一個1的標簽。為了方便地為這些標簽創(chuàng)建數(shù)組,我們可以使用 np.zeros()和 np.ones():
# Construct pandas dataframe with all the image filenames and labelsdf_photos = (pd.DataFrame({"filepath": pizza_files, "label": np.zeros(len(pizza_files))}).append(pd.DataFrame({"filepath": pasta_files, "label": np.ones(len(pasta_files))})))
現(xiàn)在,我們希望將數(shù)據(jù)集拆分為訓(xùn)練數(shù)據(jù)和測試數(shù)據(jù)。幸運的是,scikit-learn 有一個非常簡單的功能,可以直接在我們的 pandas 數(shù)據(jù)庫上為我們實現(xiàn)這個功能。我們需要設(shè)置 test_size ,它是我們用于測試集數(shù)據(jù)的一個百分比,并且,通過指定 random_state,我們可以使拆分的結(jié)果可重復(fù)進行以進行后續(xù)測試。最后,我們將重新設(shè)置并刪除新數(shù)據(jù)流的索引,因為 train_test_split 會自動為我們分配數(shù)據(jù),所以舊的索引值現(xiàn)在沒有意義了。
# Import train_test_splitfrom sklearn.model_selection import train_test_split# Split our datasetdf_train, df_test = train_test_split(df_photos, test_size=0.2, random_state=1)df_train.reset_index(drop=True, inplace=True)df_test.reset_index(drop=True, inplace=True)

我們的訓(xùn)練數(shù)據(jù)集已經(jīng)將數(shù)據(jù)與其相關(guān)的標簽混合在一起
我們有我們的圖像和標簽到一個可接受的形式,現(xiàn)在我們必須從文件路徑加載我們的圖像。我們將 PIL.Image 封裝到一個函數(shù)中,該函數(shù)將加載圖像,將其調(diào)整為128 x 128像素,將其轉(zhuǎn)換為灰度圖像,并將亮度正常化為0到1之間的值。
# Wrapper function to load and process imagesdef process_image(filepath):return np.asarray(Image.open(filepath).resize((128, 128)).convert("L")) / 255.0
讓我們來測試一下我們的封裝函數(shù),我們可以從 pizza_files 文件中加載第一張圖片,然后繪制出來看:
# Load imageimg = process_images(pizza_files[0])# Plot imagefig = plt.figure(figsize=(5, 5))ax = fig.add_subplot(111)ax.imshow(img, cmap="gray")ax.set_xticks([])ax.set_yticks([])plt.show()
酷!現(xiàn)在讓我們繼續(xù)從我們的訓(xùn)練集中繪制16張圖片,連同它們的相關(guān)標簽,來了解我們的數(shù)據(jù)是什么樣的:
# Plot 16 images from our training set with labelsfig = plt.figure(figsize=(10, 10))for i in range(16):plt.subplot(4, 4, i+1)img = process_image(df_train["filepath"].iloc[i])plt.imshow(img, cmap="gray")plt.grid(False)plt.xticks([])plt.yticks([])if df_train["label"].iloc[i] == 0:plt.title("Pizza", size=16)else:plt.title("Pasta", size=16)plt.show()
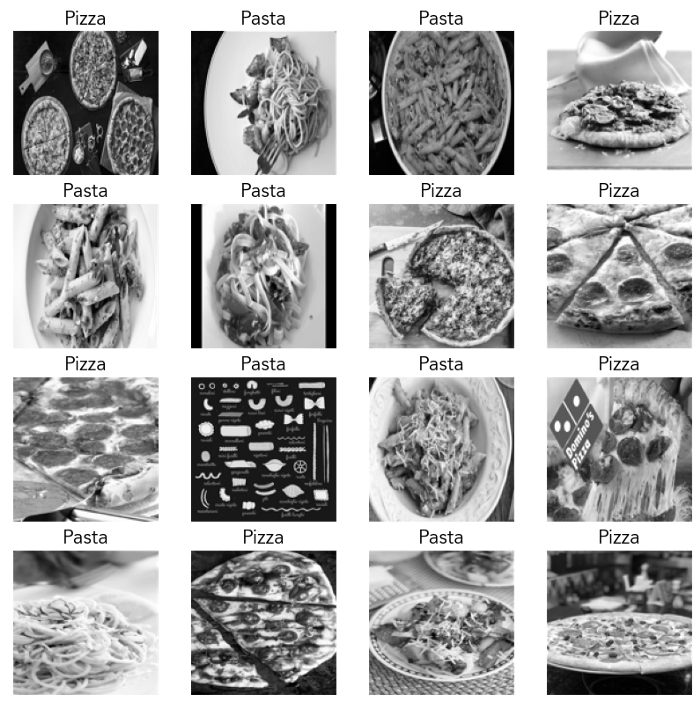
在構(gòu)建分類器之前,我們需要做的最后一件事是將所有的圖像和標簽加載到數(shù)組中,以便加載到模型中。對于我們的圖像,我們首先創(chuàng)建一個空的 numpy 數(shù)組,其長度等于訓(xùn)練集中圖像的數(shù)量。這個數(shù)組的每個元素都是一個128 x 128的矩陣,代表一幅圖像。我們也可以對我們的測試集圖像做同樣的事情。
# Create array of training imagestrain_images = np.empty([df_train.shape[0], 128, 128])for index, row in df_train.iterrows():img = process_image(row.filepath)train_images[index] = img# Create array of test imagestest_images = np.empty([df_test.shape[0], 128, 128])for index, row in df_test.iterrows():img = process_image(row.filepath)test_images[index] = img
我們可以看到一個示例圖像看起來像一個 numpy 數(shù)組:
>>> train_images[0]array([[0.12941176, 0.12156863, 0.12941176, ..., 0.10588235, 0.10588235,0.09803922],[0.09803922],[0.09803922],...,[0.0745098 ],[0.0745098 ],[0.0745098 ]])
制作訓(xùn)練標簽和測試標簽的數(shù)組更加簡單 —— 我們已經(jīng)在數(shù)據(jù)框的一列中有了值,所以我們只需將這列轉(zhuǎn)換為 numpy 數(shù)組:
# Create array of training labelstrain_labels = df_train["label"].to_numpy()# Create array of test labelstest_labels = df_test["label"].to_numpy()
我們現(xiàn)在準備構(gòu)建和訓(xùn)練我們的模型!
模型構(gòu)建與訓(xùn)練
我們將使用 keras 創(chuàng)建我們的模型,keras 是一個用于創(chuàng)建人工神經(jīng)網(wǎng)絡(luò)的高級 API。我們首先導(dǎo)入所需的軟件包:
# Import kerasimport tensorflow.keras as keras
我們的模型將由一系列層組成,我們將它們封裝在 keras.Sequential() 中。神經(jīng)網(wǎng)絡(luò)通常包括:
一個輸入層ーー將數(shù)據(jù)輸入其中
一個或多個隱藏層ーー數(shù)據(jù)流經(jīng)這些層,這些層具有激活函數(shù),以確定節(jié)點的輸入如何影響輸出
輸出層ーー讀取最終的輸出神經(jīng)元以確定分類
在我們的示例中,我們將有一個輸入層、一個隱藏層和一個輸出層。我們的模型將構(gòu)建如下:
輸入層將圖像壓平為一維(128 x 128 = 16384個輸入節(jié)點)
隱藏層有256個節(jié)點——我們將使用的激活函數(shù)是一個rectified linear unit,但你可以使用其他方法,例如sigmoid function
輸出層有2個節(jié)點(分別對應(yīng)于比薩和意大利面)ー我們將添加一個softmax function 。因此,每個節(jié)點上的值代表了我們的分類器認為圖像是披薩或意大利面的概率
# Create our modelmodel = keras.Sequential([keras.layers.Flatten(input_shape=(128, 128)),keras.layers.Dense(256, activation="relu"),keras.layers.Dense(2, activation="softmax")])
我們可以查看我們的模型:
model.summary()Model: "sequential"_________________________________________________________________Layer (type) Output Shape Param #=================================================================flatten (Flatten) (None, 16384) 0_________________________________________________________________dense (Dense) (None, 256) 4194560_________________________________________________________________dense_1 (Dense) (None, 2) 514=================================================================Total params: 4,195,074Trainable params: 4,195,074Non-trainable params: 0_________________________________________________________________
現(xiàn)在我們已經(jīng)有了網(wǎng)絡(luò)層,為了構(gòu)建我們的模型,我們還需要3樣?xùn)|西:1)優(yōu)化函數(shù),2)損失函數(shù),3)性能指標。
對于優(yōu)化函數(shù),我們將使用自適應(yīng)矩估計(ADAM) ,它在較大數(shù)據(jù)集上往往比梯度下降法更好。我們還將設(shè)置我們的優(yōu)化器的學(xué)習(xí)速率,以便在更新權(quán)重時不會出現(xiàn)大的跳躍。
對于我們的損失函數(shù),我們將使用稀疏絕對交叉熵。
我們的性能指標是準確性,即正確分類照片的比例。
# Set the learning rateopt = keras.optimizers.Adam(learning_rate=0.000005)# Compile our modelmodel.compile(optimizer=opt, loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy'])
現(xiàn)在我們可以訓(xùn)練我們的模型了!我們需要決定我們的數(shù)據(jù)集中有多少比例將用于未來的交叉驗證,以及有多少 epoch 將用于我們的訓(xùn)練。在這種情況下,我將使用20% 的驗證和運行我們的50個 epoch 的訓(xùn)練。
# Train our modelhistory = model.fit(train_images, train_labels, epochs=50, validation_split=0.2)
在我們的訓(xùn)練結(jié)束時,我們應(yīng)該看到這樣的東西:
Epoch 48/5020/20 [==============================] - 0s 10ms/step - loss: 0.4522 - accuracy: 0.9453 - val_loss: 0.4958 - val_accuracy: 0.8875Epoch 49/5020/20 [==============================] - 0s 9ms/step - loss: 0.4505 - accuracy: 0.9500 - val_loss: 0.4943 - val_accuracy: 0.8750Epoch 50/5020/20 [==============================] - 0s 9ms/step - loss: 0.4493 - accuracy: 0.9438 - val_loss: 0.4981 - val_accuracy: 0.8625
酷!我們訓(xùn)練的神經(jīng)網(wǎng)絡(luò)在我們的訓(xùn)練數(shù)據(jù)上達到了94% 的準確率,在交叉驗證上達到了86% 。通過將我們的適應(yīng)輸出設(shè)置為一個名為 history 的變量,我們可以將性能作為訓(xùn)練 epoch 的函數(shù)來繪制:
# Plot accuracyfig = plt.figure(figsize=(15,5))ax1 = fig.add_subplot(121)ax2 = fig.add_subplot(122)ax1.plot(history.history['accuracy'])ax1.plot(history.history['val_accuracy'])ax1.set_title('Model Accuracy')ax1.set_ylabel('Accuracy')ax1.set_xlabel('Epoch')ax1.legend(['train', 'val'], loc='upper left')ax2.plot(history.history['loss'])ax2.plot(history.history['val_loss'])ax2.set_title('Model Loss')ax2.set_ylabel('Loss')ax2.set_xlabel('Epoch')ax2.legend(['train', 'val'], loc='upper left')plt.show()
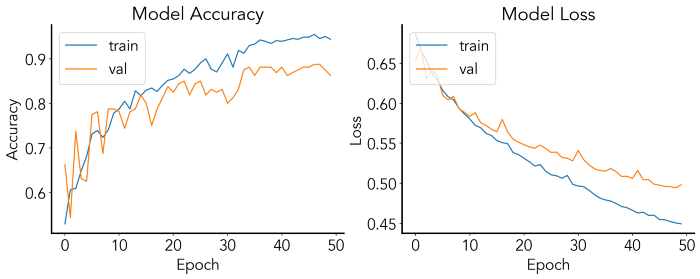
這樣的圖可以用來檢驗我們是否過度擬合(即訓(xùn)練和交叉驗證準確性和損失之間的巨大差異,在這里訓(xùn)練集是合適的)。
讓我們看看我們的模型在我們之前分割出的測試數(shù)據(jù)上的準確性:
# Evaluate training accuracymodel.evaluate(test_images, test_labels, verbose=2)7/7 - 0s - loss: 0.5233 - accuracy: 0.8250
我們的分類器在訓(xùn)練數(shù)據(jù)上有82.5% 的準確率ー現(xiàn)在讓我們在一些新的照片上嘗試我們的訓(xùn)練模型。
模型預(yù)測
現(xiàn)在讓我們用一些新的看不見的數(shù)據(jù)來測試我們的模型。首先,我們可以編寫一個封裝函數(shù),它接受模型和圖像作為 numpy 數(shù)組,并返回一個字符串,其中包含預(yù)測的類和根據(jù)模型該類的概率。
# Function to return prediction and probabilitydef model_prediction(model, img):predictions = model.predict(np.array([img]))if predictions[0][0] > predictions[0][1]:return f"Pizza: {round(100*predictions[0][0], 2)}%"else:return f"Pasta: {round(100*predictions[0][1], 2)}%"
現(xiàn)在,我們可以用我自己做飯的兩張圖片來測試這一點:一碗意大利面和一個比薩餅。
意大利面
# Load image of cacio e pepecacio_e_pepe = process_image("./cacioepepe.jpg")# Plot image along with predictionfig = plt.figure(figsize=(5, 5))ax = fig.add_subplot(111)ax.imshow(cacio_e_pepe, cmap="gray")ax.set_xticks([])ax.set_yticks([])ax.set_title(model_prediction(model, cacio_e_pepe))plt.show()

披薩
# Load image of pizzahome_pizza = process_image("./pizza.jpg")# Plot image along with predictionfig = plt.figure(figsize=(5, 5))ax = fig.add_subplot(111)ax.imshow(home_pizza, cmap="gray")ax.set_xticks([])ax.set_yticks([])ax.set_title(model_prediction(model, home_pizza))plt.show()

哇!都是正確的分類!我們現(xiàn)在有一個圖像分類器比可以區(qū)分比薩餅和面食。從這里,我們可以調(diào)整神經(jīng)網(wǎng)絡(luò)的一些層,優(yōu)化器,損失函數(shù),甚至考慮使用卷積,以提高我們模型的準確性。
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學(xué)影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~