
Hudi 原理 | 聊一聊 Apache Hudi 原理

作為這個(gè)公眾號(hào)的第二篇文章,來(lái)講講近年來(lái)比較火,并有越來(lái)越火的趨勢(shì)的存儲(chǔ)系統(tǒng)——Hudi。Hudi經(jīng)常被拿來(lái)跟Delta,Iceberg一起,并稱為“數(shù)據(jù)湖三劍客”,最近的熱度也是越來(lái)越高,被很多的大公司采用(例如字節(jié),bilibili,順豐等),相信有不少朋友也正在考慮引入Hudi,或者已經(jīng)進(jìn)入調(diào)研試用的階段。然而Hudi的概念很多,文檔寫得稍微語(yǔ)焉不詳,估計(jì)有些朋友看完文檔以后還是“有點(diǎn)懵”。這篇文章就是希望講清楚Hudi的原理,幫助大家更好地理解Hudi的工作機(jī)制和每個(gè)配置項(xiàng)的含義,然后在生產(chǎn)環(huán)境可以用好Hudi。
01
首先我會(huì)講一講Hudi的背景,因?yàn)楸尘皩?duì)理解一個(gè)項(xiàng)目很關(guān)鍵。(只想看原理的朋友,可以直接跳到第二節(jié))
Hudi,正式的全稱是Hadoop Upsert Delete and Incremental。其實(shí)關(guān)于這個(gè)名字也不用太較真,因?yàn)槎际呛髞?lái)附會(huì)上去的,從源代碼里可以看到這個(gè)項(xiàng)目最初的名字是hoodie,和現(xiàn)在的名字發(fā)音相同。但這個(gè)名字還是透露了一些信息的,那就是Hudi項(xiàng)目最初的設(shè)計(jì)目標(biāo):在hadoop上實(shí)現(xiàn)update和delete操作。
為什么會(huì)有update和delete的需求?uber在開(kāi)源Hudi的文章中解釋了:
最初uber使用的是Lambda架構(gòu),但是有個(gè)問(wèn)題是計(jì)算邏輯分為批量和實(shí)時(shí)兩種,要保持兩者的邏輯完全一致很困難(畢竟是兩套代碼)。
然后uber轉(zhuǎn)向了Kappa架構(gòu),使得兩套代碼變?yōu)橐惶祝谴鎯?chǔ)依然有兩套,分別支持實(shí)時(shí)寫入和批量寫入。
為了把存儲(chǔ)也統(tǒng)一起來(lái),減少運(yùn)維的壓力,就需要讓負(fù)責(zé)批量寫入的存儲(chǔ)系統(tǒng)也能支持實(shí)時(shí)寫入,這就產(chǎn)生了update和delete的需求。為什么呢?有多種原因,例如實(shí)時(shí)計(jì)算常有的遲到數(shù)據(jù),還有業(yè)務(wù)時(shí)效性要求以及一些合規(guī)需求(GDPR要求平臺(tái)允許用戶刪除自己的數(shù)據(jù))。而眾所眾知的是,無(wú)論是HDFS還是云平臺(tái)的對(duì)象存儲(chǔ)(例如aws的s3,阿里云的oss等),都不支持update而只能overwrite,因此要實(shí)現(xiàn)update和delete功能,就必須在底層存儲(chǔ)之上做文章。Hudi于是應(yīng)運(yùn)而生。
02
講完了背景,接下來(lái)我們會(huì)深入Hudi的實(shí)現(xiàn)部分。和上一篇文章《詳解Parquet格式》一樣,這次我同樣會(huì)循著一條主線來(lái)講解Hudi,這條主線就是Hudi的標(biāo)志性功能——Upsert。
Upsert可以說(shuō)是Hudi的招牌,正如上一節(jié)所說(shuō),Hudi最初的設(shè)計(jì)目標(biāo)就是在hadoop上實(shí)現(xiàn)數(shù)據(jù)的update。于是這里的核心問(wèn)題就是
如何在一個(gè)只能overwrite的文件系統(tǒng)上實(shí)現(xiàn)update操作?
Hudi解決了這個(gè)問(wèn)題,使用了一種很簡(jiǎn)單的思想,那就是
把一個(gè)完整的文件拆分為多個(gè)“小文件”,當(dāng)需要更新其中某條記錄時(shí),只要把包含這條記錄的“小文件”給重寫一遍即可。
到這里還沒(méi)有出現(xiàn)任何Hudi的概念,例如Copy on Write(簡(jiǎn)稱COW)或Merge on Read(簡(jiǎn)稱MOR),是不是?別急,馬上我就會(huì)拿COW表來(lái)舉例。之所以先講COW表,是因?yàn)檫@種類型的表原理更加簡(jiǎn)單,也是MOR表的基礎(chǔ)。而且Hudi最初的版本只支持COW表,可見(jiàn)這是Hudi的立項(xiàng)之本。
接下來(lái)我會(huì)用一個(gè)例子直觀地展示下COW表的upsert是如何實(shí)現(xiàn)的。
首先,假設(shè)我們向一張Hudi表中預(yù)先寫入了5行數(shù)據(jù),如下
| txn_id | user_id | item_id | amount | date |
|---|---|---|---|---|
| 1 | 1 | 1 | 2 | 20220101 |
| 2 | 2 | 1 | 1 | 20220101 |
| 3 | 1 | 2 | 3 | 20220101 |
| 4 | 1 | 3 | 1 | 20220102 |
| 5 | 2 | 3 | 2 | 20220102 |
這時(shí)在我們的hdfs里面,會(huì)有下面2個(gè)目錄,以及1個(gè)隱藏的.hoodie目錄。
warehouse├── .hoodie├── 20220101│?? └── fileId1_001.parquet└── 20220102└── fileId2_001.parquet
文件名分為兩部分,fileId是Hudi中的一個(gè)概念,后面會(huì)做解釋,001則是commitId。
畫(huà)成圖就是

可以看到,屬于20220101分區(qū)的3條數(shù)據(jù)保存在一個(gè)parquet文件:fileId1_001.parquet,屬于20220102分區(qū)的2條數(shù)據(jù)則保存在另一個(gè)parquet文件:fileId2_001.parquet。
然后我們?cè)賹懭?條新的數(shù)據(jù)。其中有2條數(shù)據(jù)是新增,1條數(shù)據(jù)是更新。寫入的數(shù)據(jù)如下
| txn_id | user_id | item_id | amount | date |
|---|---|---|---|---|
| 3 | 1 | 2 | 5 | 20220101 |
| 6 | 1 | 4 | 1 | 20220103 |
| 7 | 2 | 3 | 2 | 20220103 |
寫入完成后,hdfs里面的文件結(jié)構(gòu)會(huì)變成這樣
warehouse├──?.hoodie├── 20220101│?? ├── fileId1_001.parquet│?? └── fileId1_002.parquet├── 20220102│?? └── fileId2_001.parquet└── 20220103└── fileId3_001.parquet
注意.hoodie這個(gè)目錄,里面保存了hudi的元數(shù)據(jù)
畫(huà)成圖就是
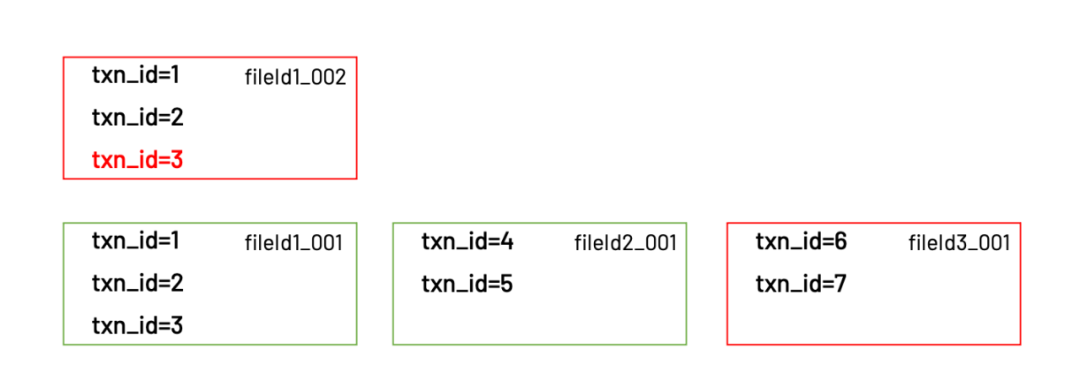
可以看到,更新的那一條記錄,實(shí)際被寫入到了同一個(gè)分區(qū)下的新文件:fileId1_002.parquet。這個(gè)新文件的fileId和上一個(gè)相同,只不過(guò)commitId變成了002。同時(shí)還有一個(gè)新文件:fileId3_001.parquet。
update到這里就算完成了,那么使用這張表的用戶又是如何讀到更新以后的數(shù)據(jù)呢?Hudi客戶端在讀取這張表時(shí),會(huì)根據(jù).hoodie目錄下保存的元數(shù)據(jù)信息,獲知需要讀取的文件是:fileId1_002.parquet,fileId2_001.parquet,fileId3_001.parquet。這些文件里保存的正是最新的數(shù)據(jù)。
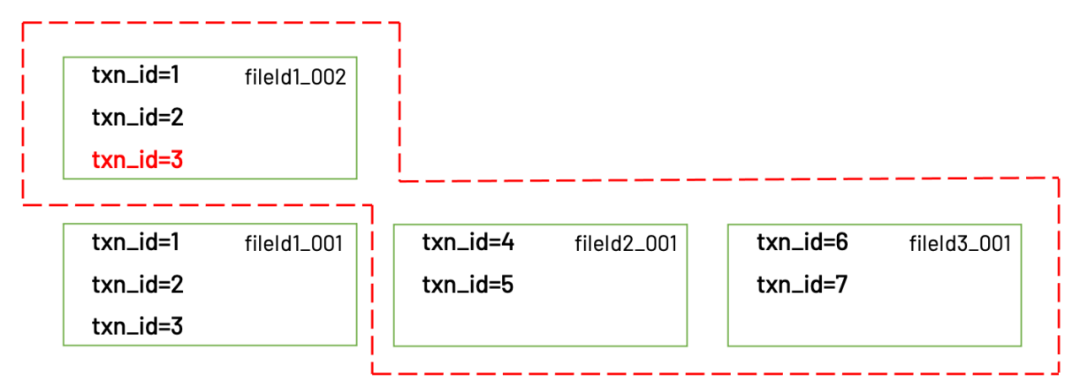
讀取的是最新的文件
以上就是Hudi實(shí)現(xiàn)update的原理。在有了相對(duì)直觀的理解之后,我們就可以進(jìn)一步深入實(shí)現(xiàn)細(xì)節(jié)了。
03
這一節(jié)會(huì)對(duì)Hudi的寫入邏輯進(jìn)行更細(xì)節(jié)的講解。首先來(lái)看下Hudi使用spark接口進(jìn)行upsert的代碼
df.write.format("hudi").option(RECORDKEY_FIELD_OPT_KEY, "txn_id").option(PARTITIONPATH_FIELD_OPT_KEY, "date").option(TABLE_NAME, tableName).mode(Overwrite).save()
注意到這里有兩個(gè)必填的配置項(xiàng):RECORDKEY_FIELD_OPT_KEY和PARTITIONPATH_FIELD_OPT_KEY,它們的含義是“作為recordKey的字段名”,“作為partitionPath的字段名”。請(qǐng)記住這兩個(gè)字段,在后面的寫入過(guò)程中有非常重要的作用。
Upsert的過(guò)程整體分為3步(這里省略了很多不太重要的步驟):
根據(jù)partitionPath進(jìn)行重新分區(qū)。
根據(jù)recordKey確定哪些記錄需要插入,哪些記錄需要更新。對(duì)于需要更新的記錄,還需要找到舊的記錄所在的文件。(這個(gè)過(guò)程被稱為tagging)
把記錄寫入實(shí)際的文件。
Step1. 重新分區(qū)
無(wú)論DataFrame在寫入前是如何分區(qū)的,Hudi都會(huì)對(duì)它們進(jìn)行重新分區(qū)。重新分區(qū)的依據(jù)就是partitionPath。partitionPath相同的record都會(huì)被分到同一個(gè)partition,并交給一個(gè)executor負(fù)責(zé)寫入。上面例子中的配置項(xiàng)PARTITIONPATH_FIELD_OPT_KEY就是用來(lái)指定record里面的哪個(gè)字段作為partitionPath。
Step2. Tagging
在確定了每個(gè)record的partition之后,接下來(lái)做的就是tagging。tagging是寫入過(guò)程中最重要的一步,核心邏輯是確定每條record是insert還是update,以及如果是update,則定位到上次寫入時(shí)的fileId。
Hudi如何確定一條record是insert還是update?是通過(guò)recordKey。用戶在寫入時(shí)需要指定每條record的recordKey,Hudi會(huì)用這個(gè)recordKey和現(xiàn)有的數(shù)據(jù)進(jìn)行比對(duì),如果找到一條key相同的record,則認(rèn)為這次新的寫入是update,否則就是insert。
對(duì)于一條update的數(shù)據(jù),也就是說(shuō)之前曾經(jīng)插入過(guò)相同key的record,那么Hudi會(huì)把舊的record的fileId取出來(lái),作為這條新record的fileId。之前一直沒(méi)有解釋fileId的含義,現(xiàn)在可以解釋下了。fileId是Hudi為每條record賦予的id,用于標(biāo)識(shí)這條record被保存在哪個(gè)文件里,或者更嚴(yán)格地說(shuō),是“哪一批文件”里。由于每次update都會(huì)生成一個(gè)新的文件,但是共享同一個(gè)fileId,所以最終會(huì)變成一批文件。Hudi把具有相同fileId的一批文件稱為file group。最后,fileId本身是一個(gè)uuid,是全局唯一的。
warehouse├──?.hoodie├── 20220101│?? ├── fileId1_001.parquet│?? └── fileId1_002.parquet├── 20220102│?? └── fileId2_001.parquet└── 20220103└── fileId3_001.parquet
文件名里包含fileId1的2個(gè)文件就是一個(gè)file group
整個(gè)tagging過(guò)程還有一個(gè)顯而易見(jiàn)的問(wèn)題,那就是tagging需要在已有的數(shù)據(jù)里尋找key相同的record,如果表的數(shù)據(jù)量比較大時(shí)會(huì)非常耗時(shí)。為了解決這個(gè)問(wèn)題,Hudi引入了index機(jī)制,下一節(jié)我會(huì)更詳細(xì)地講一講。
Step3. 寫入文件
當(dāng)tagging完成以后,就會(huì)開(kāi)始真正地寫入數(shù)據(jù)。Hudi會(huì)把需要寫入的數(shù)據(jù)分為insert和update兩部分,update的數(shù)據(jù)會(huì)用原來(lái)的fileId進(jìn)行寫入,insert的數(shù)據(jù)則會(huì)生成一個(gè)新的fileId用于寫入。值得一提的是,insert的數(shù)據(jù)也不會(huì)全部寫入到同一個(gè)文件,而是到達(dá)了一定閾值(由hoodie.parquet.max.file.size配置項(xiàng)控制)以后,關(guān)閉當(dāng)前文件,換一個(gè)新的文件繼續(xù)寫入(同時(shí)也會(huì)生成一個(gè)新的fileId)。
04
講完了Hudi的upsert過(guò)程,Hudi的基礎(chǔ)框架就已經(jīng)比較清楚了。后面的大部分工作都是在這個(gè)基礎(chǔ)上的優(yōu)化。這里試講下其中的幾個(gè)
Merge on Read
Hudi最大的特征就是表分為Copy on Write和Merge on Read兩種類型。Copy on Write的工作原理上文已經(jīng)解釋過(guò)了,Merge on Read則是對(duì)Copy on Write的優(yōu)化。優(yōu)化了什么呢?主要是寫入性能。
從上面的例子中可以看到,對(duì)于COW表,每次更新都會(huì)生成一個(gè)新的文件,里面包括了更新的數(shù)據(jù)以及屬于同一個(gè)文件但沒(méi)有被更新的老數(shù)據(jù)。所以這個(gè)文件比較大,寫入也會(huì)比較慢。
txn_id=3是更新的數(shù)據(jù),1和2沒(méi)有變化,是老數(shù)據(jù)
為了加快寫入(主要是update)的速度,Hudi引入了MOR表。和COW表最大的不同就是,MOR表在更新時(shí)只會(huì)把更新的那部分?jǐn)?shù)據(jù)寫入一個(gè).log文件,因?yàn)?log文件不包含老數(shù)據(jù),也不涉及tagging,又是順序?qū)懭氲模詫懭霑?huì)非常快。而當(dāng)客戶端要讀取數(shù)據(jù)時(shí),會(huì)有兩種選擇:
讀取時(shí)動(dòng)態(tài)地把.log文件和原始數(shù)據(jù)文件(稱為base文件)進(jìn)行merge
異步地把.log文件和base文件merge,如果merge還沒(méi)完成,只能讀到上個(gè)版本的數(shù)據(jù)
無(wú)論是哪一種辦法,都有利有弊。第一種辦法的優(yōu)點(diǎn)是數(shù)據(jù)保證最新,缺點(diǎn)是讀取的性能較差。第二種辦法的優(yōu)點(diǎn)是讀取的性能和COW表相同,缺點(diǎn)是異步merge(稱為compaction)有一定的延遲。這也就是Hudi官網(wǎng)上展示的snapshot query和read optimised query的差異來(lái)源

Index
在upsert的工作原理中,我們提到了tagging過(guò)程中需要使用index確定每一條數(shù)據(jù)之前是否已經(jīng)插入過(guò)。這個(gè)index也有很多門道,Hudi默認(rèn)提供了3種index實(shí)現(xiàn),同時(shí)允許用戶實(shí)現(xiàn)自己的index。
這3種index分別是:Bloom Index,Simple Index和HBase Index。
Bloom Index:實(shí)現(xiàn)原理是bloom filter。優(yōu)點(diǎn)是效率高,缺點(diǎn)是bloom filter固有的假陽(yáng)性問(wèn)題,所以Hudi對(duì)bloom filter里存在的key,還需要回溯原文件再查找一遍。Hudi默認(rèn)使用的是Bloom Index。
Simple Index:實(shí)現(xiàn)原理是把新數(shù)據(jù)和老數(shù)據(jù)進(jìn)行join。優(yōu)點(diǎn)是實(shí)現(xiàn)最簡(jiǎn)單,無(wú)需額外的資源。缺點(diǎn)是性能比較差。
HBase Index:實(shí)現(xiàn)原理是把index存放在HBase里面。優(yōu)點(diǎn)是性能最高,缺點(diǎn)是需要外部的系統(tǒng),增加了運(yùn)維壓力。
Index還有一個(gè)概念是global index和non-global index。這兩者有什么區(qū)別呢?global index里面存放了一張表里所有record的key,而non-global index是每個(gè)partition都有一個(gè)對(duì)應(yīng)的index,里面只存放了本partition的key。所以如果用戶使用non-global index,就必須保證同一個(gè)key的record不會(huì)出現(xiàn)在多個(gè)partition里面。看起來(lái)global index比non-global index更好,為什么還要有non-global index?主要是出于index的維護(hù)成本和寫入性能考慮。因?yàn)榫S護(hù)一個(gè)global index的難度更大,對(duì)寫入性能的影響也更大。
05
在這一篇文章里,我整體介紹了COW表的寫入原理,可以說(shuō)這是Hudi的基礎(chǔ),有助于理解Hudi的所有方面。下一篇文章,我會(huì)對(duì)MOR表的實(shí)現(xiàn)原理,以及Hudi增量寫入的原理等,再做一些介紹。