
特征工程實(shí)戰(zhàn)-20大文本特征(上)
特征工程--文本特征上半篇!
注意:
1. 本系列所有的文章主要是梯度提升樹模型展開的,抽取的特征主要為幫助梯度提升樹模型挖掘其挖掘不到的信息,本文介紹的所有特征都可以當(dāng)做特征直接加入模型,和基于神經(jīng)網(wǎng)絡(luò)的策略有些許差別;
2. 因篇幅過多,本篇文章介紹文本特征的20種不同的特征,后續(xù)的文本特征會(huì)在后面的文章中更新!
文本特征和類別特征會(huì)有一些簡(jiǎn)單的交集,一些簡(jiǎn)單的文本特征可以直接當(dāng)做類別特征處理,例如:
花的顏色:red,blue,yellow等等; 名字:Mr jack,Mr smith,Mrs will,Mr phil等等。
對(duì)這些特征可以直接進(jìn)行Label編碼然后采用類別特征的技巧對(duì)其進(jìn)行特征工程。除了把文本特征當(dāng)做類別特征處理,我們?cè)谧鑫谋鞠嚓P(guān)的特征工程時(shí),需要注意非常多的細(xì)節(jié),相較于Label編碼,就是如何防止文本內(nèi)的信息丟失問題。文本特征的處理涉及到非常多的NLP技術(shù),此處我們主要介紹一些經(jīng)常需要注意的地方以及一些技巧,關(guān)于最新的方法,大家可以跟進(jìn)最新的NLP相關(guān)技術(shù)。
針對(duì)梯度提升樹模型對(duì)文本特征進(jìn)行特征工程,我們需要充分挖掘Label編碼丟失的信息,例如上面的名字特征,內(nèi)部存在非常強(qiáng)的規(guī)律,Mr等信息,這些信息反映了性別相關(guān)的信息,如果直接進(jìn)行Label編碼就會(huì)丟失此類信息,所以我們可以通過文本技巧對(duì)其進(jìn)行挖掘。


1.expansion編碼
expansion編碼常常出現(xiàn)在一些復(fù)雜的字符串中,例如一些帶有版本信息的字符串,很多版本號(hào)的信息中涵蓋了時(shí)間以及編號(hào)等信息,我們需要將其拆分開,形成多個(gè)新的特征列,例如下面的例子:
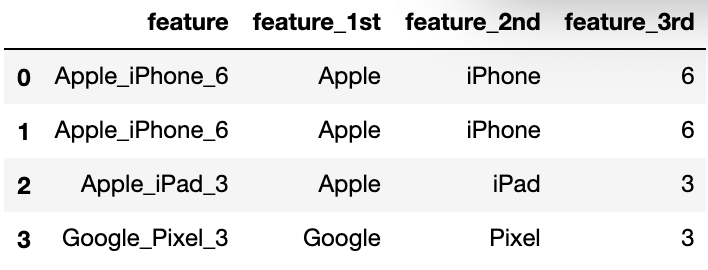
expansion編碼類似于一種帶有業(yè)務(wù)信息的聚類信息,可以加速樹模型的搜索速度,也是非常非常不錯(cuò)的特征.
import pandas as pd
df = pd.DataFrame()
df['feature'] = ['Apple_iPhone_6', 'Apple_iPhone_6', 'Apple_iPad_3', 'Google_Pixel_3']
df['feature_1st'] = df['feature'].apply(lambda x: x.split('_')[0])
df['feature_2nd'] = df['feature'].apply(lambda x: x.split('_')[1])
df['feature_3rd'] = df['feature'].apply(lambda x: x.split('_')[2])
df
| feature | feature_1st | feature_2nd | feature_3rd | |
|---|---|---|---|---|
| 0 | Apple_iPhone_6 | Apple | iPhone | 6 |
| 1 | Apple_iPhone_6 | Apple | iPhone | 6 |
| 2 | Apple_iPad_3 | Apple | iPad | 3 |
| 3 | Google_Pixel_3 | Pixel | 3 |
2.consolidation編碼
consolidation編碼常常出現(xiàn)在一些特殊的字符串中,例如:
一些帶有地址的字符串,字符串會(huì)給出詳細(xì)的信息,XX市XX縣XX村XX號(hào)等,這時(shí)我們可以將市抽取來作為一個(gè)全新的特征; 很多產(chǎn)品,例如手機(jī),pad等等,我們可以單獨(dú)抽象為蘋果,三星等公司等信息;


3.文本長(zhǎng)度特征
文本的長(zhǎng)度特征,可以按照文本的段落,句子,單詞和字母四大粒度進(jìn)行枚舉式的構(gòu)建,這些特征可以反映文本的段落結(jié)構(gòu),在很多問題中都是非常重要的信息,例如判斷文本的類型,判斷文本是小說還是論文還是其它,此時(shí)文本的長(zhǎng)度特征就是非常強(qiáng)的特征。

1.段落的個(gè)數(shù)
顧名思義就是文本中段落的個(gè)數(shù)。
2.句子的個(gè)數(shù)
文本中句子的個(gè)數(shù),可以通過計(jì)算句號(hào)感嘆號(hào)等次數(shù)來統(tǒng)計(jì)。
3.單詞的個(gè)數(shù)
文本中單詞的個(gè)數(shù),可以通過直接通過將標(biāo)點(diǎn)符號(hào)轉(zhuǎn)化為空格,然后計(jì)算空格個(gè)數(shù)的方式來計(jì)算。
4.字母?jìng)€(gè)數(shù)
刪除所有的標(biāo)點(diǎn)之后直接統(tǒng)計(jì)所有字母的個(gè)數(shù)。
5.平均每個(gè)段落的句子個(gè)數(shù)
平均每個(gè)段落的句子個(gè)數(shù) = 句子的個(gè)數(shù) / 段落的個(gè)數(shù)
6.平均每個(gè)段落的單詞個(gè)數(shù)
平均每個(gè)段落的句子個(gè)數(shù) = 單詞的個(gè)數(shù) / 段落的個(gè)數(shù)
7.平均每個(gè)段落的字母?jìng)€(gè)數(shù)
平均每個(gè)段落的句子個(gè)數(shù) = 文本字母?jìng)€(gè)數(shù) / 段落的個(gè)數(shù)
8.平均每個(gè)句子的單詞個(gè)數(shù)
平均每個(gè)句子的單詞個(gè)數(shù) = 單詞的個(gè)數(shù) / 句子的個(gè)數(shù)
9.平均每個(gè)句子的字母?jìng)€(gè)數(shù)
平均每個(gè)句子的字母?jìng)€(gè)數(shù) = 文本字母?jìng)€(gè)數(shù) / 句子的個(gè)數(shù)
10.平均每個(gè)單詞的長(zhǎng)度
平均每個(gè)單詞的長(zhǎng)度 = 文本字母?jìng)€(gè)數(shù) / 文本單詞個(gè)數(shù)
4.標(biāo)點(diǎn)符號(hào)特征
標(biāo)點(diǎn)符號(hào)也蘊(yùn)藏有非常重要的信息,例如在情感分類的問題中,感嘆號(hào)等信息往往意味著非常強(qiáng)烈的情感表達(dá),對(duì)于最終模型的預(yù)測(cè)可以帶來非常大的幫助。

1.標(biāo)點(diǎn)符號(hào)的個(gè)數(shù)
直接計(jì)算標(biāo)點(diǎn)符號(hào)出現(xiàn)的次數(shù)。
2.特殊標(biāo)點(diǎn)符號(hào)的個(gè)數(shù)
統(tǒng)計(jì)文本中一些重要的標(biāo)點(diǎn)符號(hào)出現(xiàn)的次數(shù),例如:
情感分類問題中,感嘆號(hào)出現(xiàn)的次數(shù),問號(hào)出現(xiàn)的次數(shù)等。 在病毒預(yù)測(cè)問題中,異常符號(hào)出現(xiàn)的次數(shù)。
3.其它
此處需要額外注意一點(diǎn),就是一些奇異的標(biāo)點(diǎn)符號(hào),例如連續(xù)多個(gè)感嘆號(hào),"!!!"或者連續(xù)多個(gè)問號(hào)“???”,這種符號(hào)的情感表示更為強(qiáng)烈,所以很多時(shí)候也需要特別注意。
5.詞匯屬性特征
每個(gè)詞都有其所屬的屬性,例如是名詞,動(dòng)詞,還是形容詞等等。詞匯屬性特征很多時(shí)候能幫助模型帶來效果上的微弱提升,可以作為一類補(bǔ)充信息。

6.特殊詞匯特征
標(biāo)點(diǎn)符號(hào)能從側(cè)面反映文本的情感強(qiáng)烈程度等信息,在情感分類,文本分類中有很重要的作用,當(dāng)然與此同時(shí),特殊詞匯的特征特征則更為重要。
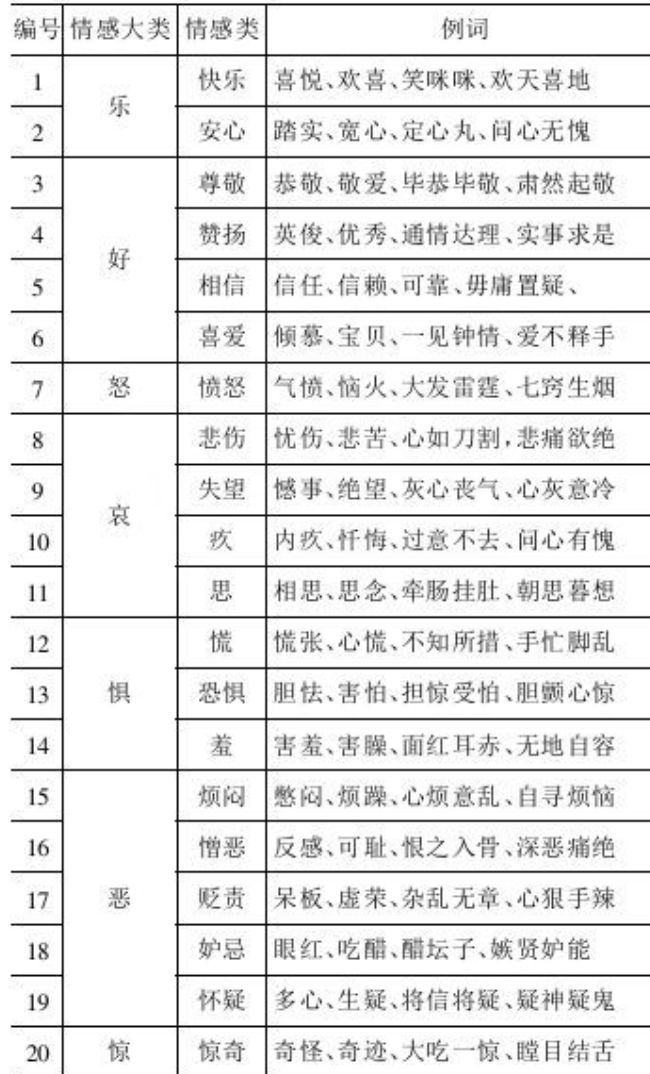
我們可以選擇直接分類別(每一類情感表示一類)統(tǒng)計(jì)每個(gè)類別中詞匯的出現(xiàn)次數(shù)。
7.詞頻特征
上面是一些簡(jiǎn)單的文本特征,還有一些文本信息會(huì)相對(duì)復(fù)雜一些,例如是句子等文本。這個(gè)時(shí)候我們就需要一些常用的文本工具了,而最為常見的就是詞頻統(tǒng)計(jì)特征,該特征較為簡(jiǎn)單,就是統(tǒng)計(jì)文本中每個(gè)詞出現(xiàn)的次數(shù),因?yàn)槊總€(gè)文本一般都是由單詞所組成的,而每個(gè)單詞出現(xiàn)的次數(shù)在一定程度上又可以從側(cè)面反映該文章的內(nèi)容,例如在謀篇文章中,"love"這個(gè)詞出現(xiàn)的比較多,也就是說"love"對(duì)應(yīng)的詞頻比較大,則我們可以猜測(cè)該文章很大可能屬于情感類的文章。所以在處理文本類的信息時(shí),詞頻特征是非常重要的信息之一。
# 導(dǎo)入工具包
from sklearn.feature_extraction.text import CountVectorizer
# 初始化,并引入停止詞匯
vectorizer = CountVectorizer(stop_words=set(['the', 'six', 'less', 'being', 'indeed', 'over', 'move', 'anyway', 'four', 'not', 'own', 'through', 'yourselves']))
df = pd.DataFrame()
df['text'] = ["The sky is blue.", "The sun is bright.","The sun in the sky is bright.", "We can see the shining sun, the bright sun."]
# 獲取詞匯
vectorizer.fit_transform(df['text']).todense()
matrix([[1, 0, 0, 0, 1, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 1, 0, 0, 0, 1, 0],
[0, 1, 0, 1, 1, 0, 0, 1, 1, 0],
[0, 1, 1, 0, 0, 1, 1, 0, 2, 1]])
如果希望知道上面每一列的意思,可以直接觀測(cè)文本的字典即可。
vectorizer.vocabulary_
{'sky': 7,
'is': 4,
'blue': 0,
'sun': 8,
'bright': 1,
'in': 3,
'we': 9,
'can': 2,
'see': 5,
'shining': 6}
詞頻特征簡(jiǎn)單易于理解,能夠從宏觀的角度捕獲文本的信息。相較于直接Label編碼可以能提取更多有用的信息特征,從而帶來效果上的提升,但是詞頻特征往往會(huì)受到停止詞匯的影響(stop words),例如"the,a"出現(xiàn)次數(shù)往往較多,這在聚類的時(shí)候如果選用了錯(cuò)誤的聚類距離,例如l2距離等,則往往難以獲得較好的聚類效果,所以需要細(xì)心的進(jìn)行停止詞匯的刪選;受文本大小的影響,如果文章比較長(zhǎng),則詞匯較多,文本較短,詞匯則會(huì)較少等問題。
8.TF-IDF特征
TF-IDF特征是詞頻特征的一個(gè)擴(kuò)展延伸,詞頻特征可以從宏觀的方面表示文本的信息,但在詞頻方法因?yàn)閷㈩l繁的詞匯的作用放大了,例如常見的"I",'the"等;將稀有的詞匯,例如"garden","tiger"的作用縮減了,而這些單詞卻有著極為重要的信息量,所以詞頻特征往往很難捕獲一些出現(xiàn)次數(shù)較少但是又非常有效的信息。而TF-IDF特征可以很好地緩解此類問題的方法。TF-IDF從全局(所有文件)和局部(單個(gè)文件)的角度來解決上述問題,TF-IDF可以更好地給出某個(gè)單詞對(duì)于某個(gè)文件的重要性。
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_model = TfidfVectorizer()
# 獲取詞匯
tfidf_matrix = tfidf_model.fit_transform(df['text']).todense()
tfidf_matrix
matrix([[0.65919112, 0. , 0. , 0. , 0.42075315,
0. , 0. , 0.51971385, 0. , 0.34399327,
0. ],
[0. , 0.52210862, 0. , 0. , 0.52210862,
0. , 0. , 0. , 0.52210862, 0.42685801,
0. ],
[0. , 0.3218464 , 0. , 0.50423458, 0.3218464 ,
0. , 0. , 0.39754433, 0.3218464 , 0.52626104,
0. ],
[0. , 0.23910199, 0.37459947, 0. , 0. ,
0.37459947, 0.37459947, 0. , 0.47820398, 0.39096309,
0.37459947]])
如果希望知道上面每一列的意思,可以直接觀測(cè)文本的字典即可。
tfidf_model.vocabulary_
{'the': 9,
'sky': 7,
'is': 4,
'blue': 0,
'sun': 8,
'bright': 1,
'in': 3,
'we': 10,
'can': 2,
'see': 5,
'shining': 6}
tfidf_model.idf_
array([1.91629073, 1.22314355, 1.91629073, 1.91629073, 1.22314355,
1.91629073, 1.91629073, 1.51082562, 1.22314355, 1. ,
1.91629073])
TDIDF忽略了文章的內(nèi)容,詞匯之間的聯(lián)系,雖然可以通過N-Gram的方式進(jìn)行緩解,但其實(shí)依然沒有從本質(zhì)上解決該問題。
9.LDA特征
基于詞頻的特征和基于TFIDF的特征都是向量形式的,因而我們可以采用基于向量抽取特征的方式對(duì)其抽取新特征,而最為典型的就是主題模型。主題模型的思想是圍繞從以主題表示的文檔語(yǔ)料庫(kù)中提取關(guān)鍵主題或概念的過程為中心。每個(gè)主題都可以表示為一個(gè)包或從文檔語(yǔ)料庫(kù)收集單詞/術(shù)語(yǔ)。這些術(shù)語(yǔ)共同表示特定的主題、主題或概念,每個(gè)主題都可以通過這些術(shù)語(yǔ)所傳達(dá)的語(yǔ)義意義與其他主題進(jìn)行區(qū)分。這些概念可以從簡(jiǎn)單的事實(shí)和陳述到觀點(diǎn)和觀點(diǎn)。主題模型在總結(jié)大量文本文檔來提取和描述關(guān)鍵概念方面非常有用。它們還可以從捕獲數(shù)據(jù)中潛在模式的文本數(shù)據(jù)中提取特征。
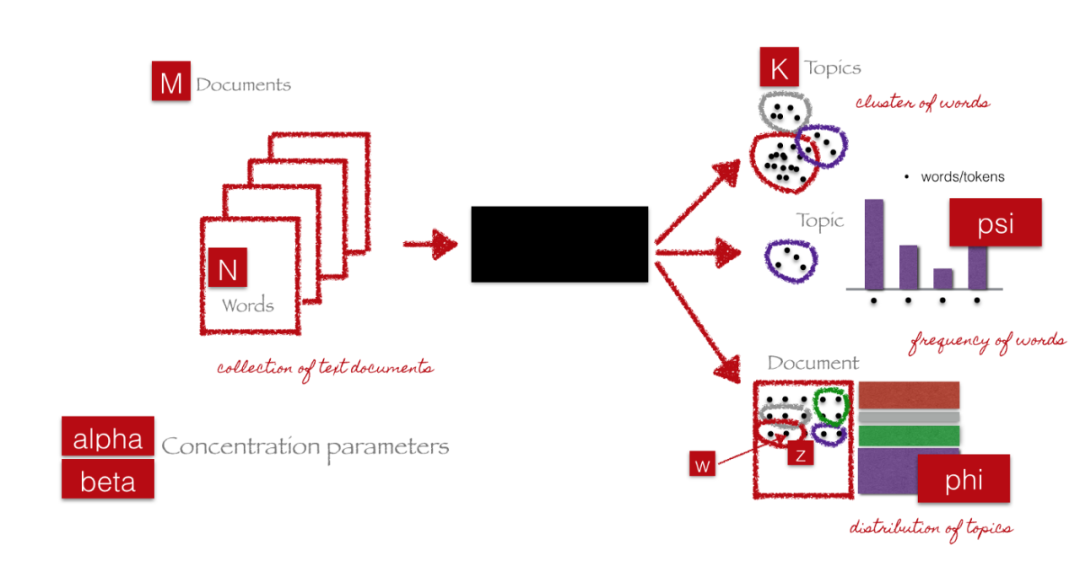
因?yàn)橹黝}模型涉及的數(shù)學(xué)等概念較多,此處我們僅僅介紹其使用方案,有興趣的朋友可以去閱讀論文等資料。
一般我們會(huì)在TF-IDF或者詞頻等矩陣上使用LDA,最終我們得到的結(jié)果也可以拆解為下面兩個(gè)核心部分:
document-topic矩陣,這將是我們需要的特征矩陣你在找什么。 一個(gè)topic-term矩陣,它幫助我們查看語(yǔ)料庫(kù)中的潛在主題。
此處我們使用上面的TDIDF矩陣并設(shè)置主題為2個(gè)進(jìn)行試驗(yàn)。
from sklearn.decomposition import LatentDirichletAllocation
lda = LatentDirichletAllocation(n_components=2, max_iter=10000, random_state=0)
dt_matrix = lda.fit_transform(tfidf_matrix)
features = pd.DataFrame(dt_matrix, columns=['T1', 'T2'])
features
| T1 | T2 | |
|---|---|---|
| 0 | 0.798663 | 0.201337 |
| 1 | 0.813139 | 0.186861 |
| 2 | 0.827378 | 0.172622 |
| 3 | 0.797794 | 0.202206 |
查看主題以及對(duì)應(yīng)的每個(gè)詞的貢獻(xiàn)。
tt_matrix = lda.components_
vocab = tfidf_model.get_feature_names()
for topic_weights in tt_matrix:
topic = [(token, weight) for token, weight in zip(vocab, topic_weights)]
topic = sorted(topic, key=lambda x: -x[1])
topic = [item for item in topic if item[1] > 0.2]
print(topic)
print()
[('the', 2.1446092537000254), ('sun', 1.7781565358915534), ('is', 1.7250615399950295), ('bright', 1.5425619519080085), ('sky', 1.3771748032988098), ('blue', 1.116020185537514), ('in', 0.9734645258594571), ('can', 0.828463031801155), ('see', 0.828463031801155), ('shining', 0.828463031801155), ('we', 0.828463031801155)]
[('can', 0.5461364394229279), ('see', 0.5461364394229279), ('shining', 0.5461364394229279), ('we', 0.5461364394229279), ('sun', 0.5440024650128295), ('the', 0.5434661558382532), ('blue', 0.5431709323301609), ('bright', 0.5404950589213404), ('sky', 0.5400833776748659), ('is', 0.539646632403921), ('in', 0.5307700509960934)]
推薦閱讀:
Python中的高效迭代庫(kù)itertools,排列組合隨便求
萬(wàn)字長(zhǎng)文詳解|Python庫(kù)collections,讓你擊敗99%的Pythoner
Python初學(xué)者必須吃透這69個(gè)內(nèi)置函數(shù)!
全面理解Python集合,17個(gè)方法全解,看完就夠了