
5分鐘完全掌握正則表達式

前言
如果說什么是我學(xué)習(xí)編程來最好用,最常用的知識點,那應(yīng)該就是正則表達式了。嚴(yán)謹(jǐn)?shù)恼f,正則表達式并不是一門編程語言,也不是為了一種編程語言而服務(wù)的知識。但他確實足夠好用,應(yīng)用也足夠廣泛。
例如可以在文本中提取規(guī)則的電話號碼,電子郵箱。在office中的通配符也是正則表達式哦,這樣在office中做規(guī)則的搜索和替換,也是能極高的提升工作效率。
正則表達式在爬蟲中也經(jīng)常使用到,例如只需要簡單的幾行代碼,就可以獲取h1標(biāo)簽下的所有內(nèi)容。
import?re
html?=?'''
?test1?
?test2?
?test3?
'''
content?=?re.findall('(.*?)
',?html)
print(content)
#result?['?test1?',?'?test2?',?'?test3?']
那正則表達式到底是什么,又該如何使用,為什么我們爬蟲中老是使用(.*?),它到底起到了什么作用,這篇文章就詳細(xì)告訴你。
什么是正則表達式
正則表達式(regular expression)描述了一種字符串匹配的模式(pattern),聽起來確實不是很好理解。
我們從這個定義中抽出三個關(guān)鍵詞:
字符串:這個定義了使用的對象,也就是文本。 匹配:定義了用途,用于查找定位。 模式:模式其實就是規(guī)則,這就是正則表達式的核心,這里的規(guī)則是人為定義好的,可以是字符,數(shù)字和字母。
所以用大白話來說,正則表達式就是一些人為定義的規(guī)則,進行組合,使其具有快速匹配字符串的功能。
元字符
前面說到正則表達式就是一些定義好的規(guī)則的組合,這個規(guī)則背后就是元字符。
元字符有很多,我們按用途將他們分為5類,便于理解和使用。
集合:[ ] 次數(shù):表示次數(shù):* + ? {} 并列:| 提取:() 特定意義符號:. ^ $ \b\B
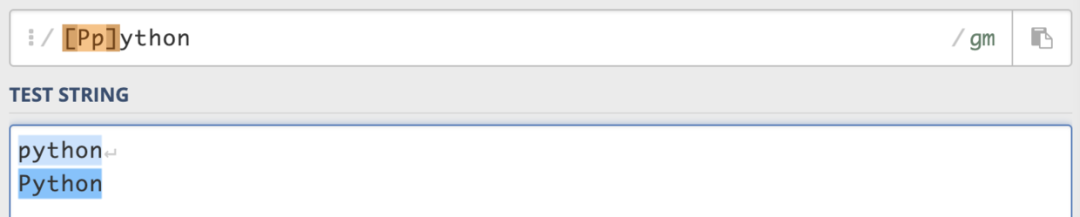
本篇文章的實例都在該網(wǎng)站上在線驗證:https://regex101.com/ (1)集合([ ]) [ ]表示匹配所包含的任意一個字符,例如[Pp]ython,就能匹配Python和python。
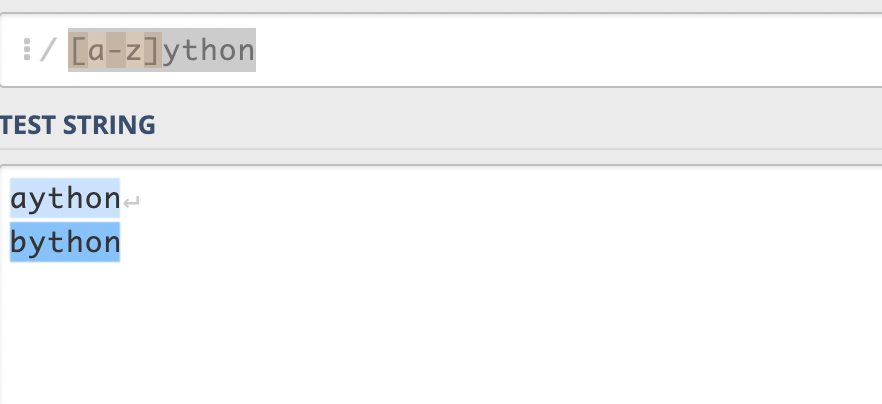
在集合中使用-,可以匹配一個范圍內(nèi)的字符,例如[a-z]可以匹配a到z任意一個字符。
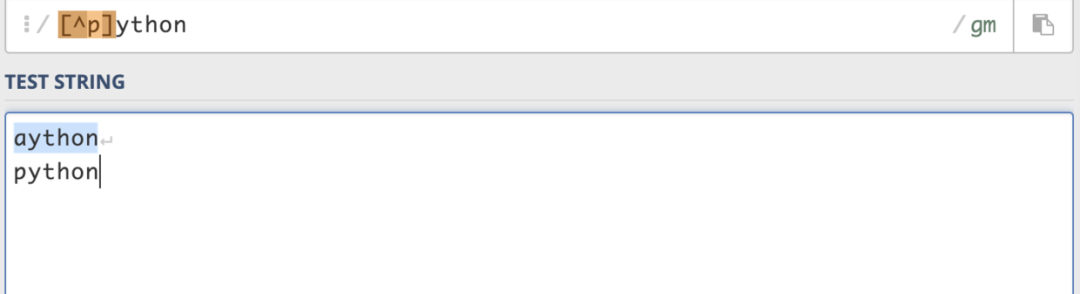
使用 ^ 可以匹配補集,例如[^p]ython,就能匹配除了p之外的字符。
(2)次數(shù)字符 上面的正則表達式只能匹配一個字符,這時你就需要次數(shù)相關(guān)的字符。
* 表示后面可跟 0 個或多個字符 + 表示后面可跟 1 個或多個字符 ? 表示后面可跟 0 個或 1 個字符 {n,m}表示后面可跟n到m個字符
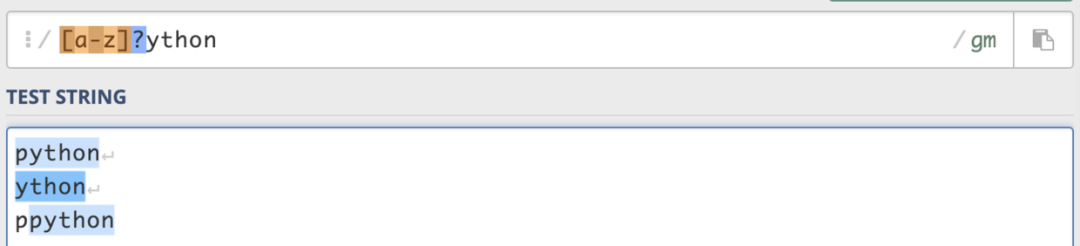
例如,匹配11個字符的電話號碼。
這個使用方法很簡單,大家多練習(xí)使用即可。但這里有一個很重要的知識點需要和大家講解下。那就是貪婪模式和非貪婪模式。
以*為例,它可以匹配0個或多個字符,那到底是匹配多少個字符了?貪婪模式就是保證匹配成功的情況下,盡可能多的匹配,非貪婪模式則反之。默認(rèn)情況下是貪婪模式,如果需要切換為非貪婪模式,就需要在*后面加上?號。
以
test
為例,如果我們使用<.*>,就會匹配到test
(.是匹配除換行符之外的任何單個字符)。
如果使用<.*?>,就會匹配到
和
。
(3)并列(|) 并列字符很好理解,當(dāng)需要匹配兩個字符中的一個的時候,就用|。A|B,匹配到了A,就不會查找B。
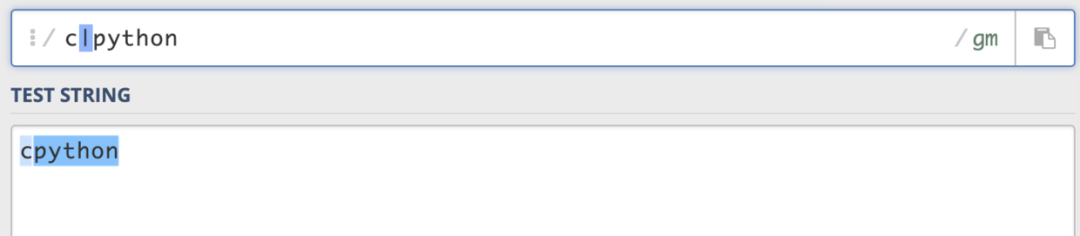
這里就是匹配到的就是c或者是python。
(4)提取() 如果需要把匹配的字符串提取出來,就需要使用小括號。這主要使用在編程中,對數(shù)據(jù)的提取。正如前面的爬蟲代碼,用上括號后,就能將h1標(biāo)簽中的內(nèi)容提取出來。
import?re
html?=?'''
?test1?
?test2?
?test3?
'''
content?=?re.findall('(.*?)
',?html)
print(content)
#result?['?test1?',?'?test2?',?'?test3?']
在 () 中最前面加入 ?:,代表只匹配不獲取(non-capturing)。
import?re
html?=?'''
?test1?
?test2?
?test3?
'''
content?=?re.findall('(?:.*?)
',?html)
print(content)
#result?['?test1?
',?'?test2?
',?'?test3?
']
其實這里的?:是是非捕獲元之一,還有兩個非捕獲元是 ?= 和 ?!,前者為正向預(yù)查,后者為負(fù)向預(yù)查。這兩個又衍生出?<=和?
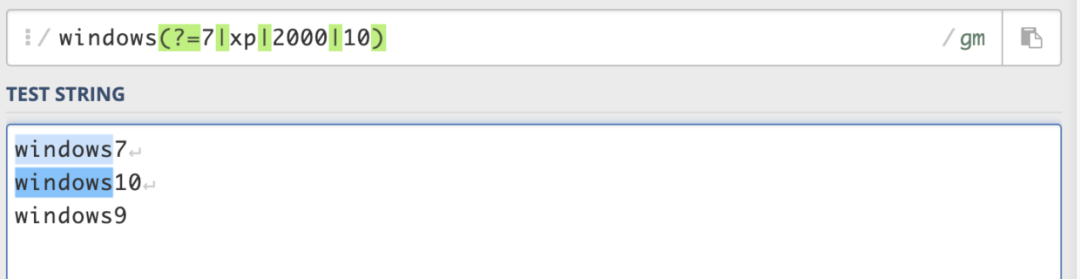
A(?=B),匹配符合B條件的A;(?<=B)A,匹配符合B條件的A。前者是匹配的是括號前面的,后者匹配的是后面的。
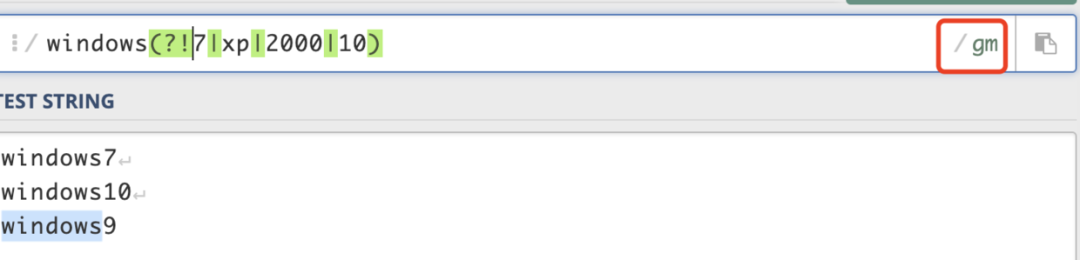
windows(?=7|xp|2000|10),能匹配windows7,windowsxp,windows2000,windows10前的windows。
A(?!B),匹配不符合B條件的A;(?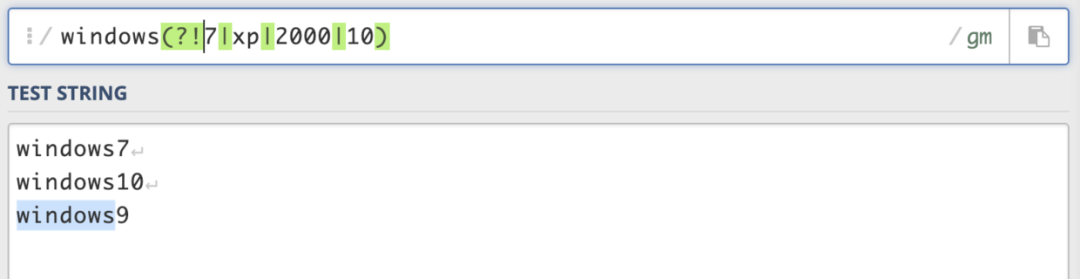
(5)特定意義符號 就是說固定的寫法來代表特定的意義,例如\d代表的就是匹配一個數(shù)字字符,等同于[0-9]。
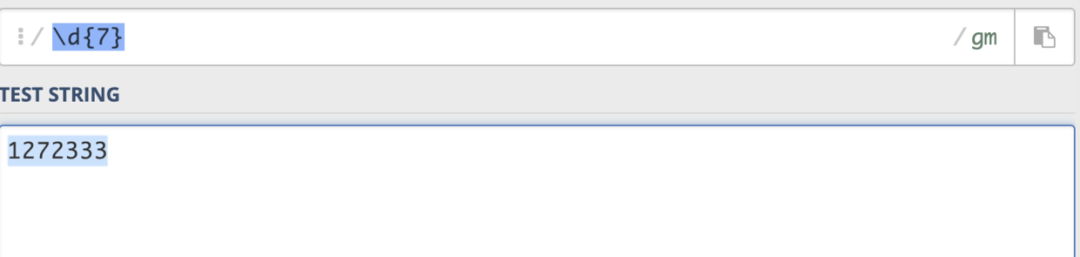
以下就是常用的特定意義符號:
| 字符串 | 含義 |
|---|---|
| ^ | 匹配輸入字符串的開始位置。 |
| $ | 匹配輸入字符串的結(jié)束位置。 |
| . | 匹配除換行符(\n、\r)之外的任何單個字符。 |
| \b | 匹配一個單詞邊界,也就是指單詞和空格間的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非單詞邊界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \d | 匹配一個數(shù)字字符。等價于 [0-9]。 |
| \D | 匹配一個非數(shù)字字符。等價于 [^0-9]。 |
| \f | 匹配一個換頁符。 |
| \n | 匹配一個換行符 |
| \r | 匹配一個回車符。 |
| \t | 匹配一個制表符。 |
| \v | 匹配一個垂直制表符。 |
| \s | 匹配任何空白字符,包括空格、制表符、換頁符等等。等價于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等價于 [^ \f\n\r\t\v]。 |
| \w | 匹配字母、數(shù)字、下劃線。等價于'[A-Za-z0-9_]'。 |
| \W | 匹配非字母、數(shù)字、下劃線。等價于 '[^A-Za-z0-9_]'。 |
\為轉(zhuǎn)義字符,例如\*,就可以匹配*本身。
修飾符(可選標(biāo)記)
學(xué)完前面的元字符后,就算是完成了大部分正則表達式的知識點了,也能獨立使用正則表達式來完成日常工作了。之前的截圖中,可以看到gm,他們其實是修飾符。
修飾符不寫在正則表達式里,標(biāo)記位于表達式之外,我們來看下他們代表的意義。
| 修飾符 | 含義 | 具體解釋 |
|---|---|---|
| i | ignore | 匹配時不區(qū)分大寫小 |
| g | global | 全局匹配,查找所有的匹配項。 |
| m | multi line | 多行匹配,使邊界字符 ^ 和 $ 匹配每一行的開頭和結(jié)尾。 |
| s | 特殊字符圓點 . 中包含換行符 \n | 默認(rèn)情況下的圓點 . 是 匹配除換行符 \n 之外的任何字符,加上 s 修飾符之后, . 中包含換行符 \n。 |
這期分享都到這了,下期我們講正則表達式在日常工作中的使用案例。
更多閱讀
特別推薦

點擊下方閱讀原文加入社區(qū)會員