
TPC奪命連環(huán)23問!
本文公眾號(hào)來源:yes的練級(jí)攻略 作者:是Yes呀 本文已收錄至我的GitHub
在進(jìn)入今天主題之前我先拋幾個(gè)問題,這篇文章一共提出 23 個(gè)問題。
TCP 握手一定是三次?TCP 揮手一定是四次?
為什么要有快速重傳,超時(shí)重傳不夠用?為什么要有 SACK,為什么要有 D-SACK?
都知道有滑動(dòng)窗口,那由于接收方的太忙了滑動(dòng)窗口降為了 0 怎么辦?發(fā)送方就永遠(yuǎn)等著了?
Silly Window 又是什么?
為什么有滑動(dòng)窗口流控還需要擁塞控制?
快速重傳一定要依賴三次重復(fù) ACK ?
這篇文章我想由淺到深地過一遍 TCP,不是生硬的搬出各個(gè)知識(shí)點(diǎn),從問題入手,然后從發(fā)展、演進(jìn)的角度來看 TCP。
起初我在學(xué)計(jì)算機(jī)網(wǎng)絡(luò)的時(shí)候就有非常非常多的疑問,腦子里簡(jiǎn)直充滿了十萬個(gè)為什么,而網(wǎng)絡(luò)又非常的復(fù)雜,發(fā)展了這么多年東西真的太多了,今天我就大致的淺顯地說一說我對(duì) TCP 這些要點(diǎn)的理解。
好了,廢話不多說,開始上正菜。
TCP 是用來解決什么問題?
TCP 即 Transmission Control Protocol,可以看到是一個(gè)傳輸控制協(xié)議,重點(diǎn)就在這個(gè)控制。
控制什么?
控制可靠、按序地傳輸以及端與端之間的流量控制。夠了么?還不夠,它需要更加智能,因此還需要加個(gè)擁塞控制,需要為整體網(wǎng)絡(luò)的情況考慮。
這就是出行你我他,安全靠大家。
為什么要 TCP,IP 層實(shí)現(xiàn)控制不行么?
我們知道網(wǎng)絡(luò)是分層實(shí)現(xiàn)的,網(wǎng)絡(luò)協(xié)議的設(shè)計(jì)就是為了通信,從鏈路層到 IP 層其實(shí)就已經(jīng)可以完成通信了。
你看鏈路層不可或缺畢竟咱們電腦都是通過鏈路相互連接的,然后 IP 充當(dāng)了地址的功能,所以通過 IP 咱們找到了對(duì)方就可以進(jìn)行通信了。
那加個(gè) TCP 層干啥?IP 層實(shí)現(xiàn)控制不就完事了嘛?
之所以要提取出一個(gè) TCP 層來實(shí)現(xiàn)控制是因?yàn)?IP 層涉及到的設(shè)備更多,一條數(shù)據(jù)在網(wǎng)絡(luò)上傳輸需要經(jīng)過很多設(shè)備,而設(shè)備之間需要靠 IP 來尋址。
假設(shè) IP 層實(shí)現(xiàn)了控制,那是不是涉及到的設(shè)備都需要關(guān)心很多事情?整體傳輸?shù)男适遣皇谴蟠蛘劭哿耍?/p>
我舉個(gè)例子,假如 A 要傳輸給 F 一個(gè)積木,但是無法直接傳輸?shù)剑枰?jīng)過 B、C、D、E 這幾個(gè)中轉(zhuǎn)站之手。這里有兩種情況:
假設(shè) BCDE 都需要關(guān)心這個(gè)積木搭錯(cuò)了沒,都拆開包裹仔細(xì)的看看,沒問題了再裝回去,最終到了 F 的手中。 假設(shè) BCDE 都不關(guān)心積木的情況,來啥包裹只管轉(zhuǎn)發(fā)就完事了,由最終的 F 自己來檢查這個(gè)積木答錯(cuò)了沒。
你覺得哪種效率高?明顯是第二種,轉(zhuǎn)發(fā)的設(shè)備不需要關(guān)心這些事,只管轉(zhuǎn)發(fā)就完事!
所以把控制的邏輯獨(dú)立出來成 TCP 層,讓真正的接收端來處理,這樣網(wǎng)絡(luò)整體的傳輸效率就高了。
連接到底是什么?
我們已經(jīng)知道了為什么需要獨(dú)立出 TCP 這一層,并且這一層主要是用來干嘛的,接下來就來看看它到底是怎么干的。
我們都知道 TCP 是面向連接的,那這個(gè)連接到底是個(gè)什么東西?真的是拉了一條線讓端與端之間連起來了?
所謂的連接其實(shí)只是雙方都維護(hù)了一個(gè)狀態(tài),通過每一次通信來維護(hù)狀態(tài)的變更,使得看起來好像有一條線關(guān)聯(lián)了對(duì)方。
TCP 協(xié)議頭
在具體深入之前我們需要先來看看一些 TCP 頭的格式,這很基礎(chǔ)也很重要。

我就不一一解釋了,挑重點(diǎn)的說。
首先可以看到 TCP 包只有端口,沒有 IP。
Seq 就是 Sequence Number 即序號(hào),它是用來解決亂序問題的。
ACK 就是 Acknowledgement Numer 即確認(rèn)號(hào),它是用來解決丟包情況的,告訴發(fā)送方這個(gè)包我收到啦。
標(biāo)志位就是 TCP flags 用來標(biāo)記這個(gè)包是什么類型的,用來控制 TPC 的狀態(tài)。
窗口就是滑動(dòng)窗口,Sliding Window,用來流控。
三次握手
明確了協(xié)議頭的要點(diǎn)之后,我們?cè)賮砜慈挝帐帧?/p>
三次握手真是個(gè)老生常談的問題了,但是真的懂了么?不是浮在表面?能不能延伸出一些點(diǎn)別的?
我們先來看一下熟悉的流程。
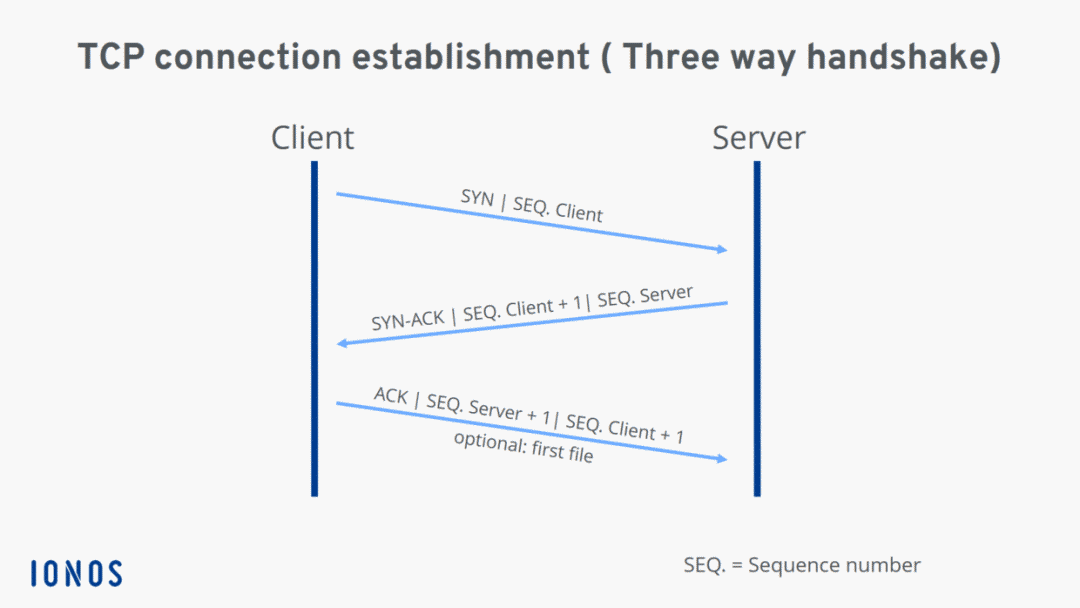
首先為什么要握手,其實(shí)主要就是為了初始化Seq Numer,SYN 的全稱是 Synchronize Sequence Numbers,這個(gè)序號(hào)是用來保證之后傳輸數(shù)據(jù)的順序性。
你要說是為了測(cè)試保證雙方發(fā)送接收功能都正常,我覺得也沒毛病,不過我認(rèn)為重點(diǎn)在于同步序號(hào)。
那為什么要三次,就拿我和你這兩個(gè)角色來說,首先我告訴你我的初始化序號(hào),你聽到了和我說你收到了。
然后你告訴我你的初始序號(hào),然后我對(duì)你說我收到了。
這好像四次了?如果真的按一來一回就是四次,但是中間一步可以合在一起,就是你和我說你知道了我的初始序號(hào)的時(shí)候同時(shí)將你的初始序號(hào)告訴我。
因此四次握手就可以減到三次了。
不過你沒有想過這么一種情形,我和你同時(shí)開口,一起告訴對(duì)方各自的初始序號(hào),然后分別回應(yīng)收到了,這不就是四次握手了?
我來畫個(gè)圖,清晰一點(diǎn)。
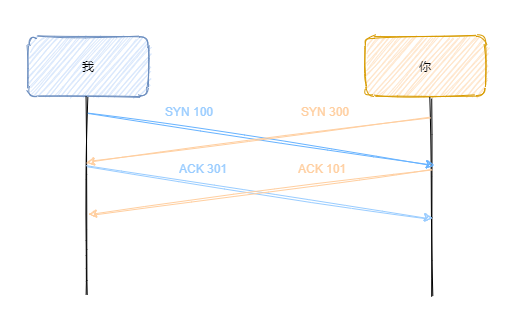
看看是不是四次握手了? 不過具體還是得看實(shí)現(xiàn),有些實(shí)現(xiàn)可能不允許這種情況出現(xiàn),但是這不影響我們思考,因?yàn)?span style="font-weight: 700;color: rgb(60, 112, 198);">握手的重點(diǎn)就是同步初始序列號(hào),這種情況也完成了同步的目標(biāo)。
初始序列號(hào) ISN 的取值
不知道大家有沒有想過 ISN 的值要設(shè)成什么?代碼寫死從零開始?
想象一下如果寫死一個(gè)值,比如 0 ,那么假設(shè)已經(jīng)建立好連接了,client 也發(fā)了很多包比如已經(jīng)第 20 個(gè)包了,然后網(wǎng)絡(luò)斷了之后 client 重新,端口號(hào)還是之前那個(gè),然后序列號(hào)又從 0 開始,此時(shí)服務(wù)端返回第 20 個(gè)包的ack,客戶端是不是傻了?
所以 RFC793 中認(rèn)為 ISN 要和一個(gè)假的時(shí)鐘綁定在一起ISN 每四微秒加一,當(dāng)超過 2 的 32 次方之后又從 0 開始,要四個(gè)半小時(shí)左右發(fā)生 ISN 回繞。
所以 ISN 變成一個(gè)遞增值,真實(shí)的實(shí)現(xiàn)還需要加一些隨機(jī)值在里面,防止被不法份子猜到 ISN。
SYN 超時(shí)了怎么處理?
也就是 client 發(fā)送 SYN 至 server 然后就掛了,此時(shí) server 發(fā)送 SYN+ACK 就一直得不到回復(fù),怎么辦?
我腦海中一想到的就是重試,但是不能連續(xù)快速重試多次,你想一下,假設(shè) client 掉線了,你總得給它點(diǎn)時(shí)間恢復(fù)吧,所以呢需要慢慢重試,階梯性重試。
在 Linux 中就是默認(rèn)重試 5 次,并且就是階梯性的重試,間隔就是1s、2s、4s、8s、16s,再第五次發(fā)出之后還得等 32s 才能知道這次重試的結(jié)果,所以說總共等63s 才能斷開連接。
SYN Flood 攻擊
你看到?jīng)] SYN 超時(shí)需要耗費(fèi)服務(wù)端 63s 的時(shí)間斷開連接,也就說 63s 內(nèi)服務(wù)端需要保持這個(gè)資源,所以不法分子就可以構(gòu)造出大量的 client 向 server 發(fā) SYN 但就是不回 server。
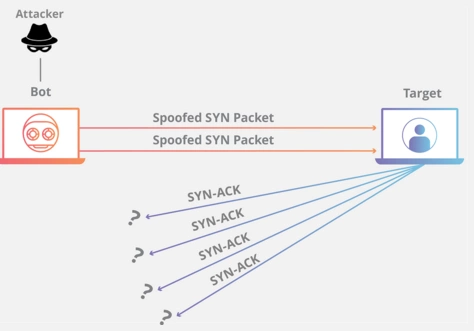
使得 server 的 SYN 隊(duì)列耗盡,無法處理正常的建連請(qǐng)求。
所以怎么辦?
可以開啟 tcp_syncookies,那就用不到 SYN 隊(duì)列了。
SYN 隊(duì)列滿了之后 TCP 根據(jù)自己的 ip、端口、然后對(duì)方的 ip、端口,對(duì)方 SYN 的序號(hào),時(shí)間戳等一波操作生成一個(gè)特殊的序號(hào)(即 cookie)發(fā)回去,如果對(duì)方是正常的 client 會(huì)把這個(gè)序號(hào)發(fā)回來,然后 server 根據(jù)這個(gè)序號(hào)建連。
或者調(diào)整 tcp_synack_retries 減少重試的次數(shù),設(shè)置 tcp_max_syn_backlog 增加 SYN 隊(duì)列數(shù),設(shè)置 tcp_abort_on_overflow SYN 隊(duì)列滿了直接拒絕連接。
為什么要四次揮手?
四次揮手和三次握手成雙成對(duì),同樣也是 TCP 中的一線明星,讓我們重溫一下熟悉的圖。
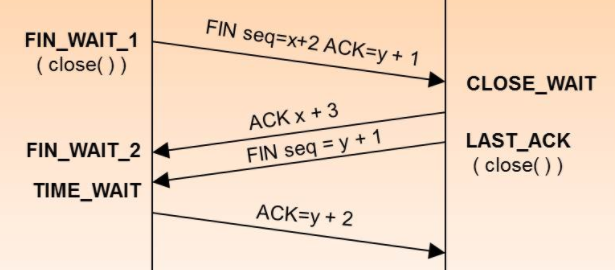
為什么揮手需要四次?因?yàn)?TCP 是全雙工協(xié)議,也就是說雙方都要關(guān)閉,每一方都向?qū)Ψ桨l(fā)送 FIN 和回應(yīng) ACK。
就像我對(duì)你說我數(shù)據(jù)發(fā)完了,然后你回復(fù)好的你收到了。然后你對(duì)我說你數(shù)據(jù)發(fā)完了,然后我向你回復(fù)我收到了。
所以看起來就是四次。
從圖中可以看到主動(dòng)關(guān)閉方的狀態(tài)是 FIN_WAIT_1 到 FIN_WAIT_2 然后再到 TIME_WAIT,而被動(dòng)關(guān)閉方是 CLOSE_WAIT 到 LAST_ACK。
四次揮手狀態(tài)一定是這樣變遷的嗎
狀態(tài)一定是這樣變遷的嗎?讓我們?cè)賮砜磦€(gè)圖。
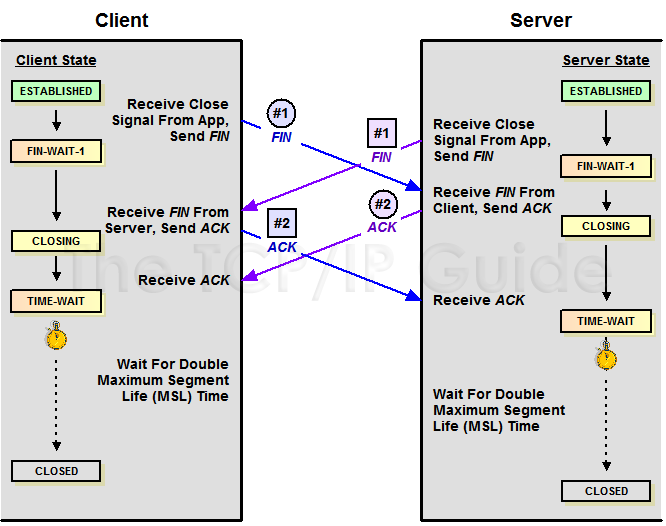
可以看到雙方都主動(dòng)發(fā)起斷開請(qǐng)求所以各自都是主動(dòng)發(fā)起方,狀態(tài)會(huì)從 FIN_WAIT_1 都進(jìn)入到 CLOSING 這個(gè)過度狀態(tài)然后再到 TIME_WAIT。
揮手一定需要四次嗎?
假設(shè) client 已經(jīng)沒有數(shù)據(jù)發(fā)送給 server 了,所以它發(fā)送 FIN 給 server 表明自己數(shù)據(jù)發(fā)完了,不再發(fā)了,如果這時(shí)候 server 還是有數(shù)據(jù)要發(fā)送給 client 那么它就是先回復(fù) ack ,然后繼續(xù)發(fā)送數(shù)據(jù)。
等 server 數(shù)據(jù)發(fā)送完了之后再向 client 發(fā)送 FIN 表明它也發(fā)完了,然后等 client 的 ACK 這種情況下就會(huì)有四次揮手。
那么假設(shè) client 發(fā)送 FIN 給 server 的時(shí)候 server 也沒數(shù)據(jù)給 client,那么 server 就可以將 ACK 和它的 FIN 一起發(fā)給client ,然后等待 client 的 ACK,這樣不就三次揮手了?
為什么要有 TIME_WAIT?
斷開連接發(fā)起方在接受到接受方的 FIN 并回復(fù) ACK 之后并沒有直接進(jìn)入 CLOSED 狀態(tài),而是進(jìn)行了一波等待,等待時(shí)間為 2MSL。
MSL 是 Maximum Segment Lifetime,即報(bào)文最長(zhǎng)生存時(shí)間,RFC 793 定義的 MSL 時(shí)間是 2 分鐘,Linux 實(shí)際實(shí)現(xiàn)是 30s,那么 2MSL 是一分鐘。
那么為什么要等 2MSL 呢?
就是怕被動(dòng)關(guān)閉方?jīng)]有收到最后的 ACK,如果被動(dòng)方由于網(wǎng)絡(luò)原因沒有到,那么它會(huì)再次發(fā)送 FIN, 此時(shí)如果主動(dòng)關(guān)閉方已經(jīng) CLOSED 那就傻了,因此等一會(huì)兒。
假設(shè)立馬斷開連接,但是又重用了這個(gè)連接,就是五元組完全一致,并且序號(hào)還在合適的范圍內(nèi),雖然概率很低但理論上也有可能,那么新的連接會(huì)被已關(guān)閉連接鏈路上的一些殘留數(shù)據(jù)干擾,因此給予一定的時(shí)間來處理一些殘留數(shù)據(jù)。
等待 2MSL 會(huì)產(chǎn)生什么問題?
如果服務(wù)器主動(dòng)關(guān)閉大量的連接,那么會(huì)出現(xiàn)大量的資源占用,需要等到 2MSL 才會(huì)釋放資源。
如果是客戶端主動(dòng)關(guān)閉大量的連接,那么在 2MSL 里面那些端口都是被占用的,端口只有 65535 個(gè),如果端口耗盡了就無法發(fā)起送的連接了,不過我覺得這個(gè)概率很低,這么多端口你這是要建立多少個(gè)連接?
如何解決 2MSL 產(chǎn)生的問題?
快速回收,即不等 2MSL 就回收, Linux 的參數(shù)是 tcp_tw_recycle,還有 tcp_timestamps 不過默認(rèn)是打開的。
其實(shí)上面我們已經(jīng)分析過為什么需要等 2MSL,所以如果等待時(shí)間果斷就是出現(xiàn)上面說的那些問題。
所以不建議開啟,而且 Linux 4.12 版本后已經(jīng)咔擦了這個(gè)參數(shù)了。
前不久剛有位朋友在群里就提到了這玩意。

一問果然有 NAT 的身影。
現(xiàn)象就是請(qǐng)求端請(qǐng)求服務(wù)器的靜態(tài)資源偶爾會(huì)出現(xiàn) 20-60 秒左右才會(huì)有響應(yīng)的情況,從抓包看請(qǐng)求端連續(xù)三個(gè) SYN 都沒有回應(yīng)。
比如你在學(xué)校,對(duì)外可能就一個(gè)公網(wǎng) IP,然后開啟了 tcp_tw_recycle(tcp_timestamps 也是打開的情況下),在 60 秒內(nèi)對(duì)于同源 IP 的連接請(qǐng)求中 timestamp 必須是遞增的,不然認(rèn)為其是過期的數(shù)據(jù)包就會(huì)丟棄。
學(xué)校這么多機(jī)器,你無法保證時(shí)間戳是一致的,因此就會(huì)出問題。
所以這玩意不推薦使用。

重用,即開啟 tcp_tw_reuse 當(dāng)然也是需要 tcp_timestamps 的。
這里有個(gè)重點(diǎn),tcp_tw_reuse 是用在連接發(fā)起方的,而我們的服務(wù)端基本上是連接被動(dòng)接收方。
tcp_tw_reuse 是發(fā)起新連接的時(shí)候,可以復(fù)用超過 1s 的處于 TIME_WAIT 狀態(tài)的連接,所以它壓根沒有減少我們服務(wù)端的壓力。
它重用的是發(fā)起方處于 TIME_WAIT 的連接。
這里還有一個(gè) SO_REUSEADDR ,這玩意有人會(huì)和 tcp_tw_reuse 混為一談,首先 tcp_tw_reuse 是內(nèi)核選項(xiàng)而 SO_REUSEADDR 是用戶態(tài)選項(xiàng)。
然后 SO_REUSEADDR 主要用在你啟動(dòng)服務(wù)的時(shí)候,如果此時(shí)的端口被占用了并且這個(gè)連接處于 TIME_WAIT 狀態(tài),那么你可以重用這個(gè)端口,如果不是 TIME_WAIT,那就是給你個(gè) Address already in use。
所以這兩個(gè)玩意好像都不行,而且 tcp_tw_reuse 和tcp_tw_recycle,其實(shí)是違反 TCP 協(xié)議的,說好的等我到天荒地老,你卻偷偷放了手?

要么就是調(diào)小 MSL 的時(shí)間,不過也不太安全,要么調(diào)整 tcp_max_tw_buckets 控制 TIME_WAIT 的數(shù)量,不過默認(rèn)值已經(jīng)很大了 180000,這玩意應(yīng)該是用來對(duì)抗 DDos 攻擊的。
所以我給出的建議是服務(wù)端不要主動(dòng)關(guān)閉,把主動(dòng)關(guān)閉方放到客戶端。畢竟咱們服務(wù)器是一對(duì)很多很多服務(wù),我們的資源比較寶貴。
自己攻擊自己
還有一個(gè)很騷的解決方案,我自己瞎想的,就是自己攻擊自己。
Socket 有一個(gè)選項(xiàng)叫 IP_TRANSPARENT ,可以綁定一個(gè)非本地的地址,然后服務(wù)端把建連的 ip 和端口都記下來,比如寫入本地某個(gè)地方。
然后啟動(dòng)一個(gè)服務(wù),假如現(xiàn)在服務(wù)端資源很緊俏,那么你就定個(gè)時(shí)間,過了多久之后就將處于 TIME_WAIT 狀態(tài)的對(duì)方 ip 和端口告訴這個(gè)服務(wù)。
然后這個(gè)服務(wù)就利用 IP_TRANSPARENT 偽裝成之前的那個(gè) client 向服務(wù)端發(fā)起一個(gè)請(qǐng)求,然后服務(wù)端收到會(huì)給真的 client 一個(gè) ACK, 那 client 都關(guān)了已經(jīng),說你在搞啥子,于是回了一個(gè) RST,然后服務(wù)端就中止了這個(gè)連接。

超時(shí)重傳機(jī)制是為了解決什么問題?
前面我們提到 TCP 要提供可靠的傳輸,那么網(wǎng)絡(luò)又是不穩(wěn)定的如果傳輸?shù)陌鼘?duì)方?jīng)]收到卻又得保證可靠那么就必須重傳。
TCP 的可靠性是靠確認(rèn)號(hào)的,比如我發(fā)給你1、2、3、4這4個(gè)包,你告訴我你現(xiàn)在要 5 那說明前面四個(gè)包你都收到了,就是這么回事兒。
不過這里要注意,SeqNum 和 ACK 都是以字節(jié)數(shù)為單位的,也就是說假設(shè)你收到了1、2、4 但是 3 沒有收到你不能 ACK 5,如果你回了 5 那么發(fā)送方就以為你5之前的都收到了。
所以只能回復(fù)確認(rèn)最大連續(xù)收到包,也就是 3。
而發(fā)送方不清楚 3、4 這兩個(gè)包到底是還沒到呢還是已經(jīng)丟了,于是發(fā)送方需要等待,這等待的時(shí)間就比較講究了。
如果太心急可能 ACK 已經(jīng)在路上了,你這重傳就是浪費(fèi)資源了,如果太散漫,那么接收方急死了,這死鬼怎么還不發(fā)包來,我等的花兒都謝了。
所以這個(gè)等待超時(shí)重傳的時(shí)間很關(guān)鍵,怎么搞?聰明的小伙伴可能一下就想到了,你估摸著正常來回一趟時(shí)間是多少不就好了,我就等這么長(zhǎng)。
這就來回一趟的時(shí)間就叫 RTT,即 Round Trip Time,然后根據(jù)這個(gè)時(shí)間制定超時(shí)重傳的時(shí)間 RTO,即 Retransmission Timeout。
不過這里大概只好了 RTO 要參考下 RTT ,但是具體要怎么算?首先肯定是采樣,然后一波加權(quán)平均得到 RTO。
RFC793 定義的公式如下:
1、先采樣 RTT 2、SRTT = ( ALPHA * SRTT ) + ((1-ALPHA) * RTT) 3、RTO = min[UBOUND,max[LBOUND,(BETA*SRTT)]]
ALPHA 是一個(gè)平滑因子取值在 0.8~0.9之間,UBOUND 就是超時(shí)時(shí)間上界-1分鐘,LBOUND 是下界-1秒鐘,BETA 是一個(gè)延遲方差因子,取值在 1.3~2.0。
但是還有個(gè)問題,RTT 采樣的時(shí)間用一開始發(fā)送數(shù)據(jù)的時(shí)間到收到 ACK 的時(shí)間作為樣本值還是重傳的時(shí)間到 ACK 的時(shí)間作為樣本值?
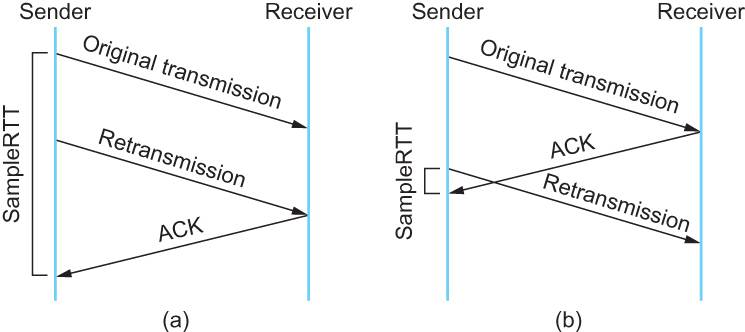
從圖中就可以看到,一個(gè)時(shí)間算長(zhǎng)了,一個(gè)時(shí)間算短了,這有點(diǎn)難,因?yàn)槟悴恢肋@個(gè) ?ACK 到底是回復(fù)誰的。
所以怎么辦?發(fā)生重傳的來回我不采樣不就好了,我不知道這次 ACK 到底是回復(fù)誰的,我就不管他,我就采樣正常的來回。
這就是 Karn / Partridge 算法,不采樣重傳的RTT。
但是不采樣重傳會(huì)有問題,比如某一時(shí)刻網(wǎng)絡(luò)突然就是很差,你要是不管重傳,那么還是按照正常的 RTT 來算 RTO, 那么超時(shí)的時(shí)間就過短了,于是在網(wǎng)絡(luò)很差的情況下還瘋狂重傳加重了網(wǎng)絡(luò)的負(fù)載。
因此 Karn 算法就很粗暴的搞了個(gè)發(fā)生重傳我就將現(xiàn)在的 RTO 翻倍,哼!就是這么簡(jiǎn)單粗暴。

但是這種平均的計(jì)算很容易把一個(gè)突然間的大波動(dòng),平滑掉,所以又搞了個(gè)算法,叫 Jacobson / Karels Algorithm。
它把最新的 RTT 和平滑過的 SRTT 做了波計(jì)算得到合適的 RTO,公式我就不貼了,反正我不懂,不懂就不嗶嗶了。
為什么還需要快速重傳機(jī)制?
超時(shí)重傳是按時(shí)間來驅(qū)動(dòng)的,如果是網(wǎng)絡(luò)狀況真的不好的情況,超時(shí)重傳沒問題,但是如果網(wǎng)絡(luò)狀況好的時(shí)候,只是恰巧丟包了,那等這么長(zhǎng)時(shí)間就沒必要。
于是又引入了數(shù)據(jù)驅(qū)動(dòng)的重傳叫快速重傳,什么意思呢?就是發(fā)送方如果連續(xù)三次收到對(duì)方相同的確認(rèn)號(hào),那么馬上重傳數(shù)據(jù)。
因?yàn)檫B續(xù)收到三次相同 ACK 證明當(dāng)前網(wǎng)絡(luò)狀況是 ok 的,那么確認(rèn)是丟包了,于是立馬重發(fā),沒必要等這么久。
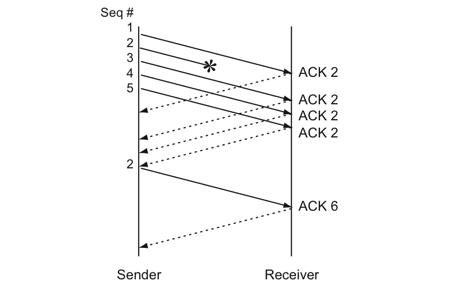
看起來好像挺完美的,但是你有沒有想過我發(fā)送1、2、3、4這4個(gè)包,就 2 對(duì)方?jīng)]收到,1、3、4都收到了,然后不管是超時(shí)重傳還是快速重傳反正對(duì)方就回 ACK 2。
這時(shí)候要重傳 2、3、4 呢還是就 2 呢?
SACK 的引入是為了解決什么問題?
SACK 即 Selective Acknowledgment,它的引入就是為了解決發(fā)送方不知道該重傳哪些數(shù)據(jù)的問題。
我們來看一下下面的圖就知道了。
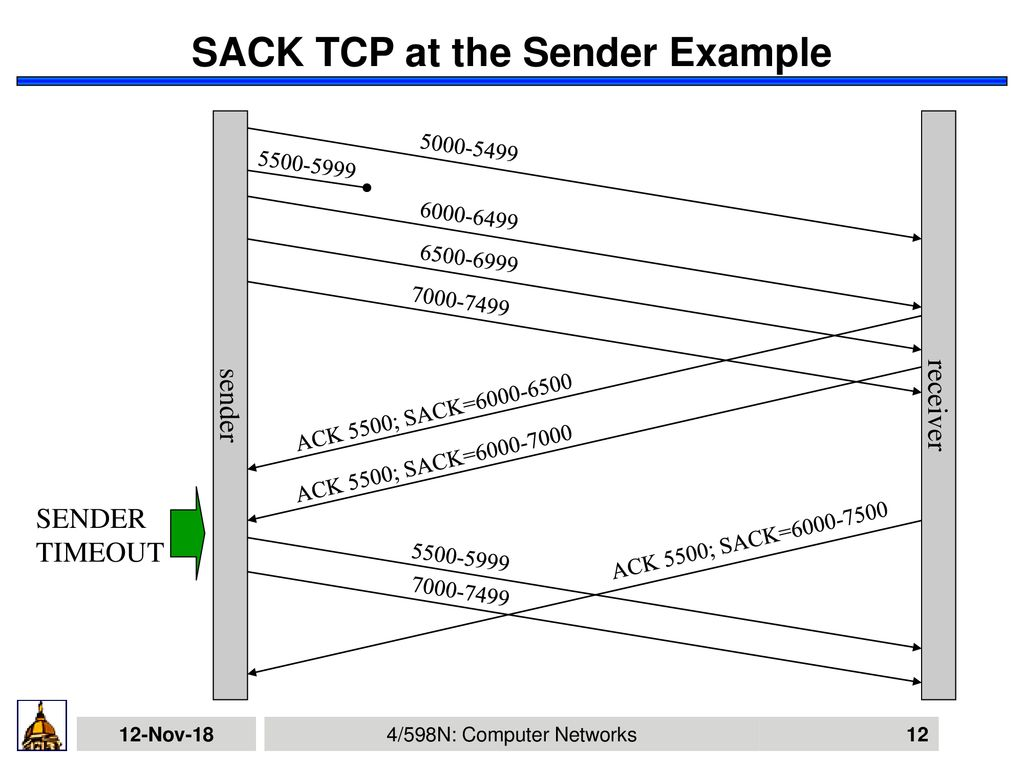
SACK 就是接收方會(huì)回傳它已經(jīng)接受到的數(shù)據(jù),這樣發(fā)送方就知道哪一些數(shù)據(jù)對(duì)方已經(jīng)收到了,所以就可以選擇性的發(fā)送丟失的數(shù)據(jù)。
如圖,通過 ACK 告知我接下來要 5500 開始的數(shù)據(jù),并一直更新 SACK,6000-6500 我收到了,6000-7000的數(shù)據(jù)我收到了,6000-7500的數(shù)據(jù)我收到了,發(fā)送方很明確的知道,5500-5999 的那一波數(shù)據(jù)應(yīng)該是丟了,于是重傳。
而且如果數(shù)據(jù)是多段不連續(xù)的, SACK 也可以發(fā)送,比如 SACK 0-500,1000-1500,2000-2500。就表明這幾段已經(jīng)收到了。
D-SACK 又是什么東西?
D-SACK 其實(shí)是 SACK 的擴(kuò)展,它利用 SACK 的第一段來描述重復(fù)接受的不連續(xù)的數(shù)據(jù)序號(hào),如果第一段描述的范圍被 ACK 覆蓋,說明重復(fù)了,比如我都 ACK 到6000了你還給我回 SACK 5000-5500 呢?
說白了就是從第一段的反饋來和已經(jīng)接受到的 ACK 比一比,參數(shù)是 tcp_dsack,Linux 2.4 之后默認(rèn)開啟。
那知道重復(fù)了有什么用呢?
1、知道重復(fù)了說明對(duì)方收到剛才那個(gè)包了,所以是回來的 ACK 包丟了。2、是不是包亂序的,先發(fā)的包后到?3、是不是自己太著急了,RTO 太小了?4、是不是被數(shù)據(jù)復(fù)制了,搶先一步呢?
滑動(dòng)窗口干嘛用?
我們已經(jīng)知道了 TCP 有序號(hào),并且還有重傳,但是這還不夠,因?yàn)槲覀儾皇倾额^青,還需要根據(jù)情況來控制一下發(fā)送速率,因?yàn)榫W(wǎng)絡(luò)是復(fù)雜多變的,有時(shí)候就會(huì)阻塞住,而有時(shí)候又很通暢。
所以發(fā)送方需要知道接收方的情況,好控制一下發(fā)送的速率,不至于蒙著頭一個(gè)勁兒的發(fā)然后接受方都接受不過來。
因此 TCP 就有個(gè)叫滑動(dòng)窗口的東西來做流量控制,也就是接收方告訴發(fā)送方我還能接受多少數(shù)據(jù),然后發(fā)送方就可以根據(jù)這個(gè)信息來進(jìn)行數(shù)據(jù)的發(fā)送。
以下是發(fā)送方維護(hù)的窗口,就是黑色圈起來的。

圖中的 #1 是已收到 ACK 的數(shù)據(jù),#2 是已經(jīng)發(fā)出去但是還沒收到 ACK 的數(shù)據(jù),#3 就是在窗口內(nèi)可以發(fā)送但是還沒發(fā)送的數(shù)據(jù)。#4 就是還不能發(fā)送的數(shù)據(jù)。
然后此時(shí)收到了 36 的 ACK,并且發(fā)出了 46-51 的字節(jié),于是窗口向右滑動(dòng)了。
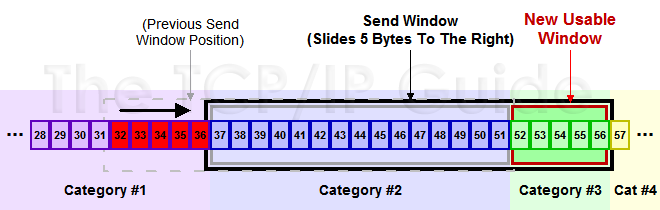
TCP/IP Guide 上還有一張完整的圖,畫的十分清晰,大家看一下。
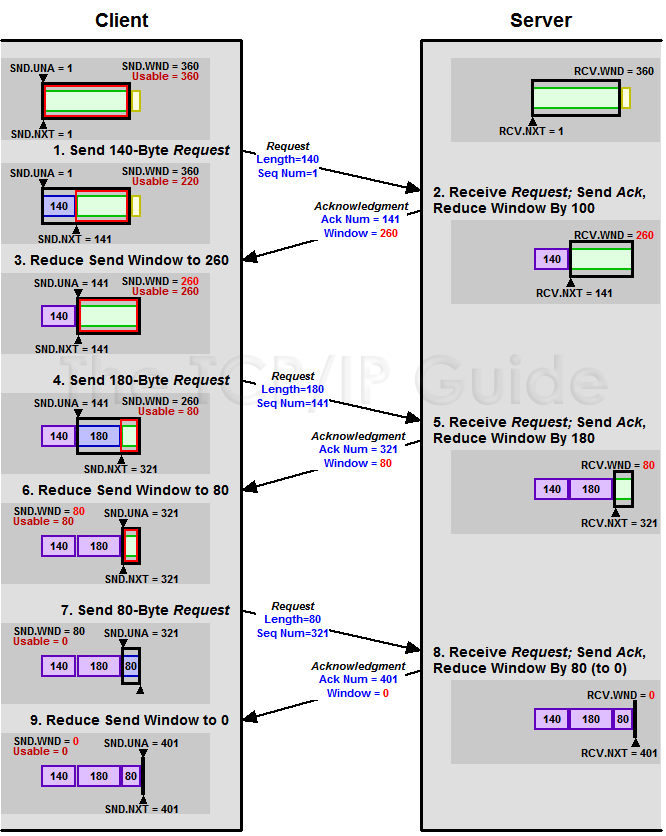
如果接收方回復(fù)的窗口一直是 0 怎么辦?
上文已經(jīng)說了發(fā)送方式根據(jù)接收方回應(yīng)的 window 來控制能發(fā)多少數(shù)據(jù),如果接收方一直回應(yīng) 0,那發(fā)送方就杵著?
你想一下,發(fā)送方發(fā)的數(shù)據(jù)都得到 ACK 了,但是呢回應(yīng)的窗口都是 0 ,這發(fā)送方此時(shí)不敢發(fā)了啊,那也不能一直等著啊,這 Window 啥時(shí)候不變 0 啊?
于是 TCP 有一個(gè) Zero Window Probe 技術(shù),發(fā)送方得知窗口是 0 之后,會(huì)去探測(cè)探測(cè)這個(gè)接收方到底行不行,也就是發(fā)送 ZWP 包給接收方。
具體看實(shí)現(xiàn)了,可以發(fā)送多次,然后還有間隔時(shí)間,多次之后都不行可以直接 RST。
假設(shè)接收方每次回應(yīng)窗口都很小怎么辦?
你想象一下,如果每次接收方都說我還能收 1 個(gè)字節(jié),發(fā)送方該不該發(fā)?
TCP + IP 頭部就 40 個(gè)字節(jié)了,這傳輸不劃算啊,如果傻傻的一直發(fā)這就叫 Silly Window。
那咋辦,一想就是發(fā)送端等著,等養(yǎng)肥了再發(fā),要么接收端自己自覺點(diǎn),數(shù)據(jù)小于一個(gè)閾值就告訴發(fā)送端窗口此時(shí)是 0 算了,也等養(yǎng)肥了再告訴發(fā)送端。
發(fā)送端等著的方案就是納格算法,這個(gè)算法相信看一下代碼就知道了。
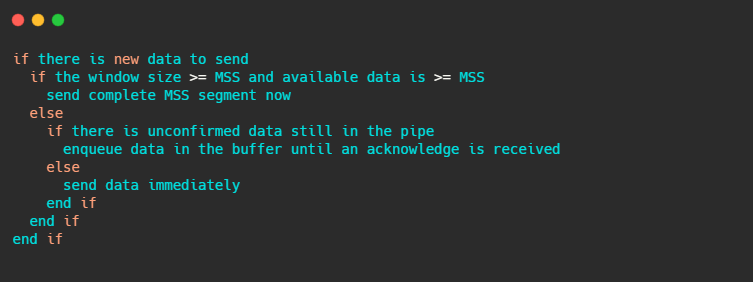
簡(jiǎn)單的說就是當(dāng)前能發(fā)送的數(shù)據(jù)和窗口大于等于 MSS 就立即發(fā)送,否則再判斷一下之前發(fā)送的包 ACK 回來沒,回來再發(fā),不然就攢數(shù)據(jù)。
接收端自覺點(diǎn)的方案是 David D Clark’s 方案,如果窗口數(shù)據(jù)小于某個(gè)閾值就告訴發(fā)送方窗口 0 別發(fā),等緩過來數(shù)據(jù)大于等于 MSS 或者接受 buffer 騰出一半空間了再設(shè)置正常的 window 值給發(fā)送方。
對(duì)了提到納格算法不得不再提一下延遲確認(rèn),納格算法在等待接收方的確認(rèn),而開啟延遲確認(rèn)則會(huì)延遲發(fā)送確認(rèn),會(huì)等之后的包收到了再一起確認(rèn)或者等待一段時(shí)候真的沒了再回復(fù)確認(rèn)。
這就相互等待了,然后延遲就很大了,兩個(gè)不可同時(shí)開啟。
已經(jīng)有滑動(dòng)窗口了為什么還要擁塞控制?
前面我已經(jīng)提到了,加了擁塞控制是因?yàn)?TCP 不僅僅就管兩端之間的情況,還需要知曉一下整體的網(wǎng)絡(luò)情形,畢竟只有大家都守規(guī)矩了道路才會(huì)通暢。
前面我們提到了重傳,如果不管網(wǎng)絡(luò)整體的情況,肯定就是對(duì)方?jīng)]給 ACK ,那我就無腦重傳。
如果此時(shí)網(wǎng)絡(luò)狀況很差,所有的連接都這樣無腦重傳,是不是網(wǎng)絡(luò)情況就更差了,更加擁堵了?
然后越擁堵越重傳,一直沖沖沖!然后就 GG 了。

所以需要個(gè)擁塞控制,來避免這種情況的發(fā)送。
擁塞控制怎么搞?
主要有以下幾個(gè)步驟來搞:
1、慢啟動(dòng),探探路。2、擁塞避免,感覺差不多了減速看看 3、擁塞發(fā)生快速重傳/恢復(fù)
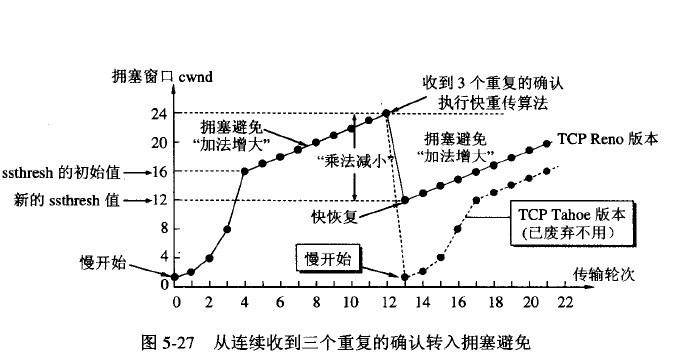
慢啟動(dòng),就是新司機(jī)上路慢慢來,初始化 cwnd(Congestion Window)為 1,然后每收到一個(gè) ACK 就 cwnd++ 并且每過一個(gè) RTT ,cwnd = 2*cwnd 。
線性中帶著指數(shù),指數(shù)中又夾雜著線性增。
然后到了一個(gè)閾值,也就是 ssthresh(slow start threshold)的時(shí)候就進(jìn)入了擁塞避免階段。
這個(gè)階段是每收到一個(gè) ACK 就 cwnd = cwnd + 1/cwnd并且每一個(gè) RTT 就 cwnd++。
可以看到都是線性增。
然后就是一直增,直到開始丟包的情況發(fā)生,前面已經(jīng)分析到重傳有兩種,一種是超時(shí)重傳,一種是快速重傳。
如果發(fā)生超時(shí)重傳的時(shí)候,那說明情況有點(diǎn)糟糕,于是直接把 ssthresh 置為當(dāng)前 cwnd 的一半,然后 cwnd 直接變?yōu)?1,進(jìn)入慢啟動(dòng)階段。

如果是快速重傳,那么這里有兩種實(shí)現(xiàn),一種是 TCP Tahoe ,和超時(shí)重傳一樣的處理。
一種是 TCP Reno,這個(gè)實(shí)現(xiàn)是把 cwnd = cwnd/2 ,然后把 ssthresh 設(shè)置為當(dāng)前的 cwnd 。
然后進(jìn)入快速恢復(fù)階段,將 cwnd = cwnd + 3(因?yàn)榭焖僦貍饔腥危?span style="font-weight: 700;color: rgb(60, 112, 198);">重傳 DACK 指定的包,如果再收到一個(gè)DACK則 cwnd++,如果收到是正常的 ACK 那么就將 cwnd 設(shè)為 ssthresh 大小,進(jìn)入擁塞避免階段。
可以看到快速恢復(fù)就重傳了指定的一個(gè)包,那有可能是很多包都丟了,然后其他的包只能等待超時(shí)重傳,超時(shí)重傳就會(huì)導(dǎo)致 cwnd 減半,多次觸發(fā)就指數(shù)級(jí)下降。
所以又搞了個(gè) New Reno,多加了個(gè) New,它是在沒有SACK 的情況下改進(jìn)快速恢復(fù),它會(huì)觀察重傳 DACK 指定的包的響應(yīng) ACK 是否是已經(jīng)發(fā)送的最大 ACK,比如你發(fā)了1、2、3、4,對(duì)方?jīng)]收到 2,但是 3、4都收到了,于是你重傳 2 之后 ACK 肯定是 5,說明就丟了這一個(gè)包。
不然就是還有其他包丟了,如果就丟了一個(gè)包就是之前的過程一樣,如果還有其他包丟了就繼續(xù)重傳,直到 ACK 是全部的之后再退出快速恢復(fù)階段。
簡(jiǎn)單的說就是一直探測(cè)到全部包都收到了再結(jié)束這個(gè)環(huán)節(jié)。
還有個(gè) FACK,它是基于 SACK 用來作為重傳過程中的擁塞控制,相對(duì)于上面的 New Reno 我們就知道它有 SACK 所以不需要一個(gè)一個(gè)試過去,具體我不展開了。
還有哪些擁塞控制算法?
從維基上看有這么多。
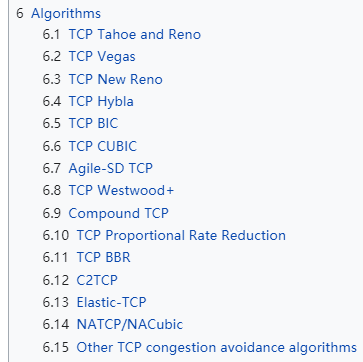
各位看官自個(gè)兒查查吧,或者等我日后修煉有成再來嗶嗶。
總結(jié)
說了這么多來總結(jié)一下吧。
TCP 是面向連接的,提供可靠、有序的傳輸并且還提供流控和擁塞控制,單獨(dú)提取出 TCP 層而不是在 IP層實(shí)現(xiàn)是因?yàn)?IP 層有更多的設(shè)備需要使用,加了復(fù)雜的邏輯不劃算。
三次握手主要是為了定義初始序列號(hào)為了之后的傳輸打下基礎(chǔ),四次揮手是因?yàn)?TCP 是全雙工協(xié)議,因此雙方都得說拜拜。
SYN 超時(shí)了就階梯性重試,如果有 SYN攻擊,可以加大半隊(duì)列數(shù),或減少重試次數(shù),或直接拒絕。
TIME_WAIT 是怕對(duì)方?jīng)]收到最后一個(gè) ACK,然后又發(fā)了 FIN 過來,并且也是等待處理網(wǎng)絡(luò)上殘留的數(shù)據(jù),怕影響新連接。

TIME_WAIT 不建議設(shè)小,或者破壞 TIME_WAIT 機(jī)制,如果真想那么可以開啟快速回收,或者重用,不過注意受益的對(duì)象。
超時(shí)重傳是為了保證對(duì)端一定能收到包,快速重傳是為了避免在偶爾丟包的時(shí)候需要等待超時(shí)這么長(zhǎng)時(shí)間,SACK 是為了讓發(fā)送方知道重傳哪些。
D-SACK 是為了讓發(fā)送方知道這次重傳的原因是對(duì)方真的沒收到還是自己太心急了 RTO 整小了,不至于兩眼一抹黑。
滑動(dòng)窗口是為了平衡發(fā)送方的發(fā)送速率和接收方的接受數(shù)率,不至于瞎發(fā),當(dāng)然還需要注意 Silly Window 的情況,同時(shí)還要注意納格算法和延遲確認(rèn)不能一起搭配。
而滑動(dòng)窗口還不夠,還得有個(gè)擁塞控制,因?yàn)?span style="font-weight: 700;color: rgb(60, 112, 198);">出行你我他,安全靠大家,TCP 還得跳出來看看關(guān)心下當(dāng)前大局勢(shì)
原創(chuàng)電子書原創(chuàng)思維導(dǎo)圖
掃碼或微信搜 Java3y?回復(fù)「888」領(lǐng)取1000+頁原創(chuàng)電子書和思維導(dǎo)圖。

 |
|

