
【機(jī)器學(xué)習(xí)】Kaggle知識點(diǎn):集成學(xué)習(xí)基礎(chǔ)
集成學(xué)習(xí)基礎(chǔ)
集成學(xué)習(xí)是指結(jié)合兩個或多個模型的機(jī)器學(xué)習(xí)模型。集成學(xué)習(xí)是機(jī)器學(xué)習(xí)的分支,通常在追求更強(qiáng)預(yù)測的能力時(shí)使用。
集成學(xué)習(xí)經(jīng)常被機(jī)器學(xué)習(xí)競賽中的頂級和獲勝參與者使用。現(xiàn)代機(jī)器學(xué)習(xí)庫(scikit-learn、XGBoost)內(nèi)部已經(jīng)結(jié)合了常見的集成學(xué)習(xí)方法。
集成學(xué)習(xí)介紹
集成學(xué)習(xí)結(jié)合多個不同的模型,然后結(jié)合單個模型完成預(yù)測。通常情況下,集成學(xué)習(xí)能比單個模型找到更好的性能。
常見的集成學(xué)習(xí)技術(shù)有三類:
Bagging, 如. Bagged Decision Trees and Random Forest. Boosting, 如. Adaboost and Gradient Boosting Stacking, 如. Voting and using a meta-model.
使用集成學(xué)習(xí)可以減少預(yù)測結(jié)果的方差,同時(shí)也比單個模型更好的性能。
Bagging
Bagging通過采樣訓(xùn)練數(shù)據(jù)集的樣本,訓(xùn)練得到多樣的模型,進(jìn)而得到多樣的預(yù)測結(jié)果。在結(jié)合模型的預(yù)測結(jié)果時(shí),可以對單個模型預(yù)測結(jié)果進(jìn)行投票或平均。
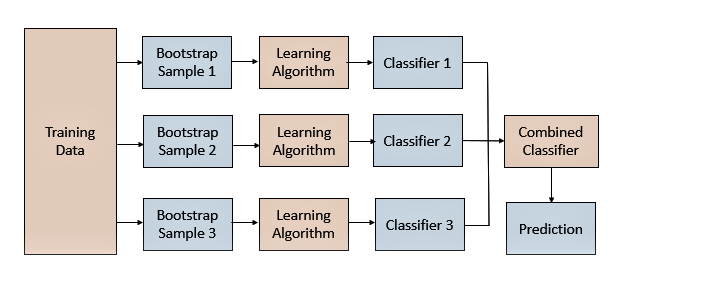
Bagging的關(guān)鍵是對數(shù)據(jù)集的采樣方法。常見的方式可以從行(樣本)維度進(jìn)行采樣,這里進(jìn)行的是有放回采樣。
Bagging可通過BaggingClassifier和BaggingRegressor使用,默認(rèn)情況下它們使用決策樹作為基本模型,可以通過n_estimators參數(shù)指定要創(chuàng)建的樹的數(shù)量。
from?sklearn.datasets?import?make_classification
from?sklearn.model_selection?import?cross_val_score
from?sklearn.model_selection?import?RepeatedStratifiedKFold
from?sklearn.ensemble?import?BaggingClassifier
#?創(chuàng)建樣例數(shù)據(jù)集
X,?y?=?make_classification(random_state=1)
#?創(chuàng)建bagging模型
model?=?BaggingClassifier(n_estimators=50)
#?設(shè)置驗(yàn)證集數(shù)據(jù)劃分方式
cv?=?RepeatedStratifiedKFold(n_splits=10,?n_repeats=3,?random_state=1)
#?驗(yàn)證模型精度
n_scores?=?cross_val_score(model,?X,?y,?scoring='accuracy',?cv=cv,?n_jobs=-1)
#?打印模型的精度
print('Mean?Accuracy:?%.3f?(%.3f)'?%?(mean(n_scores),?std(n_scores)))
Random Forest
隨機(jī)森林是 Bagging與樹模型的結(jié)合:
隨機(jī)森林集成在訓(xùn)練數(shù)據(jù)集的不同引導(dǎo)樣本上擬合決策樹。
隨機(jī)森林還將對每個數(shù)據(jù)集的特征(列)進(jìn)行采樣。
在構(gòu)建每個決策樹時(shí),隨機(jī)森林不是在選擇分割點(diǎn)時(shí)考慮所有特征,而是將特征限制為特征的隨機(jī)子集。
隨機(jī)森林集成可通過RandomForestClassifier和RandomForestRegressor類在 scikit-learn ?中獲得。您可以通過n_estimators參數(shù)指定要創(chuàng)建的樹的數(shù)量,并通過max_features參數(shù)指定要在每個分割點(diǎn)考慮的隨機(jī)選擇的特征的數(shù)量。
from?sklearn.datasets?import?make_classification
from?sklearn.model_selection?import?cross_val_score
from?sklearn.model_selection?import?RepeatedStratifiedKFold
from?sklearn.ensemble?import?RandomForestClassifier
#?創(chuàng)建樣例數(shù)據(jù)集
X,?y?=?make_classification(random_state=1)
#?創(chuàng)建隨機(jī)森林模型
model?=?RandomForestClassifier(n_estimators=50)
#?設(shè)置驗(yàn)證集數(shù)據(jù)劃分方式
cv?=?RepeatedStratifiedKFold(n_splits=10,?n_repeats=3,?random_state=1)
#?驗(yàn)證模型精度
n_scores?=?cross_val_score(model,?X,?y,?scoring='accuracy',?cv=cv,?n_jobs=-1)
#?打印模型的精度
print('Mean?Accuracy:?%.3f?(%.3f)'?%?(mean(n_scores),?std(n_scores)))
AdaBoost
Boosting在迭代過程中嘗試糾先前模型所產(chǎn)生的錯誤,迭代次數(shù)越多集成產(chǎn)生的錯誤就越少,至少在數(shù)據(jù)支持的限制范圍內(nèi)并且在過度擬合訓(xùn)練數(shù)據(jù)集之前。
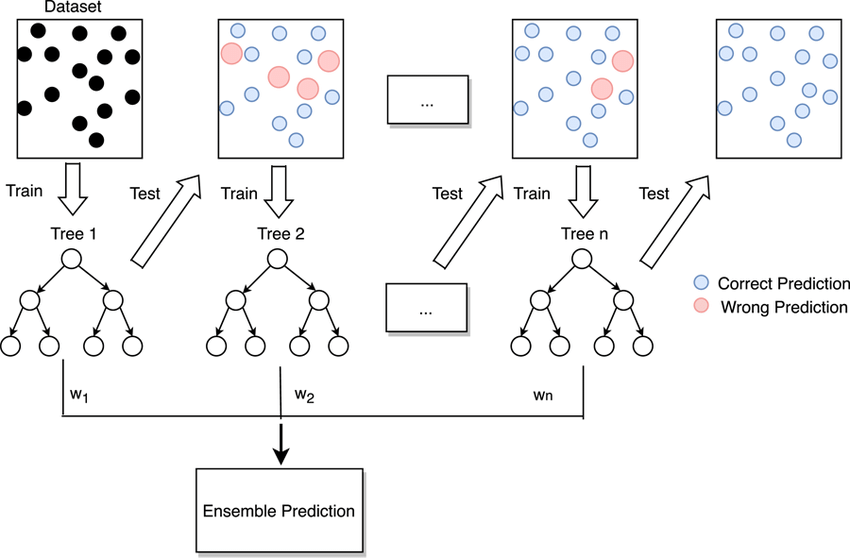
Boosting想法最初是作為一種理論思想發(fā)展起來的,AdaBoost算法是第一個成功實(shí)現(xiàn)基于Boosting的集成算法的方法。
AdaBoost在加權(quán)訓(xùn)練數(shù)據(jù)集的版本上擬合決策樹,以便樹更多地關(guān)注先前成員出錯的示例。AdaBoost不是完整的決策樹,而是使用非常簡單的樹,在做出預(yù)測之前對一個輸入變量做出單一決策。這些短樹被稱為決策樹樁。
AdaBoost可通過AdaBoostClassifier和AdaBoostRegressor使用,它們默認(rèn)使用決策樹(決策樹樁)作為基本模型,可以通過n_estimators參數(shù)指定要創(chuàng)建的樹的數(shù)量。
from?sklearn.datasets?import?make_classification
from?sklearn.model_selection?import?cross_val_score
from?sklearn.model_selection?import?RepeatedStratifiedKFold
from?sklearn.ensemble?import?AdaBoostClassifier
#?創(chuàng)建樣例數(shù)據(jù)集
X,?y?=?make_classification(random_state=1)
#?創(chuàng)建adaboost模型
model?=?AdaBoostClassifier(n_estimators=50)
#?設(shè)置驗(yàn)證集數(shù)據(jù)劃分方式
cv?=?RepeatedStratifiedKFold(n_splits=10,?n_repeats=3,?random_state=1)
#?驗(yàn)證模型精度
n_scores?=?cross_val_score(model,?X,?y,?scoring='accuracy',?cv=cv,?n_jobs=-1)
#?打印模型的精度
print('Mean?Accuracy:?%.3f?(%.3f)'?%?(mean(n_scores),?std(n_scores)))
Gradient Boosting
Gradient Boosting是一個用于提升集成算法的框架,是對AdaBoosting的擴(kuò)展。Gradient Boosting定義為統(tǒng)計(jì)框架下的加法模型,并允許使用任意損失函數(shù)以使其更加靈活,并允許使用損失懲罰(收縮)來減少過度擬合。
Gradient Boosting引入了Bagging的操作,例如訓(xùn)練數(shù)據(jù)集行和列的采樣,稱為隨機(jī)梯度提升。
對于結(jié)構(gòu)化或表格數(shù)據(jù)來說,Gradient Boosting一種非常成功的集成技術(shù),盡管由于模型是按順序添加的,因此擬合模型可能會很慢。已經(jīng)開發(fā)了更有效的實(shí)現(xiàn),如XGBoost、LightGBM。
Gradient Boosting在可以通過GradientBoostingClassifier和GradientBoostingRegressor使用,默認(rèn)使用決策樹作為基礎(chǔ)模型。您可以通過n_estimators參數(shù)指定要創(chuàng)建的樹的數(shù)量,通過learning_rate參數(shù)控制每棵樹的貢獻(xiàn)的學(xué)習(xí)率。
from?sklearn.datasets?import?make_classification
from?sklearn.model_selection?import?cross_val_score
from?sklearn.model_selection?import?RepeatedStratifiedKFold
from?sklearn.ensemble?import?GradientBoostingClassifier
#?創(chuàng)建樣例數(shù)據(jù)集
X,?y?=?make_classification(random_state=1)
#?創(chuàng)建GradientBoosting模型
model?=?GradientBoostingClassifier(n_estimators=50)
#?設(shè)置驗(yàn)證集數(shù)據(jù)劃分方式
cv?=?RepeatedStratifiedKFold(n_splits=10,?n_repeats=3,?random_state=1)
#?驗(yàn)證模型精度
n_scores?=?cross_val_score(model,?X,?y,?scoring='accuracy',?cv=cv,?n_jobs=-1)
#?打印模型的精度
print('Mean?Accuracy:?%.3f?(%.3f)'?%?(mean(n_scores),?std(n_scores)))
Voting
Voting使用簡單的統(tǒng)計(jì)數(shù)據(jù)來組合來自多個模型的預(yù)測。
硬投票:對預(yù)測類別進(jìn)行投票;
軟投票:對預(yù)測概率進(jìn)行求均值;
Voting可通過VotingClassifier和VotingRegressor使用。可以將基本模型列表作為參數(shù),列表中的每個模型都必須是具有名稱和模型的元組,
from?sklearn.datasets?import?make_classification
from?sklearn.model_selection?import?cross_val_score
from?sklearn.model_selection?import?RepeatedStratifiedKFold
from?sklearn.ensemble?import?VotingClassifier
from?sklearn.naive_bayes?import?GaussianNB
from?sklearn.linear_model?import?LogisticRegression
#?創(chuàng)建數(shù)據(jù)集
X,?y?=?make_classification(random_state=1)
#?模型列表
models?=?[('lr',?LogisticRegression()),?('nb',?GaussianNB())]
#?創(chuàng)建voting模型
model?=?VotingClassifier(models,?voting='soft')
#?設(shè)置驗(yàn)證集數(shù)據(jù)劃分方式
cv?=?RepeatedStratifiedKFold(n_splits=10,?n_repeats=3,?random_state=1)
#?驗(yàn)證模型精度
n_scores?=?cross_val_score(model,?X,?y,?scoring='accuracy',?cv=cv,?n_jobs=-1)
#?打印模型的精度
print('Mean?Accuracy:?%.3f?(%.3f)'?%?(mean(n_scores),?std(n_scores)))
Stacking
Stacking組合多種不同類型的基本模型的預(yù)測,和Voting類似。但Stacking可以根據(jù)驗(yàn)證集來調(diào)整每個模型的權(quán)重。
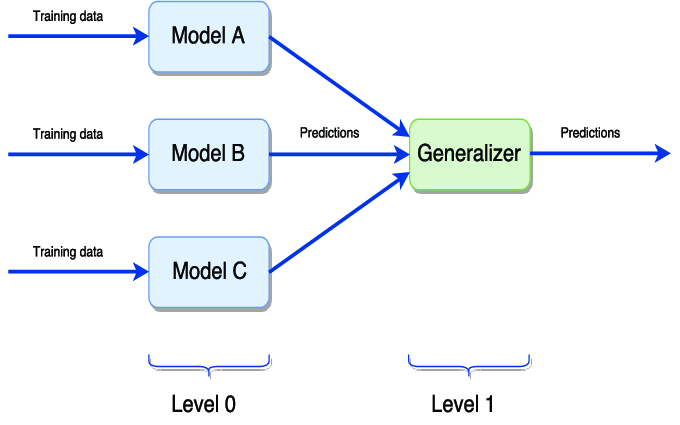
Stacking需要和交叉驗(yàn)證搭配使用,也可以通過StackingClassifier和StackingRegressor使用,可以將基本模型作為模型的參數(shù)提供。
from?sklearn.datasets?import?make_classification
from?sklearn.model_selection?import?cross_val_score
from?sklearn.model_selection?import?RepeatedStratifiedKFold
from?sklearn.ensemble?import?StackingClassifier
from?sklearn.neighbors?import?KNeighborsClassifier
from?sklearn.tree?import?DecisionTreeClassifier
from?sklearn.linear_model?import?LogisticRegression
#?創(chuàng)建數(shù)據(jù)集
X,?y?=?make_classification(random_state=1)
#?模型列表
models?=?[('knn',?KNeighborsClassifier()),?('tree',?DecisionTreeClassifier())]
#?設(shè)置驗(yàn)證集數(shù)據(jù)劃分方式
cv?=?RepeatedStratifiedKFold(n_splits=10,?n_repeats=3,?random_state=1)
#?驗(yàn)證模型精度
n_scores?=?cross_val_score(model,?X,?y,?scoring='accuracy',?cv=cv,?n_jobs=-1)
#?打印模型的精度
print('Mean?Accuracy:?%.3f?(%.3f)'?%?(mean(n_scores),?std(n_scores)))
往期精彩回顧