
SUR-adapter:LLM增強擴散模型,簡單句子生成高質(zhì)量圖像

【新智元導(dǎo)讀】參數(shù)高效的微調(diào)方法SUR-adapter,可以增強text-to-image擴散模型理解關(guān)鍵詞的能力。


背景介紹


方法概述
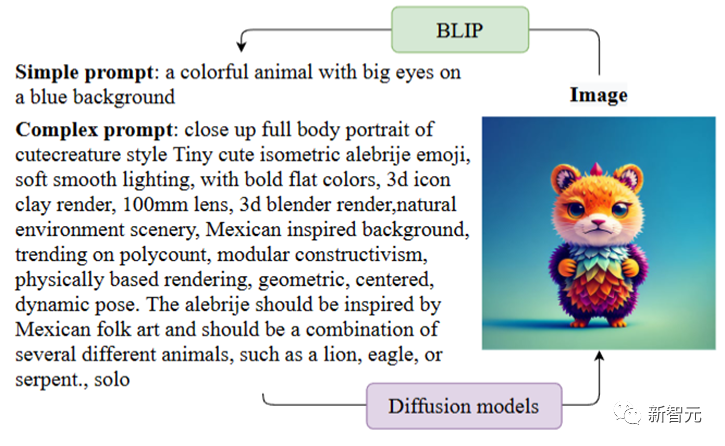
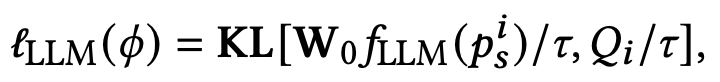
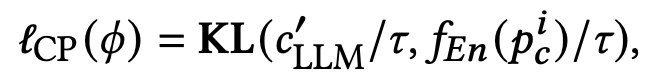
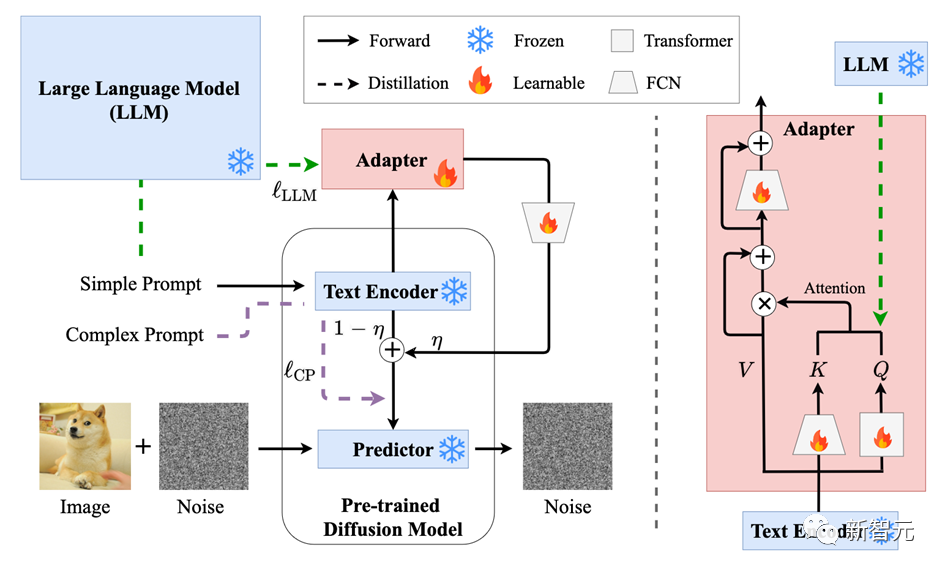
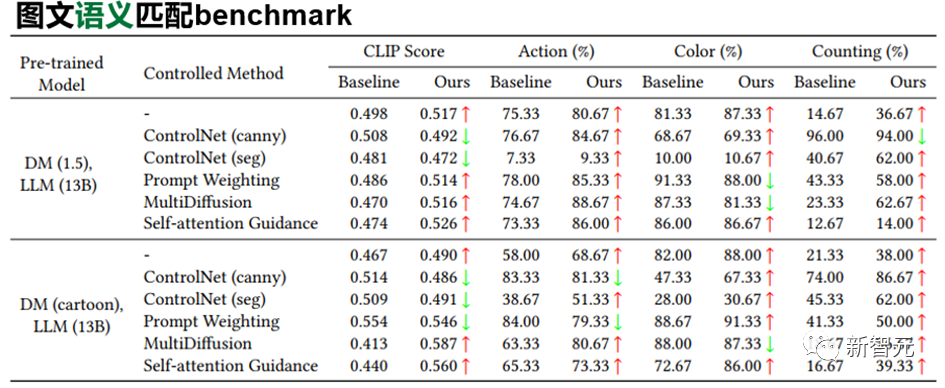
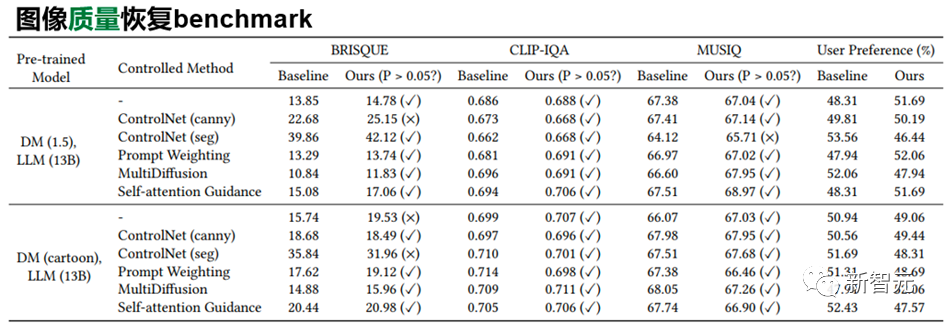
實驗結(jié)果


中山大學(xué)人機物智能融合實驗室 (HCP Lab) 由林倞教授于 2010 年創(chuàng)辦,近年來在多模態(tài)內(nèi)容理解、因果及認(rèn)知推理、具身智能等方面取得豐富學(xué)術(shù)成果,數(shù)次獲得國內(nèi)外科技獎項及最佳論文獎,并致力于打造產(chǎn)品級的AI技術(shù)及平臺。
關(guān)注公眾號【機器學(xué)習(xí)與AI生成創(chuàng)作】,更多精彩等你來讀
臥剿,6萬字!30個方向130篇!CVPR 2023 最全 AIGC 論文!一口氣讀完
深入淺出stable diffusion:AI作畫技術(shù)背后的潛在擴散模型論文解讀
深入淺出ControlNet,一種可控生成的AIGC繪畫生成算法!
 戳我,查看GAN的系列專輯~!
戳我,查看GAN的系列專輯~!
附下載 |《TensorFlow 2.0 深度學(xué)習(xí)算法實戰(zhàn)》
附下載 |《計算機視覺中的數(shù)學(xué)方法》分享
《基于深度神經(jīng)網(wǎng)絡(luò)的少樣本學(xué)習(xí)綜述》
《禮記·學(xué)記》有云:獨學(xué)而無友,則孤陋而寡聞
點擊一杯奶茶,成為AIGC+CV視覺的前沿弄潮兒!,加入 AI生成創(chuàng)作與計算機視覺 知識星球!
評論
圖片
表情