
QQ瀏覽器是如何提升搜索相關(guān)性的?
 導言 | 搜索相關(guān)性主要指衡量Query和Doc的匹配程度,是信息檢索的核心基礎(chǔ)任務(wù)之一,也是商業(yè)搜索引擎的體驗優(yōu)劣最樸素的評價維度之一。本文作者劉杰主要介紹QQ瀏覽器搜索相關(guān)性團隊在相關(guān)性系統(tǒng)及算法方面的實踐經(jīng)歷。值得一提的是,本文會特別分享在QQ瀏覽器搜索、搜狗搜索兩個大型系統(tǒng)融合過程中,在系統(tǒng)融合、算法融合、算法突破方面的實踐經(jīng)驗。希望對搜索算法以及相關(guān)領(lǐng)域內(nèi)的同學有幫助。
導言 | 搜索相關(guān)性主要指衡量Query和Doc的匹配程度,是信息檢索的核心基礎(chǔ)任務(wù)之一,也是商業(yè)搜索引擎的體驗優(yōu)劣最樸素的評價維度之一。本文作者劉杰主要介紹QQ瀏覽器搜索相關(guān)性團隊在相關(guān)性系統(tǒng)及算法方面的實踐經(jīng)歷。值得一提的是,本文會特別分享在QQ瀏覽器搜索、搜狗搜索兩個大型系統(tǒng)融合過程中,在系統(tǒng)融合、算法融合、算法突破方面的實踐經(jīng)驗。希望對搜索算法以及相關(guān)領(lǐng)域內(nèi)的同學有幫助。 業(yè)務(wù)介紹
業(yè)務(wù)介紹
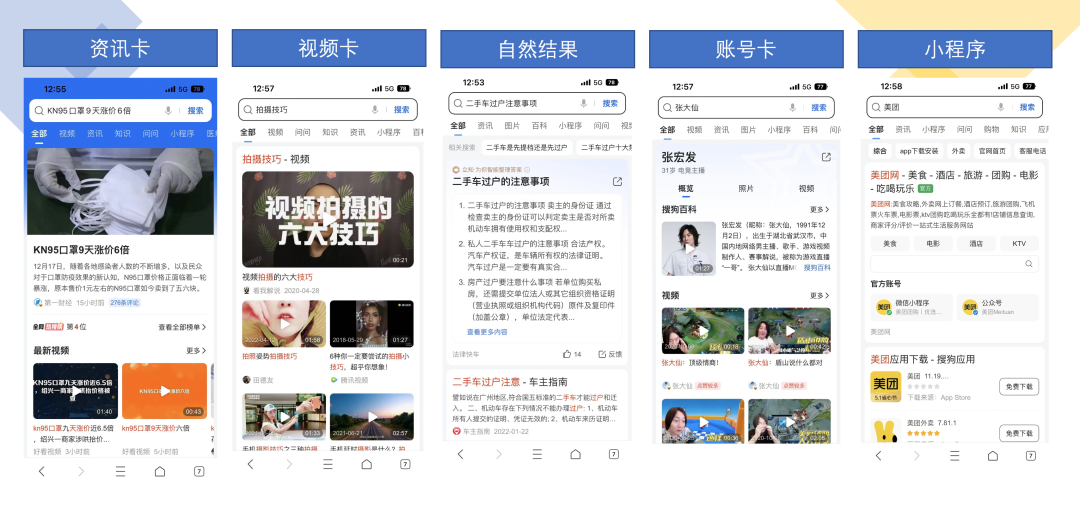

 搜索相關(guān)性介紹
搜索相關(guān)性介紹
1)搜索主體框架
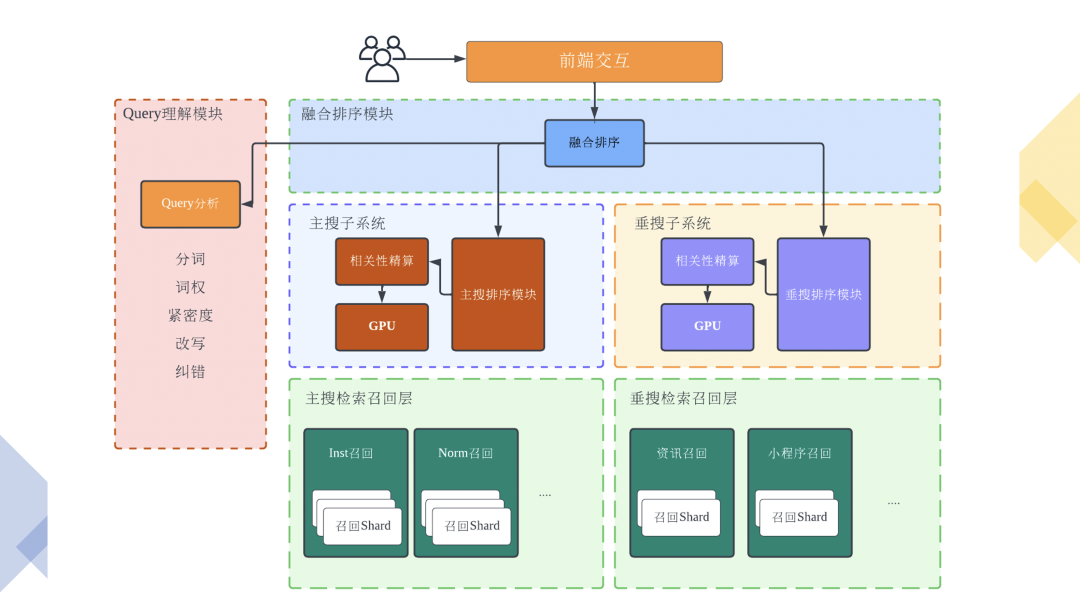
2)算法架構(gòu)
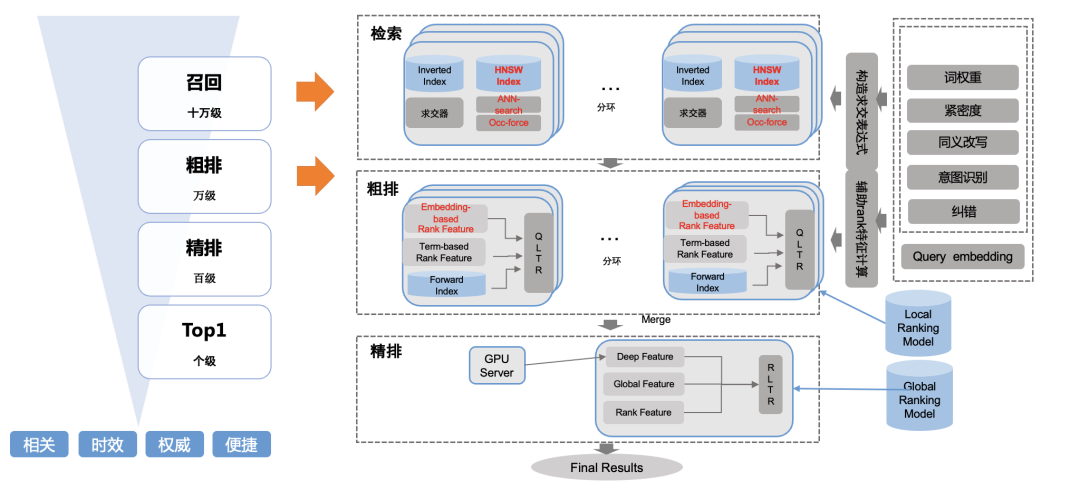
3)評估體系
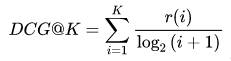
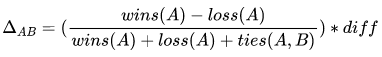
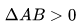
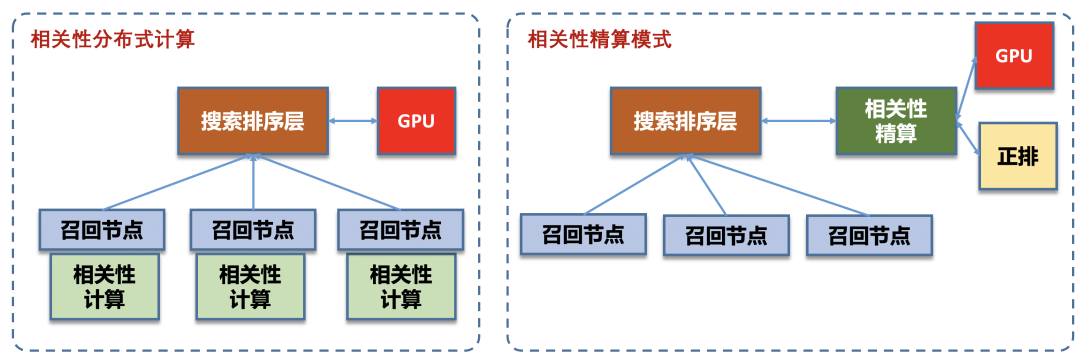
 相關(guān)性精算的系統(tǒng)演進
相關(guān)性精算的系統(tǒng)演進
1)1.0時代,群雄割據(jù)->三國爭霸
2)2.0時代,統(tǒng)一復用

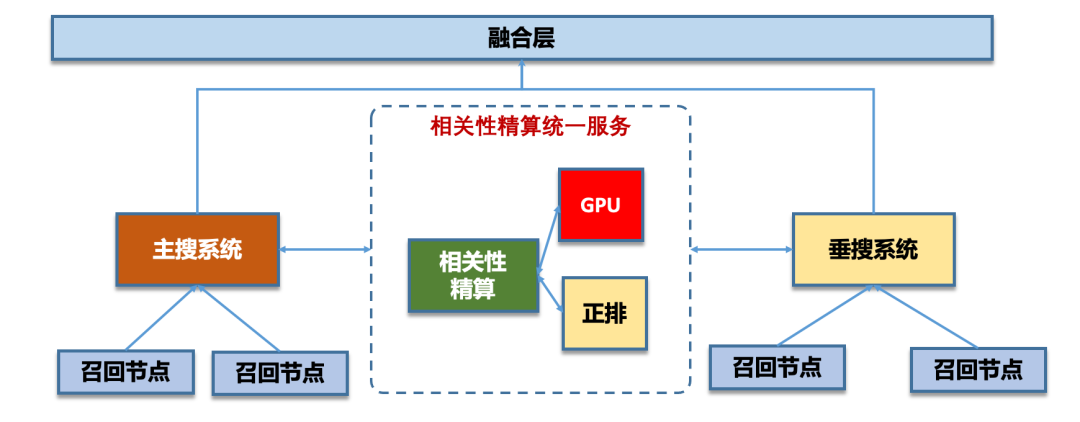
 搜索相關(guān)性技術(shù)實踐
搜索相關(guān)性技術(shù)實踐
1)相關(guān)性標準

2)相關(guān)性的技術(shù)架構(gòu)
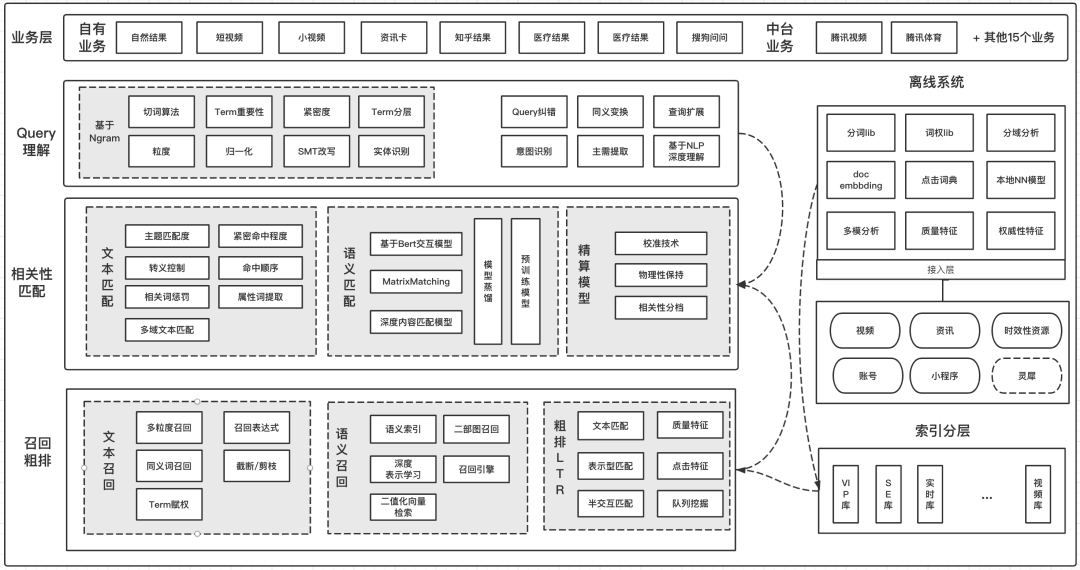
3)深度語義匹配實踐
QQ瀏覽器搜索相關(guān)性的困難與挑戰(zhàn)

深度語義的現(xiàn)狀
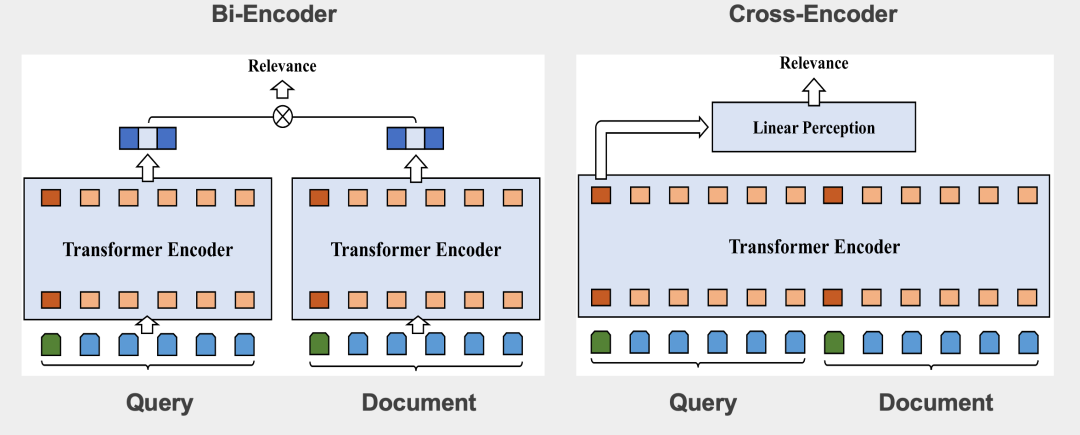
QQ瀏覽器搜索相關(guān)性深度語義實踐
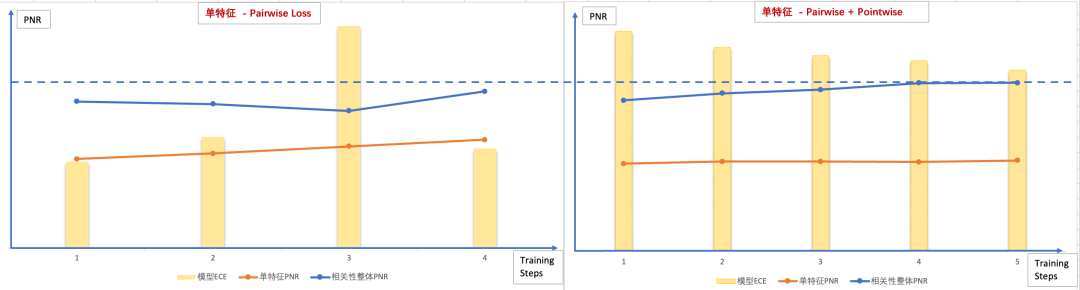
相關(guān)性Ranking Loss:目前我們的相關(guān)性標注標準共分為五個檔位,最直接的建模方式,其實是進行N=5的N分類任務(wù),即使用Pointwise的方式建模。搜索場景下,我們其實并不關(guān)心分類能力的好壞,而更關(guān)心不同樣本之前的偏序關(guān)系,例如對于同一個Query的兩個相關(guān)結(jié)果DocA和DocB,Pointwise模型只能判斷出兩者都與Query相關(guān),無法區(qū)分DocA和DocB相關(guān)性程度。因此搜索領(lǐng)域的任務(wù),更多更廣泛的建模思路是將其視為一個文檔排序場景,廣泛使用Leaning To Rank思想進行業(yè)務(wù)場景建模。
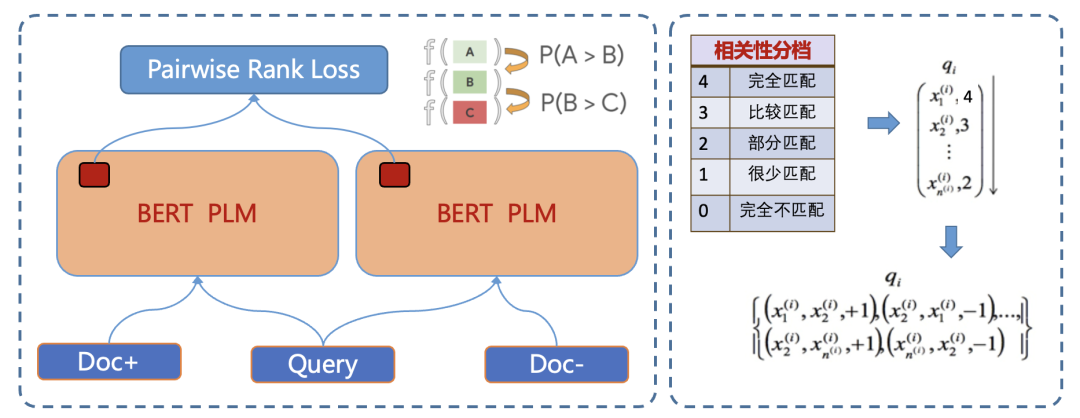
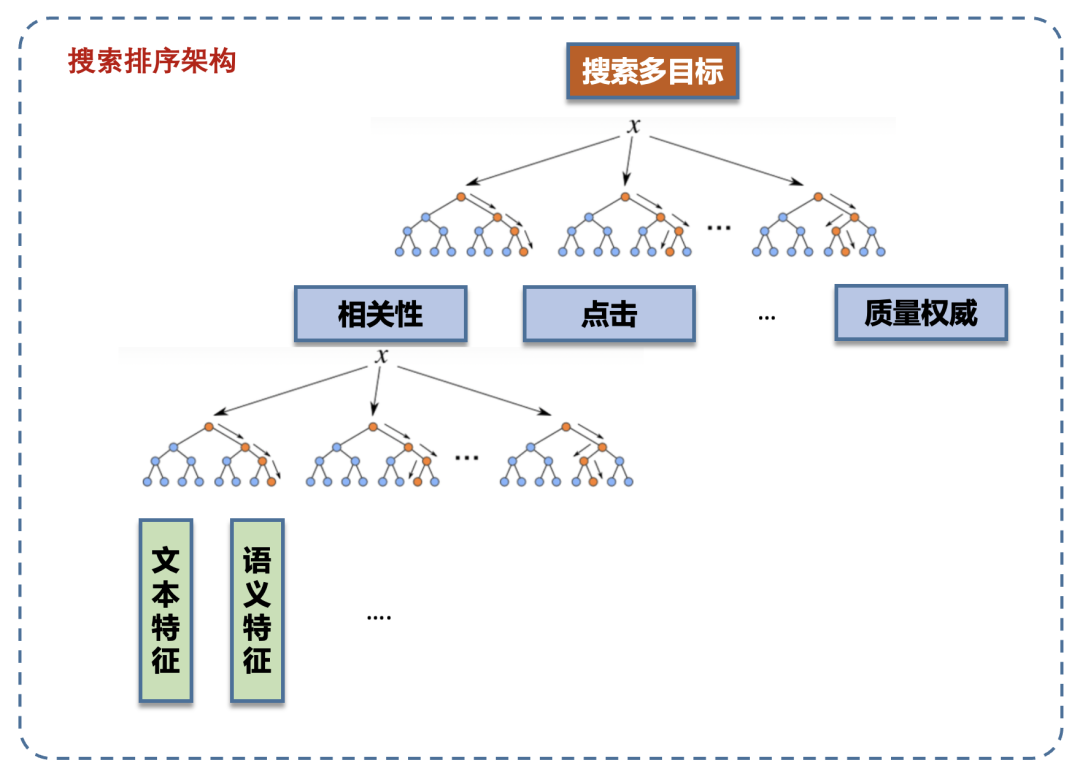
深度語義特征的校準問題——Ranking Loss的問題:相關(guān)性是搜索排序的基礎(chǔ)能力,在整個計算流程的視角看,相關(guān)性計算不是最后一個階段,所以當相關(guān)性內(nèi)部子特征的目標如果直接使用RankingLoss,要特別注意與上下游的配合應(yīng)用,特別要關(guān)注單特征的RankingLoss持續(xù)減少,是否與整體任務(wù)的提升一致。同時,RankLoss由于不具有全局的物理含義,即不同Query下的DocA和DocB的得分是不具有可比性,這直接導致了其作為特征值應(yīng)用到下游模型時,如果我們使用例如決策樹這種基于全局分裂增益來劃分閾值的模型,會有一定的損失。
領(lǐng)域自適應(yīng):最近幾年的NLP領(lǐng)域,預訓練方向可以稱得上AI方向的掌上明珠,從模型的參數(shù)規(guī)模、預訓練的方法、多語言多模態(tài)等幾個方向持續(xù)發(fā)展,不斷地刷新著領(lǐng)域Benchmark。預訓練通過自監(jiān)督學習,從大規(guī)模數(shù)據(jù)中獲得與具體任務(wù)無關(guān)的預訓練模型。那么,在搜索領(lǐng)域下,如何將預訓練語言模型,與搜索語料更好的結(jié)合,是我們團隊一直在探索的方向。
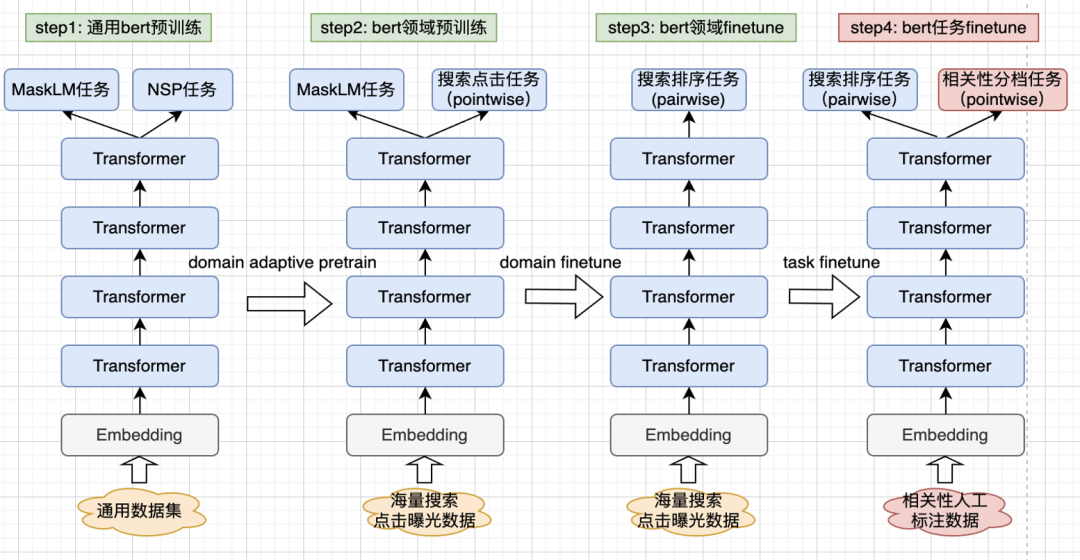
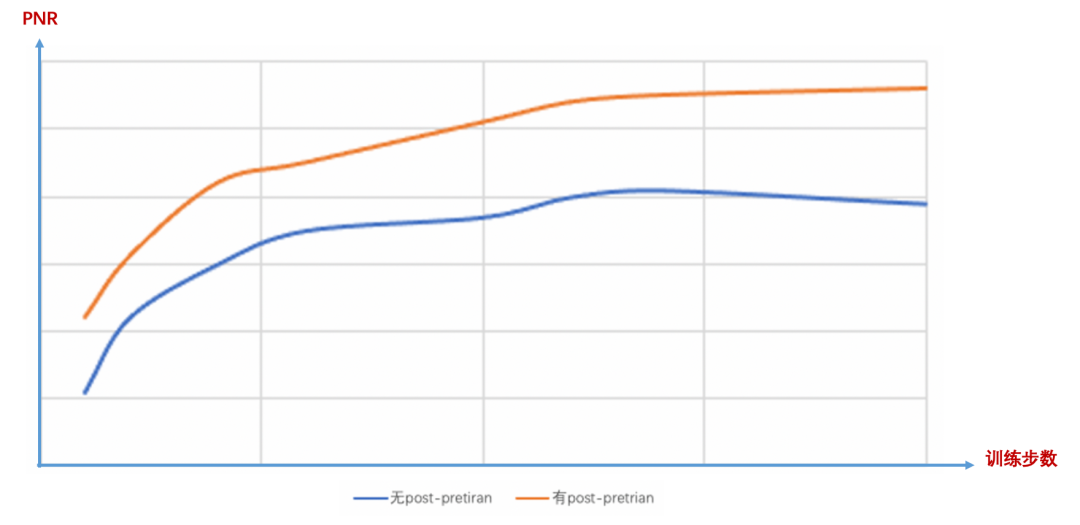
4)相關(guān)性語義匹配增強實踐
深度語義匹配的魯棒性問題
什么是相關(guān)性匹配(RelevanceMatching)
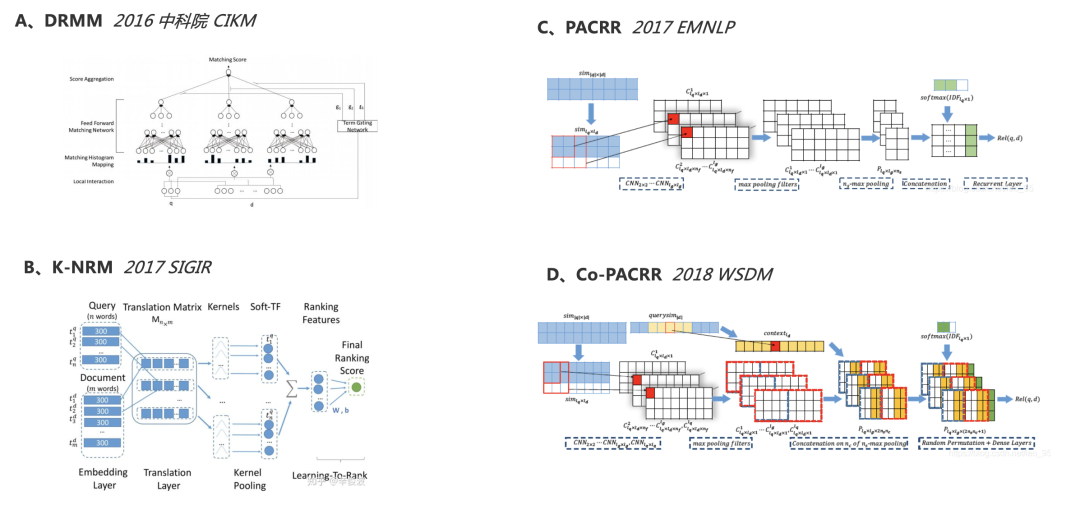
相關(guān)性匹配的相關(guān)工作
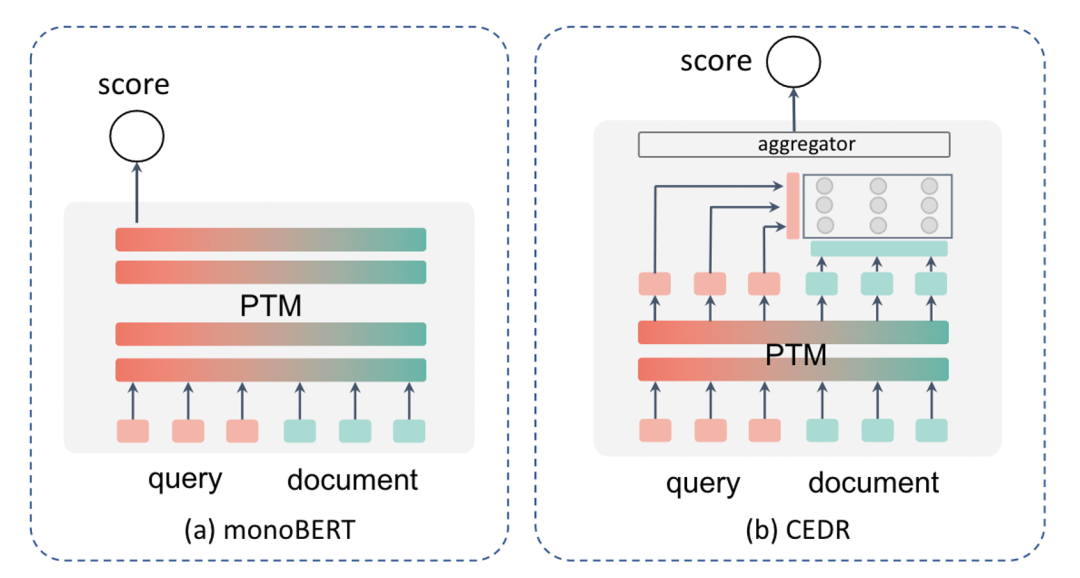
相關(guān)性匹配增強
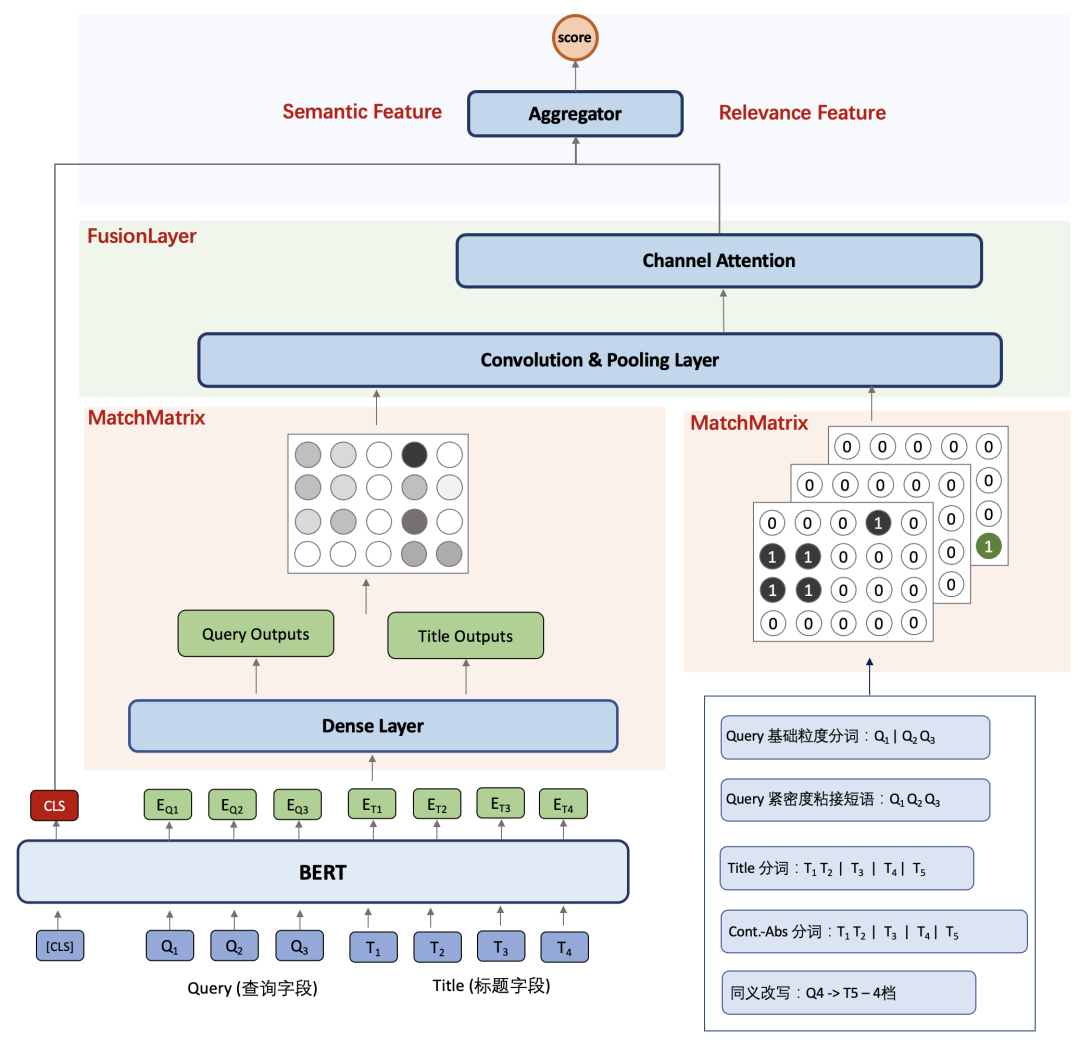
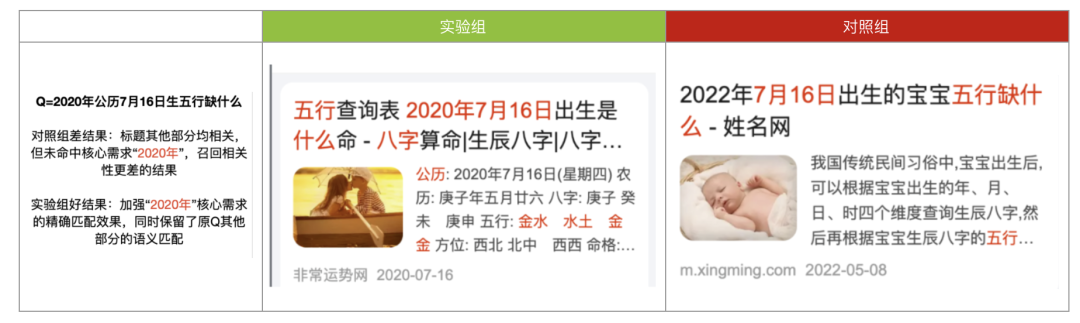
實驗&效果

小結(jié)



工作日晚8點 看騰訊技術(shù)、學專家經(jīng)驗
評論
圖片
表情