
復(fù)雜網(wǎng)絡(luò)在信用風(fēng)險(xiǎn)中的實(shí)踐
在信貸領(lǐng)域主要有兩種風(fēng)險(xiǎn):
欺詐風(fēng)險(xiǎn):借款人的目的就是騙貸。
信用風(fēng)險(xiǎn):又稱違約風(fēng)險(xiǎn),是借款人因各種原因,不愿或無力履行合同條件而構(gòu)成違約,致使平臺遭受損失。
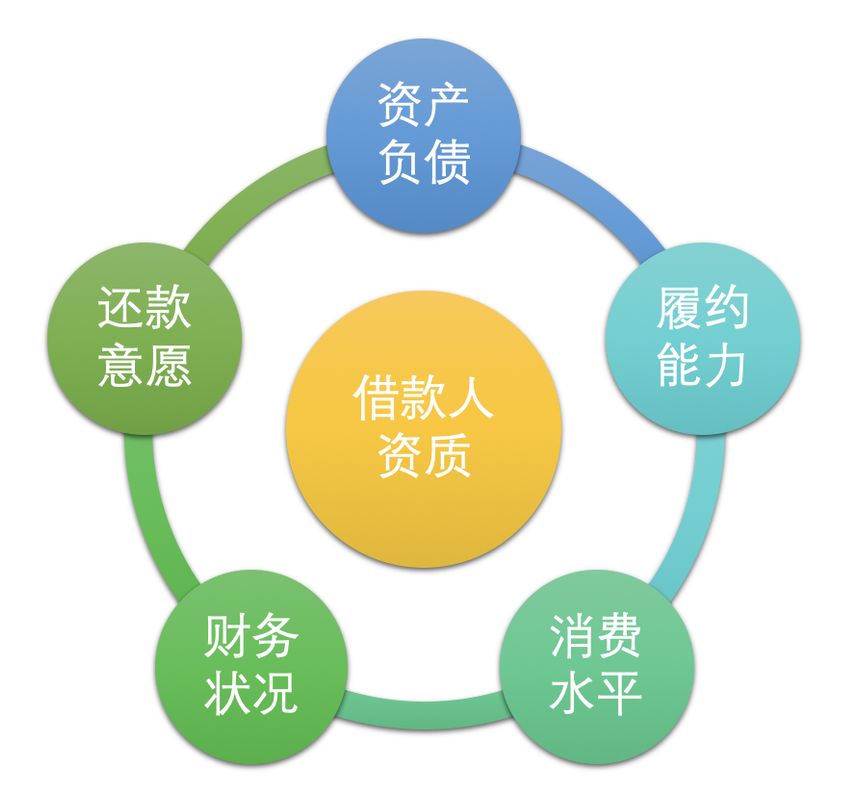
針對信用風(fēng)險(xiǎn),需要對借款人的財(cái)務(wù)狀況、還款意愿、履約能力等各方面因素綜合量化評估,并根據(jù)風(fēng)險(xiǎn)等級制定不同的差異化定價(jià)(不同額度利率)和策略。
白話一點(diǎn)的解釋就是:
業(yè)務(wù):需要訓(xùn)練一個(gè)模型,去預(yù)測借款人違約概率,并根據(jù)違約概率高低表示信用好壞,信用好的給予更高的額度和更低的貸款利率,針對信用較差的制定更嚴(yán)格的審核,更高的利率。
模型:傳統(tǒng)是使用評分卡,可解釋性比較好。但現(xiàn)在越來越多會使用機(jī)器學(xué)習(xí)(如XGBoost),快速出結(jié)果且效果更好。
特征:上圖針對各個(gè)維度設(shè)計(jì),并保證可解釋性。
樣本:歷史上是否違約的人群作為訓(xùn)練樣本(都是錢啊)。
如何將借款人所處的系統(tǒng)抽象成復(fù)雜網(wǎng)絡(luò)?下面介紹基礎(chǔ)層次和業(yè)務(wù)層次的抽象,最終得到什么樣的復(fù)雜網(wǎng)絡(luò),以及為什么要這樣做。
基礎(chǔ)層次抽象
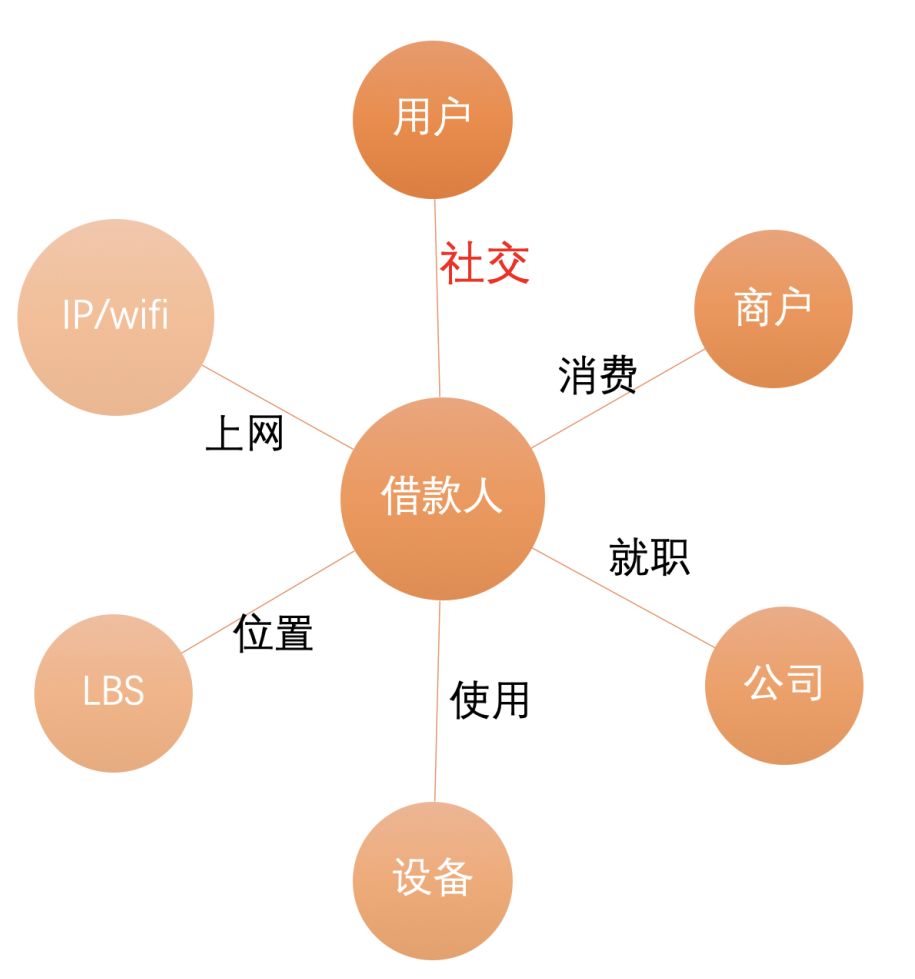
從原始數(shù)據(jù)中提取節(jié)點(diǎn)及關(guān)系抽象成復(fù)雜網(wǎng)絡(luò):
節(jié)點(diǎn):用戶、商戶、公司、設(shè)備、LBS、IP/WIFI
關(guān)系:社交、消費(fèi)、就職、使用、位置、上網(wǎng)
業(yè)務(wù)層次抽象
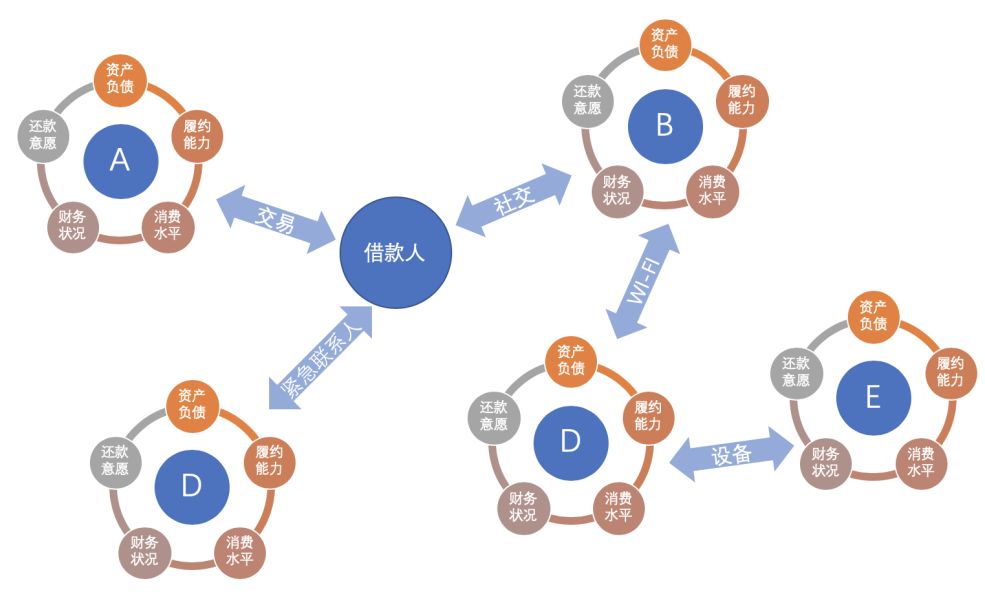
物以類聚,人以群分,一個(gè)人周圍鄰居的信用資質(zhì)可以反應(yīng)其自身信用資質(zhì)。
基于上述業(yè)務(wù)假設(shè)對網(wǎng)絡(luò)進(jìn)一步抽象:
節(jié)點(diǎn):用戶
關(guān)系:社交、同位置、同設(shè)備、同公司、同商戶、同WIFI....

我們?yōu)槊總€(gè)節(jié)點(diǎn)附上信用資質(zhì),最終可以得到一個(gè)復(fù)雜網(wǎng)絡(luò)。
為什么要這么做?
1. 基礎(chǔ)層次的抽象可以供多個(gè)不同的業(yè)務(wù)使用。
2. 基于業(yè)務(wù)經(jīng)驗(yàn)對數(shù)據(jù)進(jìn)一步精煉 garbage in garbage out。
3. 適用同類型節(jié)點(diǎn)的算法較多,計(jì)算復(fù)雜度低。
4. 壓縮圖,減少降低噪聲以及緩解數(shù)據(jù)稀疏性。
我們可以從復(fù)雜網(wǎng)絡(luò)中抽取什么信息呢?
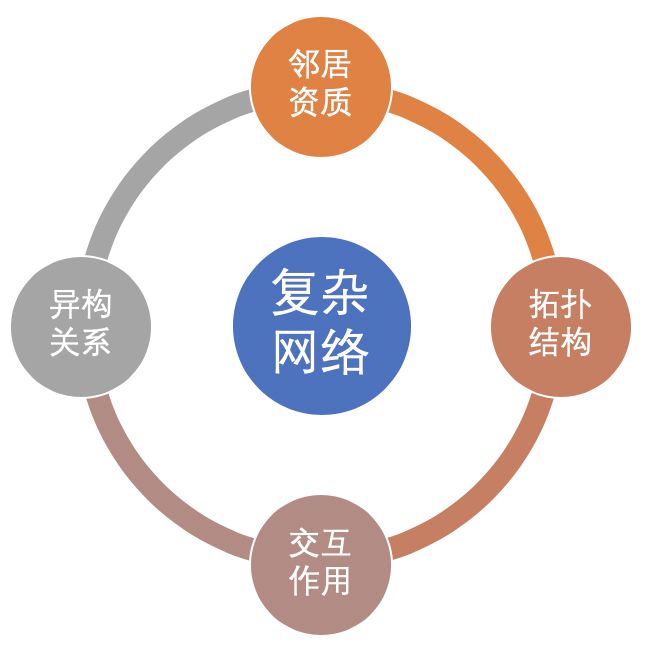
鄰居屬性:鄰居信用資質(zhì)。
異構(gòu)關(guān)系:不同關(guān)系的鄰居的信息。
拓?fù)浣Y(jié)構(gòu):周圍鄰居的拓?fù)浣Y(jié)構(gòu)信息
實(shí)體交互:節(jié)點(diǎn)資質(zhì)和鄰居資質(zhì)是如何交互的?
如何提取以上的信息?
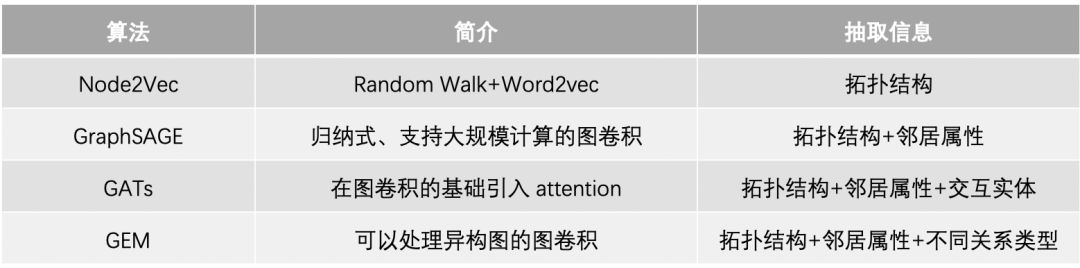
上面的模型都可以是解決方案,但是也存在著一定的局限:
1. 首先GNN是黑箱,解釋性不夠,對于和錢直接相關(guān)的業(yè)務(wù),對解釋性的要求非常高。
2. 穩(wěn)定性:金融模型上線會運(yùn)行很久,對穩(wěn)定性要求較高。
3. 性價(jià)比,雖然對圖經(jīng)過了壓縮,但是也有億級別規(guī)模,落地成本比較大,包括訓(xùn)練架構(gòu)、算法優(yōu)化等等。
如何解決這些局限性呢?
拆解上面算法,提取關(guān)鍵模塊,用數(shù)理統(tǒng)計(jì)方法解題:
1. 聚合直接相連鄰居特征:參考單層卷積的aggregator操作,其實(shí)也就是對鄰居特征不帶參數(shù)求mean、max、加權(quán)平均;
2.獲得k跳鄰居特征及拓?fù)洌嚎梢試L試多層遞歸卷積 / 社區(qū)發(fā)現(xiàn);
3.與鄰居特征做交互:拼接、比較、平均;
4.如何融合異構(gòu)關(guān)系:每種關(guān)系網(wǎng)絡(luò)都通過上述方法衍生特征,不同業(yè)務(wù)通過模型來學(xué)習(xí)權(quán)重。
某場景:借款人提交完認(rèn)證資料后,觸發(fā)信用評估并返回額度和利率,對時(shí)效性要求較高。
離線+實(shí)時(shí) 實(shí)現(xiàn)t跳鄰居特征計(jì)算
離線:T+1計(jì)算好所有節(jié)點(diǎn)(t-1跳)特征,存儲在HBASE上。
實(shí)時(shí):借款人提交完資料后,實(shí)時(shí)查找其一跳鄰居(如mysql),調(diào)用HBASE查找每一個(gè)鄰居特征,并聚合和交互生成特征。(一跳計(jì)算實(shí)時(shí)可以滿足,如果誰說二跳計(jì)算實(shí)時(shí)也可以支持那就牛逼了)。
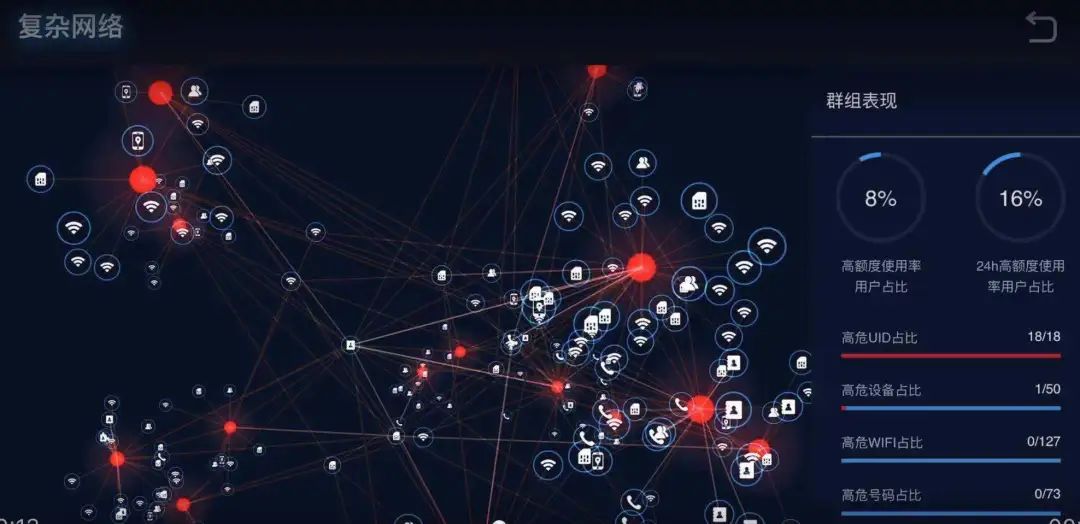
復(fù)雜網(wǎng)絡(luò)在風(fēng)控中更多是“找黑的”,比如反欺詐規(guī)則關(guān)聯(lián) N 個(gè)黑名單,N 個(gè)中介,以及團(tuán)伙挖掘等。
本文是從“找白的”角度下介紹復(fù)雜網(wǎng)絡(luò)在信用資質(zhì)上的應(yīng)用,方法具有普適性,在找黑的上驗(yàn)證效果也不錯(cuò):)。
如果精力/資源有限,建議優(yōu)先選擇某類關(guān)系和某些節(jié)點(diǎn)特征進(jìn)行實(shí)驗(yàn):
關(guān)系選擇:優(yōu)選覆蓋度較高、噪聲低、符合業(yè)務(wù)直覺的關(guān)系,如社交、支付,像LBS雖然覆蓋度高,但是噪聲也是比較大,在使用時(shí)需要謹(jǐn)慎。
節(jié)點(diǎn)特征選擇:優(yōu)先選擇已被驗(yàn)證效果不錯(cuò)的特征,如收入、信用額度等。
另外值得注意的是,比較容易數(shù)據(jù)穿越,有多個(gè)時(shí)間需要考慮,如”申請時(shí)間“、“建立關(guān)系時(shí)間”、“特征時(shí)間”等。
聚合一跳鄰居特征
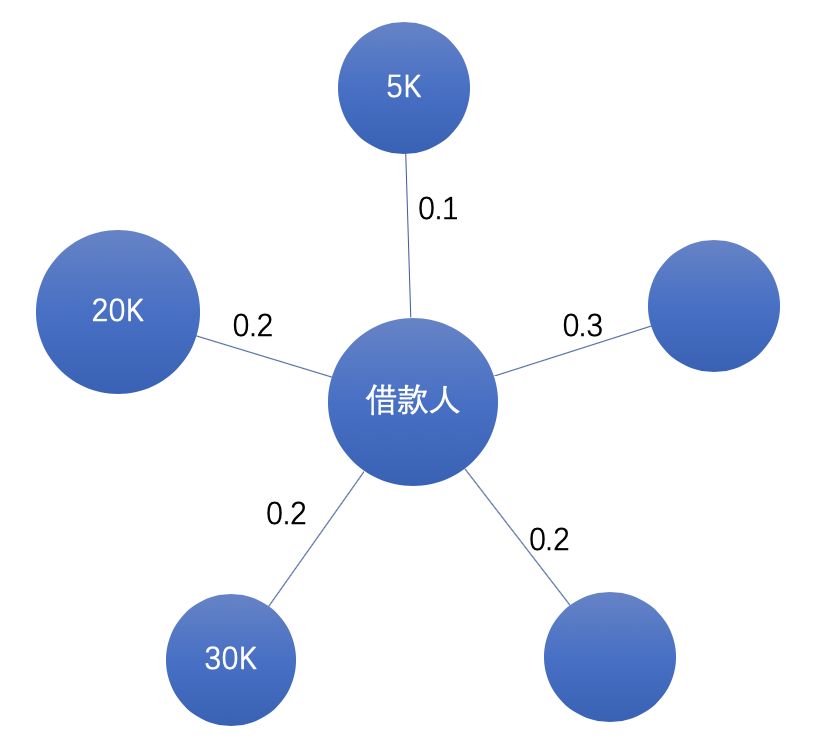
一跳鄰居即直接相連的鄰居,我們需要設(shè)計(jì)一個(gè)聚合函數(shù),在考慮關(guān)系權(quán)重的基礎(chǔ)上,如何表示一跳鄰居特征分布。
如下圖所示,假設(shè)是關(guān)系為親密度、節(jié)點(diǎn)特征為收入,如何聚合借款人不同親密度的鄰居收入特征?
我們可以設(shè)計(jì)這樣的聚合函數(shù)來加工信息(不考慮未知):
簡單平均:

假設(shè)不同親密度的朋友對借款人信用風(fēng)險(xiǎn)的影響是相同的(假設(shè)收入一樣)。
加權(quán)平均:

假設(shè)親密好友收入高低對借款人信用風(fēng)險(xiǎn)影響較大。
最大值:
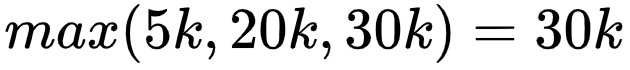
假設(shè)親密好友收入高低對借款人信用風(fēng)險(xiǎn)影響較大。
哪個(gè)聚合函數(shù)效果比較好?不同聚合函數(shù)的業(yè)務(wù)假設(shè)是不同的,建議都使用。特征工程即把可能有用的特征都加工出來,再通過 y 做特征選擇。
特征取值“未知”,怎么處理?因?yàn)槲粗鋵?shí)也可能包含信息,建議聚合計(jì)算分考慮未知和不考慮未知進(jìn)行計(jì)算。
鄰居特征是離散的,怎么聚合?轉(zhuǎn)換成one-hot編碼,計(jì)算在屬于某個(gè)類別鄰居比例。
聚合多跳鄰居特征
問題:鄰居數(shù)量隨著“跳數(shù)”增加而指數(shù)增長,直接獲得借款人多跳鄰居比較困難。假設(shè)平均節(jié)點(diǎn)度為100,那么每個(gè)借款人一跳鄰居數(shù)量為100,二跳鄰居100^2,三跳鄰居100^3。
下面介紹“多跳遞歸傳播”和”社區(qū)發(fā)現(xiàn)“這兩種方法
多跳遞歸傳播
以計(jì)算二跳鄰居特征為例,該方法大概的思路是:將當(dāng)前節(jié)點(diǎn)的二跳鄰居特征傳播到一跳鄰居上,然后將一跳鄰居新特征再傳播到當(dāng)前節(jié)點(diǎn)。
細(xì)節(jié):
1. 因?yàn)槊看蝹鞑ブ粫婕爸苯酉噙B的鄰居,故計(jì)算復(fù)雜度大為降低。
2. 原文前向傳播計(jì)算是帶參數(shù)W的,這里簡化為將所有參數(shù)相等(因?yàn)槭翘卣鞴こ蹋皇菍W(xué)習(xí),故會損失一些信息)
3. 對鄰居節(jié)點(diǎn)進(jìn)行固定數(shù)量抽樣,而不是取全部(避免數(shù)據(jù)傾斜),采樣方法使用計(jì)算復(fù)雜度為O(1)的Alias Method。
4. 遞歸實(shí)現(xiàn),每輪對所有節(jié)點(diǎn)聚合其鄰居(隱)特征及交互,并更新節(jié)點(diǎn)特征,作為下一輪輸入。
5. 第一輪得到所有節(jié)點(diǎn)一跳鄰居特征,第二輪得到二跳鄰居特征,以此類推。
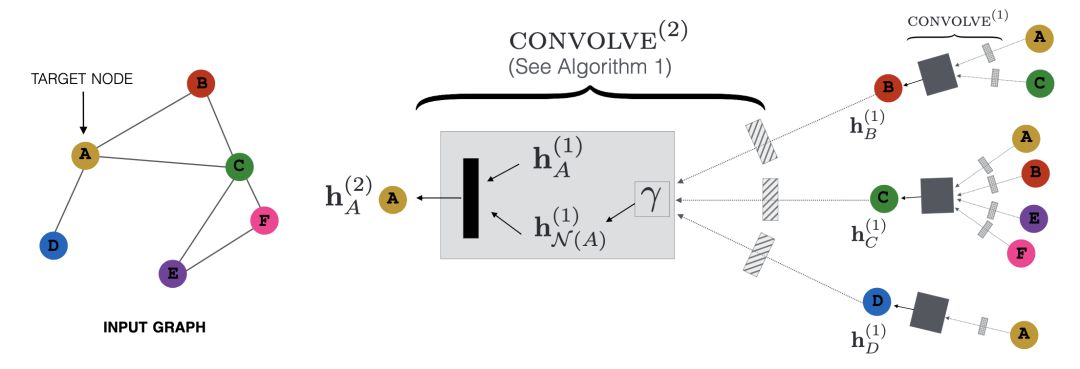
社區(qū)發(fā)現(xiàn)
大致思路:通過社區(qū)發(fā)現(xiàn)算法將graph分成一個(gè)個(gè)社區(qū),然后計(jì)算每個(gè)節(jié)點(diǎn)所屬社區(qū)的特征,如社區(qū)中黑名單比例、社區(qū)中平均收入。
這種方法相當(dāng)于對多跳鄰居根據(jù)拓?fù)浣Y(jié)構(gòu)進(jìn)行了分類(社區(qū)),故額外提取了網(wǎng)絡(luò)中拓?fù)浣Y(jié)構(gòu)信息。
工業(yè)界graph規(guī)模比較大,一般會用Louvain,速度快,效果也不錯(cuò),下面是spark版本實(shí)現(xiàn):
https://link.zhihu.com/?target=https%3A//github.com/Sotera/spark-distributed-louvain-modularity
實(shí)體間特征交互
聚合鄰居特征h1后,如何與自身特征h2做交互?
拼接:直接將h1拼接作為其一個(gè)新的特征
比較:h1-h2 或者 h1/h2 。例如求鄰居平均收入與借款人自身收入差距較大,是否有異常?
平均:(h1+h2)/2。
最大值:max(h1,h2),金融是重召回的,若特征表示風(fēng)險(xiǎn)程度,這樣即取最大風(fēng)險(xiǎn)。
處理不同異構(gòu)關(guān)系
將異構(gòu)關(guān)系拆成多個(gè)單一關(guān)系,每個(gè)關(guān)系都經(jīng)過上述方法生成特征,供下游不同場景使用。
這樣做的好處是:不同關(guān)系權(quán)重在不同場景是不同的,應(yīng)該是通過這些場景的y去學(xué)習(xí)。
形式化描述:
有|D|種類型關(guān)系,則可以拆解為|D|個(gè)graph:?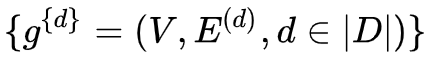
將上面提取graph特征方法記為 f
對每個(gè)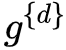 ?,都可以通過方法 f?提取特征?
?,都可以通過方法 f?提取特征?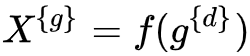
將不同的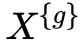 ?作為下游任務(wù)的輸入特征,根據(jù)任務(wù)目標(biāo)來賦予權(quán)重。
?作為下游任務(wù)的輸入特征,根據(jù)任務(wù)目標(biāo)來賦予權(quán)重。
借鑒螞蟻處理異構(gòu)網(wǎng)絡(luò)的思路:
https://zhuanlan.zhihu.com/p/59666737
實(shí)踐結(jié)果
不同社區(qū)發(fā)現(xiàn)算法比較
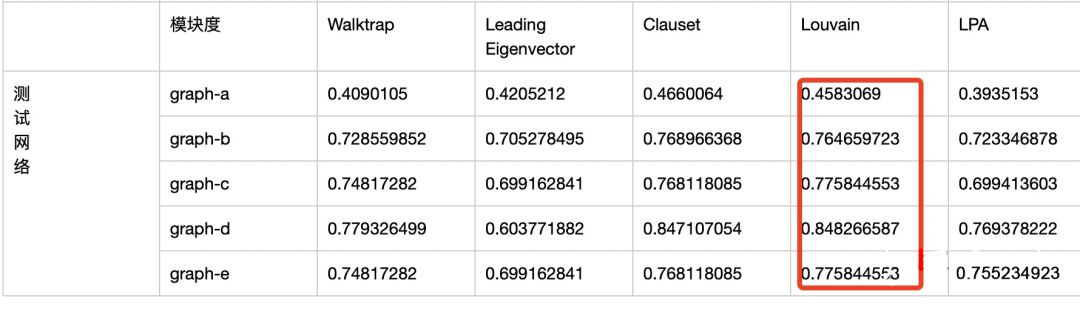
在實(shí)際小規(guī)模graph上對比了主流的社區(qū)發(fā)現(xiàn)算法,Louvain在劃分社區(qū)質(zhì)量和劃分穩(wěn)定性上均表現(xiàn)不錯(cuò)的,且能分布式實(shí)現(xiàn)。
Walktrap:基于隨機(jī)游走的社區(qū)發(fā)現(xiàn)算法 《Computing communities in large networks using random walks》
Leading Eigenvector:基于特征矩陣求模塊度,自底而上定層次聚類《Finding community structure in networks using the eigenvectors of matrices》
Fast-Greedy:自底而上的層次聚類《Finding community structure in very large networks》
Louvain:基于模塊度最大化的算法《Fast unfolding of communities in large networks》
LPA:基于標(biāo)簽傳播多社區(qū)發(fā)現(xiàn)算法 《Near linear time algorithm to detect community structures in large-scale networks.》
實(shí)驗(yàn)結(jié)果
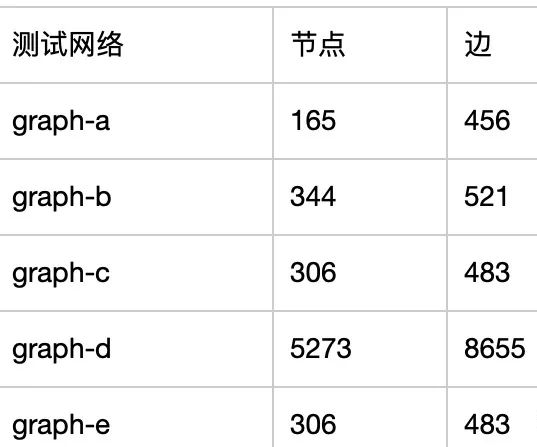
下面是脫敏后的實(shí)驗(yàn)網(wǎng)絡(luò)的規(guī)模:
劃分質(zhì)量:模塊度指標(biāo)
劃分?jǐn)?shù)量合理性

這是louvain劃分的某個(gè)graph的可視化效果(繪制工具:gephi)

感謝
感謝作者,一個(gè)快樂的數(shù)據(jù)玩家,從事風(fēng)控、圖挖掘方面的工作!
https://zhuanlan.zhihu.com/p/90813791
<b id="afajh"><abbr id="afajh"></abbr></b>